

今天,給大家分享一篇來(lái)自知乎的一篇關(guān)于目標(biāo)檢測(cè)相關(guān)的一些內(nèi)容,
本文基于Pytorch進(jìn)行編寫(xiě)。
在閱讀這篇博文之前,如果讀者真的是還沒(méi)有接觸過(guò)這個(gè)目標(biāo)檢測(cè)的話,作者建議可以先看看這幾篇文章再來(lái):
GitHub 水項(xiàng)目之 快速上手 YOLOV5
(https://blog.csdn.net/FUTEROX/article/details/124079281)
YOLOV5 參數(shù)設(shè)定與模型訓(xùn)練的坑點(diǎn)一二三
(https://blog.csdn.net/FUTEROX/article/details/124079281)
YOLOV1論文小整理
(https://blog.csdn.net/FUTEROX/article/details/124111506)
在代碼部分還參考了原先這篇博文的設(shè)計(jì):
嘿~全流程帶你基于Pytorch手?jǐn)]圖片分類(lèi)“框架“--HuClassify
那么本文兩個(gè)目標(biāo):
一. 理論
搞清楚什么是目標(biāo)檢測(cè)
目標(biāo)檢測(cè)的重難點(diǎn)
相關(guān)目標(biāo)檢測(cè)算法思想
如何設(shè)計(jì)一個(gè)目標(biāo)檢測(cè)算法
二. 編碼
voc數(shù)據(jù)集的細(xì)節(jié)
目標(biāo)檢測(cè)網(wǎng)絡(luò)
目標(biāo)分類(lèi)網(wǎng)絡(luò)
相關(guān)算法
其中的理論部分像我說(shuō)不會(huì)太深入只是快速入門(mén),編碼部分的話倒是有很多相關(guān)算法的實(shí)現(xiàn)。那么編碼的話在目標(biāo)檢測(cè)部分的網(wǎng)絡(luò),我們也是直接使用yolo的網(wǎng)絡(luò),當(dāng)然這里還是會(huì)做改動(dòng)的。這篇博文的更多的一個(gè)目的其實(shí)還是說(shuō)搭建一個(gè)簡(jiǎn)單的目標(biāo)檢測(cè)平臺(tái),這樣感興趣的朋友可以自己DIY,對(duì)我本人的話也是有DIY的需求。
那么廢話不多說(shuō),馬上發(fā)車(chē)了!
目標(biāo)檢測(cè)
要說(shuō)到目標(biāo)檢測(cè)的話,那么我們就不得不先說(shuō)到圖片分類(lèi)了。
因?yàn)閳D片分類(lèi)在我們的目標(biāo)檢測(cè)當(dāng)中是非常重要的但是二者的區(qū)別也是存在的,不過(guò)他們之間卻有很多相似的地方。
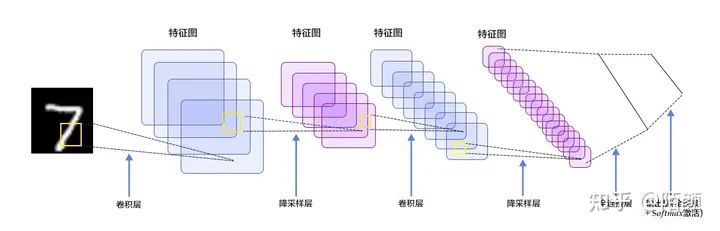
圖片分類(lèi)
圖片分類(lèi)是一個(gè)非常經(jīng)典的問(wèn)題,給定一張圖片然后對(duì)這個(gè)圖片進(jìn)行分類(lèi),它的任務(wù)非常簡(jiǎn)單,并且設(shè)計(jì)一個(gè)這樣的網(wǎng)絡(luò)也非常簡(jiǎn)單。
你只需要使用一定量的卷積,最后和一定量的全連接網(wǎng)絡(luò)輸出一組大小和類(lèi)別的最后一個(gè)維度一樣的tensor就行了,然后使用交叉熵作為你的損失函數(shù)。
比如最簡(jiǎn)單的分類(lèi)網(wǎng)絡(luò):LeNet
class LeNet(nn.Module):
def __init__(self,classes):
super().__init__()
self.feature = Sequential(
nn.Conv2d(3,6,kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2)
)
self.classifiar = nn.Sequential(
nn.Linear(16*5*5,120), # B
nn.ReLU(),
nn.Linear(120,84),
nn.ReLU(),
nn.Linear(84,classes)
)
def forward(self,x):
x = self.feature(x)
x = x.view(x.size()[0],-1)
x = self.classifiar(x)
return x
def initialize_weights(self):
#參數(shù)初始化,隨便給點(diǎn)權(quán)重,這樣的話會(huì)加快一點(diǎn)速度(訓(xùn)練)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, 0, 0.1)
m.bias.data.zero_()
我們只需要輸入一張圖片就闊以得到這張圖片的類(lèi)別。
但是這還是遠(yuǎn)遠(yuǎn)不夠的。
目標(biāo)檢測(cè)
目標(biāo)檢測(cè)則是在圖片分類(lèi)的基礎(chǔ)上,我們還需要知道我們對(duì)應(yīng)的一個(gè)物體的位置,比如下面這張圖:

我們知道這是一只貓,但是在圖片場(chǎng)景當(dāng)中并不是只有一只貓,貓只是圖片當(dāng)中的一個(gè)很明顯的特征,如果做圖片分類(lèi)的話,你說(shuō)這個(gè)是貓可以,但是我說(shuō)這是個(gè)草貌似也可以。所以現(xiàn)在的任務(wù)是我不僅僅要知道這個(gè)圖片有貓,我還要知道這個(gè)貓?jiān)趫D片的位置。

單目標(biāo)檢測(cè)
現(xiàn)在我們假設(shè),我們的圖片只有一個(gè)物體,就如上面的圖片一樣。那么如果我們需要想辦法讓神經(jīng)網(wǎng)絡(luò)得到這樣一個(gè)框的,當(dāng)然在此基礎(chǔ)上,我們還需要得到對(duì)應(yīng)的概率,也就是,如果圖片只有一個(gè)目標(biāo)的話,我們只需要在原來(lái)的基礎(chǔ)上想辦法多生成一組對(duì)應(yīng)的框的坐標(biāo)就可以了。也就是說(shuō),我們以上面的LeNet網(wǎng)絡(luò)為例子。我們可以這樣干。
我們只要把原來(lái)的那個(gè)直接輸出概率的那一個(gè)全連接層拆掉,然后再來(lái)幾個(gè)全連接層之后分別預(yù)測(cè)就完了。
至于損失函數(shù),這也好辦,一個(gè)是交叉熵得到Loss1 還有一個(gè)是求方差,求對(duì)應(yīng)的框的點(diǎn)和標(biāo)注的框的誤差就完了得到Loss2 之后Loss=Loss1+Loss2
多目標(biāo)檢測(cè)
然而理想是很豐滿的,但是現(xiàn)實(shí)很殘酷。現(xiàn)在的圖片當(dāng)中往往都是有多個(gè)目標(biāo)的,而且哪怕是同一個(gè)目標(biāo),在一張圖片當(dāng)中也可能有多個(gè),那問(wèn)題不就尷尬了,比如下面的圖片:

所以我們需要解決這個(gè)問(wèn)題。
問(wèn)題分析
首先我們來(lái)想想,我們現(xiàn)在面臨的問(wèn)題,首先對(duì)于一張圖片,對(duì)送進(jìn)神經(jīng)網(wǎng)絡(luò)的圖片來(lái)說(shuō)(假設(shè)數(shù)據(jù)集不是我們 自己搞的)我們是不知道當(dāng)前這個(gè)圖片它是有幾個(gè)目標(biāo)的,所以如果是按照咱們先前那個(gè)對(duì)LeNet的改動(dòng)的話,我們是壓根就不知道要生成幾個(gè)框,做幾個(gè)概率的預(yù)測(cè)的。假設(shè)我們知道了,或者說(shuō)我們一股腦直接生成一堆框,那么我們需要如何篩選這些有用的框出來(lái)?并且我們?cè)趺磪^(qū)別這些框?qū)?yīng)的類(lèi)別是啥?最后我們的損失函數(shù)又要怎么設(shè)計(jì)?
那么如果我們能夠找到一種方式能夠搞定上面的問(wèn)題,那么多目標(biāo)檢測(cè)應(yīng)該就能夠?qū)崿F(xiàn)了,換句話說(shuō)能夠通用的目標(biāo)檢測(cè)算法就ok了。
滑動(dòng)窗口
前面分析了我們?nèi)绻胍獙?shí)現(xiàn)那個(gè)多目標(biāo)檢測(cè),我們需要解決的問(wèn)題。那么第一個(gè)問(wèn)題,如何生成框。回到一開(kāi)始的方式,我們是直接輸入了一張圖片,然后,對(duì)這張圖片生成一個(gè)框,然后做預(yù)測(cè)等操作,那么既然如此,那么我就直接這樣,我把一張圖片直接分成一個(gè)個(gè)區(qū)域,相當(dāng)于截圖一樣,一個(gè)一個(gè)區(qū)域截圖,然后分別送進(jìn)神經(jīng)網(wǎng)絡(luò)。然后你懂的,我們套用剛剛提出的方法。
也就是下面這樣
我可以生成不同的滑動(dòng)窗口,然后瘋狂搞。
理論上只要電腦不冒煙,我就可以一直搞。只要效率顯然….
所以還需要優(yōu)化一下。
RCNN
那么這個(gè)時(shí)候,你可能會(huì)想了,剛剛的問(wèn)題難度在于我們很難去得到這些框,因?yàn)樽龇诸?lèi)對(duì)我們來(lái)說(shuō)還是非常簡(jiǎn)單的事情,但是做檢測(cè),偏偏有個(gè)預(yù)測(cè)框很難弄。如果我們可以直接得到一堆候選框,然后對(duì)每一個(gè)框所屬的類(lèi)別進(jìn)行預(yù)測(cè)之后再采用某一種方法去篩選出合適的框不久變得簡(jiǎn)單了嘛。
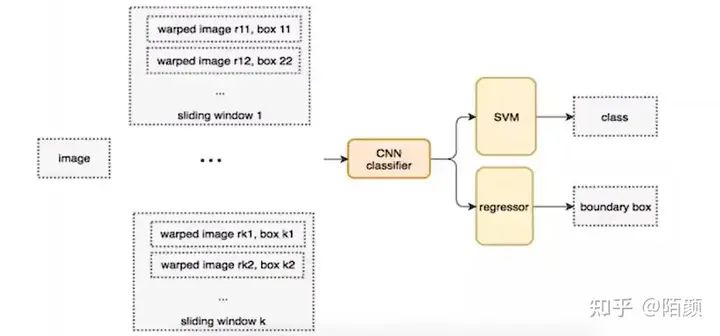
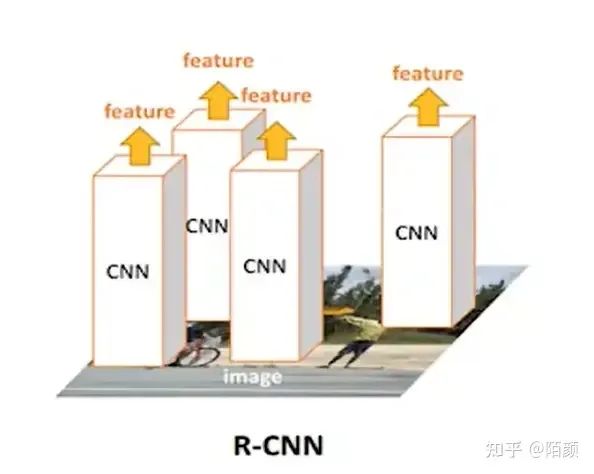
那么這個(gè)時(shí)候RCNN出現(xiàn)了,在2014年的時(shí)候,那個(gè)時(shí)候我應(yīng)該還是個(gè)小學(xué)生。它的流程是這樣的:
對(duì)于一張圖片,找出默認(rèn)2000個(gè)候選區(qū)域
2000個(gè)侯選區(qū)域做大小變換,輸入AlexNet當(dāng)中,得到特征向量 [2000,4096]
經(jīng)過(guò)20個(gè)類(lèi)別的SVM分類(lèi)器,對(duì)于2000個(gè)候選區(qū)域做判斷,得 到[2000,20]得分矩陣
2000個(gè)候選區(qū)域做NMS,取出不好的,重度高的一些候選 區(qū)域,得到剩下分?jǐn)?shù)高,結(jié)果好的相
修正候選框,bbox的回歸微調(diào)
那么現(xiàn)在既然提到了RCNN,那么我們現(xiàn)在就不得不先提到兩個(gè)概念了,第一是IOU,第二是NMS算法也就是那個(gè)篩選算法。
不過(guò)在這里我先說(shuō)一些IOU,因?yàn)镹MS在代碼階段會(huì)詳細(xì)介紹,我們需要手動(dòng)實(shí)現(xiàn)這個(gè)算法,當(dāng)然IOU也需要,但是它非常簡(jiǎn)單。
就是這個(gè)東西
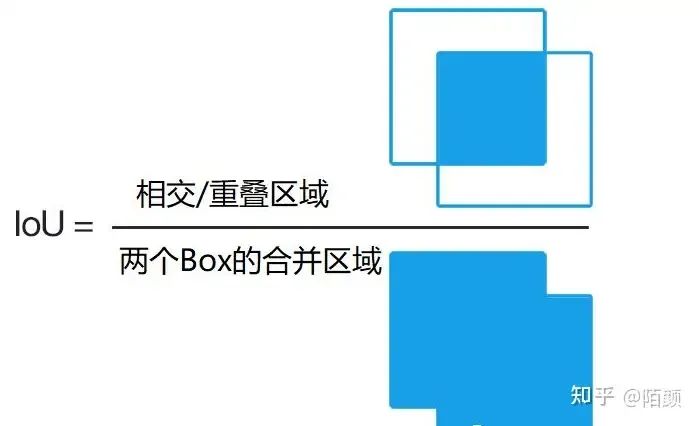
我們可以用這個(gè)玩意來(lái)衡量這兩個(gè)生成的框是不是重合了,重合了多少,如果重合太多的話,是不是說(shuō)他們兩個(gè)框都在預(yù)測(cè)同一個(gè)物體,那么我們就可不可以把概率低的給干掉。而這個(gè)的話其實(shí)也是NMS的思想,具體還是看下文。
那么這里解決了可以自動(dòng)生成框的問(wèn)題,但是這里的分類(lèi)器用的還是SVM,并且這個(gè)SVM肯定也是需要先訓(xùn)練好的,不然很難完成分類(lèi)呀。而且在訓(xùn)練SVM的時(shí)候,我們是把經(jīng)過(guò)了一個(gè)神經(jīng)網(wǎng)絡(luò)的數(shù)據(jù)給SVM的,那么意味還需要對(duì)AlexNet做處理,需要緩存很多中間數(shù)據(jù)然后訓(xùn)練。
而且每一個(gè)框都要進(jìn)入神經(jīng)網(wǎng)絡(luò),2000個(gè)要進(jìn)去似乎也沒(méi)有比暴力好到那兒去。
SPPNet
前面說(shuō)了RCNN,其實(shí)最大的一個(gè)改進(jìn)相對(duì)于滑動(dòng)窗口來(lái)說(shuō),似乎就是多了一個(gè)方式去生成候選框。實(shí)際上后面那些SVM我們也未嘗不可以和AlexNet直接合并成一個(gè)大網(wǎng)絡(luò)然后對(duì)2000個(gè)候選框做分類(lèi),而不是分開(kāi)來(lái)。
但是最大的問(wèn)題并不是這個(gè),問(wèn)題在于我們還是需要進(jìn)入2000次卷積。
那么有沒(méi)有辦法可以減少卷積咧,有SPPNet!
