 2025年Next Token Prediction范式會統一多模態嗎
2025年Next Token Prediction范式會統一多模態嗎
訓練方法與推理策略
性能評測體系
現存挑戰與未來方向
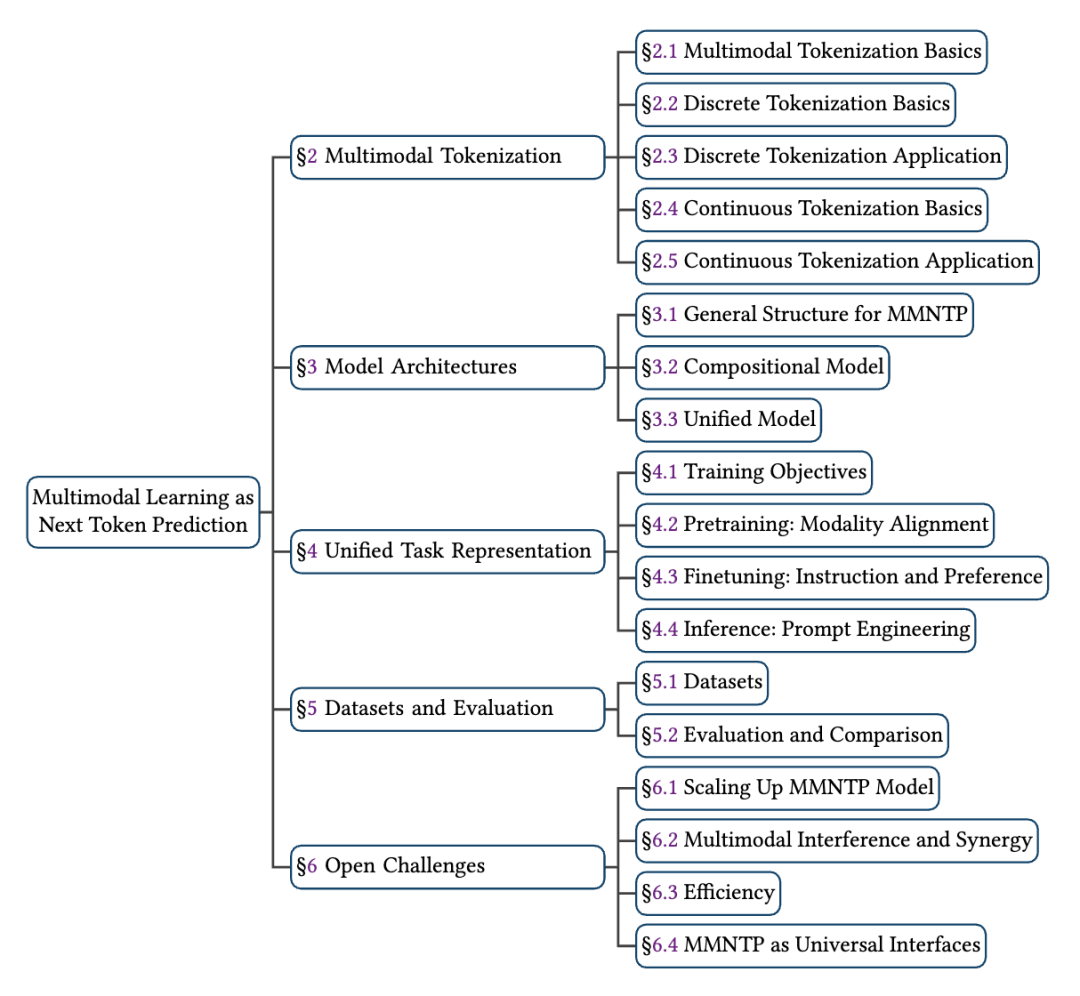
綜述的完整目錄如下:

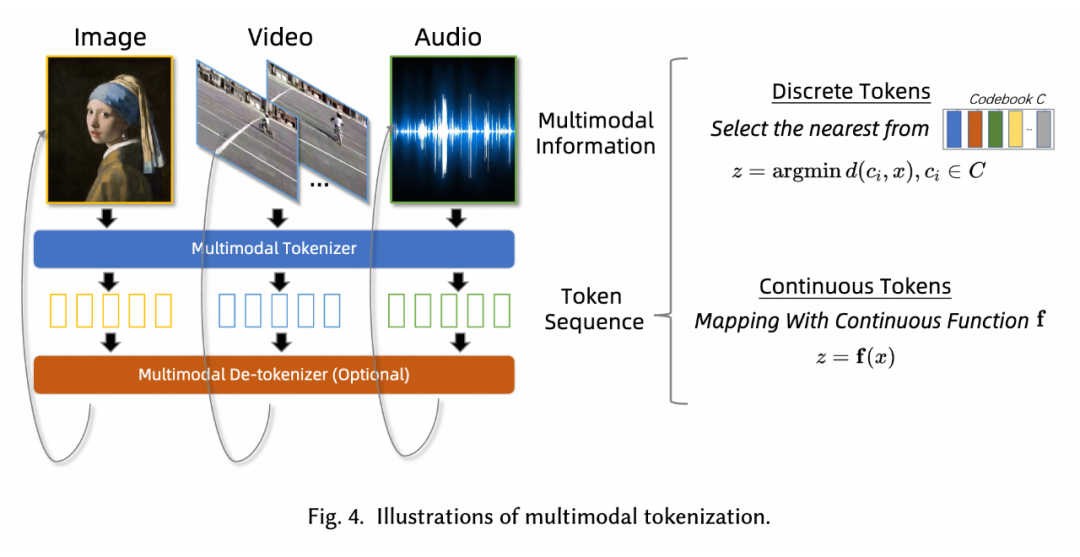
多模態的 Tokenization
我們認為多模態的 Tokenization 是 MMNTP 的基石和最重要的部分,它將各種模態的信息(如圖像、視頻和音頻片段)分解為最小的單元序列(Token),以便 Transformer 結構為基礎的 NTP 模型學習。
Tokenization 方法可以分為離散(Discrete Tokenization)和連續(Continuous Tokenization)兩種。離散標記化通過量化將原始信息映射到有限的離散空間,而連續標記化則不涉及量化,保留了數據的連續性質。下面的圖給出了兩種方式的示意圖。
