

最近,開源中國 OSCHINA、Gitee 與 Gitee AI

全文如下:
大模型撞上 “算力墻”,超級應(yīng)用的探尋之路
文 / 傅聰
近日,大模型教父 Sam Altman 在 Reddit 上的評論透露出 GPT-5 難產(chǎn)的隱憂,直言有限的算力約束讓 OpenAI 面臨迭代優(yōu)先級的艱難抉擇,在通往 AGI 的道路上一路高歌猛進(jìn)的領(lǐng)頭羊似乎撞上了“算力墻”。
除此之外,能耗、資金,難以根除的幻覺,有限的知識更新速率、有限的上下文寬度、高昂的運(yùn)營成本等等,都讓外界對大模型的發(fā)展憂心忡忡。面對棘手的困境與難題,大模型的未來,又該何去何從呢?
下一代 “明星產(chǎn)品”
“算力墻”下,模型效果邊際收益遞減,訓(xùn)練和運(yùn)營成本高昂,在這個(gè)時(shí)間節(jié)點(diǎn),最好的 AI 產(chǎn)品會是什么?奧特曼、蓋茨、小扎、吳恩達(dá)、李彥宏等一眾大佬給出了一致的答案 —— 智能體(AI Agent)。
2025,將會是智能體元年。
什么是智能體?目前業(yè)界一致認(rèn)可的公式是“智能體 = LLM + 記憶 + 規(guī)劃 + 工具”:
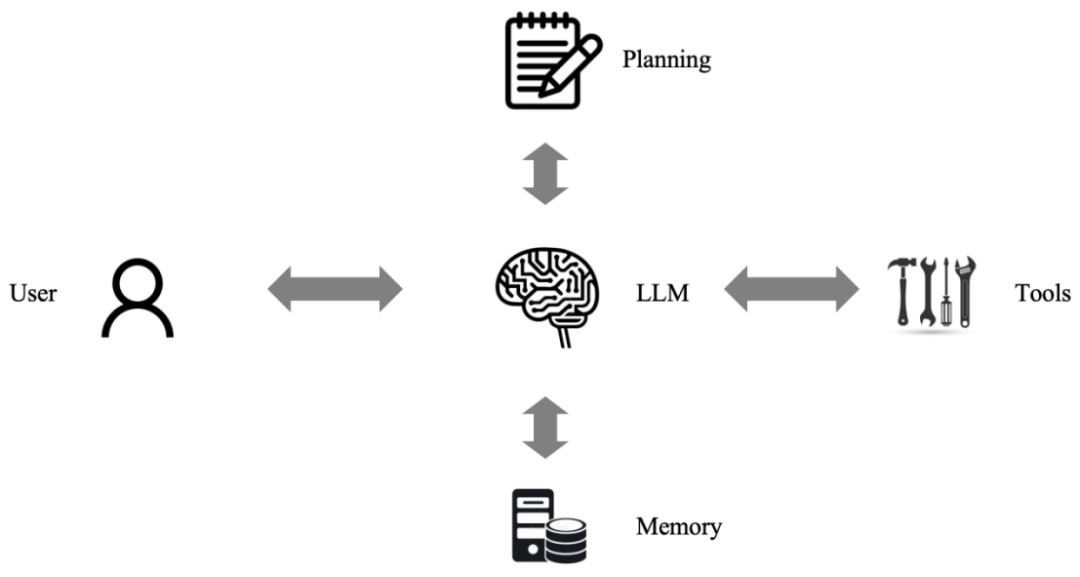
大模型充當(dāng)智能體的“大腦”,負(fù)責(zé)對任務(wù)進(jìn)行理解、拆解、規(guī)劃,并調(diào)用相應(yīng)工具以完成任務(wù)。同時(shí),通過記憶模塊,它還能為用戶提供個(gè)性化的服務(wù)。
智能體為什么是“算力墻”前 AI 產(chǎn)品的最優(yōu)解決方案?這一問題的底層邏輯包含兩個(gè)方面。
1. LLM 是目前已知最好的智能體底層技術(shù)。
智能體作為學(xué)術(shù)術(shù)語由來已久,從上世紀(jì)的“符號、專家系統(tǒng)”【1】,到十年前風(fēng)頭無兩的強(qiáng)化學(xué)習(xí)(代表作 AlphaGo【3】),再到現(xiàn)在的 LLM,agent 底層技術(shù)經(jīng)歷了三個(gè)大的階段。
符號系統(tǒng)的缺點(diǎn)在于過于依賴人工定義的“符號”和“邏輯”,強(qiáng)化學(xué)習(xí)苦于訓(xùn)練數(shù)據(jù)的匱乏和“模態(tài)墻”,而 LLM 一次性解決這些問題。
人類語言就是一種高度抽象、跨模態(tài)、表達(dá)力充分的符號系統(tǒng),同時(shí)它作為知識的載體,自然地存在大量數(shù)據(jù)可用于訓(xùn)練,還蘊(yùn)含了人類的思維模式。
在此基礎(chǔ)上訓(xùn)練得到的 LLM,自然具備被誘導(dǎo)出類人思考的潛力。在 COT(思維鏈)【4】、TOT(思維樹)【5】等技術(shù)的加持下,大模型正在學(xué)習(xí)拆解自己的“思維”,OpenAI 的 o1 就是典型案例,強(qiáng)化了推理能力的同時(shí),也大大緩解了幻覺問題。
2. 大模型做不到的,“現(xiàn)存工具”強(qiáng)勢補(bǔ)位。