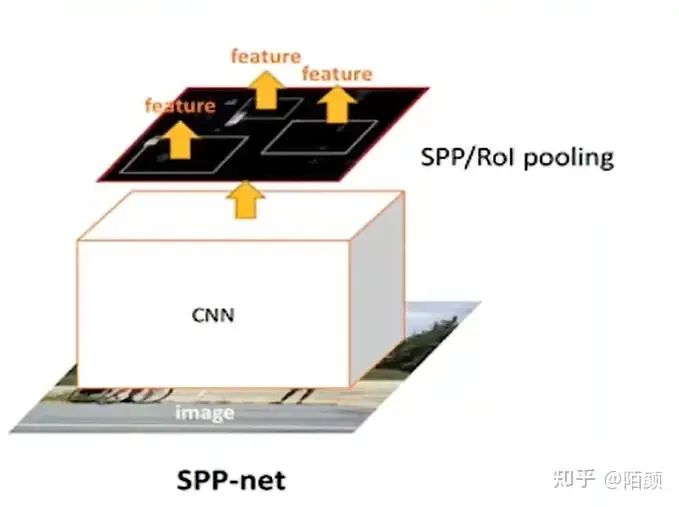
首先候選框還是咱們RCNN那種方式提取出來(lái)的,但是它直接把一張圖片輸入進(jìn)一個(gè)卷積里面。
然后得到一個(gè)特征向量,之后這個(gè)特征向量里面包含了原來(lái)的候選框的信息,他們之間存在這樣的映射關(guān)系:
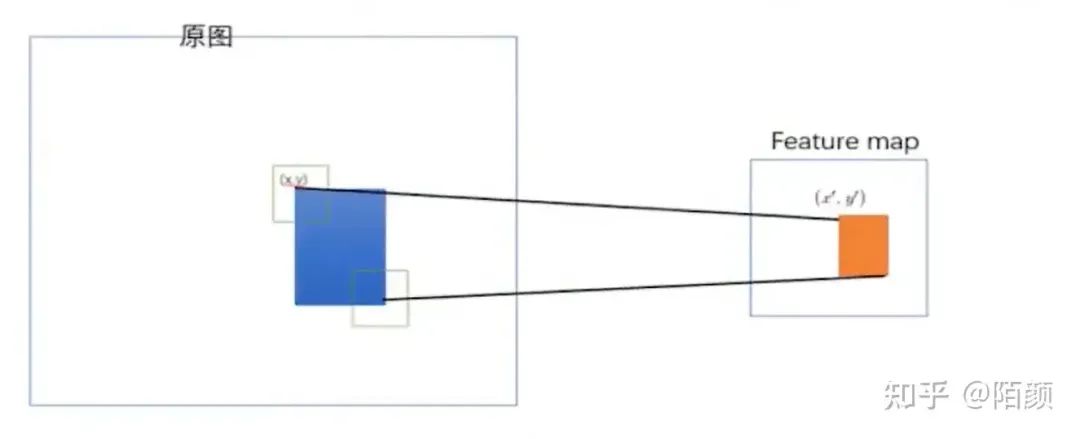
這個(gè)映射關(guān)系的不是咱們的重點(diǎn),這里就忽略了,感興趣的可以自己去了解,不夠這個(gè)拿到feature map 絕對(duì)是目標(biāo)檢測(cè)史上最重要的一點(diǎn)之一!不過(guò)在這里還沒(méi)有太大體現(xiàn)。
那么后面的操作其實(shí)就和RCNN類(lèi)似了,只是中間又加了一些池化等等操作
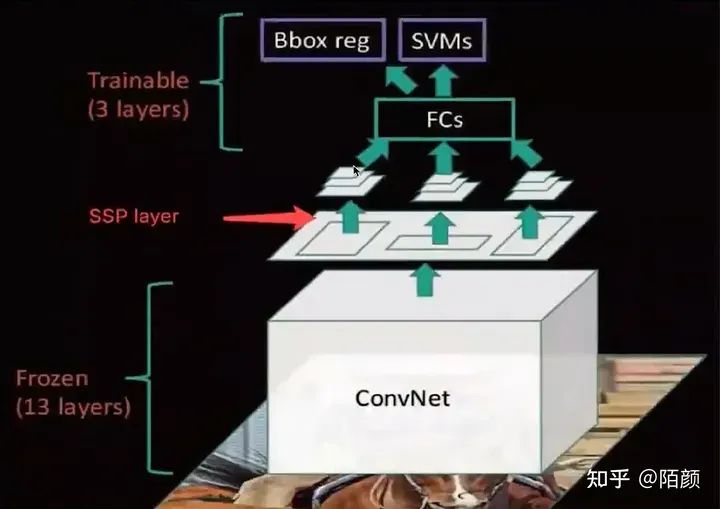
至于缺點(diǎn):
1. 訓(xùn)練依然過(guò)慢、效率低,特征需要寫(xiě)入磁盤(pán)(因?yàn)镾VM的存在)
2. 分階段訓(xùn)練網(wǎng)絡(luò):選取候選區(qū)域、訓(xùn)練CNN、訓(xùn)練SVM、訓(xùn)練bbox回歸器,SPPNet)反向傳播效率 低
Fast-RCNN
當(dāng)我把標(biāo)題單獨(dú)放在外面的時(shí)候,我想你應(yīng)該知道了這玩意的重要性。
來(lái)我們直接看到整個(gè)圖:
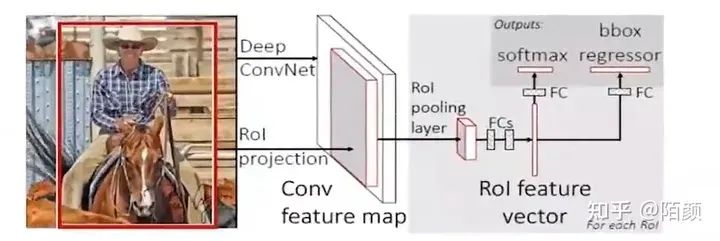
前面的部分其實(shí)和SPPNet很像,也就是一個(gè)卷積,但是后面全部變成 net,這個(gè)好像有點(diǎn)像咱們一開(kāi)始瞎扯提到的方式了,也就是在后半部分。不過(guò)有點(diǎn)可惜的是總體上FastRCNN 的改進(jìn)其實(shí)是把SPPNet后面的東西改了,前面的候選框其實(shí)還是使用RCNN的那一套機(jī)制,也就是SS算法。
不夠盡管如此,fast rcnn 總算是和咱們現(xiàn)在的目標(biāo)檢測(cè)算法的樣子有點(diǎn)像了,因?yàn)槲覀兘K于廢棄了SVM,終于讓我們的神經(jīng)網(wǎng)絡(luò)去做更多的事情了。
并且提到了咱們的多任務(wù)損失,而且不用把網(wǎng)絡(luò)拆來(lái)了訓(xùn)練了,而是可以做到端到端了。
并且速度有了很大的提升
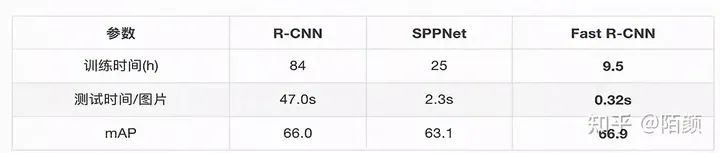
之后它的網(wǎng)絡(luò)圖是這樣的:
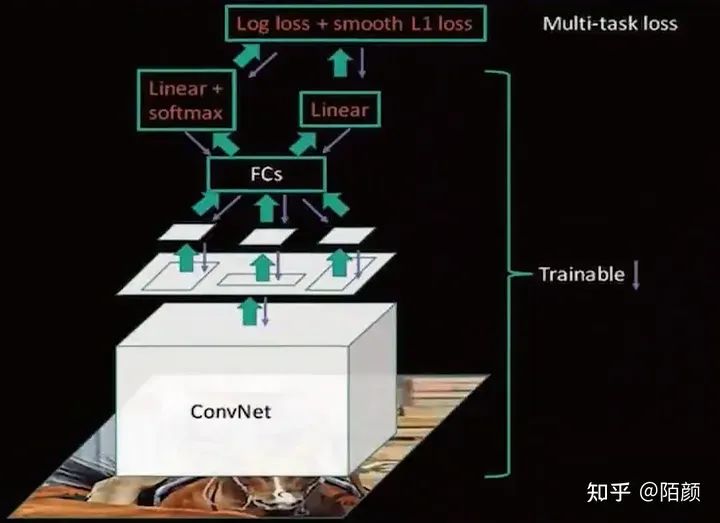
那么雖然已經(jīng)很快了,那么還有辦法嘛?原來(lái)RCNN 可是2000個(gè)候選區(qū)域啊。能不能縮減!有沒(méi)有辦法?
(這里面還有很多細(xì)節(jié)沒(méi)有提到,需要讀者自行搜索,不過(guò)不影響本文觀看)
答案是有!
Faster RCNN
前面我們的FastRCNN 已經(jīng)讓神經(jīng)網(wǎng)絡(luò)做了很多事情了,那么為什么不能把候選框的提取也做了,讓神經(jīng)網(wǎng)絡(luò)做到更多的事情?并且還有哪些東西是可以加強(qiáng)改進(jìn)的?feature map 能不能利用起來(lái)?
嘿!還真能。
我們直接在feature map上面做提取,在上面生成候選區(qū)域,然后再執(zhí)行后續(xù)操作,后續(xù)操作和咱們fast rcnn是一樣的,我們只需要對(duì)這些候選框和分類(lèi)器處理。于是我們的網(wǎng)絡(luò)結(jié)構(gòu)就變成了這樣
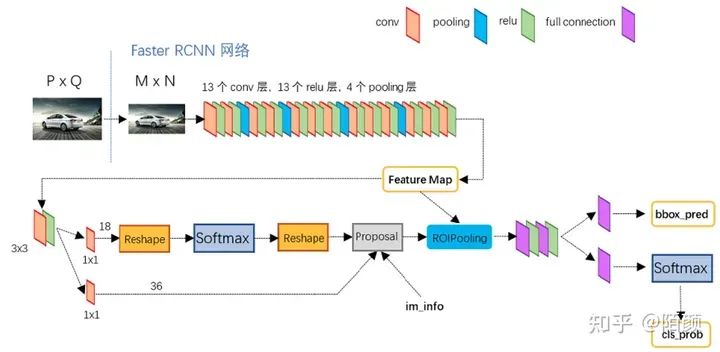
在feature后面提取的網(wǎng)絡(luò)叫做RPN
RPN 工作流程
說(shuō)到這個(gè)玩意咱們就必須提一下,因?yàn)檫@個(gè)東西的工作流程絕對(duì)是非常重要的,這意味著我們可以做出更大的改進(jìn)在后面!