2.1 Tokenizer 訓練方法
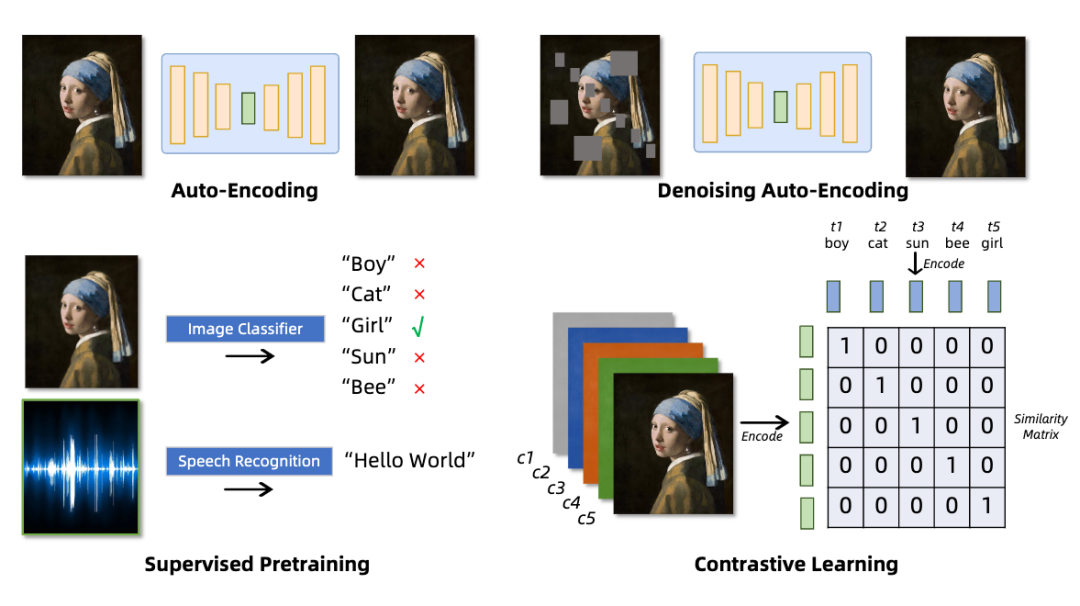
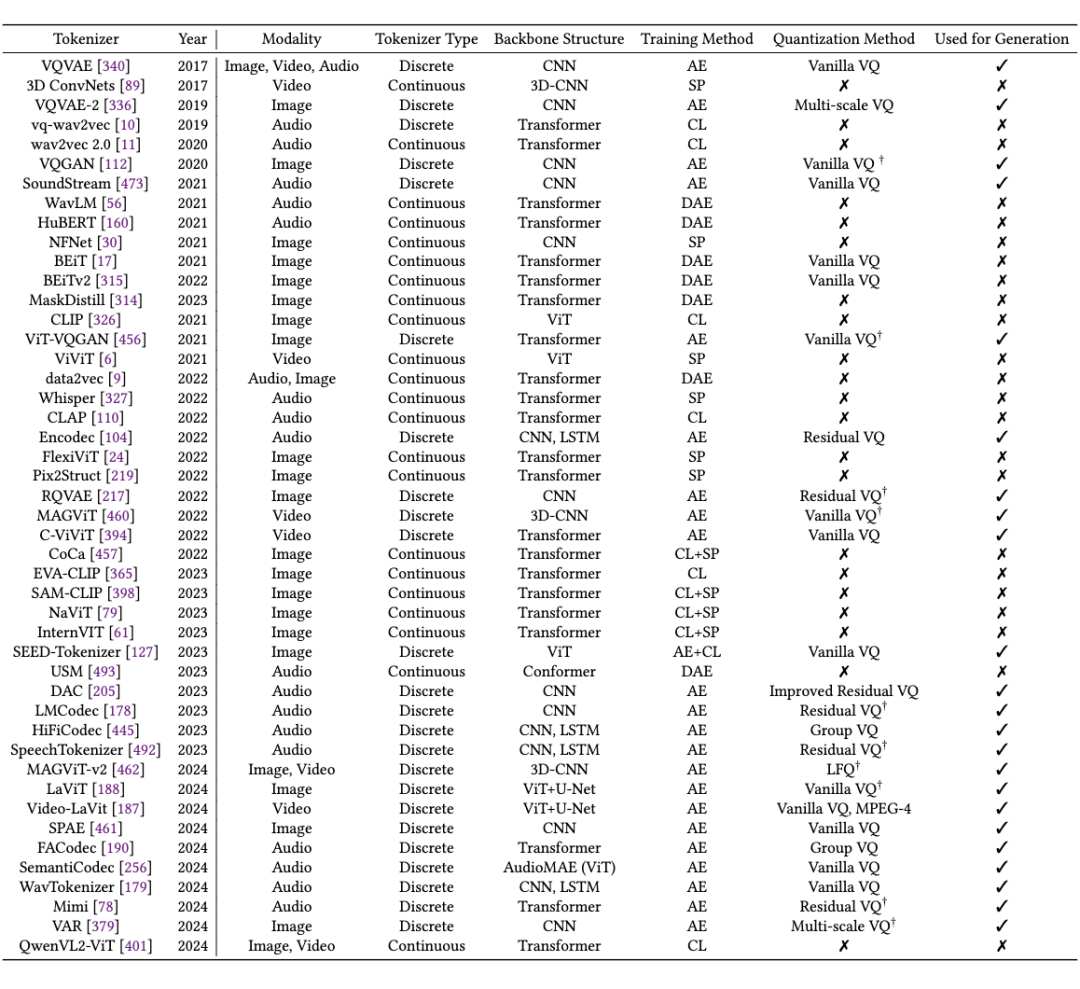
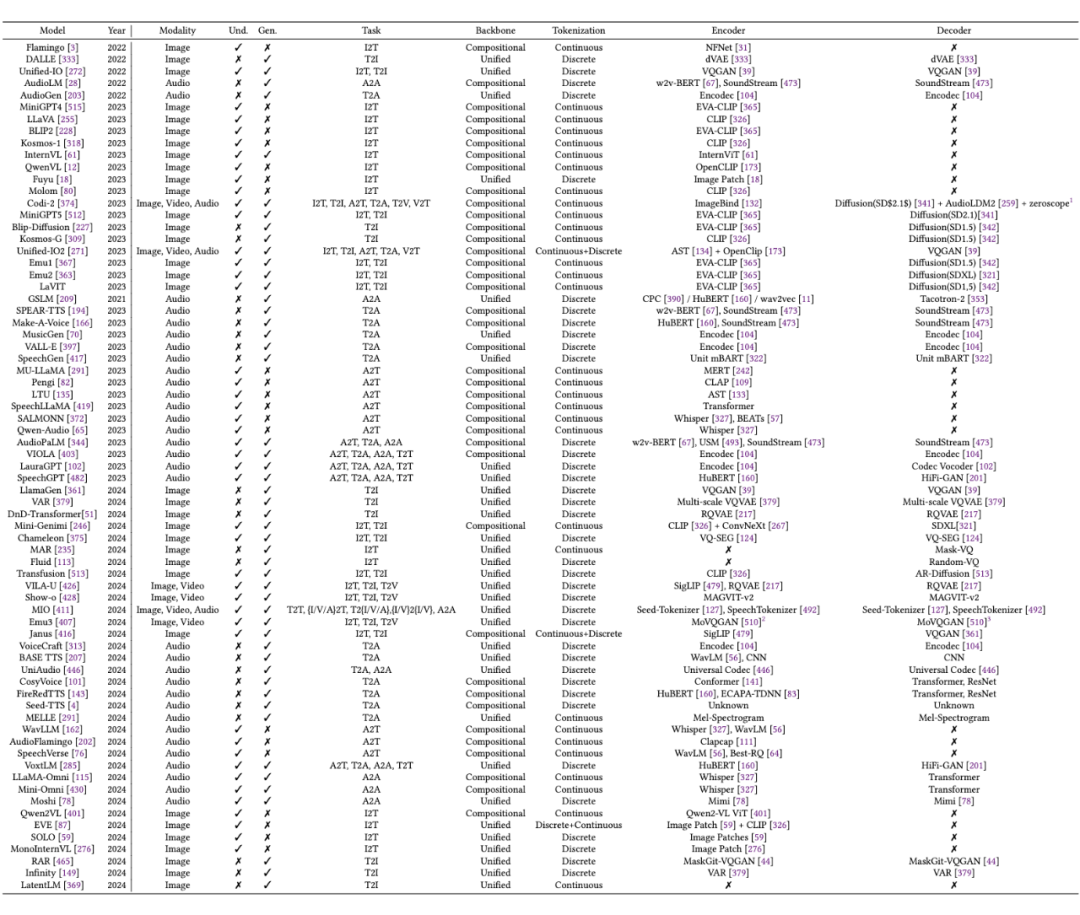
本節針對圖片,視頻,音頻領域的 Tokenization 訓練方法進行了詳細的梳理和比較。首先總結了幾種常見的訓練方法,例如對比學習,自編碼器等,以及這些方法在不同模態上的應用與針對不同模態特點的改進,并按照不同的訓練方法歸納整理了不同類型的 Tokenizers,如下表所示:
我們以表示能力(representation)和重建能力(reconstruction)為基點,重點討論了 Tokenizers 在訓練時存在的挑戰,例如離散型編碼器存在的編碼表塌陷,信息損失的問題以及一些改進措施例如 FSQ,LFQ 等方案,以及以 CLIP 為代表的連續型編碼器中主要存在的語義對齊,編碼效率,以及對于不同模態的數據,大家提出了哪些針對性的改進措施。

