

本文轉(zhuǎn)自:Coggle數(shù)據(jù)科學(xué)
隨著大規(guī)模語(yǔ)言模型(LLM)在性能、成本和應(yīng)用前景上的快速發(fā)展,越來(lái)越多的團(tuán)隊(duì)開(kāi)始探索如何自主訓(xùn)練LLM模型。然而,是否從零開(kāi)始訓(xùn)練一個(gè)LLM,并非每個(gè)組織都適合。本文將根據(jù)不同的需求與資源,幫助你梳理如何在構(gòu)建AI算法應(yīng)用時(shí)做出合適的決策。
訓(xùn)練LLM的三種選擇
在構(gòu)建AI算法應(yīng)用時(shí),首先需要決定是使用現(xiàn)有的商用API,還是開(kāi)源模型,或者選擇完全自主訓(xùn)練一個(gè)LLM。每種選擇有其獨(dú)特的優(yōu)勢(shì)與劣勢(shì)。
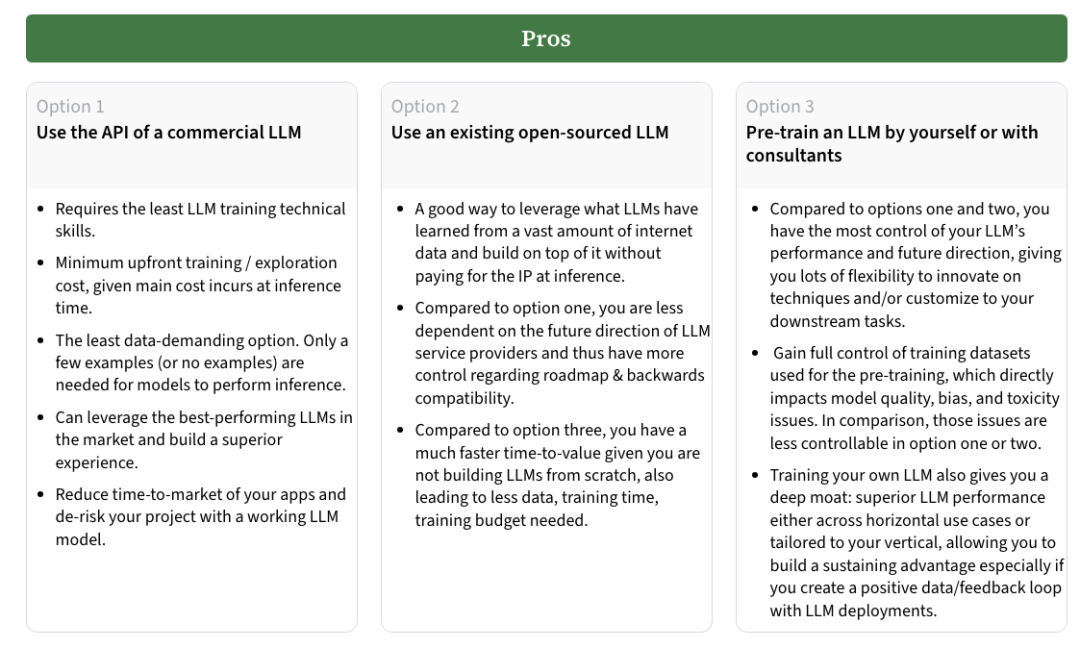
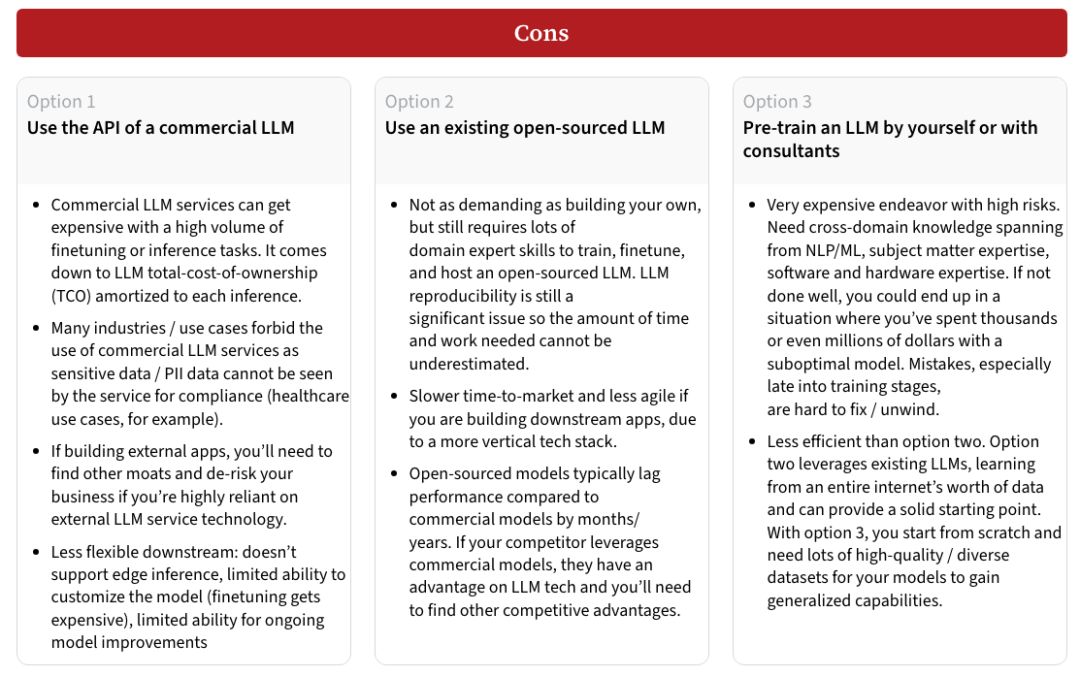
選項(xiàng)一:使用商用LLM API
這種方法最適合缺乏深厚技術(shù)背景的團(tuán)隊(duì),或者希望盡快構(gòu)建應(yīng)用的組織。商用API的優(yōu)點(diǎn)在于,無(wú)需進(jìn)行繁瑣的模型訓(xùn)練,團(tuán)隊(duì)可以直接使用現(xiàn)成的、高性能的LLM服務(wù)來(lái)執(zhí)行推理任務(wù)。它還允許使用最先進(jìn)的LLM技術(shù),節(jié)省了大量的開(kāi)發(fā)時(shí)間與成本。通過(guò)API,你只需為推理計(jì)算付費(fèi),且不需要處理數(shù)據(jù)集和模型訓(xùn)練過(guò)程中的復(fù)雜性。
然而,這種方法也有明顯的缺點(diǎn)。首先,成本問(wèn)題是一個(gè)關(guān)鍵考量,高頻次的推理任務(wù)或微調(diào)可能導(dǎo)致不小的費(fèi)用。其次,數(shù)據(jù)隱私和合規(guī)性也是商用API的限制之一,某些行業(yè)(如醫(yī)療健康、金融等)可能無(wú)法將敏感數(shù)據(jù)上傳至外部服務(wù)。此外,商用API的定制性較差,模型微調(diào)的空間有限,如果需求有所變化,靈活性較低。
選項(xiàng)二:使用開(kāi)源LLM
與商用API相比,開(kāi)源LLM提供了更多的定制和控制權(quán)。你可以基于開(kāi)源模型進(jìn)行微調(diào),或者在此基礎(chǔ)上繼續(xù)進(jìn)行預(yù)訓(xùn)練。這種方法適合有一定技術(shù)實(shí)力的團(tuán)隊(duì),尤其是當(dāng)項(xiàng)目的數(shù)據(jù)隱私要求較高時(shí)。使用開(kāi)源模型,你可以完全控制訓(xùn)練數(shù)據(jù)和模型的演化方向,避免了商用API服務(wù)帶來(lái)的依賴風(fēng)險(xiǎn)。
然而,開(kāi)源LLM的性能通常落后于商用模型,有時(shí)需要幾個(gè)月甚至更長(zhǎng)時(shí)間才能趕上最新的商業(yè)技術(shù)。訓(xùn)練和微調(diào)開(kāi)源模型也需要投入較大的計(jì)算資源與專業(yè)知識(shí),因此時(shí)間和資源的成本不可忽視。
選項(xiàng)三:完全自主訓(xùn)練LLM
當(dāng)組織擁有強(qiáng)大的技術(shù)團(tuán)隊(duì)并且預(yù)算充足時(shí),完全從零開(kāi)始訓(xùn)練一個(gè)LLM可以提供最大的靈活性。自主訓(xùn)練不僅可以讓你定制模型架構(gòu)(如選擇不同的tokenizer、調(diào)整模型維度、頭數(shù)、層數(shù)等),還可以完全控制訓(xùn)練數(shù)據(jù),以最大限度地減少模型偏差和毒性問(wèn)題。這種方法適合那些將LLM作為核心技術(shù)和競(jìng)爭(zhēng)優(yōu)勢(shì)的公司,尤其是在數(shù)據(jù)和算法方面有顯著創(chuàng)新的情況下。
但與此同時(shí),完全自主訓(xùn)練LLM也是最昂貴且風(fēng)險(xiǎn)較高的選擇。模型訓(xùn)練需要大量的計(jì)算資源和跨領(lǐng)域的技術(shù)能力,若不慎,可能導(dǎo)致訓(xùn)練失敗,尤其是在訓(xùn)練的后期,錯(cuò)誤難以修正。而且,與開(kāi)源模型相比,完全從頭開(kāi)始訓(xùn)練需要更為龐大的高質(zhì)量、多樣化的數(shù)據(jù)集,否則難以獲得具備廣泛能力的模型。
規(guī)模法則(Scaling Laws)
LLM規(guī)模的歷史演變
自2020年OpenAI首次提出LLM規(guī)模法則以來(lái),關(guān)于如何提高模型性能的觀點(diǎn)經(jīng)歷了顯著的變化。OpenAI的研究表明,增加模型的規(guī)模比增加數(shù)據(jù)量更為重要。這一理論在一定時(shí)間內(nèi)是成立的,尤其是在模型訓(xùn)練初期。然而,隨著研究的深入,尤其是2022年DeepMind提出的新見(jiàn)解,關(guān)于模型規(guī)模和數(shù)據(jù)規(guī)模的關(guān)系發(fā)生了根本性的轉(zhuǎn)變。
