

環境查看
系統環境
# lsb_release -a No LSB modules are available. Distributor ID:Ubuntu Description:Ubuntu 22.04.4 LTS Release:22.04 Codename:jammy # cat /etc/redhat-release Rocky Linux release 9.3 (Blue Onyx)
軟件環境
# kubectl version Client Version: v1.30.2 Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3 Server Version: v1.25.16 WARNING: version difference between client (1.30) and server (1.25) exceeds the supported minor version skew of +/-1
安裝Nvidia的Docker插件
在有GPU資源的主機安裝,改主機作為K8S集群的Node
設置源
# curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
配置存儲庫以使用實驗性軟件包
# sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
修改后把以下注釋取消
更新
# sudo apt-get update
安裝Toolkit
# sudo apt-get install -y nvidia-container-toolkit
配置Docker以使用Nvidia
# sudo nvidia-ctk runtime configure --runtime=docker INFO[0000] Loading config from /etc/docker/daemon.json INFO[0000] Wrote updated config to /etc/docker/daemon.json INFO[0000] It is recommended that docker daemon be restarted.
這條命令會修改配置文件/etc/docker/daemon.json添加runtimes配置
# cat /etc/docker/daemon.json
{
"insecure-registries": [
"192.168.3.61"
],
"registry-mirrors": [
"https://7sl94zzz.mirror.aliyuncs.com",
"https://hub.atomgit.com",
"https://docker.awsl9527.cn"
],
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
}
重啟docker
# systemctl daemon-reload # systemctl restart docker
使用Docker調用GPU
驗證配置
啟動一個鏡像查看GPU信息
~# docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi Sat Oct 12 01:33:33 2024 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 555.42.06 Driver Version: 555.42.06 CUDA Version: 12.5 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off | | 0% 53C P2 59W / 450W | 4795MiB / 24564MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
該輸出結果顯示了 GPU 的詳細信息,包括型號、溫度、功率使用情況和內存使用情況等。這表明 Docker 容器成功地訪問到了 NVIDIA GPU,并且 NVIDIA Container Toolkit 安裝和配置成功。
4. 使用K8S集群Pod調用GPU
以下操作在K8S機器的Master節點操作
安裝K8S插件
下載最新版本
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.16.1/deployments/static/nvidia-device-plugin.yml
yml文件內容如下
# cat nvidia-device-plugin.yml apiVersion: apps/v1 kind: DaemonSet metadata: name: nvidia-device-plugin-daemonset namespace: kube-system spec: selector: matchLabels: name: nvidia-device-plugin-ds updateStrategy: type: RollingUpdate template: metadata: labels: name: nvidia-device-plugin-ds spec: tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule # Mark this pod as a critical add-on; when enabled, the critical add-on # scheduler reserves resources for critical add-on pods so that they can # be rescheduled after a failure. # See https://kubernetes.io/docs/tasks/administer-cluster/guaranteed-scheduling-critical-addon-pods/ priorityClassName: "system-node-critical" containers: - image: nvcr.io/nvidia/k8s-device-plugin:v0.16.1 name: nvidia-device-plugin-ctr env: - name: FAIL_ON_INIT_ERROR value: "false" securityContext: allowPrivilegeEscalation: false capabilities: drop: ["ALL"] volumeMounts: - name: device-plugin mountPath: /var/lib/kubelet/device-plugins volumes: - name: device-plugin hostPath: path: /var/lib/kubelet/device-plugins
使用DaemonSet方式部署在每一臺node服務器部署
查看Pod日志
# kubectl logs -f nvidia-device-plugin-daemonset-8bltf -n kube-system I1012 02:15:37.171056 1 main.go:199] Starting FS watcher. I1012 02:15:37.171239 1 main.go:206] Starting OS watcher. I1012 02:15:37.172177 1 main.go:221] Starting Plugins. I1012 02:15:37.172236 1 main.go:278] Loading configuration. I1012 02:15:37.173224 1 main.go:303] Updating config with default resource matching patterns. I1012 02:15:37.173717 1 main.go:314] Running with config: { "version": "v1", "flags": { "migStrategy": "none", "failOnInitError": false, "mpsRoot": "", "nvidiaDriverRoot": "/", "nvidiaDevRoot": "/", "gdsEnabled": false, "mofedEnabled": false, "useNodeFeatureAPI": null, "deviceDiscoveryStrategy": "auto", "plugin": { "passDeviceSpecs": false, "deviceListStrategy": [ "envvar" ], "deviceIDStrategy": "uuid", "cdiAnnotationPrefix": "cdi.k8s.io/", "nvidiaCTKPath": "/usr/bin/nvidia-ctk", "containerDriverRoot": "/driver-root" } }, "resources": { "gpus": [ { "pattern": "*", "name": "nvidia.com/gpu" } ] }, "sharing": { "timeSlicing": {} } } I1012 02:15:37.173760 1 main.go:317] Retrieving plugins. E1012 02:15:37.174052 1 factory.go:87] Incompatible strategy detected auto E1012 02:15:37.174086 1 factory.go:88] If this is a GPU node, did you configure the NVIDIA Container Toolkit? E1012 02:15:37.174096 1 factory.go:89] You can check the prerequisites at: https://github.com/NVIDIA/k8s-device-plugin#prerequisites E1012 02:15:37.174104 1 factory.go:90] You can learn how to set the runtime at: https://github.com/NVIDIA/k8s-device-plugin#quick-start E1012 02:15:37.174113 1 factory.go:91] If this is not a GPU node, you should set up a toleration or nodeSelector to only deploy this plugin on GPU nodes I1012 02:15:37.174123 1 main.go:346] No devices found. Waiting indefinitely.