MMNTP 模型
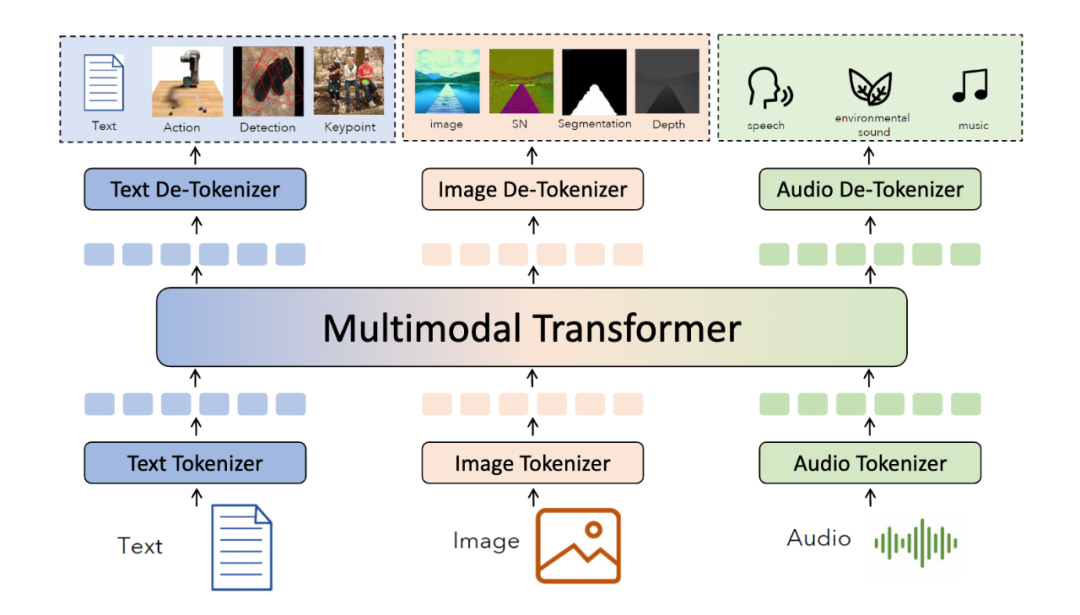
MMNTP 模型一般結構如上圖所示,它主要由骨干模型(一般是一個 Transformer 模型),以及不同模態的 Tokenizer 與 De-Tokenizer 組成。Tokenizer將不同模態的信息轉換為 Token 序列,De-Tokenizer 則將 Token 序列轉換為原始模態的信息。
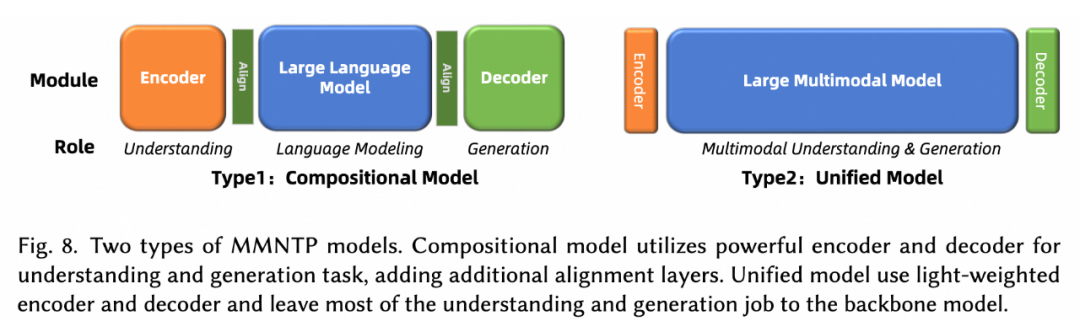
如上圖所示,我們將 MMNTP 模型進一步分為兩類,組合式(Compositional)和統一(Unified)式。組合模型依賴于強大的外部編碼器例如 CLIP 和解碼器例如 SD3 來理解和生成多模態信息,而統一模型則使用輕量級的編碼器和解碼器例如 VQVAE,將大部分理解和生成任務交給骨干模型。本文對這兩種模型結構進行了詳細討論,并比較了它們的優缺點。
