

導(dǎo)語(yǔ):
當(dāng)AI大模型從云端下沉至終端設(shè)備,一場(chǎng)關(guān)于效率、隱私與智能化的革命悄然展開(kāi)。作為全球領(lǐng)先的無(wú)線通信模組及解決方案提供商,美格智能憑借其高算力AI模組矩陣與端側(cè)大模型部署經(jīng)驗(yàn),結(jié)合最新發(fā)布的AIMO智能體產(chǎn)品,正加速開(kāi)發(fā)DeepSeek-R1模型在端側(cè)落地應(yīng)用及端云結(jié)合整體方案,助力國(guó)產(chǎn)優(yōu)質(zhì)模型滲透千行百業(yè),共塑智能化未來(lái)。
AIMO智能體硬件加速迭代,AI硬件與大模型協(xié)同優(yōu)化
美格智能基于高通驍龍高性能計(jì)算平臺(tái)打造的AIMO智能體產(chǎn)品,集成48Tops AI算力,支持混合精度計(jì)算(INT4/FP8)與異構(gòu)計(jì)算架構(gòu)(8核CPU+Adreno GPU+Hexagon NPU),可高效承載7B參數(shù)級(jí)大模型的端側(cè)推理需求。其板載16GB LPDDR5X內(nèi)存與256GB UFS 4.0存儲(chǔ),為模型動(dòng)態(tài)加載與實(shí)時(shí)數(shù)據(jù)處理提供硬件保障。2025年美格智能將推出單顆模組算力達(dá)到100Tops的高階AI硬件,遠(yuǎn)期規(guī)劃AI模組算力超過(guò)200Tops。

美格智能已成功在高算力AI模組上部署LLaMA-2、通義千問(wèn)Qwen、ChatGLM2等大模型,驗(yàn)證了從模型壓縮(量化、剪枝)到框架適配(ONNX/TFLite)的全流程能力。美格智能自研的MEIG AI算法部署平臺(tái)、AIMO智能體、模型優(yōu)化器等,可大幅縮短模型落地周期,支持開(kāi)發(fā)者通過(guò)Python快速完成應(yīng)用開(kāi)發(fā),并支持開(kāi)發(fā)者進(jìn)行模型訓(xùn)練。
AIMO智能體內(nèi)置的高算力AI模組的異構(gòu)計(jì)算架構(gòu),具備協(xié)同加速能力,支持模型并行計(jì)算與低功耗運(yùn)行,LPDDR5X內(nèi)存提供超過(guò)60GB/s帶寬,滿足7B模型推理時(shí)的高吞吐需求。內(nèi)置專用AI加速引擎支持INT4/FP16混合精度計(jì)算,與DeepSeek-R1模型的量化格式(INT4/FP8)高度適配。
DeepSeek-R1低調(diào)亮相,蒸餾小模型超越OpenAI o1-mini
DeepSeek-R1采用強(qiáng)化學(xué)習(xí)邏輯,驅(qū)動(dòng)通過(guò)多階段RL訓(xùn)練(基礎(chǔ)模型→RL→微調(diào)迭代),DeepSeek-R1在數(shù)學(xué)、代碼、邏輯推理任務(wù)中表現(xiàn)比肩國(guó)際頂尖模型,如AIME數(shù)學(xué)競(jìng)賽準(zhǔn)確率達(dá)71%。DeepSeek-R1提供輕量化適配:DeepSeek-R1系列提供1.5B至70B參數(shù)蒸餾版本,其中7B模型經(jīng)INT4量化后僅需2-4GB存儲(chǔ),完美適配終端設(shè)備內(nèi)存限制。DeepSeek-R1的動(dòng)態(tài)思維鏈,支持?jǐn)?shù)萬(wàn)字級(jí)內(nèi)部推理過(guò)程,解決復(fù)雜問(wèn)題時(shí)能自主拆解步驟并驗(yàn)證邏輯,輸出可解釋性更強(qiáng)的結(jié)果。
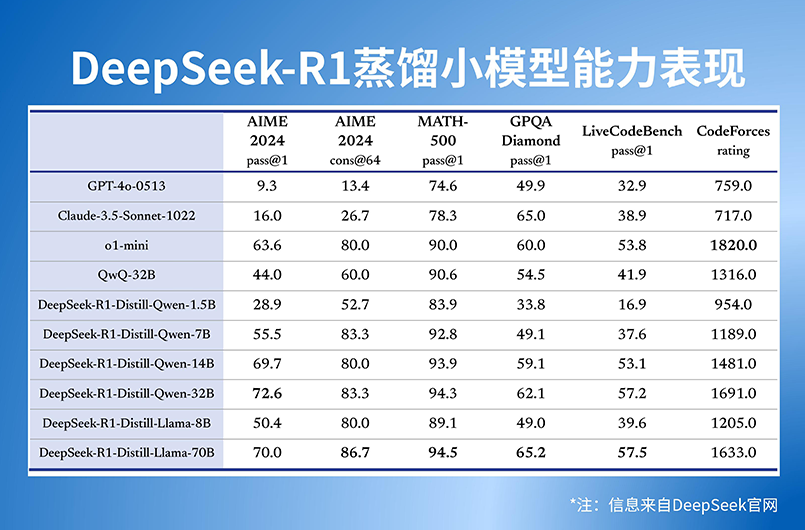
DeepSeek在開(kāi)源DeepSeek-R1-Zero和DeepSeek-R1兩個(gè)660B模型的同時(shí),通過(guò)DeepSeek-R1的輸出,蒸餾了6個(gè)小模型開(kāi)源給社區(qū),其中32B和70B模型在多項(xiàng)能力上實(shí)現(xiàn)了對(duì)標(biāo)OpenAI o1-mini的效果。除32B和70B模型能力強(qiáng)悍外,DeepSeek-R1同步開(kāi)源1.5B、7B、8B、14B等多個(gè)蒸餾小模型,極大擴(kuò)展了終端側(cè)模型部署的可選性,并支持用戶進(jìn)行“模型蒸餾”,明確允許用戶利用模型輸出、通過(guò)模型蒸餾等方式訓(xùn)練其他模型。
以DeepSeek-R1 7B模型的端側(cè)適配性舉例,該模型具備輕量化設(shè)計(jì)特征,經(jīng)蒸餾和量化后模型體積壓縮至2-4GB,很好的匹配移動(dòng)端存儲(chǔ)限制。模型具備低延遲推理能力,在高算力模組平臺(tái)上,可實(shí)現(xiàn)10-20 tokens/s的生成速度。模型支持分塊推理和稀疏計(jì)算,結(jié)合美格智能高算力AI模組的能效優(yōu)化,能實(shí)現(xiàn)極低的功耗控制。
算力與模型的技術(shù)迭代,AI應(yīng)用的iPhone時(shí)刻即將帶來(lái)
美格智能研發(fā)團(tuán)隊(duì)結(jié)合AIMO智能體、高算力AI模組的異構(gòu)計(jì)算能力,結(jié)合多款模型量化、部署、功耗優(yōu)化Know-how,正在加速開(kāi)發(fā)DeepSeek-R1模型在端側(cè)落地應(yīng)用及端云結(jié)合整體方案。