DeepMind提出,之前的LLM模型訓(xùn)練還遠(yuǎn)遠(yuǎn)不夠,它們的數(shù)據(jù)量和計(jì)算資源未能達(dá)到最佳水平。具體來(lái)說(shuō),現(xiàn)有的LLM模型并沒(méi)有在足夠的數(shù)據(jù)上進(jìn)行充分的訓(xùn)練。這一觀點(diǎn)通過(guò)DeepMind提出的模型——Chinchilla得到了驗(yàn)證。Chinchilla的規(guī)模只有Gopher模型的四分之一,但它的訓(xùn)練數(shù)據(jù)量卻是Gopher的4.6倍。在這種縮小模型規(guī)模的情況下,Chinchilla卻取得了更好的性能,超過(guò)了Gopher和其他同類模型。
新的規(guī)模法則:模型大小與數(shù)據(jù)量的平衡基于Chinchilla的實(shí)驗(yàn)結(jié)果,DeepMind提出了一個(gè)新的規(guī)模法則:模型大小和訓(xùn)練數(shù)據(jù)的大小應(yīng)該按相同的比例增加,才能獲得最佳的模型表現(xiàn)。如果你的計(jì)算資源增加了10倍,你應(yīng)該將模型的大小增加3.1倍,并且數(shù)據(jù)量也要增加3.1倍;如果計(jì)算資源增加了100倍,模型和數(shù)據(jù)的大小都應(yīng)當(dāng)增加10倍。這種方式能夠更好地平衡計(jì)算資源、模型復(fù)雜度和訓(xùn)練數(shù)據(jù)量,從而實(shí)現(xiàn)更優(yōu)的訓(xùn)練效果。
簡(jiǎn)而言之,當(dāng)前的最佳實(shí)踐建議,在選擇訓(xùn)練數(shù)據(jù)集時(shí),首先要根據(jù)數(shù)據(jù)的大小來(lái)確定最適合的模型規(guī)模。DeepMind稱為Chinchilla-Optimal模型的訓(xùn)練方法,是根據(jù)訓(xùn)練數(shù)據(jù)量來(lái)優(yōu)化模型的大小。對(duì)于數(shù)據(jù)規(guī)模和模型規(guī)模的組合,最佳做法是基于訓(xùn)練計(jì)算預(yù)算和推理延遲需求來(lái)做出決策。
過(guò)小或過(guò)大的模型:何時(shí)調(diào)整?在規(guī)模法則中,存在著一個(gè)最優(yōu)點(diǎn),即模型的大小和訓(xùn)練數(shù)據(jù)的大小之間的最佳平衡。當(dāng)模型的大小太小(即處于曲線的左側(cè))時(shí),增加模型的規(guī)模并減少數(shù)據(jù)量的需求是有益的。而當(dāng)模型太大(處于曲線的右側(cè))時(shí),減少模型的規(guī)模并增加數(shù)據(jù)量反而會(huì)帶來(lái)更好的效果。最佳的模型通常位于曲線的最低點(diǎn)——即Chinchilla-Optimal點(diǎn)。在實(shí)際訓(xùn)練過(guò)程中,你可能會(huì)面臨以下幾種情形:
模型過(guò)小:如果模型規(guī)模過(guò)小,而你有充足的訓(xùn)練數(shù)據(jù),那么擴(kuò)展模型的規(guī)模并且增加數(shù)據(jù)量,會(huì)提升性能。
- 模型過(guò)大:如果模型規(guī)模過(guò)大,且數(shù)據(jù)量相對(duì)不足,則縮小模型規(guī)模并增加數(shù)據(jù)量可能會(huì)帶來(lái)更好的性能提升。
訓(xùn)練FLOPs和訓(xùn)練tokens的最佳配置DeepMind的研究還提供了一些數(shù)據(jù),展示了不同模型規(guī)模下,訓(xùn)練所需的計(jì)算量(FLOPs)和訓(xùn)練tokens的最優(yōu)配置。這些數(shù)據(jù)為開(kāi)發(fā)者提供了一個(gè)參考框架,幫助他們根據(jù)實(shí)際計(jì)算資源和數(shù)據(jù)集的規(guī)模,選擇最適合的模型。
通過(guò)這些數(shù)據(jù),你可以更清晰地理解,不同大小的模型在計(jì)算資源與訓(xùn)練數(shù)據(jù)的需求之間的平衡。訓(xùn)練FLOPs(每次操作所需的浮點(diǎn)運(yùn)算數(shù))與訓(xùn)練tokens(經(jīng)過(guò)token化處理后的訓(xùn)練數(shù)據(jù)量)之間的關(guān)系,能夠幫助你更好地預(yù)測(cè)訓(xùn)練的需求,合理分配計(jì)算資源。
如何應(yīng)用這些Scaling Laws到訓(xùn)練中?理解了這些理論后,如何在實(shí)際訓(xùn)練中應(yīng)用這些Scaling Laws呢?以下是幾個(gè)關(guān)鍵步驟:
選擇合適的數(shù)據(jù)集:首先需要明確你的應(yīng)用場(chǎng)景和數(shù)據(jù)集。如果數(shù)據(jù)集很小,可能不適合訓(xùn)練一個(gè)大規(guī)模的模型;如果數(shù)據(jù)集龐大,可以考慮訓(xùn)練更大規(guī)模的模型,以充分利用數(shù)據(jù)的潛力。
確定模型規(guī)模:根據(jù)數(shù)據(jù)集的大小和計(jì)算預(yù)算,使用Chinchilla-Optimal方法來(lái)決定模型的規(guī)模。確保你的模型規(guī)模與數(shù)據(jù)量之間保持一致,避免過(guò)度或不足的訓(xùn)練。
