

在自然界中,好奇心驅使著生物探索未知,是生存和進化的關鍵。人類,作為地球上最具智能的物種,其探索精神引領了科技、文化和社會的進步。1492 年,哥倫布懷揣探索未知的理想,勇敢地向西航行,最終發現了新大陸。
正如人類在面對未知時展現出的探索行為,在人工智能領域,尤其在大型語言模型(LLMs)理解語言和知識中,研究人員正嘗試賦予 LLM 類似的探索能力,從而突破其在給定數據集中學習的能力邊界,進一步提升性能和安全性。
近期,中國電信集團 CTO、首席科學家、中國電信人工智能研究院(TeleAI)院長李學龍教授帶領團隊在全模態星辰大模型體系深耕的基礎之上,聯合清華大學、香港城市大學、上海人工智能實驗室等單位提出了一種新的探索驅動的大模型對齊方法 Count-based Online Preference Optimization(COPO)。
該工作將人類探索的本能融入到大語言模型的后訓練(Post-Training)中,引導模型在人類反饋強化學習(RLHF)框架下主動探索尚未充分理解的知識,解決了現有對齊框架受限于偏好數據集覆蓋范圍的問題。
這一創新成果為智傳網(AI Flow)中 “基于連接與交互的智能涌現” 提供了重要技術支撐,使得模型在動態交互中不斷學習和進步,在探索的過程中實現智能的持續涌現。論文被國際表征學習大會 ICLR 2025 錄用,實現了大模型多輪交互探索中的能力持續提升。TeleAI 研究科學家白辰甲為論文的第一作者。

論文標題:
Online Preference Alignment for Language Models via Count-based Exploration
論文地址:
https://arxiv.org/abs/2501.12735
代碼地址:
https://github.com/Baichenjia/COPO
研究動機
