

Linux系統出現了性能問題,一般我們可以通過top、iostat、free、vmstat等命令來查看初步定位問題。其中iostat可以給我們提供豐富的IO狀態數據。
一、查詢命令基本使用
1、命令介紹
$iostat -d -k 1 10
-d 表示,顯示設備(磁盤)使用狀態;
-k某些使用block為單位的列強制使用Kilobytes為單位;
1 10表示,數據顯示每隔1秒刷新一次,共顯示10次。
2、用法展示
# iostat -x 1 10 Linux 2.6.18-92.el5xen 02/03/2009 avg-cpu: %user %nice %system %iowait %steal %idle 1.10 0.00 4.82 39.54 0.07 54.46 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sda 0.00 3.50 0.40 2.50 5.60 48.00 18.48 0.00 0.97 0.97 0.28 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sdd 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 sde 0.00 0.10 0.30 0.20 2.40 2.40 9.60 0.00 1.60 1.60 0.08 sdf 17.40 0.50 102.00 0.20 12095.20 5.60 118.40 0.70 6.81 2.09 21.36 sdg 232.40 1.90 379.70 0.50 76451.20 19.20 201.13 4.94 13.78 2.45 93.16
3、參數講解
(1)參數如下:
rrqm/s: 每秒進行 merge 的讀操作數目。即 delta(rmerge)/s
wrqm/s: 每秒進行 merge 的寫操作數目。即 delta(wmerge)/s
r/s: 每秒完成的讀 I/O 設備次數。即 delta(rio)/s
w/s: 每秒完成的寫 I/O 設備次數。即 delta(wio)/s
rsec/s:每秒讀扇區數。即 delta(rsect)/s
wsec/s: 每秒寫扇區數。即 delta(wsect)/s
rkB/s: 每秒讀K字節數。是 rsect/s 的一半,因為每扇區大小為512字節。(需要計算)
wkB/s: 每秒寫K字節數。是 wsect/s 的一半。(需要計算)
avgrq-sz: 平均每次設備I/O操作的數據大小 (扇區)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O隊列長度。即 delta(aveq)/s/1000 (因為aveq的單位為毫秒)。
await: 平均每次設備I/O操作的等待時間 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次設備I/O操作的服務時間 (毫秒)。即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的時間用于 I/O 操作,或者說一秒中有多少時間 I/O 隊列是非空的。即 delta(use)/s/1000 (因為use的單位為毫秒)
(2)參數分析:
如果 %util 接近 100%,說明產生的I/O請求太多,I/O系統已經滿負荷,該磁盤可能存在瓶頸。
await小于70% IO壓力就較大了,一般讀取速度有較多的wait.
同時可以結合vmstat 查看查看bi參數(等待資源的進程數)和wa參數(IO等待所占用的CPU時間的百分比,高過30%時IO壓力高)
(3)另外還可以參考,一般情況:
① svctm < await (因為同時等待的請求的等待時間被重復計算了),
② svctm的大小一般和磁盤性能有關:CPU/內存的負荷也會對其有影響,請求過多也會間接導致 svctm的增加。
③ await: await的大小一般取決于服務時間(svctm) 以及 I/O 隊列的長度和 I/O 請求的發出模式。
④ 如果 svctm 比較接近 await,說明I/O 幾乎沒有等待時間;
⑤ 如果 await 遠大于 svctm,說明 I/O隊列太長,應用得到的響應時間變慢,
⑥ 如果響應時間超過了用戶可以容許的范圍,這時可以考慮更換更快的磁盤,調整內核 elevator算法,優化應用,或者升級 CPU。
⑦ 隊列長度(avgqu-sz)也可作為衡量系統 I/O 負荷的指標,但由于 avgqu-sz 是按照單位時間的平均值,所以不能反映瞬間的 I/O 洪水。
二、I/O理解與實例分析
1、一個不錯的例子,瞬間理解I/O (I/O 系統 vs. 超市排隊)
(1)超市例子:
舉一個例子,我們在超市排隊 checkout 時,怎么決定該去哪個交款臺呢? 首當是看排的隊人數,5個人總比20人要快吧?除了數人頭,我們也常常看看前面人購買的東西多少,如果前面有個采購了一星期食品的大媽,那么可以考慮換個隊排了。還有就是收銀員的速度了,如果碰上了連錢都點不清楚的新手,那就有的等了。另外,時機也很重要,可能 5分鐘前還人滿為患的收款臺,現在已是人去樓空,這時候交款可是很爽啊,當然,前提是那過去的 5 分鐘里所做的事情比排隊要有意義(不過我還沒發現什么事情比排隊還無聊的)。
(2)I/O 系統也和超市排隊有很多類似之處
① r/s+w/s 類似于交款人的總數
② 平均隊列長度(avgqu-sz)類似于單位時間里平均排隊人的個數
③ 平均服務時間(svctm)類似于收銀員的收款速度
④ 平均等待時間(await)類似于平均每人的等待時間
⑤ 平均I/O數據(avgrq-sz)類似于平均每人所買的東西多少
⑥ I/O 操作率 (%util)類似于收款臺前有人排隊的時間比例。
我們可以根據這些數據分析出 I/O 請求的模式,以及 I/O 的速度和響應時間。
2、參數的實例分析
(1)實例