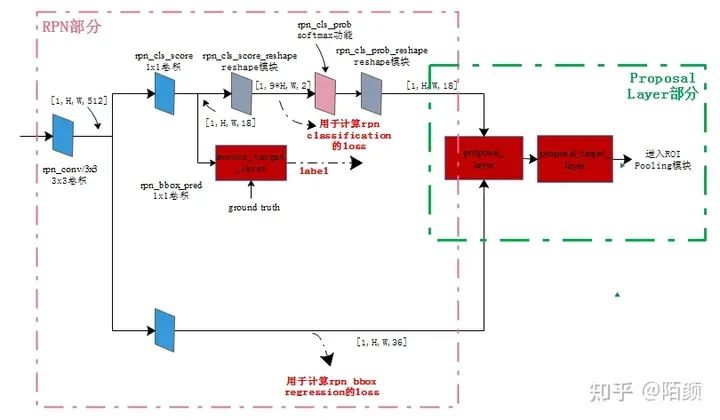
我們知道它的工作地方實(shí)在feature map上面
那么他如何工作呢。
這里引入一個(gè)名稱(chēng)叫做anchor 其實(shí)也就是bbox,那個(gè)預(yù)測(cè)框。
他是這樣的,在那個(gè)feature map 的基礎(chǔ)上,每一個(gè)網(wǎng)格,都會(huì)生成9個(gè)框,假設(shè)那個(gè)特征是20x20 的那么他有9個(gè)就是20x20x9 如果要具體表示的話,xmin,ymin,xmax,ymax(左上角,右下角)那就是20x20x36的張量
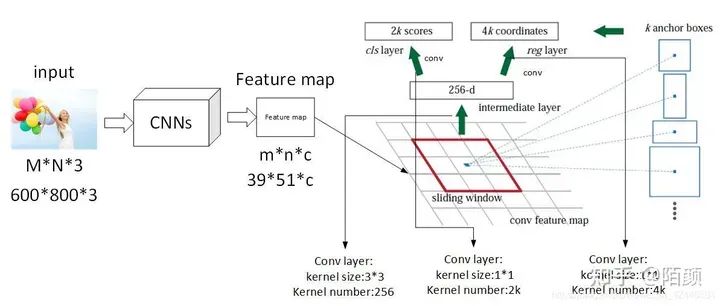
那么這里為什么是9個(gè)呢,因?yàn)槭沁@樣的,原作者設(shè)計(jì)了三種比例三種大小的樣式,因?yàn)閳D片當(dāng)中物體的大小是不一樣的。
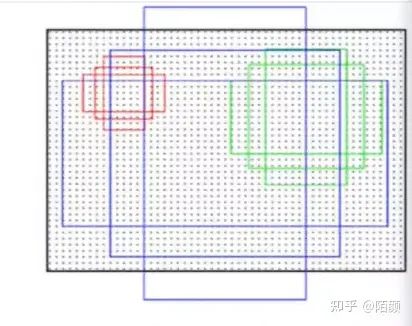
那么剛好對(duì)應(yīng)的就是9個(gè)組合。之后的部分我就不細(xì)說(shuō)了。
Yolo
那么到這里,你可能又有疑問(wèn)了,那個(gè)RPN一樣的網(wǎng)絡(luò)能不能放在featur map 前面呢?如果我一開(kāi)始就指定好圖片的網(wǎng)格,然后不同的網(wǎng)格去生成候選框會(huì)怎么樣?
沒(méi)錯(cuò)大名鼎鼎的yolo出來(lái)了:(這里是v1)
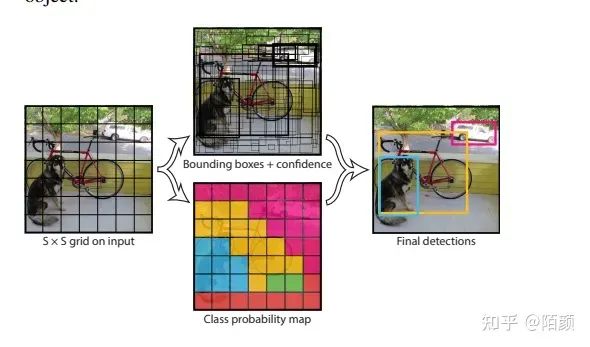
我先直接這樣認(rèn)為分成7x7的格子然后每個(gè)格子產(chǎn)生候選框,這里是2個(gè)候選框。
之后得到7x7x30的張量.
這里解釋一下30里面包含了啥。
這里面存儲(chǔ)了 兩大類(lèi)信息。
第一個(gè) 是 邊框信息,起點(diǎn),寬高,可信度。
第二個(gè)是 類(lèi)別的條件概率,這里主要是20個(gè)類(lèi)。
之后我們通過(guò)NMS對(duì)這些候選框進(jìn)行篩選。
然后進(jìn)入損失函數(shù),這部分我們后面說(shuō),它的損失函數(shù)是這樣的

我們接下來(lái)要自制的目標(biāo)檢測(cè)框架其實(shí)也是基于yolov1的。
小結(jié)
那么對(duì)于理論部分我們就先到這里,這里面的話還是有很多細(xì)節(jié)是沒(méi)有說(shuō)到的,例如Fast rcnn 里面,我們NMS處理以后,我們的那些剩下的框雖然是知道了所屬的分類(lèi),但是我們回歸的時(shí)候我們是和那些手動(dòng)標(biāo)注的框進(jìn)行回歸?這部分我沒(méi)有說(shuō),由于篇幅問(wèn)題,這部分也是需要讀者自行探索,其實(shí)讀者也可以大膽猜測(cè)一下和IOU有沒(méi)有關(guān)系咧?此外還有其他的優(yōu)秀算法沒(méi)有介紹到,比如SSD等等。
當(dāng)然前面的大部分內(nèi)容只是做了解即可,因?yàn)楦油暾膶⒃诖a部分進(jìn)行。
編碼
接下來(lái)我們將針對(duì)yolov1 算法進(jìn)行實(shí)現(xiàn)然后將其封裝進(jìn)去咱們自己搭建的平臺(tái)。
那么對(duì)我們的編碼實(shí)現(xiàn)里面最主要的其實(shí)有三個(gè)大點(diǎn):
圖片數(shù)據(jù)怎么處理,怎么對(duì)圖片進(jìn)行預(yù)處理
IOU, NMS 算法的具體實(shí)現(xiàn)
損失函數(shù)的設(shè)計(jì)
首先是咱們的第一點(diǎn),對(duì)圖片是否需要,如何進(jìn)行預(yù)處理。
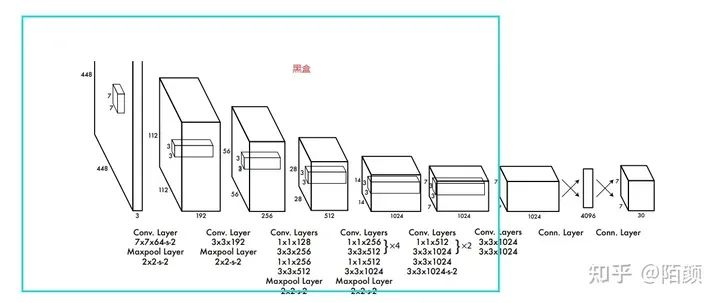
神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)
我們這邊的話是打算直接集成yolov1的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。
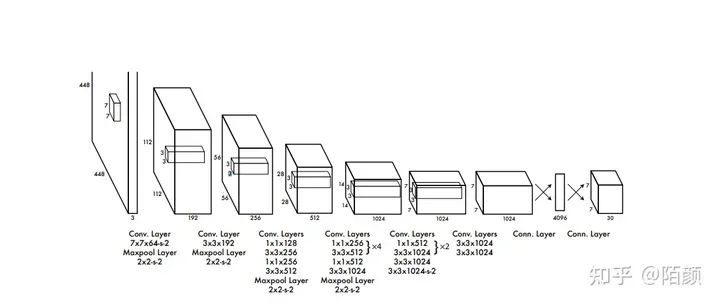
所以的話我們需要先編寫(xiě)神經(jīng)網(wǎng)絡(luò)。但是呢,為了更好地提高網(wǎng)絡(luò)識(shí)別的精度和訓(xùn)練效率,我們這邊還要考慮預(yù)訓(xùn)練一個(gè)神經(jīng)網(wǎng)絡(luò)模型。
所以為了實(shí)現(xiàn)這個(gè)效果我們需要對(duì)這個(gè)網(wǎng)絡(luò)做一點(diǎn)點(diǎn)的改動(dòng),提取出一個(gè)骨干網(wǎng)絡(luò)出來(lái)。
其中BackBone就是我們的核心網(wǎng)絡(luò),也就是其中的10幾個(gè)卷積,后面兩個(gè)一個(gè)是特征提取網(wǎng)絡(luò)一個(gè)是我們用于目標(biāo)識(shí)別的網(wǎng)絡(luò)。我們預(yù)訓(xùn)練是訓(xùn)練特征提取網(wǎng)絡(luò),這個(gè)網(wǎng)絡(luò)是依托與骨干網(wǎng)絡(luò)的。他們之間的關(guān)系是這樣的:

特征提取網(wǎng)絡(luò)其實(shí)就是在骨干網(wǎng)絡(luò)的基礎(chǔ)上用于分類(lèi),這樣一來(lái)就得到了權(quán)重,當(dāng)我們訓(xùn)練目標(biāo)檢測(cè)網(wǎng)絡(luò)的時(shí)候,我們可以把先前預(yù)訓(xùn)練的特征網(wǎng)絡(luò)當(dāng)中的骨干網(wǎng)絡(luò)的權(quán)重提取出來(lái)作為初始化權(quán)重,這也就是遷移學(xué)習(xí)。
骨干網(wǎng)絡(luò)
import torch.nn as nn
import torch
from collections import OrderedDict
class Convention(nn.Module):
def __init__(self,in_channels,out_channels,conv_size,conv_stride,padding,need_bn = True):
"""
這邊對(duì)Conv2d進(jìn)行一個(gè)封裝,參數(shù)一致
但是多加了LeakReLU,和歸一化,原因不多說(shuō)了
:param in_channels:
:param out_channels:
:param conv_size:
:param conv_stride:
:param padding:
:param need_bn:
"""
super(Convention,self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, conv_size, conv_stride, padding, bias=False if need_bn else True)
self.leaky_relu = nn.LeakyReLU()
self.need_bn = need_bn
if need_bn:
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
return self.bn(self.leaky_relu(self.conv(x))) if self.need_bn else self.leaky_relu(self.conv(x))
def weight_init(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
class BackboneNet(nn.Module):
"""
骨干網(wǎng)絡(luò),因?yàn)槟莻€(gè)論文中也提到了預(yù)訓(xùn)練的概念
那么這個(gè)預(yù)訓(xùn)練其實(shí)是說(shuō)訓(xùn)練這個(gè)骨干網(wǎng)絡(luò),而這個(gè)
網(wǎng)絡(luò)的話其實(shí)是7x7x30的前半部分
那個(gè)yolo是24卷積+2個(gè)全連接得到7x7x1024之后flatten4096
最后變成7x7x30,然后就是NMS,預(yù)訓(xùn)練需要先訓(xùn)練一個(gè)
分類(lèi)的網(wǎng)絡(luò),所以這部分是不一樣的
"""
def __init__(self):
super(BackboneNet,self).__init__()
"""
用于特征提取的16個(gè)卷積
"""
self.Conv_Feature = nn.Sequential(
Convention(3, 64, 7, 2, 3),
nn.MaxPool2d(2, 2),
Convention(64, 192, 3, 1, 1),
nn.MaxPool2d(2, 2),
Convention(192, 128, 1, 1, 0),
Convention(128, 256, 3, 1, 1),
Convention(256, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
nn.MaxPool2d(2, 2),
Convention(512, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
Convention(512, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
Convention(512, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
Convention(512, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
Convention(512, 512, 1, 1, 0),
Convention(512, 1024, 3, 1, 1),
nn.MaxPool2d(2, 2),
)
self.Conv_Semanteme = nn.Sequential(
Convention(1024, 512, 1, 1, 0),
Convention(512, 1024, 3, 1, 1),
Convention(1024, 512, 1, 1, 0),
Convention(512, 1024, 3, 1, 1),
)
這里可以看到這個(gè)網(wǎng)絡(luò)啥也沒(méi)有,就是一個(gè)最基本的骨架。
特征提取網(wǎng)絡(luò)(預(yù)訓(xùn)練)
import torch
import torch.nn as nn
from Models.Backbone import BackboneNet, Convention
class YOLOFeature(BackboneNet):
def __init__(self,classes_num = 20):
"""
原文說(shuō)的就是20個(gè)所以咱們也就來(lái)個(gè)20
:param classes_num:
"""
super(YOLOFeature,self).__init__()
self.classes_num = classes_num
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.linear = nn.Linear(1024, self.classes_num)
def forward(self, x):
x = self.Conv_Feature(x)
x = self.Conv_Semanteme(x)
x = self.avg_pool(x)
x = x.permute(0, 2, 3, 1)
x = torch.flatten(x, start_dim=1, end_dim=3)
x = self.linear(x)
return x
"""
初始化權(quán)重
"""
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
torch.nn.init.kaiming_normal_(m.weight.data)
m.bias.data.zero_()
elif isinstance(m, Convention):
m.weight_init()
目標(biāo)檢測(cè)網(wǎng)絡(luò)
最后是咱們的目標(biāo)檢測(cè)網(wǎng)絡(luò)。
import torch.nn as nn
import torch
from Models.Backbone import BackboneNet, Convention
class YOLO(BackboneNet):
def __init__(self, B=2, classes_num=20):
super(YOLO, self).__init__()
self.B = B
self.classes_num = classes_num
self.Conv_Back = nn.Sequential(
Convention(1024, 1024, 3, 1, 1, need_bn=False),
Convention(1024, 1024, 3, 2, 1, need_bn=False),
Convention(1024, 1024, 3, 1, 1, need_bn=False),
Convention(1024, 1024, 3, 1, 1, need_bn=False),
)
self.Fc = nn.Sequential(
nn.Linear(7 * 7 * 1024, 4096),
nn.LeakyReLU(inplace=True, negative_slope=1e-1),
nn.Linear(4096, 7 * 7 * (B * 5 + classes_num)),
nn.Sigmoid()
)
self.sigmoid = nn.Sigmoid()
"""
batchx7x7x30讓最后一個(gè)維度對(duì)應(yīng)的類(lèi)別為概率和為1
"""
# self.softmax = nn.Softmax(dim=3)
def forward(self, x):
x = self.Conv_Feature(x)
x = self.Conv_Semanteme(x)
x = self.Conv_Back(x)
x = x.permute(0, 2, 3, 1)
x = torch.flatten(x, start_dim=1, end_dim=3)
x = self.Fc(x)
x = x.view(-1,7,7,(self.B*5 + self.classes_num))
# x[:,:,:, 0 : self.B * 5] = self.sigmoid(x[:,:,:, 0 : self.B * 5])
# x[:,:,:, self.B * 5 : ] = self.softmax(x[:,:,:, self.B * 5 : ])
"""
在pytorch當(dāng)中注釋部分的操作屬于inplace操作,而且在官方文檔當(dāng)中,明確表明
在多交叉熵當(dāng)中,pytorch不需要使用softmax,因?yàn)樵谟?jì)算的時(shí)候是包括了這部分的操作的
并且在yolov1的損失函數(shù)當(dāng)中,計(jì)算的類(lèi)別損失也不是交叉熵
"""
x = self.sigmoid(x)
return x
def initialize_weights(self, net_param_dict):
for name, m in self.named_modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
torch.nn.init.kaiming_normal_(m.weight.data)
m.bias.data.zero_()
elif isinstance(m, Convention):
m.weight_init()
self_param_dict = self.state_dict()
for name, layer in self.named_parameters():
if name in net_param_dict:
self_param_dict[name] = net_param_dict[name]
self.load_state_dict(self_param_dict)
這里要特別注意我注釋的這段代碼:
# x[:,:,:, 0 : self.B * 5] = self.sigmoid(x[:,:,:, 0 : self.B * 5])
# x[:,:,:, self.B * 5 : ] = self.softmax(x[:,:,:, self.B * 5 : ])
接下來(lái)我會(huì)更加詳細(xì)地說(shuō)明
數(shù)據(jù)集編碼
現(xiàn)在我們已經(jīng)知道了咱們這邊的目的有兩個(gè),一個(gè)是要預(yù)訓(xùn)練,一個(gè)是要目標(biāo)檢測(cè)
預(yù)訓(xùn)練數(shù)據(jù)集
其中咱們的預(yù)訓(xùn)練是訓(xùn)練一個(gè)基本的過(guò)程。
那么在這里的話,其實(shí)很簡(jiǎn)單,我們訓(xùn)練的話我們只需要把那個(gè)特征網(wǎng)絡(luò)拿過(guò)來(lái),重點(diǎn)是咱們的這個(gè)預(yù)訓(xùn)練數(shù)據(jù)集怎么來(lái)。
那么這邊的話,如果是老盆友,或者是看來(lái)剛剛開(kāi)頭推薦觀看的文章的朋友應(yīng)該知道,這邊的話我們可以直接把咱們的HuDataSet拿過(guò)來(lái)。
首先這個(gè)數(shù)據(jù)集的定義非常簡(jiǎn)單:
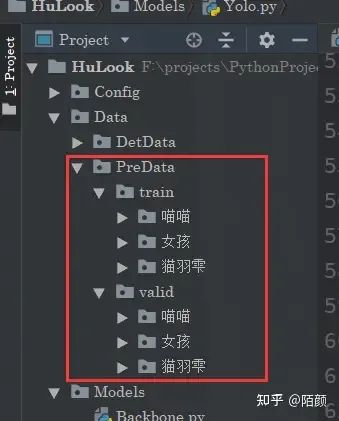
