") AlphaZero完爆人類棋類游戲 刷新對(duì)人工智能的認(rèn)知
AlphaZero完爆人類棋類游戲 刷新對(duì)人工智能的認(rèn)知
或許“智能爆炸”不會(huì)發(fā)生,但永遠(yuǎn)不要低估人工智能的發(fā)展。推出最強(qiáng)圍棋AI AlphaGo Zero不到50天,DeepMind又一次超越了他們自己,也刷新了世人對(duì)人工智能的認(rèn)知。12月5日,包括David Silver、Demis Hassabis等人在內(nèi)的DeepMind團(tuán)隊(duì)發(fā)表論文,提出通用棋類AI AlphaZero,從零開(kāi)始訓(xùn)練,除了基本規(guī)則沒(méi)有任何其他知識(shí),4小時(shí)擊敗最強(qiáng)國(guó)際象棋AI、2小時(shí)擊敗最強(qiáng)將棋AI,8小時(shí)擊敗李世石版AlphaGo,連最強(qiáng)圍棋AI AlphaGo Zero也不能幸免:訓(xùn)練34小時(shí)的AlphaZero勝過(guò)了訓(xùn)練72小時(shí)的AlphaGo Zero。
由于是通用棋類AI,因此去掉了代表圍棋的英文“Go”,沒(méi)有使用人類知識(shí),從零開(kāi)始訓(xùn)練,所以用Zero,兩相結(jié)合得到“AlphaZero”,這個(gè)新AI強(qiáng)在哪里?
世界最強(qiáng)圍棋AI AlphaGo Zero帶給世人的震撼并沒(méi)有想象中那么久——不是因?yàn)榇蠹叶既タ凑l(shuí)(沒(méi))跟誰(shuí)吃飯了,而是DeepMind再次迅速超越了他們自己,超越了我們剩下所有人的想象。
12月5日,距離發(fā)布AlphaGo Zero論文后不到兩個(gè)月,他們?cè)赼rXiv上傳最新論文《用通用強(qiáng)化學(xué)習(xí)算法自我對(duì)弈,掌握國(guó)際象棋和將棋》(Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm),用看似平淡的標(biāo)題,平淡地拋出一個(gè)炸彈。
其中,DeepMind團(tuán)隊(duì)描述了一個(gè)通用棋類AI“AlphaZero”,在不同棋類游戲中,戰(zhàn)勝了所有對(duì)手,而這些對(duì)手都是各自領(lǐng)域的頂級(jí)AI:
戰(zhàn)勝最強(qiáng)國(guó)際象棋AI Stockfish:28勝,0負(fù),72平;
戰(zhàn)勝最強(qiáng)將棋AI Elmo:90勝,2平,8負(fù);
戰(zhàn)勝最強(qiáng)圍棋AI AlphaGo Zero:60勝,40負(fù)
其中,Stockfish是世界上最強(qiáng)的國(guó)際象棋引擎之一,它比最好的人類國(guó)際象棋大師還要強(qiáng)大得多。與大多數(shù)國(guó)際象棋引擎不同,Stockfish是開(kāi)源的(GPL license)。用戶可以閱讀代碼,進(jìn)行修改,回饋,甚至在自己的項(xiàng)目中使用它,而這也是它強(qiáng)大的一個(gè)原因。
將棋AI Elmo的開(kāi)發(fā)者是日本人瀧澤城,在第27屆世界計(jì)算機(jī)將棋選手權(quán)賽中獲得優(yōu)勝。Elmo的策略是在對(duì)戰(zhàn)中搜索落子在哪個(gè)位置勝率更高,判斷對(duì)戰(zhàn)形勢(shì),進(jìn)而調(diào)整策略。Elmo名字的由來(lái)是electric monkey(電動(dòng)猴子,越來(lái)越強(qiáng)大之意),根據(jù)作者的說(shuō)法也有elastic monkey(橡皮猴子,愈挫愈勇)之意。
而AlphaGo Zero更是不必介紹,相信“阿法元”之名已經(jīng)傳遍中國(guó)大江南北。而AlphaZero在訓(xùn)練34小時(shí)后,也勝過(guò)了訓(xùn)練72小時(shí)的AlphaGo Zero。
AlphaZero橫空出世,網(wǎng)上已經(jīng)炸開(kāi)了鍋,Reddit網(wǎng)友紛紛評(píng)論:AlphaZero已經(jīng)不是機(jī)器的棋了,是神仙棋,非常優(yōu)美,富有策略性,更能深刻地謀劃(maneuver),完全是在調(diào)戲Stockfish。
看著AlphaZero贏,簡(jiǎn)直太不可思議了!這根本就不是計(jì)算機(jī),這壓根兒就是人啊!