?超低功耗
首先持續(xù)對(duì)DeepSeek-R1模型的推理延遲進(jìn)行優(yōu)化,保證模型在高算力模組軟硬件環(huán)境下的超低功耗運(yùn)行。
?開(kāi)發(fā)工具鏈
不斷進(jìn)行工具鏈打通,模組內(nèi)嵌的SNPE引擎直接支持DeepSeek-R1模型的ONNX/TFLite格式,大模型適配周期將大幅縮短。
?端云協(xié)同
結(jié)合動(dòng)態(tài)卸載技術(shù),根據(jù)任務(wù)復(fù)雜度自動(dòng)分配端側(cè)與邊緣計(jì)算資源,保障實(shí)時(shí)性與能效平衡。為客戶提供端云協(xié)同模板,面向開(kāi)發(fā)者提供動(dòng)態(tài)任務(wù)分配框架,簡(jiǎn)單配置即可實(shí)現(xiàn)“本地優(yōu)先,云端兜底”。
通過(guò)高階AI硬件與DeepSeek-R1模型的能力結(jié)合,將突破端側(cè)AI的能力邊界。7B模型支持長(zhǎng)文本理解、代碼生成等傳統(tǒng)端側(cè)小模型無(wú)法完成的任務(wù)。多模態(tài)融合能力,高算力AI模組的ISP+AI能力結(jié)合DeepSeek-R1模型,可實(shí)現(xiàn)端側(cè)圖文問(wèn)答、視頻內(nèi)容解析(如實(shí)時(shí)字幕生成)。個(gè)性化持續(xù)學(xué)習(xí),通過(guò)AI模組的邊緣計(jì)算能力,支持聯(lián)邦學(xué)習(xí)框架下的本地模型微調(diào)(如用戶習(xí)慣適配)。
在算力+模型的不斷迭代背后,端側(cè)AI及端云協(xié)同的商業(yè)模式和商業(yè)競(jìng)爭(zhēng)力都將面臨重構(gòu),DeepSeek-R1的發(fā)布,更是會(huì)極大刺激AI下游應(yīng)用,如工業(yè)智能化、汽車Agent、機(jī)器人、個(gè)人大模型等應(yīng)用場(chǎng)景的指數(shù)級(jí)增長(zhǎng),AI應(yīng)用即將迎來(lái)屬于自己的iPhone時(shí)刻。
?基于DeepSeek-R1的AI Agent開(kāi)發(fā)應(yīng)用
結(jié)合美格智能自研的AIMO智能體及DeepSeek-R1模型的基礎(chǔ)能力,開(kāi)發(fā)面向工業(yè)智能化、座艙智能體、智能無(wú)人機(jī)、機(jī)器人等領(lǐng)域的AI Agent應(yīng)用。
?端側(cè)AI能力包
推出面向AI場(chǎng)景的訂閱服務(wù),針對(duì)中小型的B端或C端客戶,推出“端側(cè)AI能力包”,與大模型廠商合作,針對(duì)Token輸入/輸出數(shù)量、不同類型模型調(diào)用、流量費(fèi)用等領(lǐng)域,推出一體化端側(cè)AI Turn-key方案。
?智能化硬件增值
商業(yè)模式方面,各類高AI配置硬件疊加端側(cè)模型加載或云端模型接入,為高算力硬件帶來(lái)更多智能化增值。
?自建GPU服務(wù)器與個(gè)性化專屬大模型開(kāi)發(fā)
美格研發(fā)團(tuán)隊(duì)持續(xù)拓展通用模型的部署通路,并不斷向客戶開(kāi)放相關(guān)教程和源代碼,并且以最新的高算力計(jì)算平臺(tái)搭建GPU服務(wù)器,可用于端側(cè)模型訓(xùn)練和支持客戶開(kāi)發(fā)專屬大模型,結(jié)合DeepSeek-R1及其寬松、開(kāi)放式的MIT授權(quán)協(xié)議,千行百業(yè)的個(gè)性化模型開(kāi)發(fā)和應(yīng)用即將爆發(fā)。
2025年,端側(cè)AI、端云協(xié)同等各類AI應(yīng)用的iPhone時(shí)刻將加速到來(lái)。DeepSeek-R1的出現(xiàn),某種程度上改變了我們對(duì)于Scale的認(rèn)知,但也不會(huì)帶來(lái)云端算力的需求減少甚至崩塌,相反優(yōu)質(zhì)模型對(duì)于AI應(yīng)用場(chǎng)景的極大刺激,也會(huì)推動(dòng)云端算力需求的提升,端側(cè)不斷進(jìn)化,云端負(fù)責(zé)兜底,端云結(jié)合終將是不變的方向。
美格智能也將持續(xù)以高算力AI模組、AI Agent應(yīng)用、大模型部署服務(wù)、端側(cè)AI服務(wù)整體解決方案為基石,攜手大模型廠商、生態(tài)伙伴等不斷推動(dòng)類似DeepSeek-R1等優(yōu)秀模型的應(yīng)用拓展,讓普惠、自主的高階AI實(shí)現(xiàn)應(yīng)有的社會(huì)價(jià)值。
-
AI
+關(guān)注
關(guān)注
87文章
32370瀏覽量
271500 -
智能體
+關(guān)注
關(guān)注
1文章
192瀏覽量
10711 -
美格智能
+關(guān)注
關(guān)注
2文章
260瀏覽量
11267 -
大模型
+關(guān)注
關(guān)注
2文章
2767瀏覽量
3423 -
DeepSeek
+關(guān)注
關(guān)注
1文章
592瀏覽量
324
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
MWC 2025|美格智能發(fā)布由高通技術(shù)賦能的全新AIMO Pro,搭載DeepSeek的48 TOPS高算力專屬AI智能體