無法持續(xù)更新的知識庫,可以通過 RAG(Retrieval Augmented Generation,檢索增強(qiáng)生成)來解決。
RAG 的出現(xiàn),讓各界越來越深刻地認(rèn)識到,大模型沒必要存儲那么多知識,只需要如何使用搜索引擎這個(gè)外部工具即可。大模型可以在搜索結(jié)果上做進(jìn)一步的信息篩選和優(yōu)化,而搜索引擎彌補(bǔ)了大模型的知識缺陷,實(shí)現(xiàn)了 1+1>=2 的效果。
RAG 可以被理解為智能體的最簡單形式。未來的智能體可以實(shí)現(xiàn)多種工具的混合使用,甚至多智能體協(xié)作,這不是猜想,我們已經(jīng)在學(xué)術(shù)界看到了驚艷的早期方案【6,7】。
“四把鑰匙”解鎖潛力
1. 領(lǐng)域模型小型化、平臺化會成為新趨勢。
“算力墻”是一方面因素,但基座模型的趨同化和運(yùn)營成本是源動力。GPT、Claude、Gemini 雖然各有所長,但實(shí)際體驗(yàn)越來越讓大家分不出差異,基座模型作為智能體核心,決定了智能體效果下限,人人訓(xùn)練基座的可能性越來越低,“基座服務(wù)化”很可能是最合理的商業(yè)模式。
甚至,在錯(cuò)誤不敏感的應(yīng)用領(lǐng)域,出現(xiàn)一個(gè)開源、無商業(yè)限制的基座的可能性也很高。小應(yīng)用開發(fā)商很可能很容易獲得一個(gè)低成本 serving 的“量化小基座”。
“7B” 是一個(gè) magic number!無論是 RAG 里的向量表征模型,還是文生圖、文本識別(OCR)、語音合成(TTS)、人臉識別等等垂直領(lǐng)域,一個(gè) 1B~7B 的小模型已經(jīng)可以滿足很多生產(chǎn)、應(yīng)用需要,并且效果也在逐步推高【8,9,10】。這些模型,作為智能體的“三頭六臂”,不需要太“大”。
同時(shí),從學(xué)術(shù)角度來講,各種領(lǐng)域?qū)S媚P偷募夹g(shù)最優(yōu)解也在逐漸趨同。應(yīng)用開發(fā)者越來越不需要了解模型的底層技術(shù),只需要懂得如何設(shè)計(jì)自己應(yīng)用的任務(wù)流,懂一點(diǎn)點(diǎn) COT 系列的 prompt engineering 的技巧,就可以利用 Maas(Model as a service)、Aaas(Agent as a service)這樣的平臺,如玩樂高一般搭建自己的 AI 云原生應(yīng)用。
2. 算力層深挖定制化、低能耗的可能性,但固化 transformer 可能不是最優(yōu)解
雖說智能體不需要太大的模型,但其運(yùn)營成本(模型推理計(jì)算成本)仍然較高。在短時(shí)間內(nèi),算力、能源仍然會是大模型領(lǐng)域令人頭疼的高墻。
根據(jù)報(bào)告【1】,能源消耗將會是 2030 模型 scaling 最卡脖子的因素。也就是說,在算力到達(dá)瓶頸之前,首先可能會出現(xiàn)電能供應(yīng)不足甚至交不起電費(fèi)的問題。因此,算力層可以根據(jù)大模型底層技術(shù)的特性,產(chǎn)出針對性的芯片,尤其是加速運(yùn)算和降低能耗。這是未來 AI 芯片領(lǐng)域的最優(yōu)競爭力。
