

數(shù)據(jù)倉庫簡介
數(shù)據(jù)倉庫,英文名稱為DataWarehouse,可簡寫為DW或DWH。數(shù)據(jù)倉庫,是為企業(yè)所有級別的決策制定過程,提供所有類型數(shù)據(jù)支持的戰(zhàn)略集合。它是單個數(shù)據(jù)存儲,出于分析性報告和決策支持目的而創(chuàng)建。為需要業(yè)務(wù)智能的企業(yè),提供指導(dǎo)業(yè)務(wù)流程改進、監(jiān)視時間、成本、質(zhì)量以及控制。
數(shù)據(jù)倉庫的用途
1.整合公司所有業(yè)務(wù)數(shù)據(jù),建立統(tǒng)一的數(shù)據(jù)中心
2.產(chǎn)生業(yè)務(wù)報表,用于作出決策
3.為網(wǎng)站運營提供運營上的數(shù)據(jù)支持
4.可以作為各個業(yè)務(wù)的數(shù)據(jù)源,形成業(yè)務(wù)數(shù)據(jù)互相反饋的良性循環(huán)
5.分析用戶行為數(shù)據(jù),通過數(shù)據(jù)挖掘來降低投入成本,提高投入效果
6.開發(fā)數(shù)據(jù)產(chǎn)品,直接或間接地為公司盈利
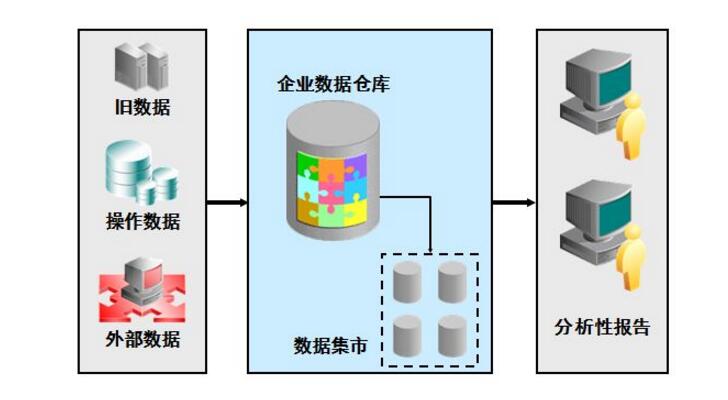
數(shù)據(jù)倉庫分層的原因
1通過數(shù)據(jù)預(yù)處理提高效率,因為預(yù)處理,所以會存在冗余數(shù)據(jù)
2如果不分層而業(yè)務(wù)系統(tǒng)的業(yè)務(wù)規(guī)則發(fā)生變化,就會影響整個數(shù)據(jù)清洗過程,工作量巨大
3通過分層管理來實現(xiàn)分步完成工作,這樣每一層的處理邏輯就簡單了
標(biāo)準(zhǔn)的數(shù)據(jù)倉庫分層:ods(臨時存儲層),pdw(數(shù)據(jù)倉庫層),mid(數(shù)據(jù)集市層),app(應(yīng)用層)
ods:歷史存儲層,它和源系統(tǒng)數(shù)據(jù)是同構(gòu)的,而且這一層數(shù)據(jù)粒度是最細的,這層的表分為兩種,一種是存儲當(dāng)前需要加載的數(shù)據(jù),一種是用于存儲處理完后的數(shù)據(jù)。
pdw:數(shù)據(jù)倉庫層,它的數(shù)據(jù)是干凈的數(shù)據(jù),是一致的準(zhǔn)確的,也就是清洗后的數(shù)據(jù),它的數(shù)據(jù)一般都遵循數(shù)據(jù)庫第三范式,數(shù)據(jù)粒度和ods的粒度相同,它會保存bi系統(tǒng)中所有歷史數(shù)據(jù)