驅動失敗,錯誤提示已經清楚說明了失敗原因
該Node部署GPU節點即該Node沒有GPU資源
該Node有GPU資源,沒有安裝Docker驅動
沒有GPU資源的節點肯定無法使用,但是已經有GPU資源的Node節點也會報這個錯誤
有GPU節點的修復方法,修改配置文件添加配置
# cat /etc/docker/daemon.json
{
"insecure-registries": [
"192.168.3.61"
],
"registry-mirrors": [
"https://7sl94zzz.mirror.aliyuncs.com",
"https://hub.atomgit.com",
"https://docker.awsl9527.cn"
],
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"args": [],
"path": "/usr/bin/nvidia-container-runtime"
}
}
}
關鍵配置是以下行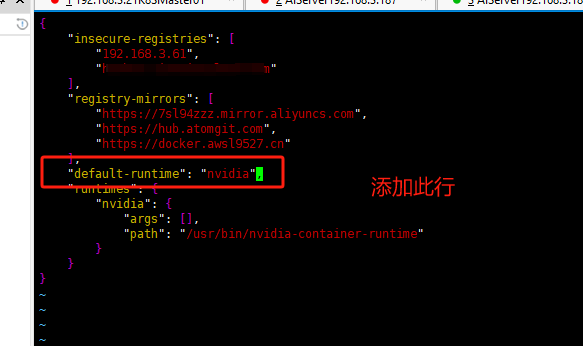
再次查看Pod日志
# kubectl logs -f nvidia-device-plugin-daemonset-mp5ql -n kube-system
I1012 02:22:00.990246 1 main.go:199] Starting FS watcher.
I1012 02:22:00.990278 1 main.go:206] Starting OS watcher.
I1012 02:22:00.990373 1 main.go:221] Starting Plugins.
I1012 02:22:00.990382 1 main.go:278] Loading configuration.
I1012 02:22:00.990692 1 main.go:303] Updating config with default resource matching patterns.
I1012 02:22:00.990776 1 main.go:314]
Running with config:
{
"version": "v1",
"flags": {
"migStrategy": "none",
"failOnInitError": false,
"mpsRoot": "",
"nvidiaDriverRoot": "/",
"nvidiaDevRoot": "/",
"gdsEnabled": false,
"mofedEnabled": false,
"useNodeFeatureAPI": null,
"deviceDiscoveryStrategy": "auto",
"plugin": {
"passDeviceSpecs": false,
"deviceListStrategy": [
"envvar"
],
"deviceIDStrategy": "uuid",
"cdiAnnotationPrefix": "cdi.k8s.io/",
"nvidiaCTKPath": "/usr/bin/nvidia-ctk",
"containerDriverRoot": "/driver-root"
}
},
"resources": {
"gpus": [
{
"pattern": "*",
"name": "nvidia.com/gpu"
}
]
},
"sharing": {
"timeSlicing": {}
}
}
I1012 02:22:00.990780 1 main.go:317] Retrieving plugins.