Holy fu*ck,第9場(chǎng)比賽太特么瘋狂了!
DeepMind太神了!
我的神啊!它竟然只玩d4/c4。總體上來(lái)看,它似乎比我們訓(xùn)練的要少得多。
這條消息太瘋狂了。
而知乎上,短短幾小時(shí)內(nèi)也有很多評(píng)論:
知乎用戶fffasttime:專治各種不服的DeepMind又出師了,但這次的主攻的內(nèi)容不再是圍棋了,而是所有的棋類游戲。……之前AlphaGo把圍棋界打得心態(tài)崩了,而現(xiàn)在AlphaZero贏的不光是人類棋手,還包括各路象棋的AI作者。
知乎用戶陸君慨:棋類的解決框架一直都是基于 minimax + heuristic。以前圍棋難是因?yàn)閙inimax在有著很大分支的游戲上無(wú)法產(chǎn)生足夠的深度,并且heuristic難以設(shè)計(jì)。Alphago Zero時(shí)候就已經(jīng)證明了cnn很適合做heuristic,而mcts也可以解決深度問(wèn)題。那為什么別人不做呢?
因?yàn)樨毟F限制了我們的想象力。
有錢真的是可以為所欲為。
比AlphaGo Zero更強(qiáng)的AlphaZero來(lái)了!8小時(shí)解決一切棋類!
知乎用戶PENG Bo迅速就發(fā)表了感慨,我們?nèi)〉昧怂氖跈?quán),轉(zhuǎn)載如下(知乎鏈接見(jiàn)文末):
讀過(guò)AlphaGo Zero論文的同學(xué),可能都驚訝于它的方法的簡(jiǎn)單。另一方面,深度神經(jīng)網(wǎng)絡(luò),是否能適用于國(guó)際象棋這樣的與圍棋存在諸多差異的棋類?MCTS(蒙特卡洛樹(shù)搜索)能比得上alpha-beta搜索嗎?許多研究者都曾對(duì)此表示懷疑。
但今天AlphaZero來(lái)了(https://arxiv.org/pdf/1712.01815.pdf),它破除了一切懷疑,通過(guò)使用與AlphaGo Zero一模一樣的方法(同樣是MCTS+深度網(wǎng)絡(luò),實(shí)際還做了一些簡(jiǎn)化),它從零開(kāi)始訓(xùn)練:
4小時(shí)就打敗了國(guó)際象棋的最強(qiáng)程序Stockfish!
2小時(shí)就打敗了日本將棋的最強(qiáng)程序Elmo!
8小時(shí)就打敗了與李世石對(duì)戰(zhàn)的AlphaGo v18!
在訓(xùn)練后,它面對(duì)Stockfish取得100盤不敗的恐怖戰(zhàn)績(jī),而且比之前的AlphaGo Zero也更為強(qiáng)大(根據(jù)論文后面的表格,訓(xùn)練34小時(shí)的AlphaZero勝過(guò)訓(xùn)練72小時(shí)的AlphaGo Zero)。
這令人震驚,因?yàn)榇饲按蠹叶颊J(rèn)為Stockfish已趨于完美,它的代碼中有無(wú)數(shù)人類精心構(gòu)造的算法技巧。
然而,現(xiàn)在Stockfish就像一位武術(shù)大師,碰上了用槍的AlphaZero,被一槍斃命。
喜歡國(guó)象的同學(xué)注意了:AlphaZero不喜歡西西里防御。
訓(xùn)練過(guò)程極其簡(jiǎn)單粗暴。超參數(shù),網(wǎng)絡(luò)架構(gòu)都不需要調(diào)整。無(wú)腦上算力,就能解決一切問(wèn)題。
Stockfish和Elmo,每秒種需要搜索高達(dá)幾千萬(wàn)個(gè)局面。
AlphaZero每秒種僅需搜索幾萬(wàn)個(gè)局面,就將他們碾壓。深度網(wǎng)絡(luò)真是狂拽炫酷。
當(dāng)然,訓(xùn)練AlphaZero所需的計(jì)算資源也是海量的。這次DeepMind直接說(shuō)了,需要5000個(gè)TPU v1作為生成自對(duì)弈棋譜。
不過(guò),隨著硬件的發(fā)展,這樣的計(jì)算資源會(huì)越來(lái)越普及。未來(lái)的AI會(huì)有多強(qiáng)大,確實(shí)值得思考。
個(gè)人一直認(rèn)為,MCTS+深度網(wǎng)絡(luò)是非常強(qiáng)的組合,因?yàn)镸CTS可為深度網(wǎng)絡(luò)補(bǔ)充邏輯性。我預(yù)測(cè),這個(gè)組合未來(lái)會(huì)在更多場(chǎng)合顯示威力,例如有可能真正實(shí)現(xiàn)自動(dòng)寫代碼,自動(dòng)數(shù)學(xué)證明。
為什么說(shuō)編程和數(shù)學(xué),因?yàn)檫@兩個(gè)領(lǐng)域和下棋一樣,都有明確的規(guī)則和目標(biāo),有可模擬的環(huán)境。(在此之前,深度學(xué)習(xí)的調(diào)參黨和架構(gòu)黨估計(jì)會(huì)先被干掉...... 目前很多灌水論文,電腦以后自己都可以寫出來(lái)。)
也許在5到20年內(nèi),我們會(huì)看到《Mastering Programming and Mathematics by General Reinforcement Learning》。然后許多人都要自謀出路了......