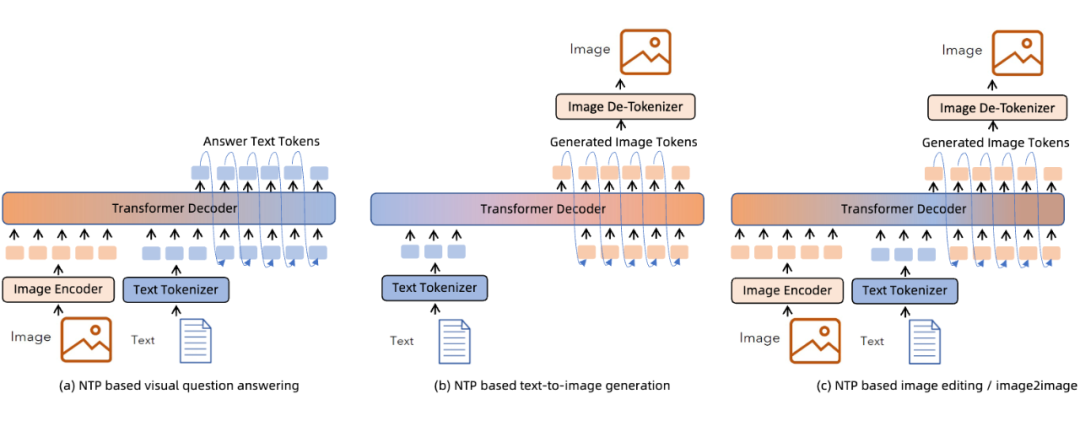
對于不同的多模態任務來說,MMNTP 模型可以以一種統一的方式處理不同任務,區別之處在于不同任務的輸入輸出不同。上圖以圖片模態為例子,列出來了同一個 MMNTP 模型結構如何進行圖片理解例如 VQA,圖片生成,以及基于文字指令的圖片編輯任務。
只需要替換輸入輸出的組合形式,同一個模型架構就可以完成不同的任務,這體現了 MMNTP 模型在多模態任務上的統一性。本文針對圖片,視頻,音頻模態的 MMNTP 模型進行了詳細的討論,并根據結構類型進行了梳理,如下表所示。

訓練范式
4.1 訓練任務的類型
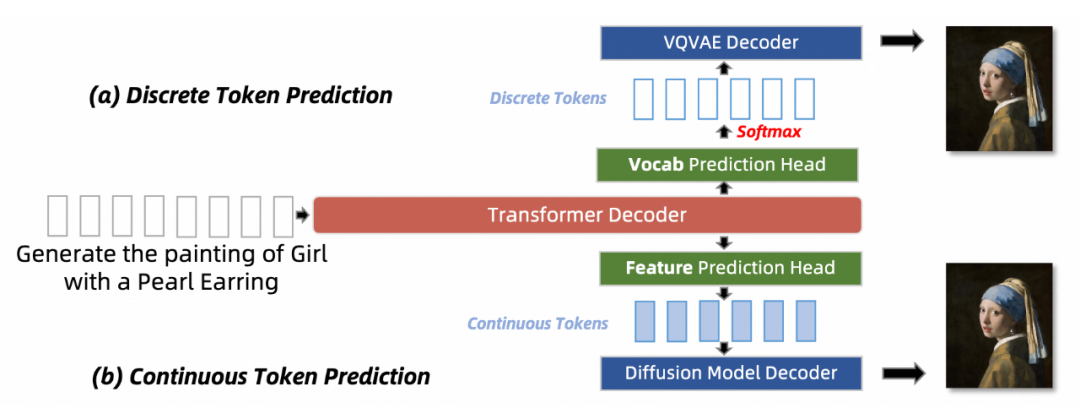
一旦將不同模態的內容轉化為序列化的標 Tokens,就可以使用統一的骨 MMNTP 模型來訓練,以解決各種理解和生成任務。