I1012 02:22:01.010950 1 server.go:216] Starting GRPC server for 'nvidia.com/gpu'
I1012 02:22:01.011281 1 server.go:147] Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
I1012 02:22:01.012376 1 server.go:154] Registered device plugin for 'nvidia.com/gpu' with Kubelet
查看GPU節點信息
# kubectl describe node aiserver003087
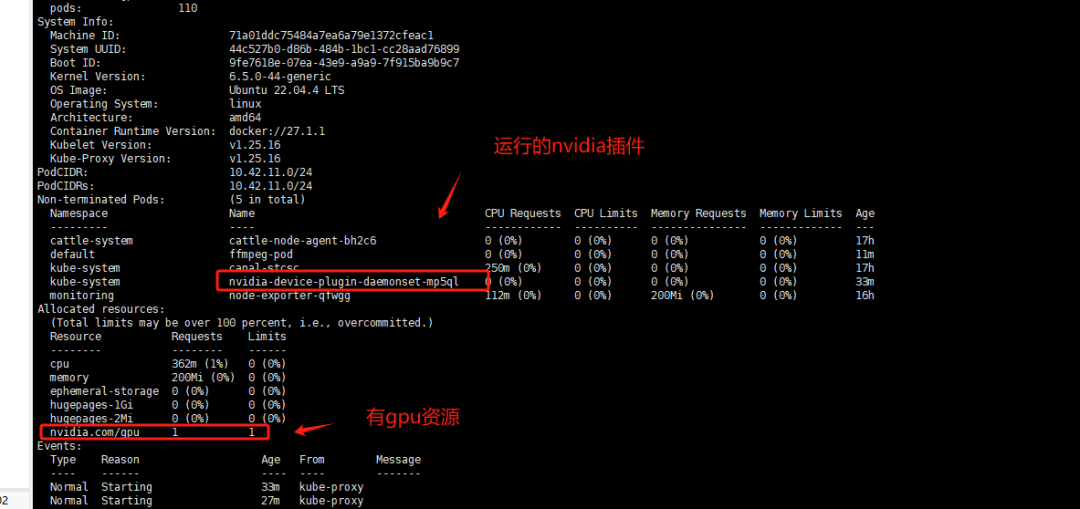
在k8s中測試GPU資源調用
測試Pod
# cat gpu_test.yaml
apiVersion: v1
kind: Pod
metadata:
name: ffmpeg-pod
spec:
nodeName: aiserver003087 #指定有gpu的節點
containers:
- name: ffmpeg-container
image: nightseas/ffmpeg:latest #k8s中配置阿里的私有倉庫遇到一些問題,暫時用公共鏡像
command: [ "/bin/bash", "-ce", "tail -f /dev/null" ]
resources:
limits:
nvidia.com/gpu: 1 # 請求分配 1個 GPU
創建Pod
# kubectl apply -f gpu_test.yaml pod/ffmpeg-pod configured
往Pod內倒入一個視頻進行轉換測試
# kubectl cp test.mp4 ffmpeg-pod:/root
進入Pod
# kubectl exec -it ffmpeg-pod bash
轉換測試視頻
# ffmpeg -hwaccel cuvid -c:v h264_cuvid -i test.mp4 -vf scale_npp=1280:720 -vcodec h264_nvenc out.mp4
成功轉換并且輸出out.mp4則代表調用GPU資源成功
為保證DaemonSet至部署至帶GPU資源的服務器可以做一個node標簽選擇器
設置給節點標簽
# kubectl label nodes aiserver003087 gpu=true
修改DaemonSet配置文件添加標簽選擇保證DaemonSet至部署至帶gpu=true標簽的Node上
deployment配置文件修改位置是一致的