計(jì)算資源預(yù)算:在決定模型規(guī)模和數(shù)據(jù)量之后,你需要確保有足夠的計(jì)算資源來(lái)支持訓(xùn)練過(guò)程。這涉及到計(jì)算能力的選擇——從硬件設(shè)備(如TPU或GPU)到實(shí)際訓(xùn)練過(guò)程中的分布式計(jì)算能力。
推理延遲的考慮:如果你的應(yīng)用需要低延遲推理,模型的大小與推理時(shí)間之間的關(guān)系也是需要考慮的。通常,大模型的推理速度較慢,因此可能需要對(duì)模型進(jìn)行優(yōu)化或采用更小的模型。
- 持續(xù)監(jiān)控與調(diào)優(yōu):訓(xùn)練過(guò)程中,需要實(shí)時(shí)監(jiān)控模型的性能,確保在訓(xùn)練的各個(gè)階段都保持最優(yōu)的計(jì)算資源和數(shù)據(jù)規(guī)模配置。如果發(fā)現(xiàn)性能沒(méi)有預(yù)期的提升,可以調(diào)整模型的規(guī)模或增加數(shù)據(jù)量進(jìn)行優(yōu)化。
高效使用硬件資源
數(shù)據(jù)并行(Data Parallelism)數(shù)據(jù)并行是處理無(wú)法裝入單一計(jì)算節(jié)點(diǎn)的數(shù)據(jù)集時(shí)最常見(jiàn)的方式。具體來(lái)說(shuō),數(shù)據(jù)并行將訓(xùn)練數(shù)據(jù)劃分為多個(gè)數(shù)據(jù)分片(shards),并將這些分片分配到不同的計(jì)算節(jié)點(diǎn)上。每個(gè)節(jié)點(diǎn)在其本地?cái)?shù)據(jù)上訓(xùn)練一個(gè)子模型,然后與其他節(jié)點(diǎn)通信,定期合并它們的結(jié)果,從而獲得全局模型。數(shù)據(jù)并行的參數(shù)更新可以是同步的或異步的。同步數(shù)據(jù)并行中,各個(gè)節(jié)點(diǎn)會(huì)在每個(gè)步驟后同步梯度,并將更新后的模型參數(shù)發(fā)送回所有節(jié)點(diǎn)。而異步數(shù)據(jù)并行則允許各個(gè)節(jié)點(diǎn)在不同步的情況下更新模型,通常可以加速訓(xùn)練,但也可能引入更多的不一致性,導(dǎo)致模型收斂較慢。
數(shù)據(jù)并行的優(yōu)點(diǎn)在于它提高了計(jì)算效率,并且相對(duì)容易實(shí)現(xiàn)。然而,缺點(diǎn)在于反向傳播時(shí),需要將整個(gè)梯度傳遞給所有其他GPU,這會(huì)導(dǎo)致較大的內(nèi)存開(kāi)銷。同時(shí),模型和優(yōu)化器的復(fù)制會(huì)占用較多的內(nèi)存,降低內(nèi)存效率。
張量并行(Tensor Parallelism)張量并行是將大模型的張量運(yùn)算分割到多個(gè)設(shè)備上進(jìn)行的一種并行方式。不同于數(shù)據(jù)并行在數(shù)據(jù)維度上的劃分,張量并行通過(guò)分割模型的不同層或張量來(lái)并行化計(jì)算。每個(gè)GPU只計(jì)算模型的一部分(例如,一層神經(jīng)網(wǎng)絡(luò)或一個(gè)張量片段),然后通過(guò)跨設(shè)備通信將其結(jié)果匯總。張量并行能夠有效解決單個(gè)GPU內(nèi)存不足以加載完整模型的問(wèn)題,但它的挑戰(zhàn)在于跨設(shè)備的通信開(kāi)銷較大。隨著模型尺寸的增加,模型并行的開(kāi)銷也隨之增加,這要求更加高效的算法和硬件架構(gòu)。
Megatron-LM是張量并行的一個(gè)典型應(yīng)用,通過(guò)將模型的張量分布到多個(gè)GPU上,從而能夠訓(xùn)練大規(guī)模模型,如GPT-3、PaLM等。結(jié)合數(shù)據(jù)并行和張量并行的方式,模型的訓(xùn)練效率和規(guī)模都得到了顯著提升。
流水線并行(Pipeline Parallelism)流水線并行是一種將模型的不同階段分布到多個(gè)設(shè)備上進(jìn)行訓(xùn)練的策略。不同于數(shù)據(jù)并行和張量并行,流水線并行將模型劃分為不同的部分,每個(gè)設(shè)備只處理某個(gè)階段的任務(wù),并將輸出傳遞給下一個(gè)階段的設(shè)備。這樣,多個(gè)設(shè)備可以并行工作,每個(gè)設(shè)備處理不同的任務(wù),但最終目標(biāo)是加速模型的訓(xùn)練過(guò)程。例如,如果一個(gè)模型有5個(gè)階段,流水線并行會(huì)將每個(gè)階段分配到一個(gè)GPU上,允許GPU并行工作,每個(gè)GPU處理模型的一部分任務(wù)。這種方法在長(zhǎng)時(shí)間的訓(xùn)練過(guò)程中非常有效,尤其是在非常深的網(wǎng)絡(luò)架構(gòu)中。
流水線并行的挑戰(zhàn)在于,需要有效地同步不同階段之間的數(shù)據(jù)流,而且每個(gè)設(shè)備只能在前一個(gè)設(shè)備完成計(jì)算后才開(kāi)始工作,這可能會(huì)帶來(lái)延遲。然而,通過(guò)合理設(shè)計(jì)流水線,延遲可以降到最低,從而提高訓(xùn)練效率。