本文將訓練任務按照生成的 Token 類型不同分為兩類,離散 Token 預測和連續 Token 預測。二者的區別在于預測的 token 是離散的還是連續的,這會對應不同的訓練任務,以及特殊的輸出頭的結構。
例如多模態理解任務往往以語言作為輸出,則需要使用語言模型頭作為輸出頭,進行離散 Token 預測。如果將 Diffusion 模型和 NTP 模型結合,則需要使用 Diffusion 模型頭作為輸出頭,進行連續 Token 預測。
4.2 訓練階段
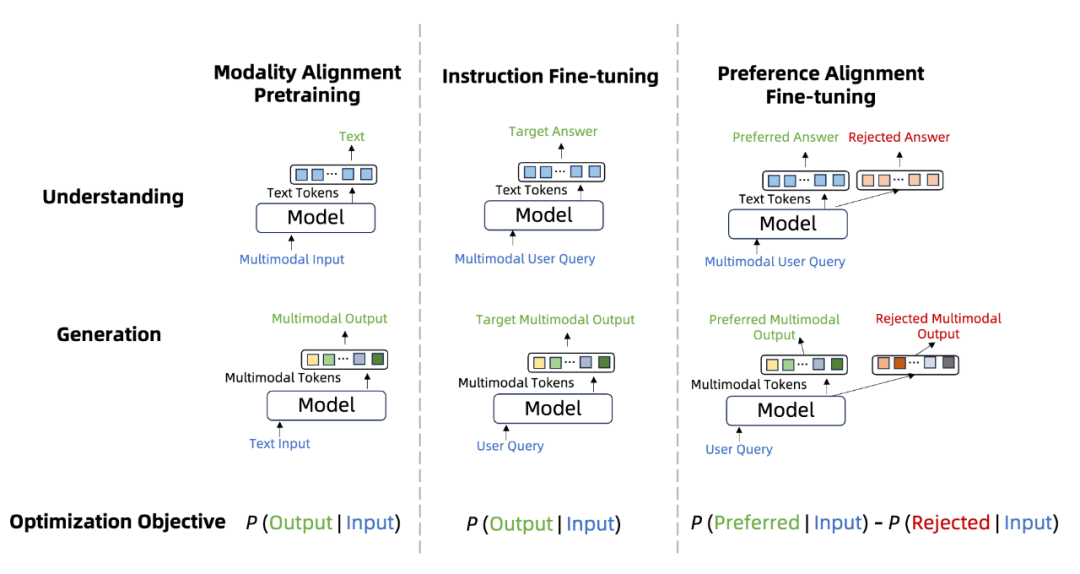
和語言模型類似,MMNTP 模型的訓練也可以分為三個階段,如上圖所示,分別是模態對齊預訓練,指令微調和偏好學習。
這里的預訓練階段,通常指的是在多模態數據-文本對數據上進行預訓練,以將不同模態的信息對齊到語言空間。指令微調階段是針對不同的下游任務,例如理解和生成類任務,用標注好的數據進行訓練。偏好學習在 MMNTP 模型中的研究剛剛起步,主要將模型的輸出和人類的偏好進行對齊。