一個(gè)通用強(qiáng)化學(xué)習(xí)算法,橫跨多個(gè)高難度領(lǐng)域,實(shí)現(xiàn)超人性能
David Silver曾經(jīng)說(shuō)過(guò),強(qiáng)化學(xué)習(xí)+深度學(xué)習(xí)=人工智能(RL+DL=AI)。而深度強(qiáng)化學(xué)習(xí)也是DeepMind一直以來(lái)致力探索的方向。AlphaZero論文也體現(xiàn)了這個(gè)思路。論文題目是《用通用強(qiáng)化學(xué)習(xí)自我對(duì)弈,掌握國(guó)際象棋和將棋》。可以看見(jiàn),AlphaGo Zero的作者Julian Schrittwieser也在其中。
 |
對(duì)計(jì)算機(jī)國(guó)際象棋的研究和計(jì)算機(jī)科學(xué)一樣古老。巴貝奇、圖靈、香農(nóng)和馮·諾依曼都設(shè)計(jì)過(guò)硬件、算法和理論來(lái)分析國(guó)際象棋,以及下國(guó)際象棋。象棋后來(lái)成為了一代人工智能研究者的挑戰(zhàn)性任務(wù),在高性能的計(jì)算機(jī)的助力下,象棋程序達(dá)到了頂峰,超越了人類的水平。然而,這些系統(tǒng)高度適應(yīng)它們的領(lǐng)域,如果沒(méi)有大量的人力投入,就不能歸納到其他問(wèn)題。
人工智能的長(zhǎng)期目標(biāo)是創(chuàng)造出可以從最初的原則自我學(xué)習(xí)的程序。最近,AlphaGo Zero算法通過(guò)使用深度卷積神經(jīng)網(wǎng)絡(luò)來(lái)表示圍棋知識(shí),僅通過(guò)自我對(duì)弈的強(qiáng)化學(xué)習(xí)來(lái)訓(xùn)練,在圍棋中實(shí)現(xiàn)了超越人類的表現(xiàn)。在本文中,除了游戲規(guī)則之外,我們還應(yīng)用了一個(gè)類似的但是完全通用的算法,我們把這個(gè)算法稱為AlphaZero,除了游戲規(guī)則之外,沒(méi)有給它任何額外的領(lǐng)域知識(shí),這個(gè)算法證明了一個(gè)通用的強(qiáng)化學(xué)習(xí)算法可以跨越多個(gè)具有挑戰(zhàn)性的領(lǐng)域?qū)崿F(xiàn)超越人類的性能,并且是以“白板”(tabula rasa)的方式。
1997年,“深藍(lán)”在國(guó)際象棋上擊敗了人類世界冠軍,這是人工智能的一個(gè)里程碑。計(jì)算機(jī)國(guó)際象棋程序在自那以后的20多年里繼續(xù)穩(wěn)步超越人類水平。這些程序使用人類象棋大師的知識(shí)和仔細(xì)調(diào)整的權(quán)重來(lái)評(píng)估落子位置,并結(jié)合高性能的alpha-beta搜索函數(shù),利用大量的啟發(fā)式和領(lǐng)域特定的適應(yīng)性來(lái)擴(kuò)展巨大的搜索樹(shù)。我們描述了這些增強(qiáng)方法,重點(diǎn)關(guān)注2016年TCEC世界冠軍Stockfish;其他強(qiáng)大的國(guó)際象棋程序,包括深藍(lán),使用的是非常相似的架構(gòu)。