# iostat -x 1 avg-cpu: %user %nice %sys %idle 16.24 0.00 4.31 79.44 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util /dev/vda 00.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29 /dev/vdb 00.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29 /dev/vbc 00.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
(2)分析
① 上面的 iostat 輸出表明秒有 28.57 次設備 I/O 操作: 總IO(io)/s = r/s(讀) +w/s(寫) = 1.02+27.55 = 28.57 (次/秒) 其中寫操作占了主體 (w:r = 27:1)。
② 平均每次設備 I/O 操作只需要 5ms 就可以完成,但每個 I/O 請求卻需要等上 78ms,為什么? 因為發出的 I/O 請求太多 (每秒鐘約 29 個),假設這些請求是同時發出的,那么平均等待時間可以這樣計算:
平均等待時間 = 單個 I/O 服務時間 * ( 1 + 2 + ... + 請求總數-1) / 請求總數
③ 應用到上面的例子: 平均等待時間 = 5ms * (1+2+...+28)/29 = 70ms,和 iostat 給出的78ms 的平均等待時間很接近。這反過來表明 I/O 是同時發起的。
④ 每秒發出的 I/O 請求很多 (約 29 個),平均隊列卻不長 (只有 2 個 左右),這表明這 29 個請求的到來并不均勻,大部分時間 I/O 是空閑的。
⑤ 一秒中有 14.29% 的時間 I/O 隊列中是有請求的,也就是說,85.71% 的時間里 I/O 系統無事可做,所有 29 個 I/O 請求都在142毫秒之內處理掉了。
⑥ delta(ruse+wuse)/delta(io) = await = 78.21 => delta(ruse+wuse)/s=78.21 * delta(io)/s = 78.21*28.57 =2232.8,表明每秒內的I/O請求總共需要等待2232.8ms。所以平均隊列長度應為 2232.8ms/1000ms = 2.23,而iostat 給出的平均隊列長度 (avgqu-sz) 卻為 22.35,為什么?! 因為 iostat 中有 bug,avgqu-sz值應為 2.23,而不是 22.35。
三、iostat用法升級
1、Input Output statistics ( iostat )
iostat反映了終端、磁盤I/O情況和CPU活動。輸出結果的第一行是從系統啟動到現在為止的這段時間的結果,接下去的每一行是interval時間段內的結果。Kernel里有一組計數器用來跟蹤這些值。
iostat的默認參數是tdc(terminal, disk, and CPU)。如果任何其他的選項被指定,這個默認參數將被完全替代,例如,iostat -d將只反映磁盤的統計結果。
2、語法介紹
基本語法:iostat
option - 讓你指定所需信息的設備,像磁盤、cpu或者終端(-d , -c , -t or -tdc ) 。x 選項給出了完整的統計結果(gives the extended statistic)。
interval - 在兩個samples之間的時間(秒)。
count - 就是需要統計幾次
3、例子
$ iostat -xtc 5 2
extended disk statistics tty cpu
disk r/s w/s Kr/s Kw/s wait actv svc_t %w %b tin tout us sy wt id
sd0 2.6 3.0 20.7 22.7 0.1 0.2 59.2 6 19 0 84 3 85 11 0
sd1 4.2 1.0 33.5 8.0 0.0 0.2 47.2 2 23
sd2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0 0
sd3 10.2 1.6 51.4 12.8 0.1 0.3 31.2 3 31
4、參數詳解
disk:磁盤名稱
r / s:每秒讀取數
w / s:每秒寫入數
Kr / s:每秒讀取的千字節數
Kw / s:每秒寫入的千字節數
等待:等待服務的平均交易次數(Q長度)
actv:正在服務的平均事務數(從隊列中刪除但尚未完成)
%w:等待服務的事務的時間百分比(隊列非空)
%b:磁盤忙碌的時間百分比(正在進行的事務)
5、結果和解決方案
(1)從iostat輸出結果中需要注意的值:
Reads/writes per second (r/s , w/s)
Percentage busy (%b)
Service time (svc_t)
(2)如果磁盤顯示長時間的高reads/writes,并且磁盤的percentage busy (%b)也遠大于5%,同時average service time (svc_t)也遠大于30 milliseconds,這以下的措施需要被執行:
① 調整應用,令其使用磁盤i/o更加有效率,可以通過修改磁盤隊列、使用應用服務器的cache
② 將文件系統分布到2個或多個磁盤上,并使用volume manager/disksuite的條帶化特點
③ 增加系統參數值,如inode cache , ufs_ninode。Increase the system parameter values for inode cache , ufs_ninode , which is Number of inodes to be held in memory. Inodes are cached globally (for UFS), not on a per-file system basis
④ 將文件系統移到更快的磁盤/控制器,或者用更好的設備來代替
-
IO
+關注
關注
0文章
483瀏覽量
40002 -
Linux
+關注
關注
87文章
11420瀏覽量
212298 -
命令
+關注
關注
5文章
722瀏覽量
22631
原文標題:監控報I/O問題,怎么辦?