相信你一眼就知道了是怎么一回事。分訓(xùn)練很驗(yàn)證集,然后每個(gè)分類(lèi)的標(biāo)簽放在對(duì)應(yīng)的文件夾下面就可以了。
核心代碼如下:
from Config.Config import * import os from PIL import Image from torch.utils.data import Dataset, DataLoader from torchvision.transforms import transforms from Utils.ReaderProcess.ReadDict import ReadDict class MyDataSet(Dataset): def __init__(self, data_dir,ClassesName, transform=None): self.ClassesName = ClassesName self.label_name = ReadDict.ReadModelClasses(self.ClassesName) self.data_info = self.get_img_info(data_dir) self.transform = transform def __getitem__(self, index): path_img, label = self.data_info[index] img = Image.open(path_img).convert('RGB') if self.transform is not None: img = self.transform(img) return img, label def __len__(self): return len(self.data_info) def get_img_info(self,data_dir): data_info = list() label_dict=ReadDict.ReadModelClasses(self.ClassesName) for root, dirs, _ in os.walk(data_dir): # # 遍歷類(lèi)別 for sub_dir in dirs: img_names = os.listdir(os.path.join(root, sub_dir)) img_names = list(filter(lambda x: x.endswith('.jpg'), img_names)) # 遍歷圖片 for i in range(len(img_names)): img_name = img_names[i] path_img = os.path.join(root, sub_dir, img_name) label = label_dict[sub_dir] data_info.append((path_img, int(label))) return data_info
目標(biāo)檢測(cè)數(shù)據(jù)集
這里的話我們采用VOC數(shù)據(jù)集,數(shù)據(jù)集的基本樣式其實(shí)很簡(jiǎn)單。
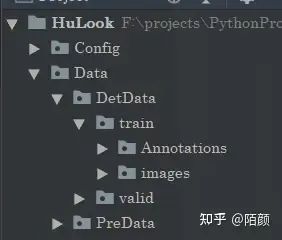
一個(gè)是Annotations注解,還有一個(gè)是圖片
注解里面是xml文件
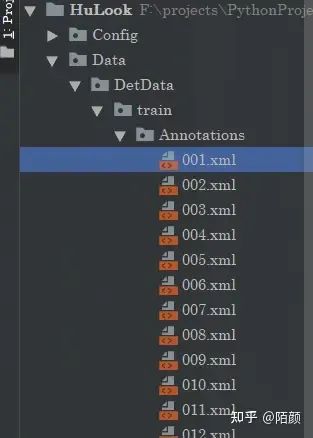
里面包括了類(lèi)別和手動(dòng)標(biāo)注的框的位置。
images 001.jpg F:projectsPythonProjectyolov5-5.0mydataimages01.jpg Unknown 1200 701 3 0
由于我們需要進(jìn)行目標(biāo)檢測(cè),但是呢,我們除了要提取里面的標(biāo)簽信息的話,還要把里面的標(biāo)簽(類(lèi)別,方框)信息進(jìn)行轉(zhuǎn)化,轉(zhuǎn)化的目的也是為了復(fù)合神經(jīng)網(wǎng)絡(luò)的輸出方便損失函數(shù)計(jì)算。
VOC標(biāo)簽解析
解析的話很簡(jiǎn)單,就這個(gè)
for object_xml in objects_xml:
bnd_xml = object_xml.find("bndbox")
class_name = object_xml.find("name").text
if class_name not in self.class_dict: # 不屬于我們規(guī)定的類(lèi)
continue
xmin = round((float)(bnd_xml.find("xmin").text))
ymin = round((float)(bnd_xml.find("ymin").text))
xmax = round((float)(bnd_xml.find("xmax").text))
ymax = round((float)(bnd_xml.find("ymax").text))
class_id = self.class_dict[class_name]
"""
這里解析存儲(chǔ)的是5個(gè)值,縮放,歸一化后的坐標(biāo)和對(duì)應(yīng)的類(lèi)別的標(biāo)簽
"""
coords.append([xmin, ymin, xmax, ymax, class_id])
完整與之配合的代碼是這樣的:
這里還使用了部分?jǐn)?shù)據(jù)增強(qiáng)
import torch
from torch.utils.data import Dataset
import os
import cv2
import xml.etree.ElementTree as ET
import torchvision.transforms as transforms
import numpy as np
import random
from Utils import image
from Config.ConfigTrain import *
class VOCDataSet(Dataset):
def __init__(self, imgs_path="../DataSet/VOC2007+2012/Train/JPEGImages",
annotations_path="../DataSet/VOC2007+2012/Train/Annotations",
is_train=True, class_num=Classes,
label_smooth_value=0.05, input_size=448, grid_size=64): # input_size:輸入圖像的尺度
self.label_smooth_value = label_smooth_value
self.class_num = class_num
self.imgs_name = os.listdir(imgs_path)
self.input_size = input_size
self.grid_size = grid_size
self.is_train = is_train
self.transform_common = transforms.Compose([
transforms.ToTensor(), # height * width * channel -> channel * height * width
transforms.Normalize(mean=(0.408, 0.448, 0.471), std=(0.242, 0.239, 0.234)) # 歸一化后.不容易產(chǎn)生梯度爆炸的問(wèn)題
])
self.imgs_path = imgs_path
self.annotations_path = annotations_path
self.class_dict = {}
class_index = 0
"""
讀取配置標(biāo)簽
"""
for class_name in ClassesName:
self.class_dict[class_name] = class_index
class_index+=1
def __getitem__(self, item):
img_path = os.path.join(self.imgs_path, self.imgs_name[item])
annotation_path = os.path.join(self.annotations_path, self.imgs_name[item].replace(".jpg", ".xml"))
img = cv2.imread(img_path)
tree = ET.parse(annotation_path)
annotation_xml = tree.getroot()
objects_xml = annotation_xml.findall("object")
coords = []
for object_xml in objects_xml:
bnd_xml = object_xml.find("bndbox")
class_name = object_xml.find("name").text
if class_name not in self.class_dict: # 不屬于我們規(guī)定的類(lèi)
continue
xmin = round((float)(bnd_xml.find("xmin").text))
ymin = round((float)(bnd_xml.find("ymin").text))
xmax = round((float)(bnd_xml.find("xmax").text))
ymax = round((float)(bnd_xml.find("ymax").text))
class_id = self.class_dict[class_name]
"""
這里解析存儲(chǔ)的是5個(gè)值,縮放,歸一化后的坐標(biāo)和對(duì)應(yīng)的類(lèi)別的標(biāo)簽
"""
coords.append([xmin, ymin, xmax, ymax, class_id])
coords.sort(key=lambda coord: (coord[2] - coord[0]) * (coord[3] - coord[1]))
if self.is_train:
transform_seed = random.randint(0, 4)
if transform_seed == 0: # 原圖
img, coords = image.resize_image_with_coords(img, self.input_size, self.input_size, coords)
img = self.transform_common(img)
elif transform_seed == 1: # 縮放+中心裁剪
img, coords = image.center_crop_with_coords(img, coords)
img, coords = image.resize_image_with_coords(img, self.input_size, self.input_size, coords)
img = self.transform_common(img)
elif transform_seed == 2: # 平移
img, coords = image.transplant_with_coords(img, coords)
img, coords = image.resize_image_with_coords(img, self.input_size, self.input_size, coords)
img = self.transform_common(img)
elif transform_seed == 3: # 明度調(diào)整 YOLO在論文中稱(chēng)曝光度為明度
img, coords = image.resize_image_with_coords(img, self.input_size, self.input_size, coords)
img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
H, S, V = cv2.split(img)
cv2.merge([np.uint8(H), np.uint8(S), np.uint8(V * 1.5)], dst=img)
cv2.cvtColor(src=img, dst=img, code=cv2.COLOR_HSV2BGR)
img = self.transform_common(img)
else: # 飽和度調(diào)整
img, coords = image.resize_image_with_coords(img, self.input_size, self.input_size, coords)
H, S, V = cv2.split(img)
cv2.merge([np.uint8(H), np.uint8(S * 1.5), np.uint8(V)], dst=img)
cv2.cvtColor(src=img, dst=img, code=cv2.COLOR_HSV2BGR)
img = self.transform_common(img)
else:
img, coords = image.resize_image_with_coords(img, self.input_size, self.input_size, coords)
img = self.transform_common(img)
ground_truth = self.encode(coords)
"""
這里傳入的coords是經(jīng)過(guò)圖片增強(qiáng),然后歸一化之后的
之后的話,我們需要經(jīng)過(guò)encode目的是的為了制作方便后期和pred對(duì)比的label
"""
return img,ground_truth
def __len__(self):
return len(self.imgs_name)
def encode(self, coords):
feature_size = self.input_size // self.grid_size
ground_truth = np.zeros([feature_size, feature_size, 10 + self.class_num],dtype=float)
for coord in coords:
# positive_num = positive_num + 1
# bounding box歸一化
xmin, ymin, xmax, ymax, class_id = coord
ground_width = (xmax - xmin)
ground_height = (ymax - ymin)
center_x = (xmin + xmax) / 2
center_y = (ymin + ymax) / 2
index_row = (int)(center_y * feature_size)
index_col = (int)(center_x * feature_size)
ground_box = [center_x * feature_size - index_col, center_y * feature_size - index_row,
ground_width, ground_height, 1,
round(xmin * self.input_size), round(ymin * self.input_size),
round(xmax * self.input_size), round(ymax * self.input_size),
round(ground_width * self.input_size * ground_height * self.input_size)
]
# ground_box.extend(class_list)
class_ = [0 for _ in range(self.class_num)]
class_[class_id]=1
ground_box.extend(class_)
ground_truth[index_row][index_col] = np.array(ground_box,dtype=float)
return ground_truth
格式轉(zhuǎn)化
現(xiàn)在請(qǐng)把目光轉(zhuǎn)移到這里來(lái):
def encode(self, coords):
feature_size = self.input_size // self.grid_size
ground_truth = np.zeros([feature_size, feature_size, 10 + self.class_num],dtype=float)
for coord in coords:
# positive_num = positive_num + 1
# bounding box歸一化
xmin, ymin, xmax, ymax, class_id = coord
ground_width = (xmax - xmin)
ground_height = (ymax - ymin)
center_x = (xmin + xmax) / 2
center_y = (ymin + ymax) / 2
index_row = (int)(center_y * feature_size)
index_col = (int)(center_x * feature_size)
ground_box = [center_x * feature_size - index_col, center_y * feature_size - index_row,
ground_width, ground_height, 1,
round(xmin * self.input_size), round(ymin * self.input_size),
round(xmax * self.input_size), round(ymax * self.input_size),
1
]
# ground_box.extend(class_list)
class_ = [0 for _ in range(self.class_num)]
