 服務器數據恢復—RAID5陣列硬盤離線但熱備盤未激活的數據恢復案例
服務器數據恢復—RAID5陣列硬盤離線但熱備盤未激活的數據恢復案例
服務器數據恢復環境:
一臺服務器上有一組由5塊硬盤(4塊數據盤+1塊熱備盤)組建的raid5陣列。服務器安裝Linux Redhat操作系統,運行一套基于oracle數據庫的OA系統。
服務器故障:
這組raid5陣列中一塊磁盤離線,但是熱備盤并沒有自動激活rebuild,當另外一塊數據盤發生故障離線后,raid崩潰。
用戶方要求恢復raid數據,同時要求還原操作系統。經過初步觀察,raid中的這些硬盤沒有表現出存在明顯的物理故障的特征,也沒有明顯的同步表現,數據恢復的可能性很大。
服務器數據恢復過程:
1、關閉服務器,將所有磁盤標記后取出并掛到一個只讀環境上進行完整磁盤鏡像。鏡像完成后將所有磁盤按照原樣還原到原服務器中,后后續的數據分析和數據恢復操作都基于鏡像文件進行,避免對原始磁盤數據造成二次破壞。
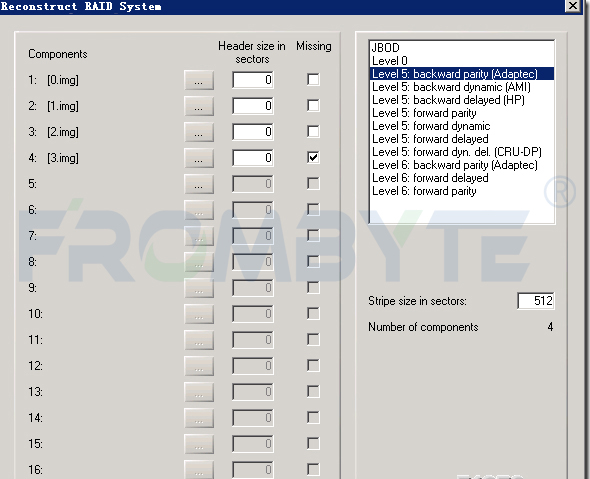
2、鏡像過程中在后掉線的硬盤中發現了幾十個壞扇區,其他硬盤都沒有發現問題。基于鏡像文件分析所有磁盤底層數據,或者重組raid所需要的信息(盤序、塊大小、數據校驗方式、條帶方向等)。
 北亞企安數據恢復—RAID5數據恢復
北亞企安數據恢復—RAID5數據恢復
3、嘗試重組raid。重組完成后驗證數據,發現數據量在200M以上壓縮包解壓正常,說明raid結構是正確的。按照這個結構在一塊單盤上生成raid并嘗試打開,沒有報錯。
4、將生成raid的這塊單盤接入到原服務器。用linux SystemRescueCd啟動,然后通過dd命令進行全盤回寫。啟動操作系統出現報錯:/etc/rc.d/rc.sysinit:Line 1:/sbin/pidof:Permission denied,
初步判斷這個文件權限出了問題。使用SystemRescueCd重啟檢查后發現該文件的權限、大小、時間都存在明顯的錯誤,節點損壞。
5、重新分析重組數據中的根分區,定位出錯的/sbin/pidof,發現導致問題出現的原因就是那塊后掉線磁盤上的壞道。使用另外幾塊完好的數據盤對后掉線的那塊盤的損壞區域進行xor補齊,可是補齊之后校驗文件系統依然報錯。再一次檢查iNode表發現后掉線的那塊盤的損壞區域有部分節點表現為55 55 55部分。
 北亞企安數據恢復—RAID5數據恢復
北亞企安數據恢復—RAID5數據恢復
6、節點中描述的uid雖然看起來正常,但是大小、屬性、最初分配塊都是錯誤的。分析了所有的可能性方案,發現都無法將這個損壞節點找回來,只能嘗試修復或者以相同文件代替。
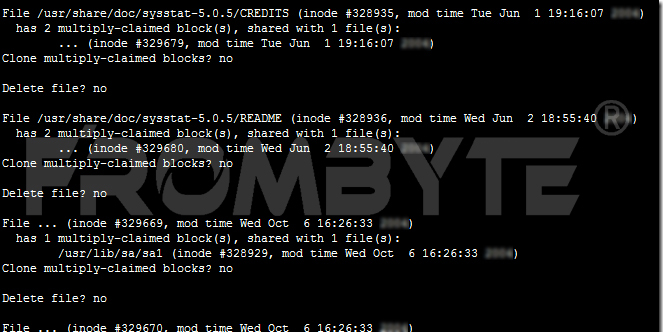
7、通過日志將所有可能有錯的文件原節點塊的節點信息確定出來,然后進行修正。修正之后重新dd根分區,然后執行fsck -fn /dev/sda5,仍然報錯。
 北亞企安數據恢復—RAID5數據恢復
北亞企安數據恢復—RAID5數據恢復
8、根據報錯提示重新分析,發現系統中有多個節點共用同樣的數據塊,原來是第一塊離線硬盤的掉線時間比較早,導致出現節點信息新舊交集的情況。將錯誤節點清除后再次執行fsck -fn /dev/sda5,依然報錯。
好在這些節點大多是在doc目錄下,不影響系統啟動。于是強行修復&重啟系統,進入桌面啟動數據庫和應用軟件,無報錯。
9、用戶方仔細檢測后,確認重要數據都在,認可數據恢復結果。
審核編輯 黃宇
-
服務器
+關注
關注
12文章
9184瀏覽量
85481 -
數據恢復
+關注
關注
10文章
575瀏覽量
17468 -
RAID5
+關注
關注
0文章
121瀏覽量
12732
發布評論請先 登錄
相關推薦

服務器數據恢復—RAID5陣列熱備盤同步數據失敗的數據恢復案例
服務器數據恢復—raid5陣列崩潰導致上層lun無法正常使用的數據恢復案例

服務器數據恢復—raid5陣列熱備盤未全部成功啟用的數據恢復案例
服務器數據恢復—硬盤離線導致Raid5陣列熱備盤上線失敗的數據恢復案例

服務器數據恢復—raid5陣列熱備盤同步失敗的數據恢復案例
服務器數據恢復—raid5陣列熱備盤未完全激活導致陣列崩潰的數據恢復案例
服務器數據恢復—raid5熱備盤同步過程中硬盤離線的數據恢復案例
服務器數據恢復—華為OceanStor存儲raid5數據恢復案例





 工商網監
工商網監
評論