 高密度Interposer封裝設計的SI分析
高密度Interposer封裝設計的SI分析
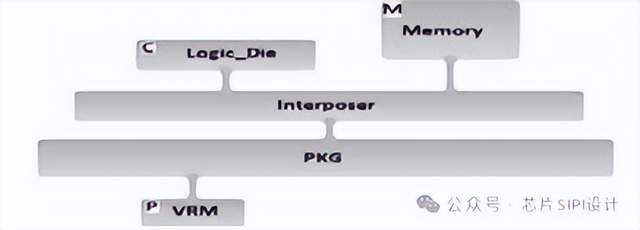
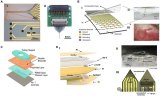
為了克服硅中間層技術的尺寸限制,并實現更好的處理器和存儲器集成,開發了一種基于硅interposer的新型2.5D SiP,如圖所示。多個芯片集成在一個接口層(interposer)上,用高密度、薄互連連接,這種高密度的信號,再加上硅interposer設計,需要仔細的設計和徹底的時序分析。

對于需要在處理器和大容量存儲器單元之間進行高速數據傳輸的高端內存密集型應用程序來說,走線寬度和長度是一個主要挑戰。HBM以更小的外形實現更高的帶寬,同時使用更少的功耗,interposer技術最適合峰值帶寬、每瓦帶寬和每區域容量是有價值指標的應用,例如圖形應用處理器單元(gpu)、高性能計算、服務器、網絡和客戶端應用。
下圖為Si interposer設計側視圖:兩個芯片并排放置,通過金屬層走線連接。硅interposer用于建立具有高密度凸點的die to die連接。其他連接則通過interposer直接連接到IC封裝基板。給出了芯片RDL在集成電路設計環境中的布局,以及封裝設計環境中芯片RDL在封裝頂部的布局。

為了獲得良好的SI性能,系統封裝必須具有低傳輸損耗和短信號路徑達到所要求的電氣規格,由于高密度互連路由,interposer集成導致新的電氣挑戰。總功耗的降低要求在盡可能低的電壓和最高可靠的頻率下運行。這導致需要將電感與位于晶體管上的decap,以保持電壓,獨立于正在執行的操作,并降低接地電阻。由于必須在一個封裝中平衡多種要求,例如降低電壓,增加晶體管數量,以及模擬和混合信號設計,因此提出了新的挑戰。
下圖顯示了帶有邏輯和存儲芯片的interposer層的示意圖,兩個DIE并排組裝,使用細銅線來進行DIE to DIE連接。

整個存儲系統使用硅interposer集成到封裝中,如下圖所示,interposer尺寸為30mm × 25mm。中間層頂部附有20mm × 24mm的高性能處理器芯片。完全集成的內存系統包括四層HBM內存,帶寬為512GB/s。處理器和HBM都使用micro bump連接到interposer上。interposer通過傳統的倒裝芯片bump安裝在基板上,處理器有189000個micro bumps,中間處理器有34000多個倒裝芯片bump。四個DIE以2.5mm的間隙并排放置。線寬為2μm實現了die to die連接,為了提高布局的性能,處理器DIE被分成六個具有相同數量bump的DIE,從D1到D6,如下圖所示。

下圖顯示了回波損耗和插入損耗,左圖顯示回波損耗小于-22dB,可以支持最高可達2800MT/s interposer數據傳輸設計;右圖顯示了PoP設計的回波損耗和插入損耗。在2800MT/s傳輸速率的介面設計中,插入損耗為-1dB。
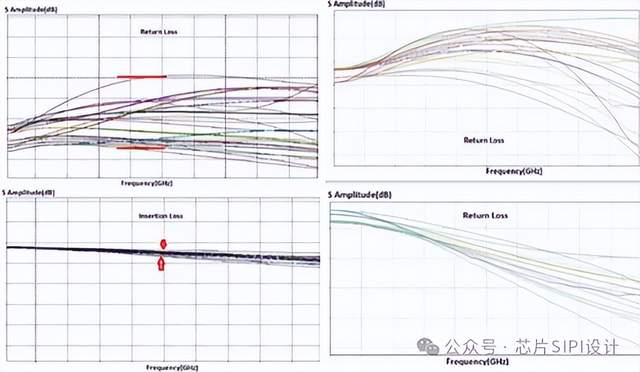
結果表明,與傳統的PoP 技術相比,interposer具有更好的回波損耗和插入損耗性能。回波損耗提高了-8dB,反演損耗提高了-1dB,通過在互連之間使用接地保護帶,可以最大限度地減少interposer中的串擾。接下來是進行時域分析,下圖是含有interposer結構的仿真拓撲。
在仿真中,interposer表示與HBM互連的處理器的s參數,為了準確地仿真IO切換行為,IBIS模型分別應用到處理器和HBM模塊中。下圖為POP封裝仿真拓撲。

對于SI分析,時域仿真使用s參數模型來檢查眼圖打開和抖動,為了電源的完整性,s參數可以簡化為檢查頻域的輸入阻抗曲線。
眼高和抖動通過眼圖仿真得到,interposer和PoP設計的仿真結果分別如下圖左右所示。與PoP封裝相比,左側為帶有interposer設計,右側結果為Pop封裝結果,可以看到interposer的設計有更大的眼圖開窗。

與 PoP設計相比,interposer設計中的抖動也更好,interposer中HBM和處理器芯片之間的互連長度更小/更短,這都表明interposer技術提高了SI 的性能。
聲明:本網站部分文章轉載自網絡,轉發僅為更大范圍傳播。 轉載文章版權歸原作者所有,如有異議,請聯系我們修改或刪除。聯系郵箱:viviz@actintl.com.hk, 電話:0755-25988573
審核編輯 黃宇
-
封裝
+關注
關注
126文章
7914瀏覽量
142993 -
PCB
+關注
關注
1文章
1807瀏覽量
13204
發布評論請先 登錄
相關推薦
揭秘高密度有機基板:分類、特性與應用全解析

什么是高密度DDR芯片
高密度互連,引爆后摩爾技術革命
用于800V牽引逆變器的SiC MOSFET高密度輔助電源

mpo高密度光纖配線架解析

高密度光纖配線架怎么安裝
使用"預成型AuRoFUSETM"實現高密度封裝





 工商網監
工商網監
評論