 如何利用FPGA技術革新視覺人工智能應用?
如何利用FPGA技術革新視覺人工智能應用?
嵌入式視覺人工智能應用通過在邊緣實現高度復雜的實時視頻流處理和決策,正在為各行各業帶來變革。這些應用范圍從自動駕駛到智能制造,其中快速分析視覺數據至關重要。這些應用要求實時處理、低延遲和低功耗,以有效分析和解釋視覺數據。
挑戰
要滿足嵌入式人工智能應用的嚴格要求,選擇合適的硬件平臺至關重要。這些要求包括在保持低功耗的同時,以最小的確定性延遲實現高性能視頻處理。人工智能邊緣應用的另一個要求是與多個傳感器和其他外圍設備互聯。CPU和GPU等傳統處理器往往難以滿足這些要求;CPU專為順序處理而設計,無法提供并行化處理器架構的處理帶寬;GPU即使基于高度并行化架構,也難以實現高能效和超低確定性延遲;這兩種技術都無法提供復雜的傳感器融合功能。ASIC雖然能夠實現超低延遲、高能效和傳感器融合能力,但并不適合需要靈活適應不斷發展的人工智能算法的應用。
解決方案
瑞蘇盈科FPGA開發板為應對嵌入式視覺人工智能的挑戰提供了令人信服的解決方案:
并行處理:可同時處理多個數據流,是實現高度并行化人工智能模型的完美硬件平臺。
(超)低延遲:通過在硬件層面對算法實施的完全控制,可以實現超低延遲設計,這在需要瞬間決策的應用中是一個關鍵因素。
電源效率:可定制的邏輯塊和較少的處理開銷可優化功耗,使其成為邊緣人工智能和功耗關鍵型應用的理想選擇。
靈活性:可進行空中重新編程,以適應不斷發展的人工智能算法,而無需重新設計硬件,從而確保了較長的產品生命周期。
傳感器融合:FPGA器件擁有大量不同類型的I/O,支持各種數據協議,能夠直接連接大量傳感器和其他外圍設備,簡化了系統架構,使數據協議適配器、電平轉換器等變得過時。

Mercury+ XU7和Mercury+ ST1
應用實例
瑞蘇盈科設計服務團隊在產品Mercury+ XU7和Mercury+ ST1基板上實現了視覺人工智能應用。Enclustra團隊將兩個可用的人工智能模型(圖像分類(基于 YoloV3)和序列中的汽車顏色檢測)結合起來,以實現最高的算法性能。這些模型是使用AMD Vitis AI工具鏈實現的,該工具鏈可將AI模型轉化為FPGA/SoC結構中的最佳實施方案,并實現SoC資源的最佳利用。
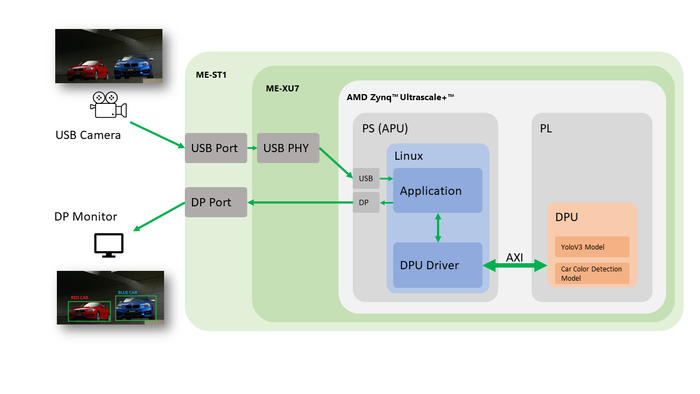
Enclustra FPGA/SoC模塊和基板組合
(Mercury+ XU7和Mercury+ ST1)上的視覺人工智能應用
FPGA技術在性能、效率和適應性方面的獨特組合使其成為下一代嵌入式人工智能應用的首選硬件。瑞蘇盈科在FPGA技術和FPGA開發工具方面擁有豐富的經驗,能夠將最初的想法轉化為現實!
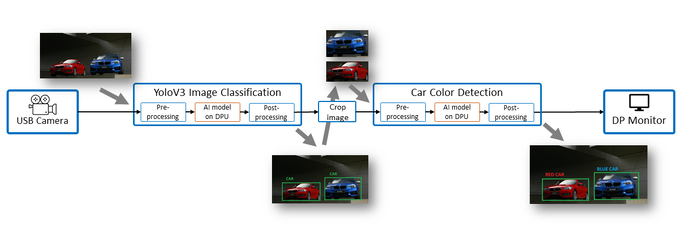
兩個人工智能模型的序列:
基于YoloV3的圖像分類和汽車顏色檢測
水星Mercury+ XU7亮點