本文詳細這三個階段的相關研究工作,并根據任務類型進行了歸納整理。
4.3 測試時的Prompt工程
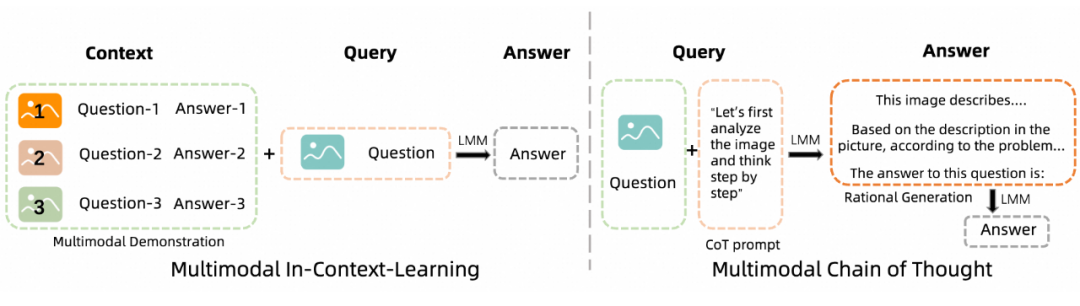
Prompt 工程是提升 LLM 模型效果的重要手段,在 MMNTP 模型中,借助了 LLM 繼基座模型的能力,Prompt 工程同樣重要。本文對 MMNTP 模型中的 Prompt 工程進行了詳細的討論,如上圖所示,分為多模態的上下文學習(Multimodal In-Context Learning)和多模態思維鏈(Multimodal Chain-of-Thought)兩種方法。

如上圖所示,多模態的上下文學習指的是在輸入中加入多模態任務的例子,以幫助模型更好地理解任務。多模態思維鏈則是指在輸入中加入一些思維鏈的提示,例如“感知”,“推理過程”等,以促使模型更好地進行多模態推理。我們將這些方法進行整理,如下表所示。