在計(jì)算復(fù)雜性方面,將棋比國(guó)際象棋更難:在更大的棋盤上進(jìn)行比賽,任何被俘的對(duì)手棋子都會(huì)改變方向,隨后可能會(huì)掉到棋盤的任何位置。計(jì)算機(jī)將棋協(xié)會(huì)(CSA)的世界冠軍Elmo等最強(qiáng)大的將棋程序,直到最近才擊敗了人類冠軍。這些程序使用與計(jì)算機(jī)國(guó)際象棋程序類似的算法,再次基于高度優(yōu)化的alpha-beta搜索引擎,并具有許多特定領(lǐng)域的適應(yīng)性。
圍棋非常適合AlphaGo中使用的神經(jīng)網(wǎng)絡(luò)架構(gòu),因?yàn)橛螒蛞?guī)則是平移不變的(匹配卷積網(wǎng)絡(luò)的權(quán)重共享結(jié)構(gòu)),是根據(jù)棋盤上落子點(diǎn)之間的相鄰點(diǎn)的自由度來(lái)定義的,并且是旋轉(zhuǎn)和反射對(duì)稱的(允許數(shù)據(jù)增加和合成)。此外,動(dòng)作空間很簡(jiǎn)單(可以在每個(gè)可能的位置放置一個(gè)棋子),而且游戲結(jié)果僅限于二元輸贏,這兩者都可能有助于神經(jīng)網(wǎng)絡(luò)的訓(xùn)練。
國(guó)際象棋和將棋可能不太適合AlphaGo的神經(jīng)網(wǎng)絡(luò)架構(gòu)。這些規(guī)則是依賴于位置的(例如棋子可以從第二級(jí)向前移動(dòng)兩步,在第八級(jí)晉級(jí))和不對(duì)稱的(例如棋子只向前移動(dòng),而王翼和后翼易位則不同)。規(guī)則包括遠(yuǎn)程互動(dòng)(例如,女王可能在一步之內(nèi)穿過(guò)棋盤,或者從棋盤的遠(yuǎn)側(cè)將死國(guó)王)。國(guó)際象棋的行動(dòng)空間包括棋盤上所有棋手的所有符合規(guī)則的目的地;將棋也可以將被吃掉的棋子放回棋盤上。國(guó)際象棋和將棋都可能造成勝負(fù)之外的平局;實(shí)際上,人們認(rèn)為國(guó)際象棋的最佳解決方案就是平局。
AlphaZero:更通用的AlphaGo Zero
AlphaZero算法是AlphaGo Zero算法更通用的版本。它用深度神經(jīng)網(wǎng)絡(luò)和白板(tabula rasa)強(qiáng)化學(xué)習(xí)算法,替代傳統(tǒng)游戲程序中所使用的手工編碼知識(shí)和領(lǐng)域特定增強(qiáng)。
AlphaZero不使用手工編碼評(píng)估函數(shù)和移動(dòng)排序啟發(fā)式算法,而是利用參數(shù)為θ的深度神經(jīng)網(wǎng)絡(luò)(p,v)=fθ(s)。這個(gè)神經(jīng)網(wǎng)絡(luò)把棋盤的位置作為輸入,輸出一個(gè)落子移動(dòng)概率矢量p,其中每個(gè)動(dòng)作a的分量為pa = Pr(a | s),標(biāo)量值v根據(jù)位置s估計(jì)預(yù)期結(jié)果z,v ≈E [L| S]。AlphaZero完全從自我對(duì)弈中學(xué)習(xí)這些移動(dòng)概率和價(jià)值估計(jì),然后用學(xué)到的東西來(lái)指導(dǎo)其搜索。
