 拉格朗日乘子法和KKT條件的定義及選取原因
拉格朗日乘子法和KKT條件的定義及選取原因
拉格朗日乘子法無疑是最優化理論中最重要的一個方法。但是現在網上并沒有很好的完整介紹整個方法的文章。所以小編整理了如下文章,希望能博得大家一贊。
在求取有約束條件的優化問題時,拉格朗日乘子法(Lagrange Multiplier) 和KKT條件是非常重要的兩個求取方法,對于等式約束的優化問題,可以應用拉格朗日乘子法去求取最優值;如果含有不等式約束,可以應用KKT條件去求取。當然,這兩個方法求得的結果只是必要條件,只有當是凸函數的情況下,才能保證是充分必要條件。
KKT條件是拉格朗日乘子法的泛化。之前學習的時候,只知道直接應用兩個方法,但是卻不知道為什么拉格朗日乘子法(Lagrange Multiplier) 和KKT條件能夠起作用,為什么要這樣去求取最優值呢?本文將首先把什么是拉格朗日乘子法(Lagrange Multiplier) 和KKT條件敘述一下;然后開始分別談談為什么要這樣求最優值。
一.拉格朗日乘子法(Lagrange Multiplier) 和KKT條件通常我們需要求解的最優化問題有如下幾類
:(i) 無約束優化問題,可以寫為:min f(x); (ii) 有等式約束的優化問題,可以寫為:min f(x),s.t. h_i(x) = 0; i =1, ..., n(iii) 有不等式約束的優化問題,可以寫為:min f(x),s.t. g_i(x) <= 0; i =1, ..., nh_j(x) = 0; j =1, ..., m對于第(i)類的優化問題,常常使用的方法就是Fermat定理,即使用求取f(x)的導數,然后令其為零,可以求得候選最優值,再在這些候選值中驗證;如果是凸函數,可以保證是最優解。對于第(ii)類的優化問題,常常使用的方法就是拉格朗日乘子法(Lagrange Multiplier) ,即把等式約束h_i(x)用一個系數與f(x)寫為一個式子,稱為拉格朗日函數,而系數稱為拉格朗日乘子。通過拉格朗日函數對各個變量求導,令其為零,可以求得候選值集合,然后驗證求得最優值。
對于第(iii)類的優化問題,常常使用的方法就是KKT條件。同樣地,我們把所有的等式、不等式約束與f(x)寫為一個式子,也叫拉格朗日函數,系數也稱拉格朗日乘子,通過一些條件,可以求出最優值的必要條件,這個條件稱為KKT條件。
(a)拉格朗日乘子法(Lagrange Multiplier)對于等式約束,我們可以通過一個拉格朗日系數a 把等式約束和目標函數組合成為一個式子L(a, x) = f(x) + a*h(x), 這里把a和h(x)視為向量形式,a是橫向量,h(x)為列向量,之所以這么寫,完全是因為csdn很難寫數學公式,只能將就了.....。然后求取最優值,可以通過對L(a,x)對各個參數求導取零,聯立等式進行求取,這個在高等數學里面有講,但是沒有講為什么這么做就可以,在后面,將簡要介紹其思想。(b)KKT條件對于含有不等式約束的優化問題,如何求取最優值呢?常用的方法是KKT條件,同樣地,把所有的不等式約束、等式約束和目標函數全部寫為一個式子L(a, b, x)= f(x) + a*g(x)+b*h(x),KKT條件是說最優值必須滿足以下條件:
1. L(a, b, x)對x求導為零;2. h(x) =0;3. a*g(x) = 0;求取這三個等式之后就能得到候選最優值。其中第三個式子非常有趣,因為g(x)<=0,如果要滿足這個等式,必須a=0或者g(x)=0. 這是SVM的很多重要性質的來源,如支持向量的概念。
二. 為什么拉格朗日乘子法(Lagrange Multiplier) 和KKT條件能夠得到最優值?