訓(xùn)練優(yōu)化策略在訓(xùn)練LLM時(shí),除了并行化策略,硬件和算法的優(yōu)化同樣至關(guān)重要。以下是一些重要的訓(xùn)練優(yōu)化策略:
梯度累積(Gradient Accumulation)
梯度累積是一種將訓(xùn)練批次分割為微批次,并在每個(gè)微批次的訓(xùn)練過(guò)程中累積梯度,直到所有微批次完成后再進(jìn)行一次參數(shù)更新的技術(shù)。這種方式可以有效降低內(nèi)存需求,并使得大批次的訓(xùn)練成為可能,從而加速模型訓(xùn)練。
混合精度訓(xùn)練(Mixed Precision Training)
混合精度訓(xùn)練使用16位和32位浮動(dòng)精度的結(jié)合來(lái)訓(xùn)練神經(jīng)網(wǎng)絡(luò)。通過(guò)使用低精度的計(jì)算,可以顯著減少內(nèi)存占用和計(jì)算開(kāi)銷,同時(shí)又不會(huì)損失太多的模型精度。這種技術(shù)在處理大規(guī)模模型時(shí)尤其有用。
動(dòng)態(tài)學(xué)習(xí)率(Dynamic Learning Rates)
在訓(xùn)練過(guò)程中,根據(jù)模型的表現(xiàn)動(dòng)態(tài)調(diào)整學(xué)習(xí)率,可以提高收斂速度并減少過(guò)擬合的風(fēng)險(xiǎn)。常見(jiàn)的學(xué)習(xí)率調(diào)整策略包括基于訓(xùn)練輪次的衰減、基于梯度的自適應(yīng)調(diào)整等。
- 模型剪枝與蒸餾(Model Pruning and Distillation)
在訓(xùn)練后期,通過(guò)剪枝減少不必要的模型參數(shù),或者通過(guò)蒸餾技術(shù)將大模型的知識(shí)轉(zhuǎn)移到小模型中,從而提升推理效率。這些技術(shù)可以幫助減輕大模型部署的資源壓力,并加速推理。
數(shù)據(jù)集收集
“壞數(shù)據(jù)導(dǎo)致壞模型。” 這一點(diǎn)在訓(xùn)練大型語(yǔ)言模型(LLM)時(shí)尤為重要。高質(zhì)量、具有高多樣性和大規(guī)模的訓(xùn)練數(shù)據(jù)集,不僅能提高下游任務(wù)的模型表現(xiàn),還能加速模型的收斂過(guò)程。
數(shù)據(jù)集的多樣性對(duì)于LLM尤其關(guān)鍵。這是因?yàn)閿?shù)據(jù)的多樣性能有效提升模型在跨領(lǐng)域的知識(shí)涵蓋能力,從而提高其對(duì)各種復(fù)雜任務(wù)的泛化能力。通過(guò)訓(xùn)練多樣化的示例,能夠增強(qiáng)模型在處理各種細(xì)微任務(wù)時(shí)的表現(xiàn)。在數(shù)據(jù)集收集過(guò)程中,一般的數(shù)據(jù)可以由非專家收集,但對(duì)于特定領(lǐng)域的數(shù)據(jù),通常需要由專業(yè)領(lǐng)域的專家(SMEs,Subject Matter Experts)來(lái)進(jìn)行收集和審查。
NLP工程師在這個(gè)階段也應(yīng)當(dāng)深度參與,原因在于他們熟悉LLM如何“學(xué)習(xí)表示數(shù)據(jù)”的過(guò)程,因此能發(fā)現(xiàn)專家可能遺漏的數(shù)據(jù)異常或缺口。專家和NLP工程師之間的協(xié)作非常重要,可以確保數(shù)據(jù)的質(zhì)量和代表性。
數(shù)據(jù)預(yù)處理
- 數(shù)據(jù)采樣(Data Sampling):
- 某些數(shù)據(jù)組件可以進(jìn)行過(guò)采樣(up-sampling),以獲得更平衡的數(shù)據(jù)分布。例如,一些研究會(huì)對(duì)低質(zhì)量的數(shù)據(jù)集(如未過(guò)濾的網(wǎng)頁(yè)爬取數(shù)據(jù))進(jìn)行下采樣(down-sampling)。而其他研究則會(huì)根據(jù)模型目標(biāo)對(duì)特定領(lǐng)域的數(shù)據(jù)進(jìn)行過(guò)采樣。
- 對(duì)于預(yù)訓(xùn)練數(shù)據(jù)集而言,其組成通常來(lái)源于高質(zhì)量的科學(xué)資源,例如學(xué)術(shù)論文、教科書、講義和百科全書。數(shù)據(jù)集的質(zhì)量通常非常高,并且會(huì)根據(jù)任務(wù)需要進(jìn)行特定的篩選,比如使用任務(wù)特定的數(shù)據(jù)集來(lái)幫助模型學(xué)習(xí)如何將這些知識(shí)融入到新的任務(wù)上下文中。
- 數(shù)據(jù)清理(Data Cleaning):
通常在訓(xùn)練之前,需要對(duì)數(shù)據(jù)進(jìn)行清理和重新格式化。一些常見(jiàn)的清理步驟包括去除樣板文本(boilerplate text)、去除HTML代碼或標(biāo)記。對(duì)于某些項(xiàng)目,還需要修復(fù)拼寫錯(cuò)誤、處理跨領(lǐng)域的同形異義詞(homographs),或者去除有偏見(jiàn)或有害的言論,以提高模型的表現(xiàn)。