AlphaZero使用通用的蒙特卡洛樹(shù)搜索(MCTS)算法。每個(gè)搜索都包含一系列自我對(duì)弈模擬,模擬時(shí)會(huì)從根節(jié)點(diǎn)到葉節(jié)點(diǎn)將一棵樹(shù)遍歷。每次模擬都是通過(guò)在每個(gè)狀態(tài)s下,根據(jù)當(dāng)前的神經(jīng)網(wǎng)絡(luò)fθ,選擇一步棋的走法移動(dòng)a,這一步具有低訪問(wèn)次數(shù)、高移動(dòng)概率和高的價(jià)值(這些值是從s中選擇a的模擬葉節(jié)點(diǎn)狀態(tài)上做了平均的)。搜索返回一個(gè)向量π,表示移動(dòng)的概率分布。
AlphaZero中的深度神經(jīng)網(wǎng)絡(luò)參數(shù)θ通過(guò)自我對(duì)弈強(qiáng)化學(xué)習(xí)(self-play reinforcement learning)來(lái)訓(xùn)練,從隨機(jī)初始化參數(shù)θ開(kāi)始。游戲中,MCTS輪流為雙方選擇下哪步棋,at?πt。游戲結(jié)束時(shí),根據(jù)游戲規(guī)則,按照最終的位置sT進(jìn)行評(píng)分,計(jì)算結(jié)果z:z為-1為輸,0為平局,+1為贏。在反復(fù)自我對(duì)弈過(guò)程中,不斷更新神經(jīng)網(wǎng)絡(luò)的參數(shù)θ,讓預(yù)測(cè)結(jié)果vt和游戲結(jié)果z之間的誤差最小化,同時(shí)使策略向量pt與搜索概率πt的相似度最大化。具體說(shuō),參數(shù)θ通過(guò)在損失函數(shù)l上做梯度下降進(jìn)行調(diào)整,這個(gè)損失函數(shù)l是均方誤差和交叉熵?fù)p失之和。
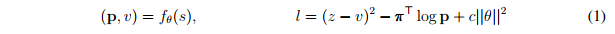
其中,c是控制L2權(quán)重正則化水平的參數(shù)。更新的參數(shù)將被用于之后的自我對(duì)弈當(dāng)中。
AlphaZero與AlphaGo Zero的4大不同
AlphaZero算法與原始的AlphaGo Zero算法有以下幾大不同:
1、AlphaGo Zero是在假設(shè)結(jié)果為贏/輸二元的情況下,對(duì)獲勝概率進(jìn)行估計(jì)和優(yōu)化。而AlphaZero會(huì)將平局或其他潛在結(jié)果也納入考慮,對(duì)結(jié)果進(jìn)行估計(jì)和優(yōu)化。
2、AlphaGo和AlphaGo Zero會(huì)轉(zhuǎn)變棋盤位置進(jìn)行數(shù)據(jù)增強(qiáng),而AlphaZero不會(huì)。根據(jù)圍棋的規(guī)則,棋盤發(fā)生旋轉(zhuǎn)和反轉(zhuǎn)結(jié)果都不會(huì)發(fā)生變化。對(duì)此,AlphaGo和AlphaGo Zero使用兩種方式應(yīng)對(duì)。首先,為每個(gè)位置生成8個(gè)對(duì)稱圖像來(lái)增強(qiáng)訓(xùn)練數(shù)據(jù)。