RK3588開(kāi)發(fā)板上部署DeepSeek-R1大模型的完整指南
聯(lián)想moto手機(jī)集成DeepSeek-R1大模型
了解DeepSeek-V3 和 DeepSeek-R1兩個(gè)大模型的不同定位和應(yīng)用選擇
超星未來(lái)驚蟄R1芯片適配DeepSeek-R1模型
Deepseek R1大模型離線部署教程

廣汽ADiGO SENSE端云一體大模型與DeepSeek-R1大模型完成深度融合
AIBOX 全系產(chǎn)品已適配 DeepSeek-R1

軟通動(dòng)力天璇MaaS融合DeepSeek-R1,引領(lǐng)企業(yè)智能化轉(zhuǎn)型
deepin UOS AI接入DeepSeek-R1模型
芯動(dòng)力神速適配DeepSeek-R1大模型,AI芯片設(shè)計(jì)邁入“快車道”!

網(wǎng)易有道全面接入DeepSeek-R1大模型
原生鴻蒙版小藝App上架DeepSeek-R1, AI智慧體驗(yàn)更豐富
中軟國(guó)際JointPilot平臺(tái)上線DeepSeek-R1模型
CES 2025 | 美格智能創(chuàng)新發(fā)布AI智能體產(chǎn)品AIMO






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論