雖然大型語言模型(LLM)在進行多種語言任務中已經有出色的表現,但它們在與人類價值觀和意圖對齊方面仍面臨著很多挑戰。現有的大模型 RLHF 框架主要依賴于預先收集的偏好數據集進行對齊,其性能受限于離線偏好數據集對提示 - 回復(Prompt-Response)的覆蓋范圍,對數據集覆蓋之外的語言難以進行有效泛化。
然而,人類偏好數據集的收集是較為昂貴的,且現有的偏好數據難以覆蓋所有可能的提示和回復。這就引出了一個關鍵問題:是否可以使 LLM 在對齊過程中對語言空間進行自主探索,從而突破離線數據集的約束,不斷提升泛化能力?
為了解決這一問題,近期的大模型相關研究開始由人類反饋強化學習驅動的離線對齊(Offline RLHF)轉向在線對齊(Online RLHF),通過迭代式地收集提示和回復,允許大模型在與語言環境的互動中不斷學習和進步,從而在偏好數據集的覆蓋之外進行探索。
本研究旨在解決在線 RLHF 過程中的核心問題:如何使 LLM 高效在語言空間(類比于強化學習動作空間)中進行探索。
具體地,強化學習算法在進行大規模的狀態動作空間(類比于 LLM 中的語言生成空間)中的最優策略求解時,系統性探索(Systematic Exploration)對于收集有益的經驗至關重要,會直接關系到策略學習的效果。在 LLM 對齊中,如果缺乏有效的探索機制,可能會導致模型對齊陷入局部最優策略。
同時,有效的探索可以幫助大模型更好地理解語言環境的知識,從而在廣闊的語言空間中找到最優回復策略。
本研究的目標在于解決在線 RLHF 中的探索問題,即如何在每次迭代中有效地探索提示 - 回復空間,以擴大偏好數據覆蓋范圍,提高模型對人類偏好的學習和適應能力。具體地,COPO 算法通過結合基于計數的探索(Count-based Exploration)和直接偏好優化(DPO)框架,利用一個輕量級的偽計數模塊來平衡探索和偏好優化,并在線性獎勵函數近似和離散狀態空間中提供了理論框架。
實驗中,在 Zephyr 和 Llama-3 模型上進行的 RLHF 實驗結果表明,COPO 在指令遵循和學術基準測試中的性能優于其他 RLHF 基線。
理論框架、