其次,在MCTS期間,棋盤位置在被神經(jīng)網(wǎng)絡(luò)評(píng)估前,會(huì)使用隨機(jī)選擇的旋轉(zhuǎn)或反轉(zhuǎn)進(jìn)行轉(zhuǎn)換,以便MonteCarlo評(píng)估在不同的偏差上進(jìn)行平均。而在國(guó)際象棋和將棋中,棋盤是不對(duì)稱的,一般來(lái)說(shuō)對(duì)稱也是不可能的。因此,AlphaZero不會(huì)增強(qiáng)訓(xùn)練數(shù)據(jù),也不會(huì)在MCTS期間轉(zhuǎn)換棋盤位置。
3、在AlphaGo Zero中,自我對(duì)弈是由以前所有迭代中最好的玩家生成的。而這個(gè)“最好的玩家”是這樣選擇出來(lái)的:每次訓(xùn)練結(jié)束后,都會(huì)比較新玩家與最佳玩家;如果新玩家以55%的優(yōu)勢(shì)獲勝,那么它將成為新的最佳玩家,自我對(duì)弈也將由這個(gè)新玩家產(chǎn)生的。AlphaZero只維護(hù)單一的一個(gè)神經(jīng)網(wǎng)絡(luò),這個(gè)神經(jīng)網(wǎng)絡(luò)不斷更新,而不是等待迭代完成。自我對(duì)弈是通過(guò)使用這個(gè)神經(jīng)網(wǎng)絡(luò)的最新參數(shù)生成的,省略了評(píng)估步驟和選擇最佳玩家的過(guò)程。
4、使用的超參數(shù)不同:AlphaGo Zero通過(guò)貝葉斯優(yōu)化調(diào)整搜索的超參數(shù);AlphaZero中,所有對(duì)弈都重復(fù)使用相同的超參數(shù),因此無(wú)需進(jìn)行針對(duì)特定某種游戲的調(diào)整。唯一的例外是為保證探索而添加到先驗(yàn)策略中的噪音;這與棋局類型典型移動(dòng)數(shù)量成比例。
奢華的計(jì)算資源:5000個(gè)第一代TPU,64個(gè)第二代TPU,碾壓其他棋類AI
像AlphaGo Zero一樣,棋盤狀態(tài)僅由基于每個(gè)游戲的基本規(guī)則的空間平面編碼。下棋的行動(dòng)則是由空間平面或平面矢量編碼,也是僅基于每種游戲的基本規(guī)則。
作者將AlphaZero應(yīng)用在國(guó)際象棋、將棋和圍棋中,都使用同樣的算法設(shè)置、網(wǎng)絡(luò)架構(gòu)和超參數(shù)。他們?yōu)槊恳环N棋都單獨(dú)訓(xùn)練了一個(gè)AlphaZero。訓(xùn)練進(jìn)行了700,000步(minibatch大小為4096),從隨機(jī)初始化的參數(shù)開(kāi)始,使用5000個(gè)第一代TPU生成自我對(duì)弈,使用64個(gè)第二代TPU訓(xùn)練神經(jīng)網(wǎng)絡(luò)。
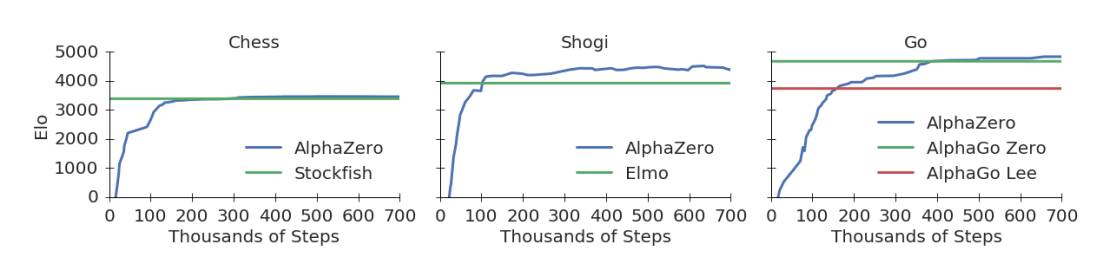
下面的圖1展示了AlphaZero在自我對(duì)弈強(qiáng)化學(xué)習(xí)中的性能。下國(guó)際象棋,AlphaZero僅用了4小時(shí)(300k步)就超越了Stockfish;下將棋,AlphaZero僅用了不到2小時(shí)(110k步)就超越了Elmo;下圍棋,AlphaZero不到8小時(shí)(165k步)就超越了李世石版的AlphaGo。