class_[class_id]=1
ground_box.extend(class_)
ground_truth[index_row][index_col] = np.array(ground_box,dtype=float)
return ground_truth
我們把VOC的格式解析出來(lái)了,也做了數(shù)據(jù)增強(qiáng)之后做了歸一化得到了幾個(gè)標(biāo)注的框。但是由于在論文當(dāng)中是這樣的:
作者將一張圖片劃分為了7x7的網(wǎng)格,讓每一格子預(yù)測(cè)兩個(gè)框,所以我們真實(shí)標(biāo)注的框也需要轉(zhuǎn)化為這種格式,我們需要手動(dòng)把我們的結(jié)果轉(zhuǎn)化為7x7x(10+類(lèi)別個(gè)數(shù))的樣子,因?yàn)榫W(wǎng)絡(luò)最后的輸出就是7x7x(10+類(lèi)別個(gè)數(shù))
當(dāng)然 實(shí)際上,我們標(biāo)注的框轉(zhuǎn)化之后一個(gè)格子應(yīng)該是只有一個(gè)物體的,所以這里我們轉(zhuǎn)化的話其實(shí)不用那么嚴(yán)格只需要7x7x(5+類(lèi)別個(gè)數(shù))就可以了,但是這里為了對(duì)得到,同時(shí)方便后面轉(zhuǎn)化,這里還存儲(chǔ)了實(shí)際上圖片的框的坐標(biāo)(以這個(gè)格子為中心)
那么一來(lái)在實(shí)際計(jì)算損失的時(shí)候,我們只需要這樣:

所以因?yàn)檫@個(gè)特性,我們需要把標(biāo)簽這樣進(jìn)行轉(zhuǎn)化,方便損失函數(shù)計(jì)算,而且損失函數(shù)的計(jì)算是一個(gè)一個(gè)格子來(lái)對(duì)比計(jì)算的,也就是一個(gè)一個(gè)的grad cell。
損失函數(shù)(目標(biāo)檢測(cè))
之后咱們的損失函數(shù),前面說(shuō)了為啥要轉(zhuǎn)化標(biāo)簽,那么現(xiàn)在咱們可以來(lái)看看損失函數(shù)了。
這里提一下正負(fù)樣本的概念,這里的話其實(shí)也簡(jiǎn)單,就是一個(gè)一個(gè)格子去對(duì)比,然后呢有些格子是沒(méi)有目標(biāo)的,但是我們預(yù)測(cè)的時(shí)候每個(gè)格子都是預(yù)測(cè)了兩個(gè)框的,那么這兩個(gè)框顯然是沒(méi)有用的,那么這個(gè)玩意就是負(fù)樣本,同理如果對(duì)應(yīng)的格子有目標(biāo),但是兩個(gè)框的IOU不一樣(與實(shí)際的框)那么IOU低的也算是負(fù)樣本。
import sys
import torch.nn as nn
import math
import torch
import torch.nn.functional as F
from Config.ConfigTrain import ClassesName
class YOLOLoss(nn.Module):
def __init__(self, S=7, B=2, Classes=20, l_coord=5, l_noobj=0.5, epcoh_threshold=400):
"""
:param S:
:param B:
:param Classes:
:param l_coord:
:param l_noobj:
:param epcoh_threshold:
有物體的box損失權(quán)重設(shè)為l_coord,沒(méi)有物體的box損失權(quán)重設(shè)置為l_noobj
在論文當(dāng)中應(yīng)該是正樣本和負(fù)樣本之間的一個(gè)權(quán)重,因?yàn)槲覀儾粌H僅要預(yù)測(cè)有物體的,原來(lái)沒(méi)有物體的也不能有物體
"""
super(YOLOLoss, self).__init__()
self.S = S
self.B = B
self.Classes = Classes
self.l_coord = l_coord
self.l_noobj = l_noobj
self.epcoh_threshold = epcoh_threshold
def iou(self, bounding_box, ground_box, gridX, gridY, img_size=448, grid_size=64):
"""
計(jì)算交并比
:param bounding_box:
:param ground_box:
:param gridX:
:param gridY:
:param img_size:
:param grid_size:
由于predict_box 返回的是x y w h 這種格式,所以我們還是需要進(jìn)行轉(zhuǎn)換回原來(lái)的xmin ymin xmax ymax
也就是左上右下
"""
predict_box = [0, 0, 0, 0]
predict_box[0] = (int)(gridX + bounding_box[0].item() * grid_size)
predict_box[1] = (int)(gridY + bounding_box[1].item() * grid_size)
predict_box[2] = (int)(bounding_box[2].item() * img_size)
predict_box[3] = (int)(bounding_box[3].item() * img_size)
predict_coord = list([max(0, predict_box[0] - predict_box[2] / 2),
max(0, predict_box[1] - predict_box[3] / 2),
min(img_size - 1, predict_box[0] + predict_box[2] / 2),
min(img_size - 1, predict_box[1] + predict_box[3] / 2)])
predict_Area = (predict_coord[2] - predict_coord[0]) * (predict_coord[3] - predict_coord[1])
ground_coord = list([ground_box[5].item() , ground_box[6].item() , ground_box[7].item() , ground_box[8].item() ])
ground_Area = (ground_coord[2] - ground_coord[0]) * (ground_coord[3] - ground_coord[1])
"""
轉(zhuǎn)化為原來(lái)左上右下之后進(jìn)行計(jì)算
"""
CrossLX = max(predict_coord[0], ground_coord[0])
CrossRX = min(predict_coord[2], ground_coord[2])
CrossUY = max(predict_coord[1], ground_coord[1])
CrossDY = min(predict_coord[3], ground_coord[3])
if CrossRX < CrossLX or CrossDY < CrossUY: # 沒(méi)有交集
return 0
interSection = (CrossRX - CrossLX) * (CrossDY - CrossUY)
return interSection / (predict_Area + ground_Area - interSection)
def forward(self, bounding_boxes, ground_truth, batch_size=32, grid_size=64,
img_size=448): # 輸入是 S * S * ( 2 * B + Classes)
# 定義三個(gè)計(jì)算損失的變量 正樣本定位損失 樣本置信度損失 樣本類(lèi)別損失
loss = 0
loss_coord = 0
loss_confidence = 0
loss_classes = 0
iou_sum = 0
object_num = 0
mseLoss = nn.MSELoss()
for batch in range(len(bounding_boxes)):
for indexRow in range(self.S): # 先行 - Y
for indexCol in range(self.S): # 后列 - X
"""
這里額外統(tǒng)計(jì)了三個(gè)損失
"""
bounding_box = bounding_boxes[batch][indexRow][indexCol]
predict_box_one = bounding_box[0:5]
predict_box_two = bounding_box[5:10]
ground_box = ground_truth[batch][indexRow][indexCol]
# 1.如果此處ground_truth不存在 即只有背景 那么兩個(gè)框均為負(fù)樣本
if (ground_box[4]) == 0: # 面積為0的grount_truth 表明此處只有背景
loss = loss + self.l_noobj * torch.pow(predict_box_one[4], 2) + torch.pow(
predict_box_two[4], 2)
loss_confidence += self.l_noobj * math.pow(predict_box_one[4].item(), 2) + math.pow(
predict_box_two[4].item(), 2)
else:
# print(ground_box[4].item(), ClassesName[int(ground_box[10].item())])
object_num = object_num + 1
predict_iou_one = self.iou(predict_box_one, ground_box, indexCol * 64, indexRow * 64)
predict_iou_two = self.iou(predict_box_two, ground_box, indexCol * 64, indexRow * 64)
# 改進(jìn):讓兩個(gè)預(yù)測(cè)的box與ground box擁有更大iou的框進(jìn)行擬合 讓iou低的作為負(fù)樣本
if predict_iou_one > predict_iou_two: # 框1為正樣本 框2為負(fù)樣本
predict_box = predict_box_one
iou = predict_iou_one
no_predict_box = predict_box_two
else:
predict_box = predict_box_two
iou = predict_iou_two
no_predict_box = predict_box_one
# 正樣本:
# 定位
loss = loss + self.l_coord * (torch.pow((ground_box[0] - predict_box[0]), 2) + torch.pow(
(ground_box[1] - predict_box[1]), 2) + torch.pow(
torch.sqrt(ground_box[2] + 1e-8) - torch.sqrt(predict_box[2] + 1e-8), 2) + torch.pow(
torch.sqrt(ground_box[3] + 1e-8) - torch.sqrt(predict_box[3] + 1e-8), 2))
loss_coord += self.l_coord * (
math.pow((ground_box[0] - predict_box[0].item()), 2) + math.pow(
(ground_box[1] - predict_box[1].item()), 2) + math.pow(
math.sqrt(ground_box[2] + 1e-8) - math.sqrt(predict_box[2].item() + 1e-8),
2) + math.pow(
math.sqrt(ground_box[3] + 1e-8) - math.sqrt(predict_box[3].item() + 1e-8), 2))
# 置信度
loss = loss + torch.pow(predict_box[4] - iou, 2)
loss_confidence += math.pow(predict_box[4].item() - iou, 2)
iou_sum = iou_sum + iou
# 分類(lèi)
ground_class = ground_box[10:]
predict_class = bounding_box[self.B * 5:]
loss = loss + mseLoss(ground_class, predict_class)
loss_classes += mseLoss(ground_class, predict_class).item()
# 負(fù)樣本 置信度:
loss = loss + self.l_noobj * torch.pow(no_predict_box[4] - 0, 2)
loss_confidence += math.pow(no_predict_box[4].item() - 0, 2)
return loss/batch_size, loss_coord/batch_size, loss_confidence/batch_size, loss_classes/batch_size, iou_sum, object_num
那么在這里的話我也要說(shuō)說(shuō),剛剛注釋的這個(gè)代碼:
# x[:,:,:, 0 : self.B * 5] = self.sigmoid(x[:,:,:, 0 : self.B * 5])
# x[:,:,:, self.B * 5 : ] = self.softmax(x[:,:,:, self.B * 5 : ])
它為什么不行了,第一個(gè)這個(gè)代碼本身存在inplace操作。
第二如果真的需要使用交叉熵作為分類(lèi)的損失函數(shù)的話,pytorch內(nèi)部的交叉熵?fù)p失函數(shù)自己是計(jì)算了softmax的
第三,就是咱們的sunshine函數(shù)里面壓根不是交叉熵來(lái)算類(lèi)別損失的,人家就是MSE。
之后是關(guān)于置信度confidence的計(jì)算,這個(gè)玩意是表示這里面有沒(méi)有(這個(gè)格子里面)物體的,首先預(yù)測(cè)的時(shí)候,那個(gè)值是預(yù)測(cè)出來(lái)的,計(jì)算損失的時(shí)候,那個(gè)c(在有物品的情況下)是等于1的,這個(gè)在咱們voc數(shù)據(jù)集里面可以看到,有物品直接為1
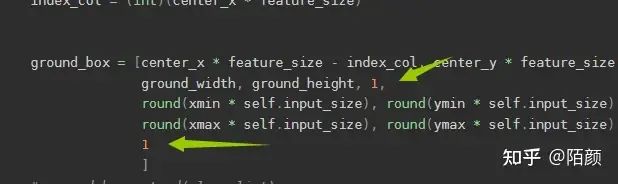
但是呢,實(shí)際計(jì)算的時(shí)候,這個(gè)c呢是咱們那個(gè)預(yù)測(cè)框和實(shí)際框的IOU。
這個(gè)論文當(dāng)中也有描述。
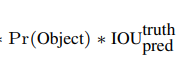
訓(xùn)練部分
接下來(lái)是咱們的訓(xùn)練部分,這個(gè)呢,有兩個(gè)一個(gè)是預(yù)訓(xùn)練一個(gè)是實(shí)際訓(xùn)練。
預(yù)訓(xùn)練得到的一個(gè)模型還可以用于圖片分類(lèi)。
預(yù)訓(xùn)練
這部分其實(shí)很簡(jiǎn)單就不多說(shuō)了。
import argparse
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torch.optim as optim
from Models.FeatureNet import YOLOFeature
from Utils import ModelUtils
from Config.ConfigPre import *
from Utils.DataSet.MyDataSet import MyDataSet
from Utils.DataSet.TransformAtions import TransFormAtions
import os
from Utils import SaveModel
from Utils import Log
from torch.utils.tensorboard import SummaryWriter
def train():
ModelUtils.set_seed()
# 初始化驅(qū)動(dòng)
device = None
if (torch.cuda.is_available()):
if (not opt.device == 'cpu'):
div = "cuda:" + opt.device
# 這邊后面還得做一個(gè)檢測(cè),看看有沒(méi)有坑貨,亂輸入
device = torch.device(div)
print("33[0;31;0m使用GPU訓(xùn)練中:{}33[0m".format(torch.cuda.get_device_name()))
else:
device = torch.device("cpu")
print("33[0;31;40m使用CPU訓(xùn)練33[0m")
else:
device = torch.device("cpu")
print("33[0;31;40m使用CPU訓(xùn)練33[0m")
# 創(chuàng)建 runs exp 文件
EPX_Path = SaveModel.CreatRun(0,"pre")