mid:數(shù)據(jù)集市層,它是面向主題組織數(shù)據(jù)的,通常是星狀和雪花狀數(shù)據(jù),從數(shù)據(jù)粒度將,它是輕度匯總級別的數(shù)據(jù),已經(jīng)不存在明細的數(shù)據(jù)了,從廣度來說,它包含了所有業(yè)務(wù)數(shù)量。從分析角度講,大概就是近幾年
app:應(yīng)用層,數(shù)據(jù)粒度高度匯總,倒不一定涵蓋所有業(yè)務(wù)數(shù)據(jù),只是mid層數(shù)據(jù)的一個子集。

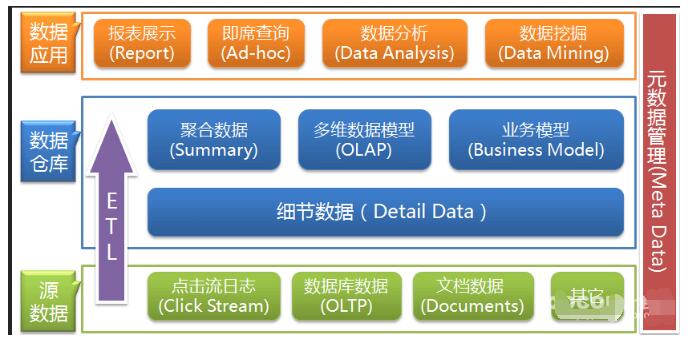
數(shù)據(jù)倉庫的架構(gòu)圖介紹
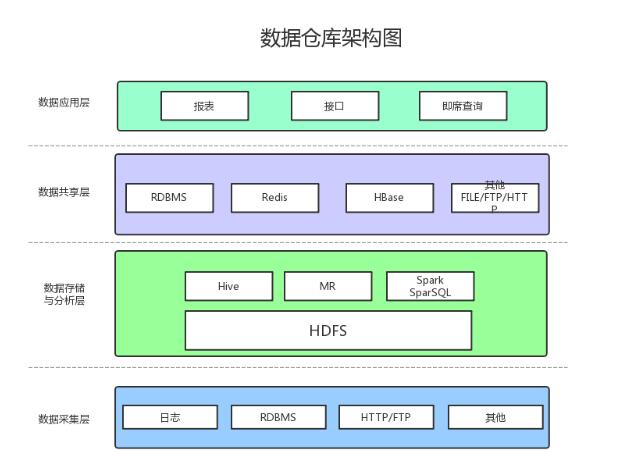
1、數(shù)據(jù)采集
數(shù)據(jù)采集層的任務(wù)就是把數(shù)據(jù)從各種數(shù)據(jù)源中采集和存儲到數(shù)據(jù)存儲上,期間有可能會做一些ETL操作。
數(shù)據(jù)源種類可以有多種:
日志:所占份額最大,存儲在備份服務(wù)器上
業(yè)務(wù)數(shù)據(jù)庫:如Mysql、Oracle
來自HTTP/FTP的數(shù)據(jù):合作伙伴提供的接口
其他數(shù)據(jù)源:如Excel等需要手工錄入的數(shù)據(jù)
2、數(shù)據(jù)存儲與分析
HDFS是大數(shù)據(jù)環(huán)境下數(shù)據(jù)倉庫/數(shù)據(jù)平臺最完美的數(shù)據(jù)存儲解決方案。
離線數(shù)據(jù)分析與計算,也就是對實時性要求不高的部分,Hive是不錯的選擇。
使用Hadoop框架自然而然也提供了MapReduce接口,如果真的很樂意開發(fā)Java,或者對SQL不熟,那么也可以使用MapReduce來做分析與計算。
Spark性能比MapReduce好很多,同時使用SparkSQL操作Hive。
3、數(shù)據(jù)共享
前面使用Hive、MR、Spark、SparkSQL分析和計算的結(jié)果,還是在HDFS上,但大多業(yè)務(wù)和應(yīng)用不可能直接從HDFS上獲取數(shù)據(jù),那么就需要一個數(shù)據(jù)共享的地方,使得各業(yè)務(wù)和產(chǎn)品能方便的獲取數(shù)據(jù)。
