 數據倉庫和多維數據庫的區別在哪里
數據倉庫和多維數據庫的區別在哪里
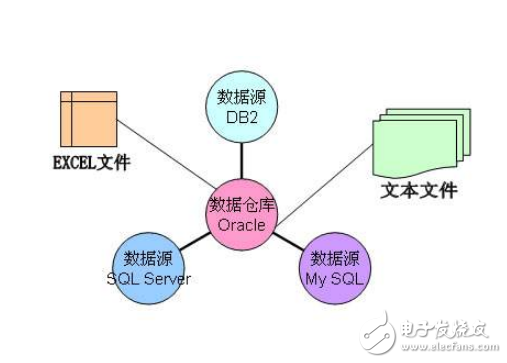
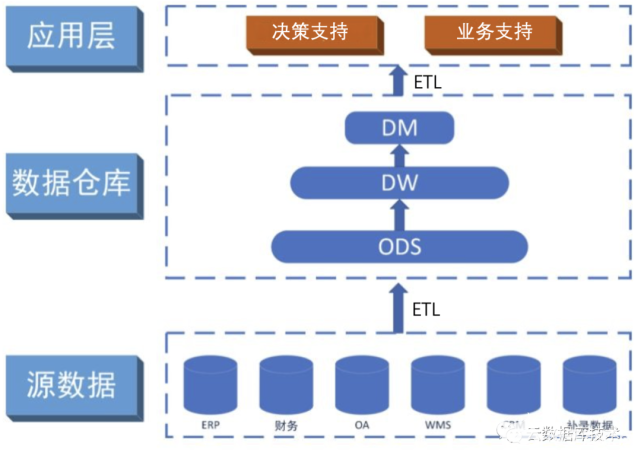
數據倉庫
數據倉庫,英文名稱為Data Warehouse,可簡寫為DW或DWH。數據倉庫,是為企業所有級別的決策制定過程,提供所有類型數據支持的戰略集合。它是單個數據存儲,出于分析性報告和決策支持目的而創建。 為需要業務智能的企業,提供指導業務流程改進、監視時間、成本、質量以及控制。
數據倉庫是決策支持系統(dss)和聯機分析應用數據源的結構化數據環境。數據倉庫研究和解決從數據庫中獲取信息的問題。數據倉庫的特征在于面向主題、集成性、穩定性和時變性。數據倉庫 ,由數據倉庫之父比爾·恩門(Bill Inmon)于1990年提出,主要功能仍是將組織透過資訊系統之聯機事務處理(OLTP)經年累月所累積的大量資料,透過數據倉庫理論所特有的資料儲存架構,作一有系統的分析整理,以利各種分析方法如聯機分析處理(OLAP)、數據挖掘(Data Mining)之進行,并進而支持如決策支持系統(DSS)、主管資訊系統(EIS)之創建,幫助決策者能快速有效的自大量資料中,分析出有價值的資訊,以利決策擬定及快速回應外在環境變動,幫助建構商業智能(BI)。
多維數據庫
多維數據庫(Multi Dimensional Database,MDD)可以簡單地理解為:將數據存放在一個n維數組中,而不是像關系數據庫那樣以記錄的形式存放。因此它存在大量稀疏矩陣,人們可以通過多維視圖來觀察數據。
多維數據庫是指將數據存放在一個門維數組中,而不是像關系數據庫那樣以記錄的形式存放。因此它存在大量稀疏矩陣,人們可以通過多維視圖來觀察數據。多維數據庫增加了一個時間維,與關系數據庫相比,它的優勢在于可以提高數據處理速度,加快反應時間,提高查詢效率。
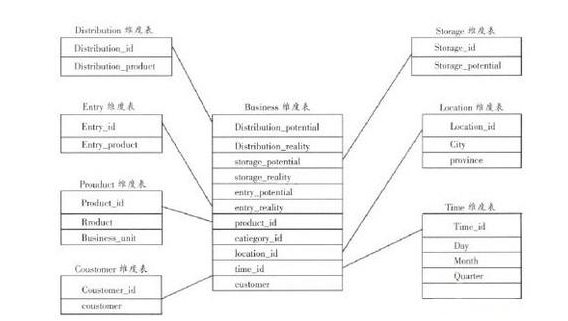
數據倉庫和多維數據庫的區別
數據倉庫中廣泛采用的數據庫設計模型有兩種:關系型和多維型。普遍認為在數據倉庫的設計方法中關系模型是“Inmon”方法而多維模型是“Kimball”方法。
先來看下關系模型,關系型數據以一種稱為“標準化”的形式存在。數據標準化是指數據庫設計會使數據分解成非常低的粒度級,標準化數據以一種孤立模式 存在,這種情況下對數據表里的數據關系要求很嚴格。一般遵循3NF范式。采用關系型設計的數據庫一般具有較強的靈活性和多功能性(可以支持數據的多種視 圖)。
再來看下多維模型,多維模型一般有星型模式、雪花模式、混雜模式(又叫星系模式)。多維模型設計的最大優點在于訪問的高效性。
兩種模型的區別
作為數據倉庫設計的基礎,星形連接和關系型結構兩者之間存在很多不同。最重要的區別是在靈活性和性能方面。關系模型具有高靈活性,但是對用戶來說在性能方面卻不是很理想的。多維模型在滿足用戶需求方面是非常高效的,但是靈活性不好。
另一重要區別在于設計的范圍不同。必然地,多維設計只能在有限的范圍內進行,也就是說,數據庫設計只能在一組請求過程下得到最優化。如果所有不同組請求全部加入到設計當中,最優化變得毫無意義。