- 非標(biāo)準(zhǔn)文本組件的處理(Handling Non-Standard Textual Components):
在某些情況下,將非標(biāo)準(zhǔn)的文本組件轉(zhuǎn)換成標(biāo)準(zhǔn)文本非常重要。例如,emoji表情可以轉(zhuǎn)換為其對(duì)應(yīng)的文本表示:可以轉(zhuǎn)換為“snowflake”。這種轉(zhuǎn)換通常可以通過(guò)編程實(shí)現(xiàn)。
數(shù)據(jù)去重(Data Deduplication):
- 一些研究者發(fā)現(xiàn),去重訓(xùn)練數(shù)據(jù)能夠顯著提高模型的表現(xiàn)。常用的去重方法包括局部敏感哈希(LSH, Locality-Sensitive Hashing)。通過(guò)這種方法,可以識(shí)別并移除重復(fù)的訓(xùn)練數(shù)據(jù),從而減少模型學(xué)習(xí)到的冗余信息。
預(yù)訓(xùn)練
訓(xùn)練一個(gè)數(shù)十億參數(shù)的LLM(大規(guī)模語(yǔ)言模型)通常是一個(gè)高度實(shí)驗(yàn)性的過(guò)程,充滿了大量的試驗(yàn)與錯(cuò)誤。通常,團(tuán)隊(duì)會(huì)從一個(gè)較小的模型開(kāi)始,確保其具有潛力,然后逐步擴(kuò)展到更多的參數(shù)。需要注意的是,隨著模型規(guī)模的擴(kuò)大,會(huì)出現(xiàn)一些在訓(xùn)練小規(guī)模數(shù)據(jù)時(shí)不會(huì)遇到的問(wèn)題。
模型架構(gòu)為了減少訓(xùn)練不穩(wěn)定的風(fēng)險(xiǎn),實(shí)踐者通常會(huì)選擇從流行的前身模型(如GPT-2或GPT-3)中借鑒架構(gòu)和超參數(shù),并在此基礎(chǔ)上做出調(diào)整,以提高訓(xùn)練效率、擴(kuò)展模型的規(guī)模(包括深度和寬度),并增強(qiáng)模型的性能。正如前面提到的,預(yù)訓(xùn)練過(guò)程通常涉及大量的實(shí)驗(yàn),以找到模型性能的最佳配置。實(shí)驗(yàn)可以涉及以下內(nèi)容之一或全部:
- 權(quán)重初始化(Weight Initialization)
- 位置嵌入(Positional Embeddings)
- 優(yōu)化器(Optimizer)
- 激活函數(shù)(Activation)
- 學(xué)習(xí)率(Learning Rate)
- 權(quán)重衰減(Weight Decay)
- 損失函數(shù)(Loss Function)
- 序列長(zhǎng)度(Sequence Length)
- 層數(shù)(Number of Layers)
- 注意力頭數(shù)(Number of Attention Heads)
- 參數(shù)數(shù)量(Number of Parameters)
- 稠密與稀疏層(Dense vs. Sparse Layers)
- 批量大小(Batch Size)
Dropout等。
通常,人工試錯(cuò)與自動(dòng)超參數(shù)優(yōu)化(HPO)相結(jié)合,用來(lái)找到最優(yōu)的配置組合。常見(jiàn)的超參數(shù)包括:學(xué)習(xí)率、批量大小、dropout率等。超參數(shù)搜索是一個(gè)高昂的過(guò)程,尤其是對(duì)于數(shù)十億參數(shù)的模型來(lái)說(shuō),往往過(guò)于昂貴,不容易在完整規(guī)模下進(jìn)行。通常會(huì)根據(jù)先前的小規(guī)模實(shí)驗(yàn)結(jié)果和已發(fā)布的工作,來(lái)選擇超參數(shù),而不是從零開(kāi)始。此外,某些超參數(shù)在訓(xùn)練過(guò)程中也需要進(jìn)行動(dòng)態(tài)調(diào)整,以平衡學(xué)習(xí)效率和訓(xùn)練收斂。例如:
學(xué)習(xí)率(Learning Rate):在訓(xùn)練的早期階段可以線性增加,之后再衰減。
批量大小(Batch Size):通常會(huì)從較小的批量大小開(kāi)始,逐步增加。
硬件故障與訓(xùn)練不穩(wěn)定
硬件故障(Hardware Failure):在訓(xùn)練過(guò)程中,計(jì)算集群可能會(huì)發(fā)生硬件故障,這時(shí)需要手動(dòng)或自動(dòng)重啟訓(xùn)練。在手動(dòng)重啟時(shí),訓(xùn)練會(huì)暫停,并進(jìn)行一系列診斷測(cè)試來(lái)檢測(cè)有問(wèn)題的節(jié)點(diǎn)。標(biāo)記為有問(wèn)題的節(jié)點(diǎn)應(yīng)該被隔離,然后從最后保存的檢查點(diǎn)繼續(xù)訓(xùn)練。