訓練數據集與性能評測
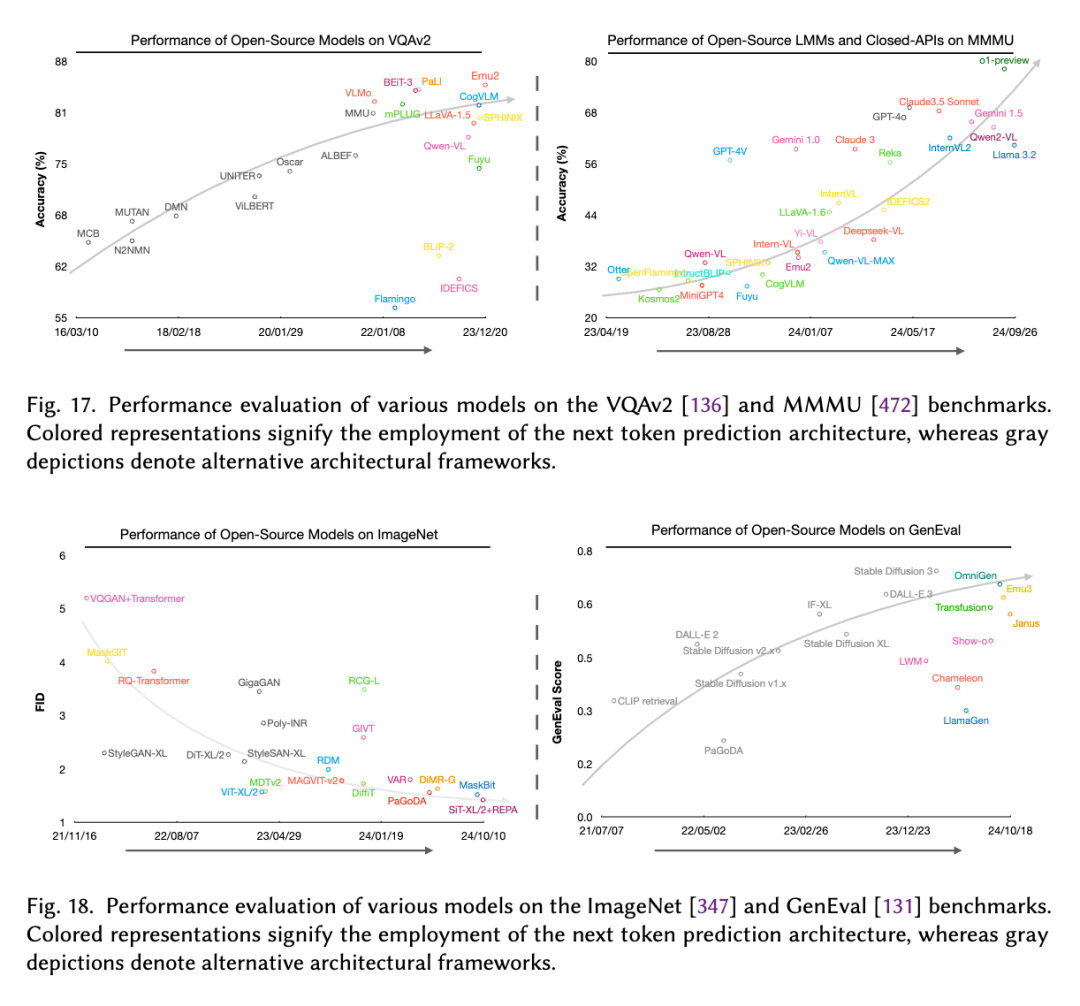
在綜述中,我們還對 MMNTP 模型的訓練數據集進行了詳細的討論,包括數據集的構建,數據集的規模,以及數據集的多樣性。同時,我們也比較了 NTP 模型和非 NTP 模型在多模態任務上的表現,如上圖所示,在大規模理解任務例如 VQAv2,MMMU上,NTP 模型表現全面優于非 NTP 模型。
在生成任務評測數據例如 Imagenet,GenEval,我們觀察到 NTP 模型在和純 Diffusion 取得了不相上下的效果,甚至在某些任務上表現更好,這展示了 NTP 模型在統一不同多模態任務上的潛力。

存在的挑戰
本文提出了四個目前尚未解決的挑戰,主要源于 MMNTP 訓練范式。這些挑戰包括:
如何更好地利用無監督的多模態數據來擴展 MMNTP 模型
克服多模態干擾并增強協同作用
提高 MMNTP 模型的訓練和推理效率
將 MMNTP 作為更廣闊任務的通用接口。
這些挑戰的解決對于 MMNTP 范式實現多模態智能的發展至關重要。
-
編碼器
+關注
關注
45文章
3663瀏覽量
135012 -
NTP
+關注
關注
1文章
176瀏覽量
13940
原文標題:2025年Next Token Prediction范式會統一多模態嗎?
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

麻省理工科技評論:2025年AI領域突破性技術

商湯日日新多模態大模型權威評測第一
2025電子設計與制造技術研討會
一文理解多模態大語言模型——下

一文理解多模態大語言模型——上

利用OpenVINO部署Qwen2多模態模型
云知聲山海多模態大模型UniGPT-mMed登頂MMMU測評榜首

Meta發布多模態LLAMA 3.2人工智能模型
云知聲推出山海多模態大模型
統一多云管理平臺怎么用?
李未可科技正式推出WAKE-AI多模態AI大模型






 工商網監
工商網監
評論