這里的數(shù)據(jù)共享,其實指的是前面數(shù)據(jù)分析與計算后的結(jié)果存放的地方,其實就是關(guān)系型數(shù)據(jù)庫和NOSQL數(shù)據(jù)庫。
4、數(shù)據(jù)應(yīng)用
報表:報表所使用的數(shù)據(jù),一般也是已經(jīng)統(tǒng)計匯總好的,存放于數(shù)據(jù)共享層。
接口:接口的數(shù)據(jù)都是直接查詢數(shù)據(jù)共享層即可得到。
即席查詢:即席查詢通常是現(xiàn)有的報表和數(shù)據(jù)共享層的數(shù)據(jù)并不能滿足需求,需要從數(shù)據(jù)存儲層直接查詢。一般都是通過直接操作SQL得到。
理想的數(shù)據(jù)倉庫架構(gòu)
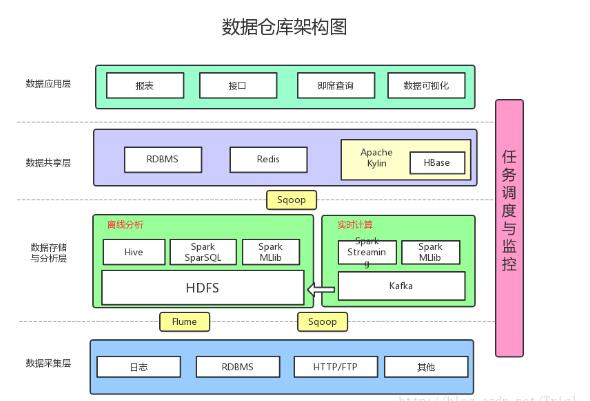
增加了以下內(nèi)容:
數(shù)據(jù)采集:采用Flume收集日志,采用Sqoop將RDBMS以及NoSQL中的數(shù)據(jù)同步到HDFS上
消息系統(tǒng):可以加入Kafka防止數(shù)據(jù)丟失
實時計算:實時計算使用SparkStreaming消費Kafka中收集的日志數(shù)據(jù),實時計算結(jié)果大多保存在Redis中
機器學(xué)習(xí):使用了SparkMLlib提供的機器學(xué)習(xí)算法
多維分析OLAP:使用Kylin作為OLAP引擎
數(shù)據(jù)可視化:提供可視化前端頁面,方便運營等非開發(fā)人員直接查詢
-
數(shù)據(jù)倉庫
+關(guān)注
關(guān)注
0文章
61瀏覽量
10564
發(fā)布評論請先 登錄
相關(guān)推薦
基于阿里云數(shù)加MaxCompute的企業(yè)大數(shù)據(jù)倉庫架構(gòu)建設(shè)思路
應(yīng)用部署架構(gòu)圖
RT-Thread 架構(gòu)圖
PCIE基本概念與拓撲架構(gòu)圖
電信數(shù)據(jù)倉庫設(shè)計
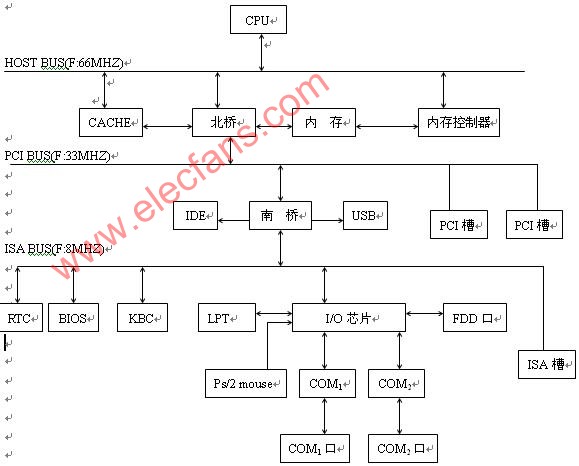
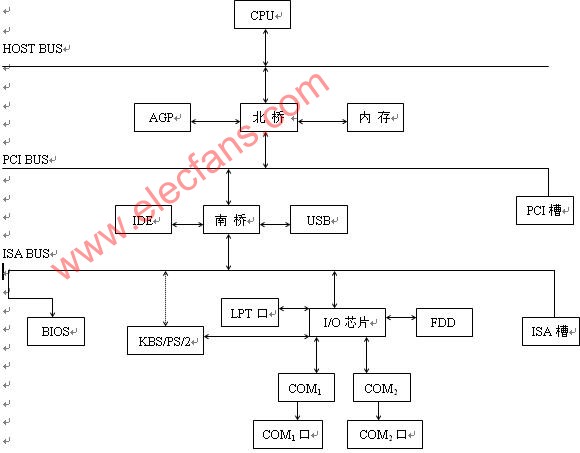
什么是paas平臺_paas邏輯架構(gòu)圖

數(shù)據(jù)倉庫是什么_數(shù)據(jù)倉庫的特點_數(shù)據(jù)倉庫與數(shù)據(jù)庫區(qū)別





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論