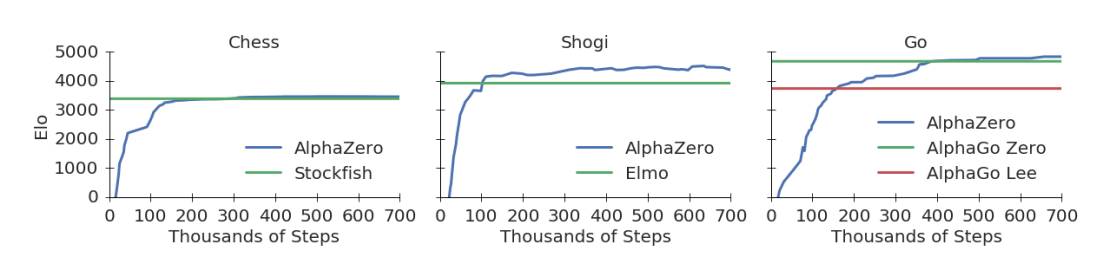
圖1:訓(xùn)練AlphaZero 70萬(wàn)步。Elo 等級(jí)分是根據(jù)不同玩家之間的比賽評(píng)估計(jì)算得出的,每一步棋有1秒的思考時(shí)間。a. AlphaZero在國(guó)際象棋上的表現(xiàn),與2016 TCEC世界冠軍程序Stockfish對(duì)局;b. AlphaZero在將棋上的表現(xiàn),與2017 CSA世界冠軍程序Elmo對(duì)局;c. AlphaZero在圍棋上的表現(xiàn),與AlphaGo Lee和AlphaGo Zero(20 block / 3 天)對(duì)戰(zhàn)。
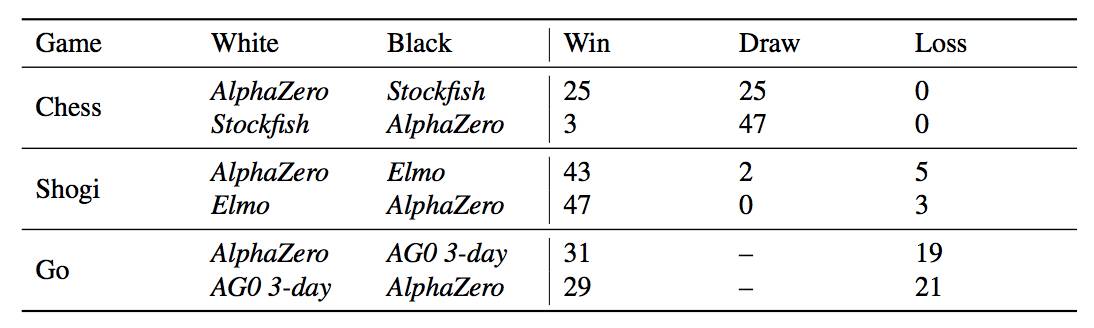
表1:AlphaZero視角下,在比賽中贏,平局或輸?shù)木謹(jǐn)?shù)。經(jīng)過(guò)3天的訓(xùn)練,AlphaZero分別與Stockfish,Elmo以及之前發(fā)布的AlphaGo Zero在國(guó)際象棋、將棋和圍棋分別進(jìn)行100場(chǎng)比賽。每個(gè)AI每步棋都有1分鐘的思考時(shí)間。
他們還使用完全訓(xùn)練好的AlphaZero與Stockfish、Elmo和AlphaGo Zero(訓(xùn)練了3天)分別在國(guó)際象棋、將棋和圍棋中對(duì)比,對(duì)局100回,每下一步的時(shí)長(zhǎng)控制在1分鐘。AlphaZero和前一版AlphaGo Zero使用一臺(tái)帶有4個(gè)TPU的機(jī)器訓(xùn)練。Stockfish和Elmo都使用最強(qiáng)版本,使用64線1GB hash的機(jī)器。AlphaZero擊敗了所有選手,與Stockfish對(duì)戰(zhàn)全勝,與Elmo對(duì)戰(zhàn)輸了8局。
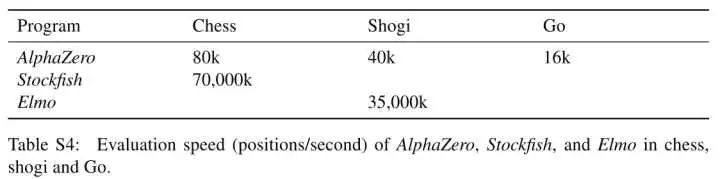
此外,他們還比較了Stockfish和Elmo使用的state-of-the-art alpha-beta搜索引擎,分析了AlphaZero的MCTS搜索的相對(duì)性能。AlphaZero在國(guó)際象棋中每秒搜索8萬(wàn)個(gè)局面(position),在將棋中搜索到4萬(wàn)個(gè)。相比之下,Stockfish每秒搜索7000萬(wàn)個(gè),Elmo每秒能搜索3500萬(wàn)個(gè)局面。AlphaZero通過(guò)使用深度神經(jīng)網(wǎng)絡(luò),更有選擇性地聚焦在最有希望的變化上來(lái)補(bǔ)償較低數(shù)量的評(píng)估,就像香農(nóng)最初提出的那樣,是一種更“人性化”的搜索方法。圖2顯示了每個(gè)玩家相對(duì)于思考時(shí)間的可擴(kuò)展性,通過(guò)Elom量表衡量,相對(duì)于Stockfish或者Elmo 40ms的思考時(shí)間。AlphaZero的MCTS的思維時(shí)間比Stockfish或Elmo更有效,這對(duì)人們普遍持有的觀點(diǎn),也即認(rèn)為alpha-beta搜索在這些領(lǐng)域本質(zhì)上具有優(yōu)越性,提出了質(zhì)疑。