# 日志相關(guān)的準(zhǔn)備工作
wirter = None
openTensorboard = opt.tensorboardopen
path_board = None
if (openTensorboard):
path_board = EPX_Path + "\logs"
wirter = SummaryWriter(path_board)
fo = Log.PrintLog(EPX_Path)
# 準(zhǔn)備數(shù)據(jù)集
transformations = TransFormAtions()
train_data_dir = opt.train_dir
if (not train_data_dir):
train_data_dir = Data_Root + "" + Train
if (not os.path.exists(train_data_dir)):
raise Exception("訓(xùn)練集路徑錯(cuò)誤")
train_data = MyDataSet(data_dir=train_data_dir, transform=transformations.train_transform,ClassesName=ClassesName)
valid_data_dir = opt.valid_dir
if (not valid_data_dir):
valid_data_dir = Data_Root + "" + Valid
if (not os.path.exists(valid_data_dir)):
raise Exception("測(cè)試集路徑錯(cuò)誤")
valid_data = MyDataSet(data_dir=valid_data_dir, transform=transformations.valid_transform,ClassesName=ClassesName)
# 構(gòu)建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=opt.batch_size, num_workers=opt.works, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=opt.batch_size)
# 開(kāi)始進(jìn)入網(wǎng)絡(luò)訓(xùn)練
# 1 開(kāi)始初始化網(wǎng)絡(luò),設(shè)置參數(shù)啥的
# 1.1 初始化網(wǎng)絡(luò)
net = YOLOFeature(Classes)
net.initialize_weights()
net = net.to(device)
# 1.2選擇交叉熵?fù)p失函數(shù),做分類(lèi)問(wèn)題一般是選擇這個(gè)損失函數(shù)的
criterion = nn.CrossEntropyLoss()
# 1.3設(shè)置優(yōu)化器
optimizer = optim.SGD(net.parameters(), lr=opt.lr, momentum=0.09) # 選擇優(yōu)化器
# 設(shè)置學(xué)習(xí)率下降策略,默認(rèn)的也可以,那就不設(shè)置嘛,主要是不斷去自動(dòng)調(diào)整學(xué)習(xí)的那個(gè)速度
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.01)
# 2 開(kāi)始進(jìn)入訓(xùn)練步驟
# 2.1 進(jìn)入網(wǎng)絡(luò)訓(xùn)練
Best_weight = None
Best_Acc = 0.0
for epoch in range(opt.epochs):
loss_mean = 0.0
correct = 0.0
total = 0.0
current_Acc_ecpho = 0.0
bacth_index = 0.
val_time = 0
net.train()
print("正在進(jìn)行第{}輪訓(xùn)練".format(epoch + 1))
for i, data in enumerate(train_loader):
bacth_index+=1
# forward
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
# print(inputs.shape,labels.shape)
outputs = net(inputs)
# print(outputs.shape, labels.shape)
# backward
optimizer.zero_grad()
loss = criterion(outputs, labels)
loss.backward()
# update weights
optimizer.step()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).squeeze().sum()
# 打印訓(xùn)練信息,進(jìn)入對(duì)比
loss_mean += loss.item()
current_Acc = correct / total
current_Acc_ecpho+=current_Acc
if (i + 1) % opt.log_interval == 0:
loss_mean = loss_mean / opt.log_interval
info = "訓(xùn)練:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}"
.format
(
epoch, opt.epochs, i + 1, len(train_loader), loss_mean, current_Acc
)
print(info, file=fo)
if (opt.show_log_console):
info_print = "33[0;33;0m" + info + "33[0m"
print(info_print)
loss_mean = 0.0
# tensorboard 繪圖
if (wirter):
wirter.add_scalar("訓(xùn)練準(zhǔn)確率", current_Acc_ecpho, (epoch))
wirter.add_scalar("訓(xùn)練損失均值", loss_mean, (epoch))
current_Acc_ecpho/=bacth_index
# 保存效果最好的玩意
if (current_Acc_ecpho > Best_Acc):
Best_weight = net.state_dict()
Best_Acc = current_Acc_ecpho
scheduler.step() # 更新學(xué)習(xí)率
# 2.2 進(jìn)入訓(xùn)練對(duì)比階段
if (epoch + 1) % opt.val_interval == 0:
correct_val = 0.0
total_val = 0.0
loss_val = 0.0
current_Acc_val = 0.0
current_Acc_ecpho_val = 0.
batch_index_val = 0.0
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
batch_index_val+=1
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
outputs = net(inputs)
loss = criterion(outputs, labels)
loss_val += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).squeeze().sum()
current_Acc_val = correct_val / total_val
current_Acc_ecpho_val+=current_Acc_val
info_val = "測(cè)試: Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format
(
epoch, opt.epochs, j + 1, len(valid_loader), loss_val, current_Acc_val
)
print(info_val, file=fo)
if (opt.show_log_console):
info_print_val = "33[0;31;0m" + info_val + "33[0m"
print(info_print_val)
current_Acc_ecpho_val/=batch_index_val
if (wirter):
wirter.add_scalar("測(cè)試準(zhǔn)確率", current_Acc_ecpho_val, (val_time))
wirter.add_scalar("測(cè)試損失總值", loss_val, (val_time))
val_time+=1
# 最后一次的權(quán)重
Last_weight = net.state_dict()
# 保存模型
SaveModel.Save_Model(EPX_Path, Best_weight, Last_weight)
fo.close()
if (wirter):
print("tensorboard dir is:", path_board)
wirter.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--batch-size', type=int, default=8)
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--log_interval', type=int, default=10)
# 訓(xùn)練幾輪測(cè)試一次
parser.add_argument('--val_interval', type=int, default=1)
parser.add_argument('--train_dir', type=str, default='')
parser.add_argument('--valid_dir', type=str, default='')
# 如果是Mac系注意這個(gè)參數(shù)可能需要設(shè)置為1,本地訓(xùn)練,不推薦MAC
parser.add_argument('--works', type=int, default=2)
parser.add_argument('--show_log_console', type=bool, default=True)
parser.add_argument('--device', type=str, default="0", help="默認(rèn)使用顯卡加速訓(xùn)練參數(shù)選擇:0,1,2...or cpu")
parser.add_argument('--tensorboardopen', type=bool, default=True)
opt = parser.parse_args()
train()
# tensorboard --logdir = runs/train/epx2/logs
這部分還是簡(jiǎn)單的。
目標(biāo)檢測(cè)訓(xùn)練
之后就是咱們目標(biāo)檢測(cè)算法的實(shí)現(xiàn),這個(gè)其實(shí)核心流程都是一樣的,就是多了一些東西用來(lái)做記錄
import argparse
import gc
import torch
from torch.utils.data import DataLoader
import torch.optim as optim
from Models.Yolo import YOLO
from Models.YoloLoss import YOLOLoss
from Utils import ModelUtils
from Config.ConfigTrain import *
from Utils.DataSet.VOC import VOCDataSet
import os
from Utils import SaveModel
from Utils import Log
from torch.utils.tensorboard import SummaryWriter
def train():
ModelUtils.set_seed()
# 初始化驅(qū)動(dòng)
device = None
if (torch.cuda.is_available()):
if (not opt.device == 'cpu'):
div = "cuda:" + opt.device
device = torch.device(div)
torch.backends.cudnn.benchmark = True
print("33[0;31;0m使用GPU訓(xùn)練中:{}33[0m".format(torch.cuda.get_device_name()))
else:
device = torch.device("cpu")
print("33[0;31;40m使用CPU訓(xùn)練33[0m")
else:
device = torch.device("cpu")
print("33[0;31;40m使用CPU訓(xùn)練33[0m")
# 創(chuàng)建 runs exp 文件
EPX_Path = SaveModel.CreatRun(0,"detect")
# 日志相關(guān)的準(zhǔn)備工作
wirter = None
openTensorboard = opt.tensorboardopen
path_board = None
if (openTensorboard):
path_board = EPX_Path + "\logs"
wirter = SummaryWriter(path_board)
fo = Log.PrintLog(EPX_Path)
train_data_dir_image = opt.train_dir_image
train_data_dir_Ann = opt.train_dir_Ann
if (not train_data_dir_image):
train_data_dir_image = TrainImage
if (not os.path.exists(train_data_dir_image)):
raise Exception("訓(xùn)練集路徑錯(cuò)誤")
if (not train_data_dir_Ann):
train_data_dir_Ann = TrainAnn
if (not os.path.exists(train_data_dir_Ann)):
raise Exception("訓(xùn)練集路徑錯(cuò)誤")
train_data =VOCDataSet(imgs_path=train_data_dir_image,
annotations_path=train_data_dir_Ann,
is_train=True)
valid_data_dir_image = opt.valid_dir_image
valid_data_dir_Ann = opt.valid_dir_Ann
if (not valid_data_dir_image):
valid_data_dir_image = ValImage
if (not os.path.exists(valid_data_dir_image)):
raise Exception("訓(xùn)練集路徑錯(cuò)誤")
if (not valid_data_dir_Ann):
valid_data_dir_Ann = ValAnn
if (not os.path.exists(valid_data_dir_Ann)):
raise Exception("訓(xùn)練集路徑錯(cuò)誤")
valid_data = VOCDataSet(imgs_path=valid_data_dir_image,
annotations_path=valid_data_dir_Ann,
is_train=False)
# 構(gòu)建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=opt.batch_size, num_workers=opt.works, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=opt.batch_size)
# 1 開(kāi)始初始化網(wǎng)絡(luò),設(shè)置參數(shù)啥的
net = YOLO(B=2,classes_num=Classes)
#加載預(yù)訓(xùn)練權(quán)重
if(PreWeight):
# 1.1 初始化網(wǎng)絡(luò)
preweight = torch.load(PreWeight)
net.initialize_weights(preweight)
net = net.to(device)
loss_func = YOLOLoss(S=7,B=2,Classes=Classes).to(device)
# 1.3設(shè)置優(yōu)化器
optimizer = optim.SGD(net.parameters(), lr=opt.lr, momentum=0.09) # 選擇優(yōu)化器
# 設(shè)置學(xué)習(xí)率下降策略,默認(rèn)的也可以,那就不設(shè)置嘛,主要是不斷去自動(dòng)調(diào)整學(xué)習(xí)的那個(gè)速度
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.01)
# 2 開(kāi)始進(jìn)入訓(xùn)練步驟
# 2.1 進(jìn)入網(wǎng)絡(luò)訓(xùn)練
Best_weight = None
TotalLoss = 0.