那么,把 transformer “焊死”到板子上就是最佳方案嗎?我知道你很急,但你先別急。大模型底層框架還存在底層路線之爭。
我們知道,Transformer 架構(gòu)呈現(xiàn)了 O (n2) 的理論計(jì)算復(fù)雜度,這里的 n 指的是大模型輸入序列的 token 數(shù)量,但其前任語言模型擔(dān)當(dāng) RNN 只有 O (n) 的理論計(jì)算復(fù)雜度。
最近,以 Mamba、RWKV 為代表的類 RNN 結(jié)構(gòu)死灰復(fù)燃,公開挑戰(zhàn) transformer 地位。更有最新研究【13】從理論上表明,RNN 對比 Transformer 的表達(dá)力,只差一個(gè) in-context-retrieval。在這個(gè)方向的持續(xù)投入下,我們很可能會迎接一個(gè)介于 RNN 和 Transformer 之間的“新王”。
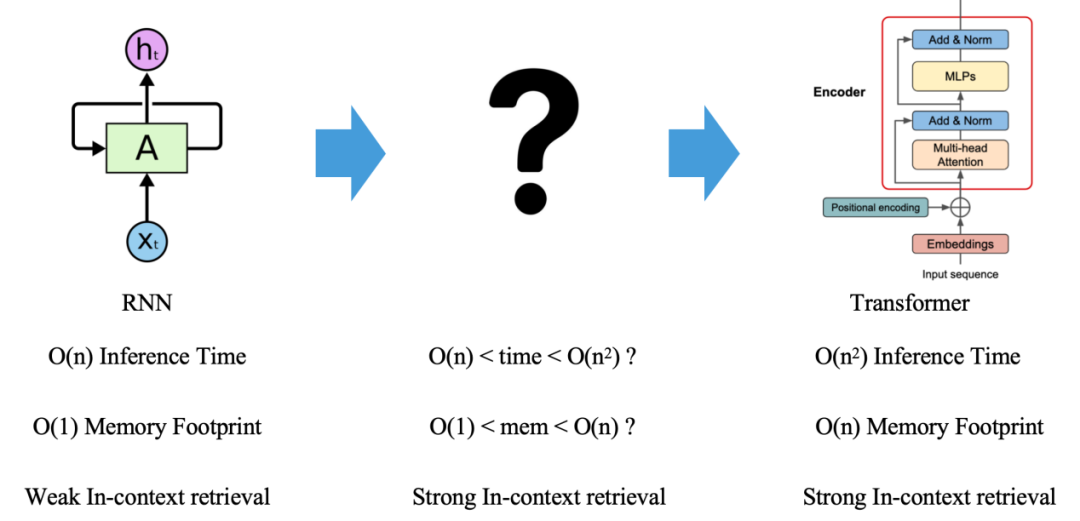
因此,算力層短時(shí)間內(nèi)的主題仍然是“半通用化”“高算力”“低能耗”。
3. 合成數(shù)據(jù)驅(qū)動新產(chǎn)業(yè)鏈
早有機(jī)構(gòu)預(yù)測,人類社會可利用訓(xùn)練數(shù)據(jù)會在 2026 年耗盡。這可能還是一個(gè)樂觀估計(jì)。光頭哥 Tibor Blaho 還曾爆料,OpenAI 用于訓(xùn)練“獵戶座“的數(shù)據(jù)中,已經(jīng)包含了由 GPT-4 和 O1 產(chǎn)出的合成數(shù)據(jù)。
這不僅是因?yàn)樽匀淮嬖诘母哔|(zhì)量文本的匱乏,還因?yàn)橹悄荏w所需的數(shù)據(jù)很可能需要顯式地蘊(yùn)含任務(wù)思考和規(guī)劃的拆解信息。然而,針對合成數(shù)據(jù)的問題,學(xué)術(shù)界早有預(yù)警,模型可能會在合成數(shù)據(jù)上的持續(xù)訓(xùn)練中崩壞【14】。
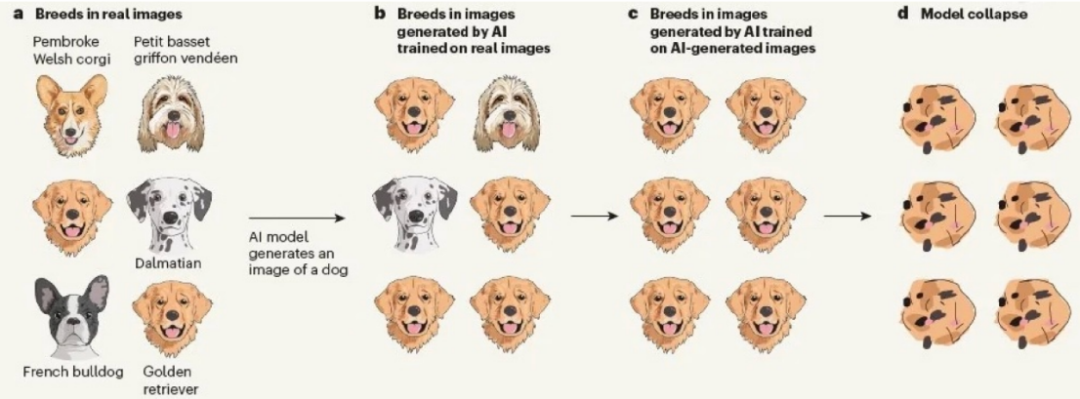
這是因?yàn)楹铣蓴?shù)據(jù)往往攜帶“錯(cuò)誤”和“幻覺”,在一些冷門的知識上尤甚。因此,合成數(shù)據(jù)的實(shí)用秘訣是“去粗取精”,需要一定程度的“人機(jī)協(xié)同”。在如何構(gòu)造大批量、高質(zhì)量的合成數(shù)據(jù),讓智能體能夠在持續(xù)地與用戶的交互中自我優(yōu)化而不是劣化,將會成為眾多無機(jī)器學(xué)習(xí)技術(shù)背景的開發(fā)者的頭號難題。
因此,面向數(shù)據(jù)進(jìn)行定制化合成、評估、測試、標(biāo)注、人機(jī)協(xié)同的“純數(shù)據(jù)”產(chǎn)業(yè),有可能會走上越來越重要的位置,不僅僅是服務(wù)于基座模型廠商。
4. 多模態(tài)對齊很可能給基座模型帶來質(zhì)的提升