訓(xùn)練不穩(wěn)定(Training Instability):訓(xùn)練不穩(wěn)定性是一個(gè)根本性的挑戰(zhàn)。在訓(xùn)練過(guò)程中,超參數(shù)(如學(xué)習(xí)率和權(quán)重初始化)直接影響模型的穩(wěn)定性。例如,當(dāng)損失值發(fā)散時(shí),降低學(xué)習(xí)率并從較早的檢查點(diǎn)重新啟動(dòng)訓(xùn)練,可能會(huì)幫助恢復(fù)訓(xùn)練并繼續(xù)進(jìn)行。此外,模型越大,訓(xùn)練過(guò)程中發(fā)生損失峰值(loss spikes)的難度也越大,這些峰值可能在訓(xùn)練的后期出現(xiàn),并且不規(guī)則。盡管沒(méi)有很多系統(tǒng)性的方法來(lái)減少這種波動(dòng),但以下是一些行業(yè)中的最佳實(shí)踐:
批量大小(Batch Size):通常,使用GPU能夠支持的最大批量大小是最好的選擇。
批量歸一化(Batch Normalization):對(duì)mini-batch中的激活進(jìn)行歸一化可以加速收斂并提高模型性能。
學(xué)習(xí)率調(diào)度(Learning Rate Scheduling):高學(xué)習(xí)率可能會(huì)導(dǎo)致?lián)p失波動(dòng)或發(fā)散,從而導(dǎo)致?lián)p失峰值。通過(guò)調(diào)整學(xué)習(xí)率的衰減,逐步減小模型參數(shù)更新的幅度,可以提高訓(xùn)練穩(wěn)定性。常見(jiàn)的調(diào)度方式包括階梯衰減(step decay)**和**指數(shù)衰減(exponential decay)。
權(quán)重初始化(Weight Initialization):正確的權(quán)重初始化有助于模型更快收斂并提高性能。常見(jiàn)的方法包括隨機(jī)初始化、高斯噪聲初始化以及Transformers中的T-Fixup初始化。
模型訓(xùn)練起點(diǎn)(Model Training Starting Point):使用在相關(guān)任務(wù)上預(yù)訓(xùn)練過(guò)的模型作為起點(diǎn),可以幫助模型更快收斂并提高性能。
正則化(Regularization):使用dropout、權(quán)重衰減(weight decay)和L1/L2正則化等方法可以減少過(guò)擬合并提高模型的泛化能力。
數(shù)據(jù)增強(qiáng)(Data Augmentation):通過(guò)對(duì)訓(xùn)練數(shù)據(jù)應(yīng)用轉(zhuǎn)換,可以幫助模型更好地泛化,減少過(guò)擬合。
訓(xùn)練過(guò)程中熱交換(Hot-Swapping):在訓(xùn)練過(guò)程中根據(jù)需要更換優(yōu)化器或激活函數(shù),幫助解決出現(xiàn)的問(wèn)題。
模型評(píng)估
通常,預(yù)訓(xùn)練的模型會(huì)在多種語(yǔ)言模型數(shù)據(jù)集上進(jìn)行評(píng)估,以評(píng)估其在邏輯推理、翻譯、自然語(yǔ)言推理、問(wèn)答等任務(wù)中的表現(xiàn)。機(jī)器學(xué)習(xí)領(lǐng)域的實(shí)踐者已經(jīng)對(duì)多種標(biāo)準(zhǔn)評(píng)估基準(zhǔn)達(dá)成共識(shí)。另一個(gè)評(píng)估步驟是n-shot學(xué)習(xí)。它是一個(gè)與任務(wù)無(wú)關(guān)的維度,指的是在推理時(shí)提供給模型的監(jiān)督樣本(示例)數(shù)量。n-shot通常通過(guò)“提示(prompting)”技術(shù)來(lái)提供。評(píng)估通常分為以下三類:
零樣本(Zero-shot):不向模型提供任何監(jiān)督樣本進(jìn)行推理任務(wù)的評(píng)估。
一-shot(One-shot):類似于少樣本(few-shot),但n=1,表示在推理時(shí)向模型提供一個(gè)監(jiān)督樣本。
- 少樣本(Few-shot):評(píng)估中向模型提供少量監(jiān)督樣本(例如,提供5個(gè)樣本 -> 5-shot)。
偏見(jiàn)與有害語(yǔ)言
在基于網(wǎng)頁(yè)文本訓(xùn)練的大規(guī)模通用語(yǔ)言模型中,存在潛在的風(fēng)險(xiǎn)。這是因?yàn)椋喝祟惐旧碛衅?jiàn),這些偏見(jiàn)會(huì)通過(guò)數(shù)據(jù)傳遞到模型中,模型在學(xué)習(xí)這些數(shù)據(jù)時(shí),也會(huì)繼承這些偏見(jiàn)。除了加劇或延續(xù)社會(huì)刻板印象之外,我們還需要確保模型不會(huì)記住并泄露私人信息。
仇恨言論檢測(cè)(Hate Speech Detection)
社會(huì)偏見(jiàn)檢測(cè)(Social Bias Detection)
有害語(yǔ)言生成(Toxic Language Generation)
對(duì)話安全評(píng)估(Dialog Safety Evaluations)
截至目前,大多數(shù)對(duì)現(xiàn)有預(yù)訓(xùn)練模型的分析表明,基于互聯(lián)網(wǎng)訓(xùn)練的模型會(huì)繼承互聯(lián)網(wǎng)規(guī)模的偏見(jiàn)。此外,預(yù)訓(xùn)練模型通常容易生成有害語(yǔ)言,即使給出相對(duì)無(wú)害的提示,且對(duì)抗性提示也容易找到。那么,如何修復(fù)這些問(wèn)題呢?以下是一些在預(yù)訓(xùn)練過(guò)程中以及訓(xùn)練后緩解偏見(jiàn)的方法:
- 訓(xùn)練集過(guò)濾(Training Set Filtering)
- 訓(xùn)練集修改(Training Set Modification)
- 訓(xùn)練后偏見(jiàn)緩解方法
- 提示工程(Prompt Engineering)
- 微調(diào)(Fine-tuning)
輸出引導(dǎo)(Output Steering)
Instruction Tuning(指令微調(diào))
假設(shè)我們現(xiàn)在擁有一個(gè)預(yù)訓(xùn)練的通用大型語(yǔ)言模型(LLM)。如果我們之前的工作做得足夠好,那么模型已經(jīng)能夠在零-shot和少量-shot的情況下執(zhí)行一些特定領(lǐng)域的任務(wù)。然而,盡管零-shot學(xué)習(xí)可以在某些情況下有效,許多任務(wù)(如閱讀理解、問(wèn)答、自然語(yǔ)言推理等)中,零-shot學(xué)習(xí)的效果通常要遜色于少量-shot學(xué)習(xí)的表現(xiàn)。一個(gè)可能的原因是,在沒(méi)有少量示例的情況下,模型很難在格式與預(yù)訓(xùn)練數(shù)據(jù)不同的提示下取得好的表現(xiàn)。為了應(yīng)對(duì)這個(gè)問(wèn)題,我們可以使用指令微調(diào)(Instruction Tuning)。指令微調(diào)是一種先進(jìn)的微調(diào)技術(shù),它通過(guò)對(duì)預(yù)訓(xùn)練模型進(jìn)行微調(diào),使其能更好地響應(yīng)各種任務(wù)指令,從而減少在提示階段對(duì)少量示例的需求(即顯著提高零-shot性能)。
指令微調(diào)在2022年大受歡迎,因?yàn)檫@一技術(shù)能顯著提高模型性能,同時(shí)不會(huì)影響其泛化能力。通常,預(yù)訓(xùn)練的LLM會(huì)在一組語(yǔ)言任務(wù)上進(jìn)行微調(diào),并通過(guò)在微調(diào)過(guò)程中未見(jiàn)過(guò)的任務(wù)來(lái)評(píng)估其泛化能力和零-shot能力。
與預(yù)訓(xùn)練–微調(diào)和提示的比較
預(yù)訓(xùn)練–微調(diào)(Pretrain–Finetune):在預(yù)訓(xùn)練模型的基礎(chǔ)上,進(jìn)行特定任務(wù)的微調(diào)。模型通常在特定領(lǐng)域數(shù)據(jù)上進(jìn)行微調(diào),能顯著提升該任務(wù)的性能,但對(duì)其他任務(wù)的泛化能力可能較差。
提示(Prompting):使用適當(dāng)?shù)奶崾驹~(prompt)引導(dǎo)模型執(zhí)行特定任務(wù),但在某些任務(wù)中(如閱讀理解和問(wèn)答),零-shot學(xué)習(xí)的效果往往較差。
指令微調(diào):通過(guò)對(duì)模型進(jìn)行全面微調(diào),使其能夠更加有效地理解和執(zhí)行各種任務(wù)指令,從而減少了對(duì)少量示例的依賴,并顯著提升零-shot性能。
思維鏈(Chain-of-Thought)在指令微調(diào)中的作用
思維鏈?zhǔn)且环N技術(shù),通過(guò)這種方式,模型在執(zhí)行任務(wù)時(shí)會(huì)顯式地推理每一個(gè)步驟,幫助模型更好地理解問(wèn)題的背景并給出合理的推理過(guò)程。對(duì)于某些復(fù)雜的推理任務(wù),使用思維鏈的示例可以顯著提高模型的推理能力,并提升其在這些任務(wù)上的表現(xiàn)。在指令微調(diào)過(guò)程中,若包含思維鏈?zhǔn)纠ɡ绮襟E分解、推理過(guò)程的寫作等),模型會(huì)學(xué)會(huì)按照邏輯推理的步驟逐步完成任務(wù),而非直接給出答案。這對(duì)像數(shù)學(xué)推理、常識(shí)推理等復(fù)雜任務(wù)尤其有效。
提高零-shot能力:通過(guò)對(duì)預(yù)訓(xùn)練模型進(jìn)行指令微調(diào),模型能更好地理解和執(zhí)行未見(jiàn)過(guò)的任務(wù),提升其在零-shot任務(wù)上的表現(xiàn)。
泛化性強(qiáng):與只針對(duì)特定任務(wù)微調(diào)的模型相比,指令微調(diào)的模型具有更強(qiáng)的泛化能力,能夠適應(yīng)多種下游任務(wù)。
- 減少對(duì)少量示例的需求:經(jīng)過(guò)指令微調(diào)的模型在零-shot和少-shot任務(wù)中表現(xiàn)更為優(yōu)秀,減少了對(duì)示例輸入的依賴。
強(qiáng)化學(xué)習(xí)與人類反饋 (RLHF)