研究的理論框架基于大模型獎勵的線性假設,將獎勵函數簡化為參數向量和特征向量的內積形式。在此假設下,可以將復雜大模型對語言提取的特征作為一個低維的向量,將 RLHF 過程中構建的顯式或隱式的大模型獎勵視為向量的線性函數,具體地:

在此基礎上,給定大模型偏好數據集 ,在現有 Bradley-Terry (BT) 獎勵模型的基礎上可以通過極大似然估計來估計獎勵模型的參數,即:
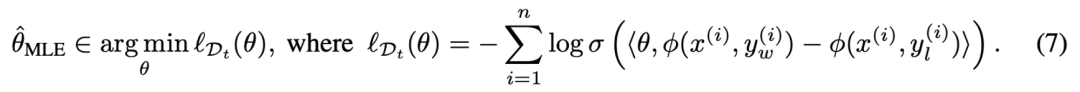
隨后,根據統計學中的相關理論,可以定量地為獎勵模型提供了一個明確的誤差界限,并得到關于獎勵模型參數的置信集合(confidence set),從而使估計的參數以較大概率落在置信集合中。具體地:
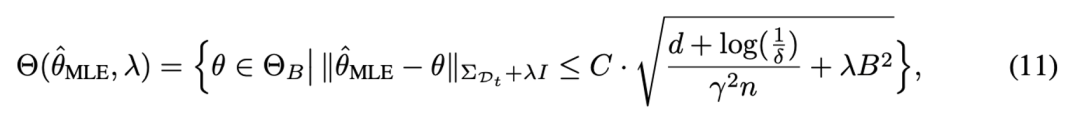
隨后,在參數集合中可以使用樂觀的期望值函數來獲得值函數估計的置信上界,從而實現了強化學習探中的樂觀原則(Optimism), 使大模型策略向樂觀方向進行策略優化。
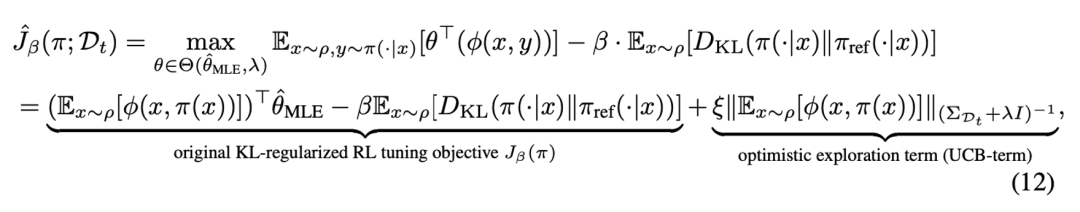
在上述目標中,最終的優化項包含兩個部分:第一部分對應于經典的兩階段 RLHF 方法,在 BT 模型的基礎上估計獎勵,通過最大化獎勵來學習策略,同時保持和原始大模型策略的接近性約束。第二部分為新引入的置信區間上界(UCB)項,用于測量當前數據集對目標策略生成的狀態分布的覆蓋程度,鼓勵模型探索那些尚未充分探索的語言空間。
具體來說,UCB 項通過增加對較少產生的提問 - 回答的組合的對數似然,從而鼓勵大模型生成新的、可能更優的回答。這將有助于大模型在最大化獎勵和探索新響應之間的權衡,即著名的強化學習探索 - 利用權衡(exploration-exploitation trade-off)。
最終,研究證明了采用 COPO 算法的在線學習范式能夠在 T 次迭代后,將總后悔值限制在 O (√T) 的量級內,顯示了算法在處理大規模狀態空間時的效率和穩定性。

算法設計