當使用關系模型時,在性能方面沒有特別的優化方法。既然關系模型要求數據以最低粒度級存儲,那么就可以無限制地添加新數據。很顯然,添加數據到關系 模型永遠也不會停止。正因為這樣,關系模式適合大范圍數據(如一個企業模型),而多維模型適用于小范圍數據(如一個部門或甚至一個子部門)。
區別的起源:
關系環境是通過起源數據模型設計出來的。多維模型是根據最終用戶的請求塑造的。換句話說,關系模型通過純數據模型和其他模式設計,而多維模型通過處理請求塑造。
在適用性方面:由于關系模型通過抽象數據形成,所以模型自身非常靈活。但這種靈活性,對于直接數據訪問的執行卻不是最優化的。如果想得到一個高性能的關系模型,最佳方法是從模型中抽取出數據,并重新構造一種適合于快速訪問的模式。
多維模型在直接訪問數據方面是快速而高效的。從體系結構觀點來看,在數據倉庫設計基礎方面關系模型是更好地支持數據倉庫的模式,其原因是,數據倉庫需要根 據不同的議程和多種觀察數據的方式來支持許多不同的用戶組。也就是說,數據倉庫對于訪問已給定的用戶并不是最佳的。相反,數據倉庫可以以多種方式支持多個 不同的用戶。
關系模式,數據以最低粒度級和標準化形式存儲;關系表間的關系已經定義好并且包含一個含有外鍵的關鍵字表;新表可以對關系表中的基本數據集定義新的 匯總和篩選標準;也就是說可以很簡單以一種形式創建關系表,再以另一種形式重新塑造這些表,這樣做對于數據倉庫環境來說是非常理想的。
此外,關系模式支持將來未知的需求、支持適度變化的需求方面具有多維模型無法比擬的優勢。
因此根據上面討論過的原因可以看出:關系模型對數據倉庫是理想的基礎,而星形連接對于數據集市是最佳的。
獨立集市和從屬集市的區別:
獨立集市是指直接通過歷史應用創建的數據集市。建立獨立數據集市不需要有“全局思想”考慮。
與獨立數據集市相對應的是從屬數據集市。從屬數據集市是利用來自數據倉庫的數據建立的。它的數據源不依賴與歷史數據或操作型數據,只依賴于數據倉庫。總之,從屬數據集市要求有預先的計劃、長期的觀察、全局的分析和企業各不同部門對需求分析的合作與協調。
建立多個獨立數據集市后,很快用戶就會發現數據集市之間的信息不統一,也不同步,而且每增加一個數據集市就會出現不斷增長的細節數據冗余的問題,需要大量的資源來建立接口程序,維護這些程序也變成了負擔。因此獨立數據集市不適合與解決企業中的信息問題。
當然,如果企業采用了從屬數據集市,并在建立任何數據集市之前先創建了一個數據倉庫,那么,獨立數據集市固有的哪些體系結構方面的問題就不會出現了。
換句話說,獨立數據集市表示的是不需要顧及全局及全景的一個短期的、有限范圍的解決方法。另一方面,從屬數據集市則要求一個長期和全局的展望。但是獨立數據集市不能為企業信息提供一個堅實的基礎,而從屬數據集市確能為信息決策提供了一個真正的長期基礎。
-
數據倉庫
+關注
關注
0文章
61瀏覽量
10457 -
多維數據庫
+關注
關注
0文章
2瀏覽量
1478
發布評論請先 登錄
相關推薦
什么是數據倉庫?數據倉庫的優勢分析
多版本數據倉庫模型設計
銀行數據倉庫的系統設計與實現
數據庫與數據倉庫的區別
數據倉庫的OLAP多維展現技術的研究與應用

保護MySQL數據倉庫的最佳實踐
數據倉庫是什么_數據倉庫的特點_數據倉庫與數據庫區別
多維數據庫有哪些
數據倉庫是什么_數據倉庫有什么特點_數據庫和數據倉庫區別分析
如何建設企業級數據倉庫_多維數據庫模型的設計你知道多少
數據庫發展史2--數據倉庫





 工商網監
工商網監
評論