水星Mercury+ XU7核心板
(點擊圖片,了解更多產品詳情)
基于AMD Xilinx's Zynq Ultrascale+ MPSoC XCZU6EG/9EG/15EG
PS端(DDR4 ECC SDRAM)和PL端(DDR4 SDRAM)2個獨立的內存通道
最高28.8 GByte/sec內存帶寬
提供PCIe Gen2 x 4,2 x USB 3.0,2x Gigabit Ethernet
多個型號可供選擇,提供工業級型號
采用3個168-pin Hirose FX10連接器,引出236個用戶I/O
提供Linux BSP和工具鏈
功能強大、身材小巧的FPGA核心板
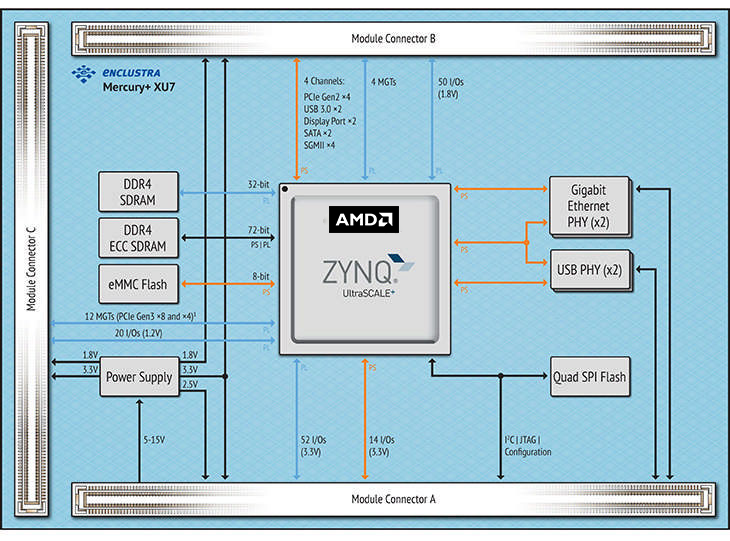
水星Mercury+ XU7結構框圖
水星Mercury+ ST1亮點

水星Mercury+ ST1底板
(點擊圖片,了解更多產品詳情)
兼容所有水星Mercury(+)系列FPGA和SoC核心板
適用于從原型到量產
身材緊湊(120 × 100 mm)
為視頻應用而設計的大量接口
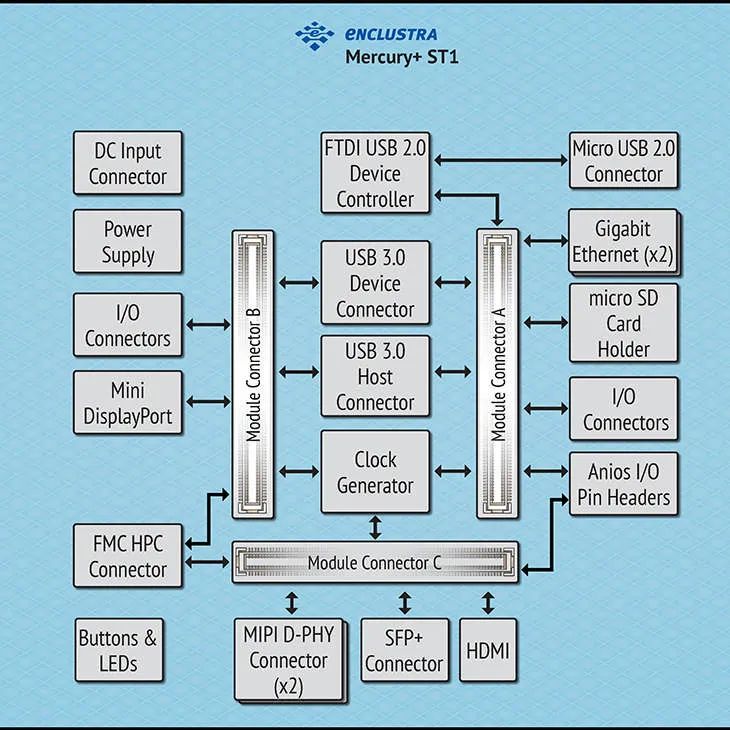
水星Mercury+ ST1結構框圖
-
FPGA
+關注
關注
1629文章
21756瀏覽量
604236 -
嵌入式
+關注
關注
5086文章
19144瀏覽量
306095 -
人工智能
+關注
關注
1792文章
47410瀏覽量
238925
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論