在理論框架下,具體的算法設計中結合了直接偏好優化(DPO)的算法框架。其中第一項對獎勵的構建和獎勵最大化的學習具象化為 DPO 的學習目標,而將樂觀探索的 UCB 項轉化為更容易求解的目標。具體地,在有限狀態動作空間的假設下,樂觀探索項可以表示為基于狀態 - 動作計數(Count)的學習目標,即:
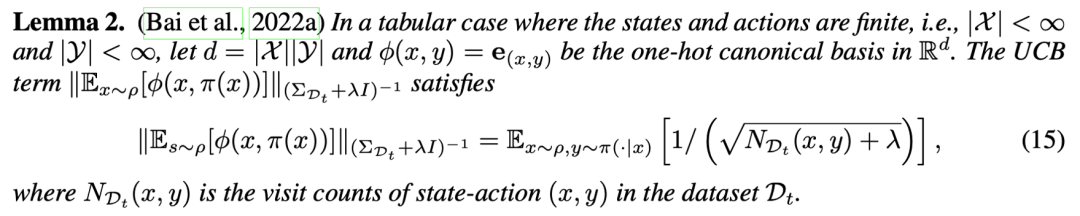
從而,最終的學習目標表示為 DPO 獎勵和基于提示 - 回答計數的探索目標。具體地:
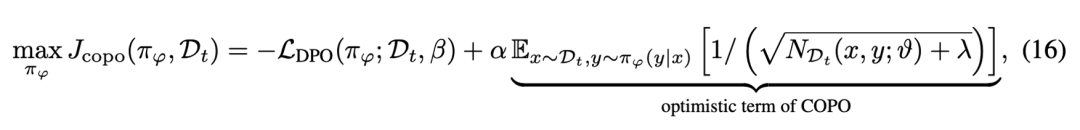
上式中第二項通過在偏好數據中對模型產生的提示 - 回答進行計數,可以鼓勵增加對之前出現次數較少的提示 - 回答的探索來鼓勵大模型突破離線數據集的覆蓋,使模型主動探索新的、可能更優的回復,從而在迭代過程中擴大數據覆蓋范圍并提高策略的性能。
進而可以通過求解梯度的方式進一步的解析 COPO 優化目標的意義:
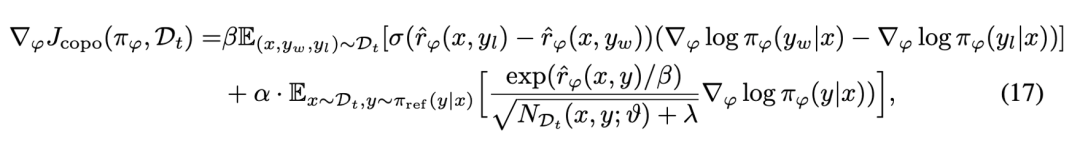
由兩部分組成:第一部分負責優化模型以最大化偏好數據上的預期獎勵;第二部分對應于探索項的梯度,它根據提示 - 回復對的歷史訪問次數來調整模型的優化方向。
當某個回復的歷史訪問次數較少時,該項會推動模型增加生成該回復的對數似然,從而鼓勵模型探索那些較少被訪問但可能帶來更高獎勵的區域,使算法能夠在最大化獎勵的同時有效地平衡探索與利用,實現更優的策略學習。
然而,在對大模型進行上述目標優化中,往往無法在大規模語言空間中實現對 “提示 - 回復” 的準確 “計數”。語言空間的狀態通常是無限的,且完全相同的回復很少被多次產生,因此需要一種方法來估計或模擬這些提示 - 回復對的 “偽計數”,以便算法能夠在探索較少訪問的區域時獲得激勵。
在此基礎上,COPO 提出使用 Coin Flipping Network(CFN)來高效的實現偽計數。CFN 不依賴于復雜的密度估計或對模型架構和訓練過程的限制,而是通過一個簡單的回歸問題來預測基于計數的探索獎勵。