RLHF(Reinforcement Learning with Human Feedback)是一種在指令微調(diào)的基礎(chǔ)上,通過(guò)引入人類反饋來(lái)進(jìn)一步提升模型與用戶期望對(duì)齊的技術(shù)。預(yù)訓(xùn)練的LLM(大型語(yǔ)言模型)通常會(huì)表現(xiàn)出一些不良行為,例如編造事實(shí)、生成偏見(jiàn)或有毒的回復(fù),或者由于訓(xùn)練目標(biāo)和用戶目標(biāo)之間的錯(cuò)位,未能按照指令執(zhí)行任務(wù)。RLHF 通過(guò)利用人類反饋來(lái)對(duì)模型的輸出進(jìn)行精細(xì)調(diào)整,從而解決這些問(wèn)題。例如,OpenAI 的 InstructGPT 和 ChatGPT 就是 RLHF 的實(shí)際應(yīng)用案例。InstructGPT 是在 GPT-3 上使用 RLHF 進(jìn)行微調(diào)的,而 ChatGPT 基于 GPT-3.5 系列,這些模型在提升真實(shí)度和減少有毒輸出方面取得了顯著進(jìn)展,同時(shí)性能回歸(也稱為“對(duì)齊稅”)保持在最低水平。
以下是 RLHF 流程的概念圖,展示了三個(gè)主要步驟:
- 監(jiān)督微調(diào)(SFT):對(duì)預(yù)訓(xùn)練模型進(jìn)行指令微調(diào)。
- 獎(jiǎng)勵(lì)模型(RM)訓(xùn)練:通過(guò)人類反饋訓(xùn)練獎(jiǎng)勵(lì)模型。
- 通過(guò)近端策略優(yōu)化(PPO)進(jìn)行強(qiáng)化學(xué)習(xí):使用獎(jiǎng)勵(lì)模型優(yōu)化模型的行為策略。
參考文獻(xiàn)
What Language Model Architecture and Pre-training Objective Work Best for Zero-Shot Generalization?GPT-3 Paper – Language Models are Few-Shot LearnersGPT-NeoX-20B: An Open-Source Autoregressive Language ModelOPT: Open Pre-trained Transformer Language ModelsEfficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LMHow To Build an Efficient NLP ModelEmergent Abilities of Large Language ModelsBeyond the Imitation Game Benchmark (BIG-bench)Talking About Large Language ModelsGalactica: A Large Language Model for ScienceState of AI Report 2022Finetuned Language Models are Zero-Shot LearnersScaling Instruction-Fine Tuned Language ModelsTraining Language Models to Follow Instructions with Human FeedbackScalable Deep Learning on Distributed Infrastructures: Challenges, Techniques, and ToolsNew Scaling Laws for Large Language Models by DeepMindNew Scaling Laws for Large Language Models
Understanding the Difficulty of Training Transformers
-
語(yǔ)言模型
+關(guān)注
關(guān)注
0文章
557瀏覽量
10588 -
大模型
+關(guān)注
關(guān)注
2文章
2930瀏覽量
3680 -
LLM
+關(guān)注
關(guān)注
1文章
316瀏覽量
632
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
攝像機(jī)EMC電磁兼容性測(cè)試整改:影像設(shè)備關(guān)鍵步驟

EMC電機(jī)控制器測(cè)試整改:確保產(chǎn)品可靠性關(guān)鍵步驟

電動(dòng)工具EMC測(cè)試整改:確保電磁兼容性的關(guān)鍵步驟

如何訓(xùn)練自己的LLM模型
深圳南柯電子 EMC測(cè)試整改:確保產(chǎn)品電磁兼容性的關(guān)鍵步驟

組合邏輯電路設(shè)計(jì)的關(guān)鍵步驟是什么
LLM大模型推理加速的關(guān)鍵技術(shù)
大模型LLM與ChatGPT的技術(shù)原理
llm模型有哪些格式
LLM模型和LMM模型的區(qū)別
llm模型和chatGPT的區(qū)別
LLM模型的應(yīng)用領(lǐng)域
深圳比創(chuàng)達(dá)|EMC與EMI測(cè)試整改:確保設(shè)備電磁兼容性的關(guān)鍵步驟

大語(yǔ)言模型(LLM)快速理解

EMI測(cè)試整改:確保電子設(shè)備電磁兼容性的關(guān)鍵步驟






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論