ValLoss = 0.
ValTime = 0.
Best_loss = float("inf")
for epoch in range(opt.epochs):
"""
下面是一些用來(lái)記錄當(dāng)前網(wǎng)絡(luò)運(yùn)行狀態(tài)的參數(shù)
"""
train_loss = 0
val_loss = 0
# train_iou = 0
# val_iou = 0
# train_object_num = 0
# val_object_num = 0
train_loss_coord = 0
val_loss_coord = 0
train_loss_confidence = 0
val_loss_confidence = 0
train_loss_classes = 0
val_loss_classes = 0
log_loss_mean_train = 0.
# log_loss_mean_val = 0.
net.train()
print("正在進(jìn)行第{}輪訓(xùn)練".format(epoch + 1))
for i, data in enumerate(train_loader):
# forward
inputs, labels = data
inputs, labels = inputs.float().to(device), labels.float().to(device)
outputs = net(inputs)
optimizer.zero_grad()
loss = loss_func(bounding_boxes=outputs, ground_truth=labels,batch_size = opt.batch_size )
batch_loss = loss[0]
batch_loss.backward()
optimizer.step()
log_loss_mean_train+=batch_loss
train_loss+=batch_loss
train_loss_coord+=loss[1]
train_loss_confidence+=loss[2]
train_loss_classes+=loss[3]
# train_iou+=train_iou+loss[4]
# train_object_num+=loss[5]
# update weights
if (i + 1) % opt.log_interval == 0:
log_loss_mean_train = log_loss_mean_train / opt.log_interval
info = "訓(xùn)練:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f}"
.format
(
epoch, opt.epochs, i + 1, len(train_loader), log_loss_mean_train
)
print(info, file=fo)
if (opt.show_log_console):
info_print = "33[0;33;0m" + info + "33[0m"
print(info_print)
log_loss_mean_train = 0.0
#總體損失
TotalLoss+=train_loss
# tensorboard 繪圖
if (wirter):
wirter.add_scalar("總體損失值",TotalLoss,epoch)
wirter.add_scalar("每輪損失值",train_loss,epoch)
wirter.add_scalar("每輪預(yù)測(cè)預(yù)測(cè)框損失值",train_loss_coord,epoch)
wirter.add_scalar("每輪預(yù)測(cè)框置信度損失",train_loss_confidence,epoch)
wirter.add_scalar("每輪預(yù)測(cè)類(lèi)別損失值",train_loss_classes,epoch)
# 保存效果最好的玩意
if (train_loss < Best_loss):
Best_weight = net.state_dict()
Best_loss = train_loss
scheduler.step() # 更新學(xué)習(xí)率
# 2.2 進(jìn)入訓(xùn)練對(duì)比階段
if (epoch + 1) % opt.val_interval == 0:
"""
這部分和訓(xùn)練的那部分是類(lèi)似的,可以忽略這部分的代碼
"""
net.eval()
with torch.no_grad():
for j, data in enumerate(valid_loader):
inputs, labels = data
inputs, labels = inputs.float().to(device), labels.float().to(device)
outputs = net(inputs)
loss = loss_func(outputs, labels)
batch_loss = loss[0]
# log_loss_mean_val += batchLoss
val_loss += batch_loss
val_loss_coord += loss[1]
val_loss_confidence += loss[2]
val_loss_classes += loss[3]
# val_iou += train_iou + loss[4]
# val_object_num += loss[5]
info_val = "測(cè)試: Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} ".format
(
epoch, opt.epochs, (j+1), len(valid_loader), val_loss
)
print(info_val, file=fo)
if (opt.show_log_console):
info_print_val = "33[0;31;0m" + info_val + "33[0m"
print(info_print_val)
ValLoss+=val_loss
if (wirter):
wirter.add_scalar("測(cè)試總體損失",ValLoss, (ValTime))
wirter.add_scalar("每次測(cè)試總損失總值", val_loss, (ValTime))
wirter.add_scalar("每輪測(cè)試預(yù)測(cè)框損失值", val_loss_coord, ValTime)
wirter.add_scalar("每輪測(cè)試預(yù)測(cè)框置信度損失", val_loss_confidence, ValTime)
wirter.add_scalar("每輪測(cè)試預(yù)測(cè)類(lèi)別損失值", val_loss_classes, ValTime)
ValTime+=1
# 最后一次的權(quán)重
Last_weight = net.state_dict()
# 保存模型
SaveModel.Save_Model(EPX_Path, Best_weight, Last_weight)
fo.close()
if (wirter):
print("tensorboard dir is:", path_board)
wirter.close()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=4)
parser.add_argument('--lr', type=float, default=0.01)
#每5個(gè)batch輸出一次結(jié)果
parser.add_argument('--log_interval', type=int, default=2)
# 訓(xùn)練幾輪測(cè)試一次
parser.add_argument('--val_interval', type=int, default=10)
parser.add_argument('--train_dir_image', type=str, default='')
parser.add_argument('--train_dir_Ann', type=str, default='')
parser.add_argument('--valid_dir_image', type=str, default='')
parser.add_argument('--valid_dir_Ann', type=str, default='')
# 如果是Mac系注意這個(gè)參數(shù)可能需要設(shè)置為1,本地訓(xùn)練,不推薦MAC
parser.add_argument('--works', type=int, default=0)
parser.add_argument('--show_log_console', type=bool, default=True)
parser.add_argument('--device', type=str, default="cpu", help="默認(rèn)使用顯卡加速訓(xùn)練參數(shù)選擇:0,1,2...or cpu")
parser.add_argument('--tensorboardopen', type=bool, default=True)
opt = parser.parse_args()
train()
# tensorboard --logdir = runs/train/epx2/logs
分類(lèi)與目標(biāo)檢測(cè)
之后就是咱們的后處理階段,其實(shí)也就是咱們的使用部分。
這里也是兩個(gè)部分,一個(gè)是圖片分類(lèi)的實(shí)現(xiàn),還有一個(gè)就是咱們目標(biāo)檢測(cè)的實(shí)現(xiàn)。
圖片分類(lèi)
這里面也是兩個(gè)部分,一個(gè)是預(yù)訓(xùn)練模型,進(jìn)行前向傳播,還有一個(gè)是進(jìn)行識(shí)別后的處理。
import argparse
from PIL import Image
from Utils.DataSet.MyDataSet import MyDataSet
from Utils.DataSet.TransformAtions import TransFormAtions
import argparse
import torch
from torch.utils.data import DataLoader
from Models.FeatureNet import YOLOFeature
from Config.ConfigPre import *
import outProcessClassfiy
def detect():
ways = opt.valid_imgs
transformations = TransFormAtions()
net = YOLOFeature(Classes)
state_dict_load = torch.load(opt.path_state_dict)
net.load_state_dict(state_dict_load)
if(ways):
test_data = MyDataSet(data_dir=opt.valid_dir, transform=transformations.valid_transform,ClassesName=ClassesName)
valid_loader = DataLoader(dataset=test_data, batch_size=1)
net.eval()
with torch.no_grad():
for i, data in enumerate(valid_loader):
# forward
inputs, labels = data
outputs = net(inputs)
_, predicted = torch.max(outputs.data, 1)
# 輸出處理器
outProcessClassfiy.Function(predicted.numpy()[0])
else:
#指定的是單張圖片,少給我來(lái)奇奇怪怪的輸入,這個(gè)版本容錯(cuò)很差滴!!!
path_img = opt.valid_dir
if(".jpg" not in path_img):
raise Exception("小爺打不開(kāi)這圖片")
image = Image.open(path_img)
image = transformations.valid_transform(image)
image = torch.reshape(image, (1, 3, 32, 32))
net.eval()
with torch.no_grad():
out = net(image)
outProcessClassfiy.Function(out.argmax(1).item())
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# False表示識(shí)別單張圖片,True表示多張圖片,此時(shí)指定路徑即可。
parser.add_argument('--valid_imgs',type=bool,default=False)
parser.add_argument('--valid_dir', type=str, default=r'F:projectsPythonProjectHuLookDataPreData rain貓羽雫1.jpg')
parser.add_argument('--path_state_dict', type=str, default=r'runs rainpreepx0weightsest.pth')
opt = parser.parse_args()
detect()
之后是咱們的后處理
from Config.ConfigPre import *
def Function(out):
print("類(lèi)別為:", ClassesName[out])
目標(biāo)檢測(cè)
這個(gè)也是類(lèi)似的,但是的話,這里就不去拆什么后置處理器了哈
那么這里要注意的就是編碼的時(shí)候opencv是不支持中文的,解決方案的話也不難,需要自己準(zhǔn)備一個(gè)字體文件就完了,當(dāng)然咱們的項(xiàng)目工程里面是帶了一個(gè)的。
import cv2
import torchvision.transforms as transforms
from Models.Yolo import YOLO
import argparse
import torch
from Config.ConfigTrain import *
import numpy as np
from PIL import Image,ImageDraw,ImageFont
def iou(box_one, box_two):
LX = max(box_one[0], box_two[0])
LY = max(box_one[1], box_two[1])
RX = min(box_one[2], box_two[2])
RY = min(box_one[3], box_two[3])
if LX >= RX or LY >= RY:
return 0
return (RX - LX) * (RY - LY) / ((box_one[2]-box_one[0]) * (box_one[3] - box_one[1]) + (box_two[2]-box_two[0]) * (box_two[3] - box_two[1]))
def NMS(bounding_boxes,S=7,B=2,img_size=448,confidence_threshold=0.5,iou_threshold=0.0,possible_pred=0.4):
bounding_boxes = bounding_boxes.cpu().detach().numpy().tolist()
predict_boxes = []
nms_boxes = []
grid_size = img_size / S
for batch in range(len(bounding_boxes)):
for i in range(S):
for j in range(S):
gridX = grid_size * j
gridY = grid_size * i
if bounding_boxes[batch][i][j][4] < bounding_boxes[batch][i][j][9]:
bounding_box = bounding_boxes[batch][i][j][5:10]
else:
bounding_box = bounding_boxes[batch][i][j][0:5]
class_possible = (bounding_boxes[batch][i][j][10:])
bounding_box.extend(class_possible)
possible = max(class_possible)
if (bounding_box[4] < confidence_threshold
):
continue
if(bounding_box[4]*possible < possible_pred):
continue
# print(bounding_box[4]*possible)
centerX = (int)(gridX + bounding_box[0] * grid_size)
centerY = (int)(gridY + bounding_box[1] * grid_size)
width = (int)(bounding_box[2] * img_size)
height = (int)(bounding_box[3] * img_size)
bounding_box[0] = max(0, (int)(centerX - width / 2))
bounding_box[1] = max(0, (int)(centerY - height / 2))
bounding_box[2] = min(img_size - 1, (int)(centerX + width / 2))
bounding_box[3] = min(img_size - 1, (int)(centerY + height / 2))
predict_boxes.append(bounding_box)
while len(predict_boxes) != 0:
predict_boxes.sort(key=lambda box:box[4])
assured_box = predict_boxes[0]
temp = []
classIndex = np.argmax(assured_box[5:])
#print("類(lèi)別:{}".format(ClassesName[classIndex))
assured_box[4] = assured_box[4] * assured_box[5 + classIndex]
#修正置信度為 物體分類(lèi)準(zhǔn)確度 × 含有物體的置信度
assured_box[5] = classIndex
nms_boxes.append(assured_box)
i = 1
while i < len(predict_boxes):
if iou(assured_box,predict_boxes[i]) <= iou_threshold:
temp.append(predict_boxes[i])
i = i + 1
predict_boxes = temp
return nms_boxes
def detect():
transform = transforms.Compose([
transforms.ToTensor(), # height * width * channel -> channel * height * width
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
image_dir = opt.valid_dir
img_data = cv2.imread(image_dir)
img_data = cv2.resize(img_data, (448, 448), interpolation=cv2.INTER_AREA)
train_data = transform(img_data)
train_data = train_data.unsqueeze(0)
net = YOLO(B=2,classes_num=Classes)
state_dict_load = torch.load(opt.path_state_dict)
net.load_state_dict(state_dict_load)
net.eval()
with torch.no_grad():
bounding_boxes = net(train_data)
NMS_boxes = NMS(bounding_boxes,confidence_threshold=opt.confidence,iou_threshold=opt.iou,possible_pred=opt.possible_pre)
font = ImageFont.truetype(r'font/simsun.ttc', 20, encoding='utf-8')
for box in NMS_boxes:
img_data = cv2.rectangle(img_data, (box[0], box[1]), (box[2], box[3]), (0, 255, 0), 1)
"""
處理中文
"""
pil_img = Image.fromarray(cv2.cvtColor(img_data, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(pil_img)
draw.text((box[0], box[1]),"{}:{}".format(ClassesName[box[5]], round(box[4], 2)),(148,175,100),font)
print("class_name:{} confidence:{}".format(ClassesName[int(box[5])],round(box[4],2)))
img_data = cv2.cvtColor(np.array(pil_img), cv2.COLOR_RGB2BGR)
if(opt.show_img):
cv2.imshow("img_detection", img_data)
cv2.waitKey()
cv2.destroyAllWindows()
if(opt.save_dir):
cv2.imwrite(opt.save_dir, img_data)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--valid_dir', type=str, default=r'F:projectsPythonProjectHuLookDataDetData rainimages02.jpg')
parser.add_argument('--path_state_dict', type=str, default=r'F:projectsPythonProjectHuLook
uns raindetectepx0weightsest.pth')
parser.add_argument("--iou",type=float,default=0.2)
parser.add_argument("--confidence",type=float,default=0.5)
parser.add_argument("--possible_pre",type=float,default=0.35)
parser.add_argument("--show_img",type=bool,default=True)
parser.add_argument("--save_dir",type=str,default="")
opt = parser.parse_args()
detect()
項(xiàng)目獲取
那么整個(gè)玩意咱們就搞定了,考慮到特殊原因,項(xiàng)目上傳至碼云:https://gitee.com/Huterox/hu-look
此外由于咱們訓(xùn)練出來(lái)的權(quán)重文件太大了,所以這理的話就不上傳入權(quán)重文件了。
當(dāng)然其實(shí)還有一個(gè)原因是,咱們的這個(gè)權(quán)重文件只是用來(lái)做測(cè)試的,所以實(shí)際的意義不大。
不過(guò)你以為這就完了嘛,不,接下來(lái)是咱們的這個(gè)玩意如何使用!