具體地,CFN 基于的基本假設是,計數可以通過從 Rademacher 分布的采樣來估計來得到,考慮從 {-1,1} 的集合中近似隨機采樣得到的分布,如果進行 n 次采樣并對采樣結果取平均,則該變量的二階矩和計數的倒數呈現出等價的關系,即:
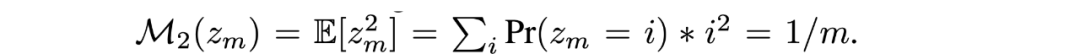
進而,CFN 通過在每次遇到狀態時進行 Rademacher 試驗(即硬幣翻轉),并利用這些試驗的平均值來推斷狀態的訪問頻率。在實現中,CFN 表示為一個輕量化的網絡,它通過最小化預測值和實際 Rademacher 標簽之間的均方誤差來進行訓練。
在實現中,CFN 接受由主語言模型提取的提示 - 回復對的最后隱藏狀態作為輸入,并輸出一個預測值,該值與狀態的 “偽計數” 成反比。通過這種方式,CFN 能夠為每個提示 - 響應提供一個探索激勵,鼓勵模型在探索迭代中擴大數據覆蓋范圍,提高模型對齊的性能。
實驗結果
在實驗中使用 UltraFeedback 60K 偏好數據集來對 Zephyr-7B 和 Llama3-8B 模型進行微調,數據集中包含豐富的單輪對話偏好對的數據。
實驗中使用了一個小型的獎勵模型 PairRM 0.4B 來對多輪迭代過程中模型模型生成的回復進行偏好排序,從而在探索中利用不斷更新后的大模型來產生不斷擴充的偏好數據,提升了數據集的質量和覆蓋率。
此外,實驗中使用輕量化的 CFN 網絡實現對提示 - 響應對的偽計數,大幅提升了在線 RLHF 算法的探索能力。
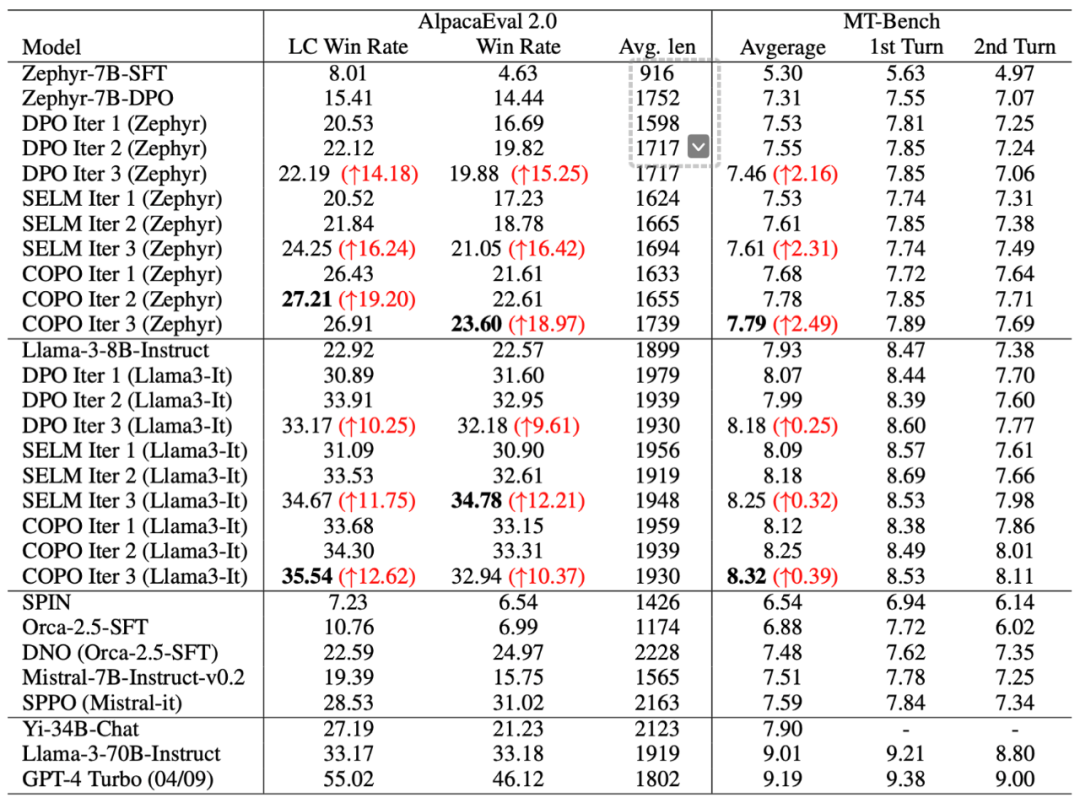
實驗結果表明,COPO 算法在 AlpacaEval 2.0 和 MT-Bench 基準測試可以通過多輪探索和對齊來不斷進行性能提升。具體地,相比于離線 DPO 算法,COPO 顯著提升了 Zephyr-7B 和 Llama3-8B 模型的 LC 勝率,分別達到了 18.8% 和 7.1% 的提升,驗證了 LLM 探索能力提升對獲取更大數據覆蓋和最優策略方面的優勢。