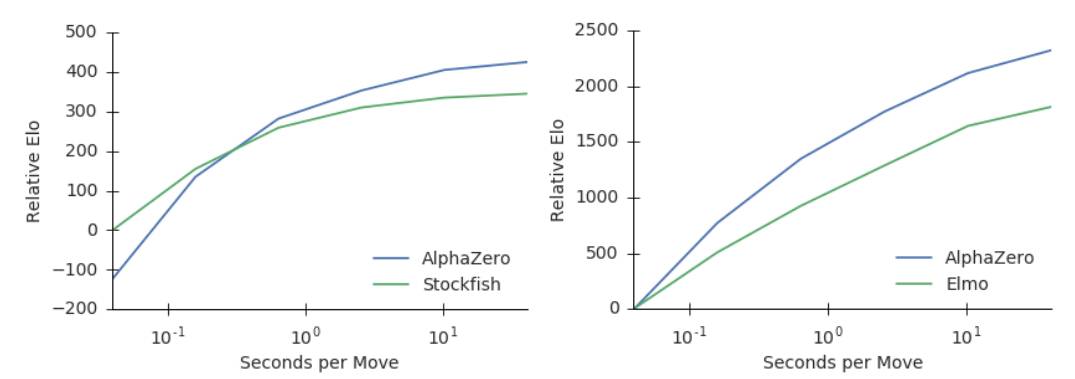
圖2:用每步棋的思考時(shí)間來(lái)衡量AlphaZero的可擴(kuò)展性,以Elo作為衡量標(biāo)準(zhǔn)。a. 在國(guó)際象棋中,AlphaZero和Stockfish的表現(xiàn),橫軸表示每步棋的思考時(shí)間。b. 在將棋中,AlphaZero和Elmo的表現(xiàn),橫軸表示每步棋的思考時(shí)間。
分析10萬(wàn)+人類開(kāi)局,AlphaZero確實(shí)掌握了國(guó)際象棋,alpha-beta搜索并非不可超越
最后,我們分析了AlphaZero發(fā)現(xiàn)的國(guó)際象棋知識(shí)。表2分析了人類最常用的開(kāi)局方式(在人類國(guó)際象棋游戲在線數(shù)據(jù)庫(kù)中玩過(guò)超過(guò)10萬(wàn)次的opening)。在自我訓(xùn)練期間,這些開(kāi)局方式被AlphaZero獨(dú)立地發(fā)現(xiàn)和對(duì)弈。以每個(gè)人類開(kāi)局方式為開(kāi)始,AlphaZero徹底擊敗Stockfish,表明它確實(shí)掌握了廣泛的國(guó)際象棋知識(shí)。

表2:對(duì)12種最受歡迎的人類的開(kāi)局(在一個(gè)在線數(shù)據(jù)庫(kù)的出現(xiàn)次數(shù)超過(guò)10萬(wàn)次)的分析。每個(gè)開(kāi)局都用ECO代碼和通用名稱標(biāo)記。這張圖顯示了自我對(duì)弈的比例,其中AlphaZero都是先手。
在過(guò)去的幾十年里,國(guó)際象棋代表了人工智能研究的頂峰。State-of-the-art的程序是建立在強(qiáng)大的engine的基礎(chǔ)上的,這些engine可以搜索數(shù)以百萬(wàn)計(jì)的位置,利用人工的特定領(lǐng)域的專業(yè)知識(shí)和復(fù)雜的領(lǐng)域適應(yīng)性。
AlphaZero是一種通用的強(qiáng)化學(xué)習(xí)算法,最初是為了圍棋而設(shè)計(jì)的,它在幾小時(shí)內(nèi)取得了優(yōu)異的成績(jī),搜索次數(shù)減少了1000倍,而且除了國(guó)際象棋的規(guī)則外,不需要任何領(lǐng)域知識(shí)。此外,同樣的算法在沒(méi)有修改的情況下,也適用于更有挑戰(zhàn)性的游戲,在幾小時(shí)內(nèi)再次超越了當(dāng)前最先進(jìn)的水平。
-
AI
+關(guān)注
關(guān)注
87文章
31158瀏覽量
269524 -
AlphaGo
+關(guān)注
關(guān)注
3文章
79瀏覽量
27789
原文標(biāo)題:【重磅】AlphaZero煉成最強(qiáng)通用棋類AI,DeepMind強(qiáng)化學(xué)習(xí)算法8小時(shí)完爆人類棋類游戲
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論