項(xiàng)目使用
預(yù)訓(xùn)練數(shù)據(jù)集
這個(gè)的話其實(shí)可以考慮省去,我們可以選擇直接訓(xùn)練,問(wèn)題不大。
這個(gè)預(yù)訓(xùn)練數(shù)據(jù)集就和前面說(shuō)的一樣,按照類(lèi)別放在不同的文件夾下面。
例如我這里準(zhǔn)備這幾種圖片:
(我這個(gè)是用于測(cè)試的數(shù)據(jù)集所以很小,就幾十張圖片)
預(yù)訓(xùn)練
這部分的話需要打開(kāi)配置
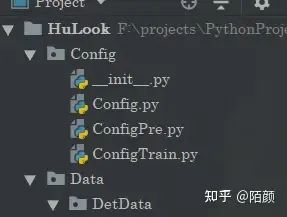
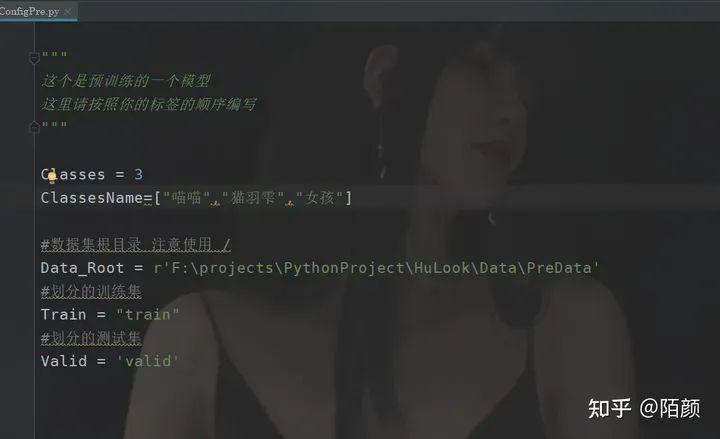
配置一下就好了
當(dāng)然在訓(xùn)練文件當(dāng)中也是可以配置的
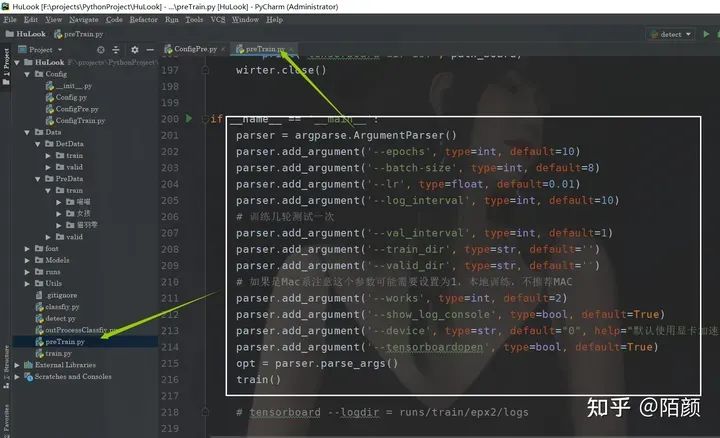
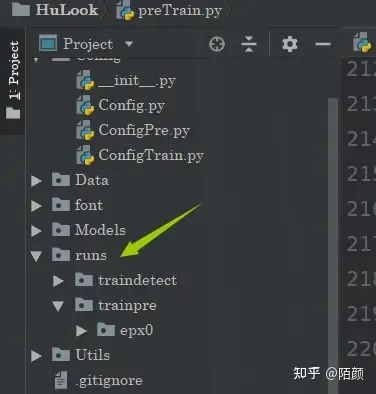
訓(xùn)練完畢后,你可以打開(kāi)tensorboad
我們的訓(xùn)練過(guò)程當(dāng)中的數(shù)據(jù)都在這兒
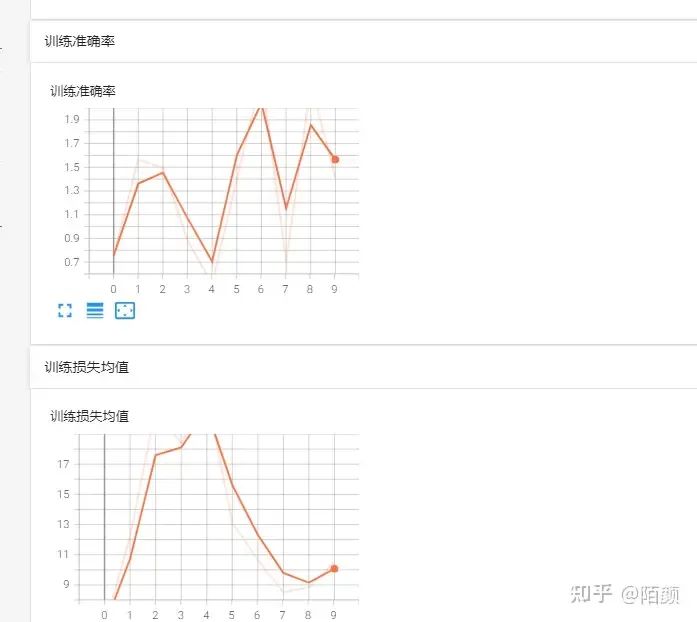
之后的話,預(yù)訓(xùn)練完之后,這個(gè)網(wǎng)絡(luò)是具備圖片分類(lèi)功能的,可以使用
進(jìn)行圖片分類(lèi)。
不過(guò)這里注意的是,預(yù)訓(xùn)練的只是一個(gè)用于分類(lèi)的網(wǎng)絡(luò),目的為了讓骨干網(wǎng)絡(luò)具備權(quán)重。所以準(zhǔn)備的數(shù)據(jù)集最好是一張圖片里面只有一個(gè)目標(biāo),因?yàn)槟峭嬉庵皇怯脕?lái)分類(lèi)的。
目標(biāo)檢測(cè)數(shù)據(jù)集
這部分的話就是咱們的voc數(shù)據(jù)集,和正常的一樣就可以了,咱們可以直接使用labelimg進(jìn)行標(biāo)注。
那個(gè)怎么使用前面的博客有,那么在咱們這里的話還是需要手動(dòng)劃分一下訓(xùn)練集和驗(yàn)證集的。
然后里面的內(nèi)容就和voc一樣了
訓(xùn)練目標(biāo)檢測(cè)
之后就是咱們的訓(xùn)練
還是先到配置處
之后打開(kāi)tensorboard
tensorboard --logdir=runs/traindetect/epx0/logs
識(shí)別
這個(gè)就不用我說(shuō)了,打開(kāi)detect
我們可以看到這識(shí)別的情況
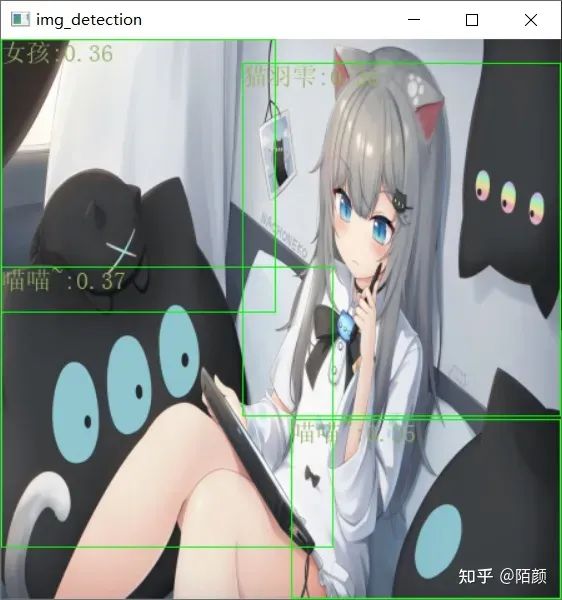
這里的話由于咱們的數(shù)據(jù)集太那啥了,而且數(shù)據(jù)集本身設(shè)置的就不好,所以導(dǎo)致這里的效果也不好,同時(shí)這其實(shí)我不上傳權(quán)重的原因之一,只是用來(lái)做測(cè)試的。
總結(jié)
以上就是全部?jī)?nèi)容了,全網(wǎng)應(yīng)該找不到比這個(gè)還全的了吧?
-
目標(biāo)檢測(cè)
+關(guān)注
關(guān)注
0文章
220瀏覽量
15842 -
pytorch
+關(guān)注
關(guān)注
2文章
808瀏覽量
13669
原文標(biāo)題:近兩萬(wàn)字長(zhǎng)文,從理論到實(shí)現(xiàn)!手把手教你如何自制目標(biāo)檢測(cè)框架
文章出處:【微信號(hào):vision263com,微信公眾號(hào):新機(jī)器視覺(jué)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
周三晚19:00,手把手教你做PC第七課:Audio 音頻驅(qū)動(dòng)框架適配

GPU顯卡維修避坑指南:手把手教你識(shí)別行業(yè)套路!

KiCad直播活動(dòng)(三):在 Windows上編譯KiCad 手把手教您編譯/構(gòu)建 KiCad 源碼

《零基礎(chǔ)開(kāi)發(fā)AI Agent——手把手教你用扣子做智能體》
《手把手教你做星閃無(wú)人機(jī)—KaihongOS星閃無(wú)人機(jī)開(kāi)發(fā)實(shí)戰(zhàn)》系列課程課件匯總
《手把手教你做PC-KaihongOS筆記本電腦開(kāi)發(fā)實(shí)戰(zhàn)》課件匯總
【第四章 定時(shí)任務(wù)】手把手教你玩轉(zhuǎn)新版正點(diǎn)原子云
【第一章 透?jìng)鞑呗浴?b class='flag-5'>手把手教你玩轉(zhuǎn)新版正點(diǎn)原子云
開(kāi)發(fā)者集結(jié)!《手把手教你做星閃無(wú)人機(jī)》第二課開(kāi)講啦!

《手把手教你做星閃無(wú)人機(jī)》即將開(kāi)播,鎖定15日晚七點(diǎn)!
《手把手教你做PC》課程即將啟動(dòng)!深開(kāi)鴻引領(lǐng)探索KaihongOS筆記本電腦開(kāi)發(fā)實(shí)戰(zhàn)
Air780E模組LuatOS開(kāi)發(fā)實(shí)戰(zhàn) —— 手把手教你搞定數(shù)據(jù)打包解包

手把手教你通過(guò)宏集物聯(lián)網(wǎng)工控屏&網(wǎng)關(guān)進(jìn)行協(xié)議轉(zhuǎn)換,將底層PLC/傳感器的數(shù)據(jù)轉(zhuǎn)換為T(mén)CP協(xié)議并傳輸?shù)接脩?/a>
手把手教你排序算法怎么寫(xiě)

手把手帶你移植HAL庫(kù)函數(shù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論