最新研究發(fā)現(xiàn),在沒有預(yù)先約束和約定下,不同模態(tài)領(lǐng)域的最強(qiáng)模型正在向著某個(gè)世界模型認(rèn)知領(lǐng)域收縮【15】,AI 模型對不同概念的數(shù)字化表達(dá)(向量表征)會逐步趨同,構(gòu)建對這個(gè)世界的統(tǒng)一認(rèn)知。這也符合我們?nèi)祟悓κ澜绲恼J(rèn)知:人類通過語言文字這種符號,將不同模態(tài)的信號統(tǒng)一地表達(dá),并在腦中構(gòu)建了某種受限于當(dāng)前科技水平的統(tǒng)一模型,這是人類意識、社會溝通的前提。
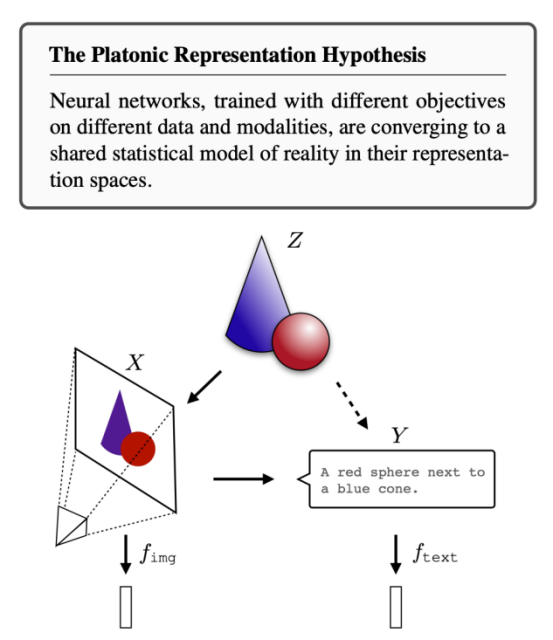
從這個(gè)角度理解,多模態(tài)大模型很可能是通向真正 AGI 的必經(jīng)之路。將多模態(tài)信號統(tǒng)一對齊,是智能體與這個(gè)世界“無障礙”交互的前提,換個(gè)新潮的詞匯,就是我們期待的“具身智能”。
誰不想擁有一臺自己專屬的“Javis” 呢?而多模態(tài)大模型的突破,也同樣依賴前文所述的算力和數(shù)據(jù)上的沉淀。
參考文獻(xiàn) 【1】https://epoch.ai/blog/can-ai-scaling-continue-through-2030 【2】Newell, A., & Simon, H. A. (1956). The Logic Theory Machine – A Complex Information Processing System. IRE Transactions on Information Theory, 2(3), 61-79. 【3】Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." nature 529.7587 (2016): 484-489. 【4】 Wei, Jason, et al. "Chain-of-thought prompting elicits reasoning in large language models." Advances in neural information processing systems 35 (2022): 24824-24837. 【5】Yao, Shunyu, et al. "Tree of thoughts: Deliberate problem solving with large language models." Advances in Neural Information Processing Systems 36 (2024). 【6】Karpas, Ehud, et al. "MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning." arXiv preprint arXiv:2205.00445 (2022). 