此外,COPO 超越了在線 DPO、SELM 等當前最好的在線對齊方法,以 8B 的模型容量超越了許多大體量模型(如 Yi-34B,Llama3-70B)的性能,提升了大模型在語言任務中的指令跟隨能力和泛化能力。
-
人工智能
+關注
關注
1803文章
48406瀏覽量
244633 -
LLM
+關注
關注
1文章
316瀏覽量
628
原文標題:ICLR 2025 | 8B模型反超Llama3-70B!TeleAI提出探索驅動的對齊方法COPO
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

IBM在watsonx.ai平臺推出DeepSeek R1蒸餾模型
IBM企業級AI開發平臺watsonx.ai上線DeepSeek R1蒸餾模型
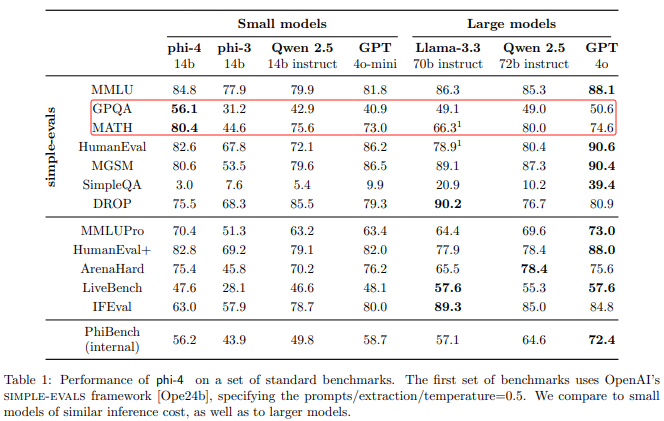
在算力魔方上本地部署Phi-4模型
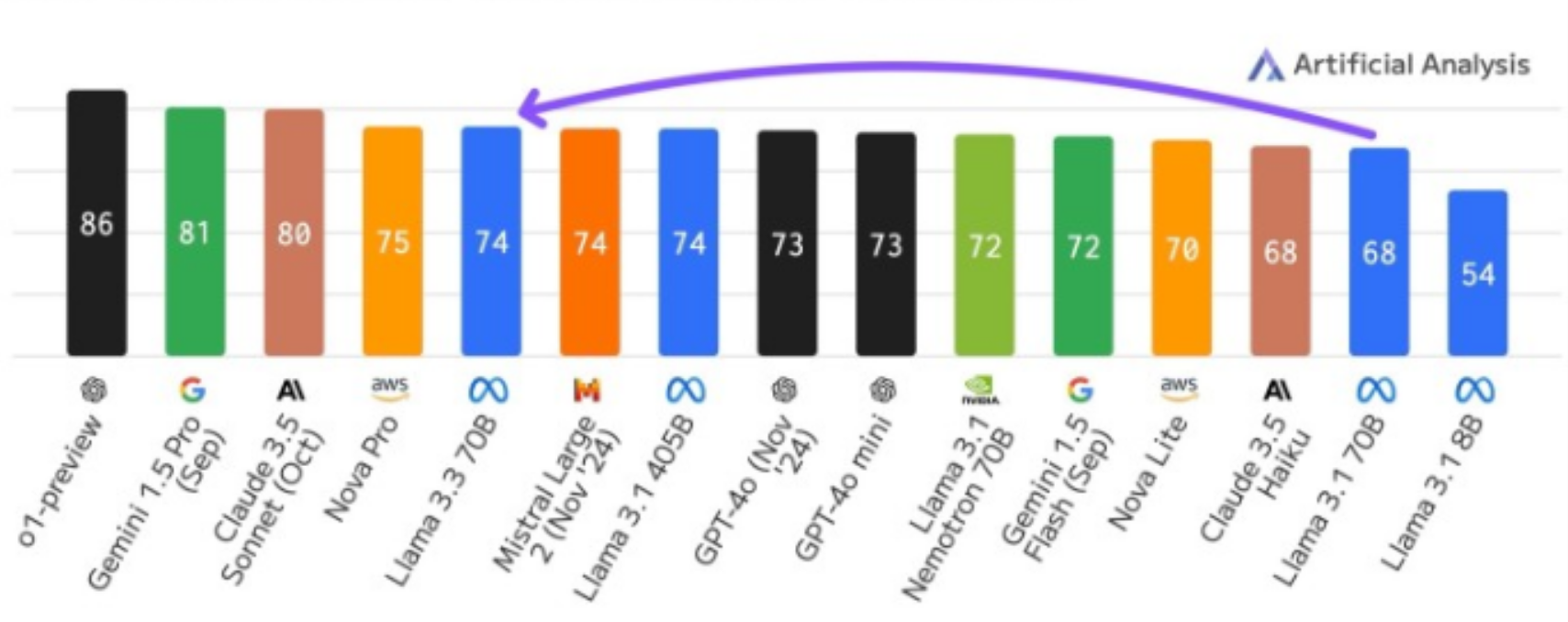
Meta重磅發布Llama 3.3 70B:開源AI模型的新里程碑
Meta推出Llama 3.3 70B,AI大模型競爭白熱化
光纜8d與8b區別
Llama 3 語言模型應用
TAS5805的I2C地址配置的是7b:2D,8b:5A怎么出來是7b:2F,8b:5E?這個是什么原因?
英偉達發布AI模型 Llama-3.1-Nemotron-51B AI模型
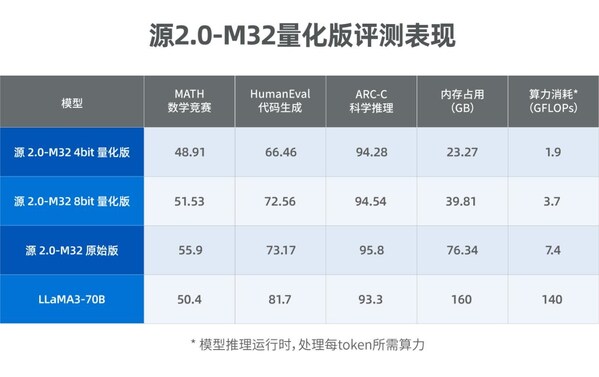
源2.0-M32大模型發布量化版 運行顯存僅需23GB 性能可媲美LLaMA3
PerfXCloud平臺成功接入Meta Llama3.1
NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型

Optimum Intel三步完成Llama3在算力魔方的本地量化和部署





 工商網監
工商網監

評論