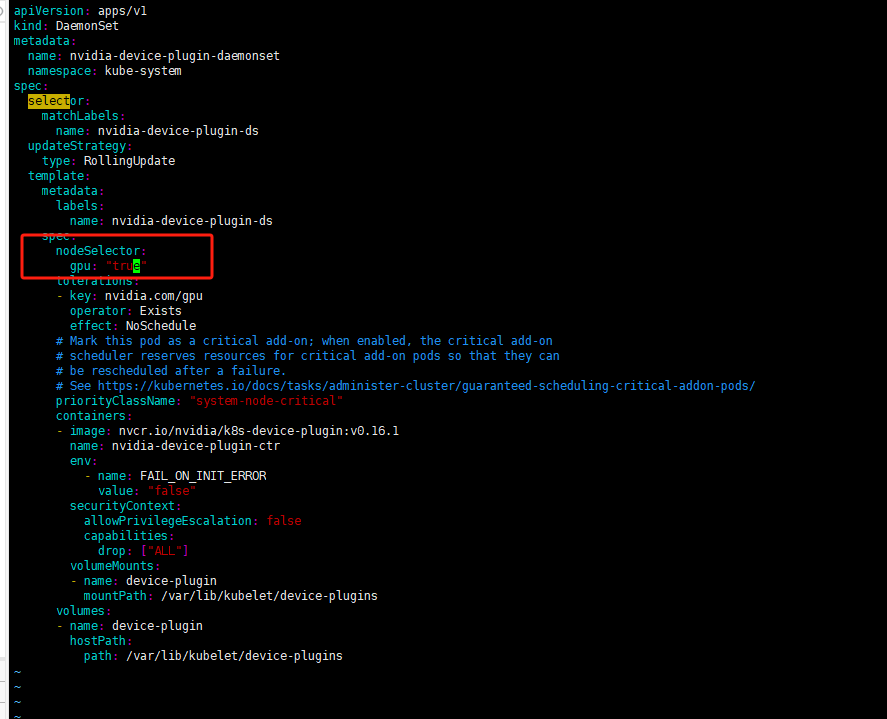
修改gpu測試Pod的yaml文件使用標簽選擇器
# cat gpu_test.yaml
apiVersion: v1
kind: Pod
metadata:
name: ffmpeg-pod
spec:
#nodeName: aiserver003087 #指定有gpu的節點
containers:
- name: ffmpeg-container
image: nightseas/ffmpeg:latest #k8s中配置阿里的私有倉庫遇到一些問題,暫時用公共鏡像
command: [ "/bin/bash", "-ce", "tail -f /dev/null" ]
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
gpu: "true"
#kubernetes.io/os: linux
注意: 標簽選擇器需要值需要添加雙引號"true"否則apply會報錯,不能把bool值作為對應的值應用至標簽選擇器
K8S集群會自動調用GPU資源,但是如果一個GPU設備已經被使用,再啟動一個應用時可能調用到改設備導致顯存溢出
可以修改配置指定GPU設備啟動
指定第8塊顯卡啟動應用,設備號從0開始計算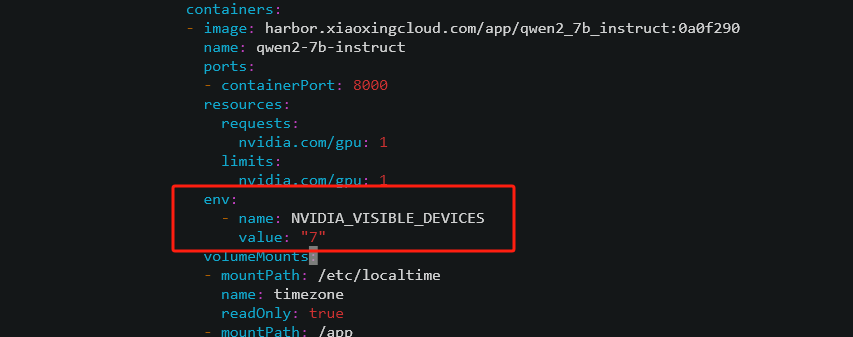
鏈接:https://www.cnblogs.com/minseo/p/18460107
-
gpu
+關注
關注
28文章
4876瀏覽量
130328 -
集群
+關注
關注
0文章
97瀏覽量
17339 -
命令
+關注
關注
5文章
719瀏覽量
22621 -
Docker
+關注
關注
0文章
501瀏覽量
12505
原文標題:AI時代GPU加速:如何通過Docker和K8S集群實現高效調用GPU
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
全面提升,阿里云Docker/Kubernetes(K8S) 日志解決方案與選型對比
全面提升,阿里云Docker/Kubernetes(K8S) 日志解決方案與選型對比
K8s 從懵圈到熟練 – 集群網絡詳解
k8s容器運行時演進歷史
Docker不香嗎為什么還要用K8s
簡單說明k8s和Docker之間的關系
K8S集群服務訪問失敗怎么辦 K8S故障處理集錦

多k8s集群環境中工作有多快

k8s是什么意思?kubeadm部署k8s集群(k8s部署)|PetaExpres
K8s多集群管理:為什么需要多集群、多集群的優勢是什么

k8s云原生開發要求






 工商網監
工商網監

評論