【7】Schick, Timo, et al. "Toolformer: Language models can teach themselves to use tools." Advances in Neural Information Processing Systems 36 (2024). 【8】https://huggingface.co/spaces/mteb/leaderboard 【9】https://github.com/deep-floyd/IF 【10】https://developer.nvidia.com/blog/pushing-the-boundaries-of-speech-recognition-with-nemo-parakeet-asr-models/ 【11】Mamba:?Linear-time sequence modeling?with?selective state spaces 【12】Peng, Bo, et al. "Rwkv: Reinventing rnns for the transformer era." arXiv preprint arXiv:2305.13048 (2023). 【13】Wen, Kaiyue, Xingyu Dang, and Kaifeng Lyu. "Rnns are not transformers (yet): The key bottleneck on in-context retrieval." arXiv preprint arXiv:2402.18510 (2024). 【14】AI Models Collapse When Trained on Recursively Generated Data’ 【15】The Platonic Representation Hypothesis
-
AI
+關(guān)注
關(guān)注
87文章
33443瀏覽量
274016 -
大模型
+關(guān)注
關(guān)注
2文章
2925瀏覽量
3673 -
LLM
+關(guān)注
關(guān)注
1文章
316瀏覽量
628
原文標(biāo)題:大模型撞上“算力墻”,超級應(yīng)用的探尋之路
文章出處:【微信號:OSC開源社區(qū),微信公眾號:OSC開源社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
DeepSeek對芯片算力的影響


算智算中心的算力如何衡量?

科技云報(bào)到:要算力更要“算利”,“精裝算力”觸發(fā)大模型產(chǎn)業(yè)新變局?
浪潮信息與智源研究院攜手共建大模型多元算力生態(tài)
喜報(bào) 祝賀澎峰科技榮獲“2024中國算力卓越企業(yè)獎”

軟通動力受邀出席第六屆中國超級算力大會
聯(lián)想亮相第六屆中國超級算力大會
ETH-X超節(jié)點(diǎn):開辟AI算力約束突破的新路徑

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗(yàn)】--全書概覽
中國算力大會召開,業(yè)界首個(gè)算力高質(zhì)量評估體系發(fā)布






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論