為什么要這么求能得到最優值?先說拉格朗日乘子法,設想我們的目標函數z = f(x), x是向量, z取不同的值,相當于可以投影在x構成的平面(曲面)上,即成為等高線,如下圖,目標函數是f(x, y),這里x是標量,虛線是等高線,現在假設我們的約束g(x)=0,x是向量,在x構成的平面或者曲面上是一條曲線,假設g(x)與等高線相交,交點就是同時滿足等式約束條件和目標函數的可行域的值,但肯定不是最優值,因為相交意味著肯定還存在其它的等高線在該條等高線的內部或者外部,使得新的等高線與目標函數的交點的值更大或者更小,只有到等高線與目標函數的曲線相切的時候,可能取得最優值,如下圖所示,即等高線和目標函數的曲線在該點的法向量必須有相同方向,所以最優值必須滿足:f(x)的梯度 = a* g(x)的梯度,a是常數,表示左右兩邊同向。這個等式就是L(a,x)對參數求導的結果。
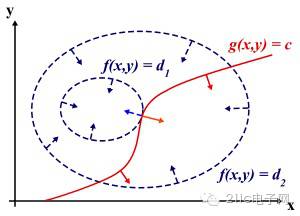
而KKT條件是滿足強對偶條件的優化問題的必要條件,可以這樣理解:我們要求min f(x), L(a, b, x) = f(x) + a*g(x) + b*h(x),a>=0,我們可以把f(x)寫為:max_{a,b} L(a,b,x),為什么呢?因為h(x)=0, g(x)<=0,現在是取L(a,b,x)的最大值,a*g(x)是<=0,所以L(a,b,x)只有在a*g(x) = 0的情況下才能取得最大值,否則,就不滿足約束條件,因此max_{a,b} L(a,b,x)在滿足約束條件的情況下就是f(x),因此我們的目標函數可以寫為 min_x max_{a,b} L(a,b,x)。如果用對偶表達式:?max_{a,b}?min_x ?L(a,b,x),由于我們的優化是滿足強對偶的(強對偶就是說對偶式子的最優值是等于原問題的最優值的),所以在取得最優值x0的條件下,它滿足 f(x0) =?max_{a,b}?min_x ?L(a,b,x) =?min_x max_{a,b} L(a,b,x) =f(x0),我們來看看中間兩個式子發生了什么事情:
f(x0) =max_{a,b}min_x L(a,b,x) =max_{a,b}min_x f(x) + a*g(x) + b*h(x) =max_{a,b} f(x0)+a*g(x0)+b*h(x0)= f(x0)
可以看到上述加黑的地方本質上是說min_xf(x) + a*g(x) + b*h(x) 在x0取得了最小值,用fermat定理,即是說對于函數f(x) + a*g(x) + b*h(x),求取導數要等于零,即f(x)的梯度+a*g(x)的梯度+ b*h(x)的梯度 = 0
這就是kkt條件中第一個條件:L(a, b, x)對x求導為零。
而之前說明過,a*g(x) = 0,這時kkt條件的第3個條件,當然已知的條件h(x)=0必須被滿足,所有上述說明,滿足強對偶條件的優化問題的最優值都必須滿足KKT條件,即上述說明的三個條件。可以把KKT條件視為是拉格朗日乘子法的泛化。
-
機器學習
+關注
關注
66文章
8425瀏覽量
132773
原文標題:機器學習基礎 深入理解拉格朗日乘子法
文章出處:【微信號:weixin21ic,微信公眾號:21ic電子網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
機器學習基礎|深入理解拉格朗日乘子法
條件編譯是先判斷變量是否被宏定義嗎
如何利用文件名來定義case結構的條件
基于預條件共軛梯度法的混凝土層析成像
如何搞定機器學習中的拉格朗日?看看這個乘子法與KKT條件大招
基于KKT和SVM算法的云架構入侵檢測系統
區間聯絡線選取方法

機器學習筆記之優化-拉格朗日乘子法和對偶分解
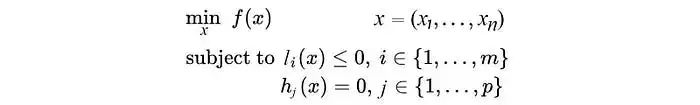





 工商網監
工商網監
評論