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
請問我該怎么辦才能用CyUSB做Linux?
Linux 系統應用編程之標準I/O詳解


Linux中如何使用信號驅動式I/O?
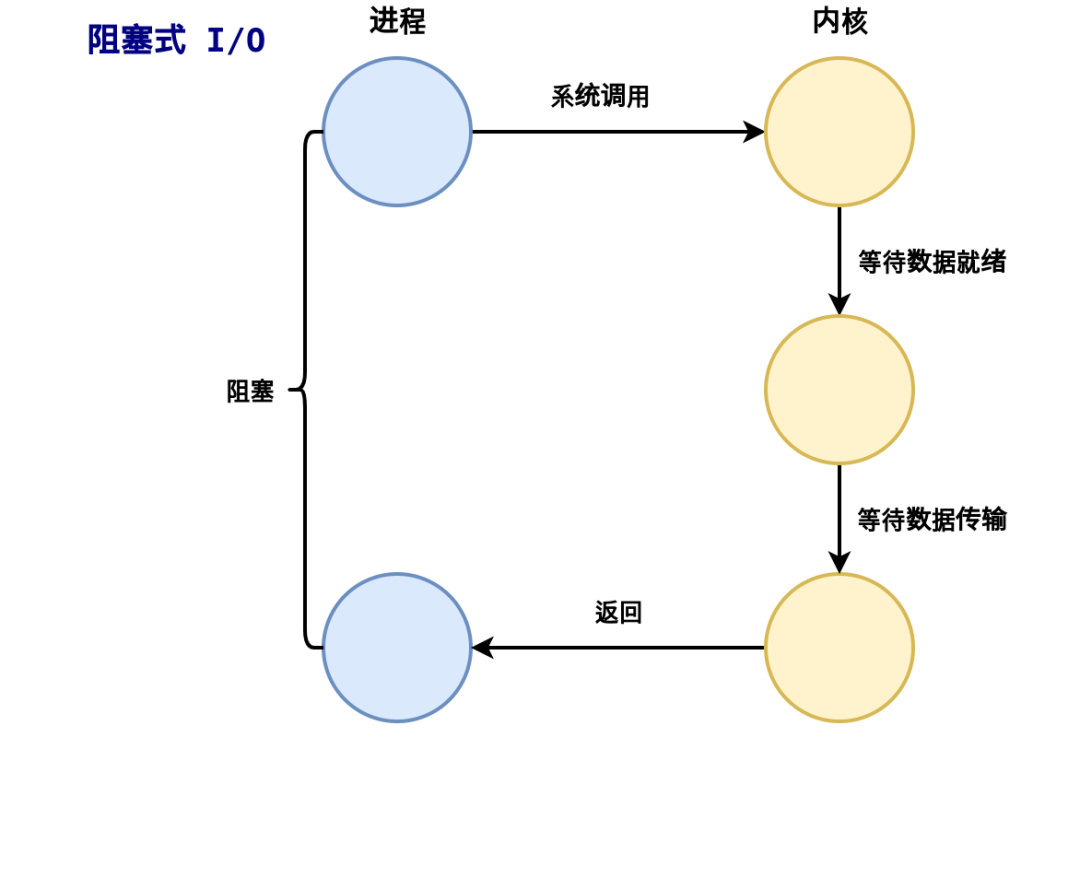
深入理解 Linux 的 I/O 系統





 工商網監
工商網監

評論