") 圖像識(shí)別的技術(shù)原理,會(huì)看沒那么簡單
圖像識(shí)別的技術(shù)原理,會(huì)看沒那么簡單
對(duì)人類來說,描述我們眼睛所看到的事物,即“視覺世界”,看起來太微不足道了,以至于我們根本沒有意識(shí)到那正是我們時(shí)時(shí)刻刻在做的事情。在看到某件事物時(shí),不管是汽車、大樹,還是一個(gè)人,我們通常都不需要過多的思考就能立刻叫出名字。然而對(duì)于一臺(tái)計(jì)算機(jī)來說,區(qū)分識(shí)別“人類對(duì)象”(比如:在小狗、椅子或是鬧鐘這些“非人類對(duì)象”中識(shí)別出奶奶這一“人類對(duì)象”)卻是相當(dāng)困難的。
能解決這一問題可以帶來非常高的收益。“圖像識(shí)別”技術(shù),更寬泛地說是“計(jì)算機(jī)視覺”技術(shù),是許多新興技術(shù)的基礎(chǔ)。從無人駕駛汽車和面部識(shí)別軟件到那些看似簡單但十分重要的發(fā)展成果——能夠監(jiān)測流水線缺陷和違規(guī)的“智能工廠”,以及保險(xiǎn)公司用來處理和分類索賠照片的自動(dòng)化軟件。這些新興科技是離不開“圖像識(shí)別”的。
在接下來的內(nèi)容里,我們將要探究“圖像識(shí)別”所面臨的問題和挑戰(zhàn),并分析科學(xué)家是如何用一種特殊的神經(jīng)網(wǎng)絡(luò)來解決這一挑戰(zhàn)的。
學(xué)會(huì)“看”是一項(xiàng)高難度、高成本的任務(wù)
著手解決這個(gè)難題,我們可以首先將元數(shù)據(jù)應(yīng)用于非結(jié)構(gòu)化數(shù)據(jù)。在之前的文章里,我們?cè)枋鲞^在元數(shù)據(jù)稀缺或元數(shù)據(jù)不存在的情況下,進(jìn)行文本內(nèi)容分類和搜索遇到的一些問題和挑戰(zhàn)。讓專人來對(duì)電影和音樂進(jìn)行人工分類和標(biāo)記,確實(shí)是一項(xiàng)艱巨的任務(wù)。但有些任務(wù)不僅艱巨,甚至是幾乎不可能完成的。比如訓(xùn)練無人駕駛汽車?yán)锏膶?dǎo)航系統(tǒng),讓其能夠?qū)⑵渌囕v與正在過馬路的行人區(qū)分開來;或者是每天對(duì)社交網(wǎng)站上用戶上傳的千千萬萬張的照片和視頻進(jìn)行標(biāo)記、分類和篩查。
唯一能夠解決這一難題的方法就是神經(jīng)網(wǎng)絡(luò)。理論上我們可以用常規(guī)的神經(jīng)網(wǎng)絡(luò)來進(jìn)行圖像分析,但在實(shí)際操作中,從計(jì)算角度看,使用這種方法的成本非常高。舉例來說,一個(gè)常規(guī)的神經(jīng)網(wǎng)絡(luò),就算是處理一個(gè)非常小的圖像,假設(shè)是30*30像素圖像,仍需要900個(gè)數(shù)據(jù)輸入和五十多萬個(gè)參數(shù)。這樣的處理加工對(duì)一個(gè)相對(duì)強(qiáng)大的機(jī)器來說還是可行的;但是,如果需要處理更大的圖像,假設(shè)是500*500像素的圖像,那么機(jī)器所需的數(shù)據(jù)輸入和參數(shù)數(shù)量就會(huì)大大增加,增加到難以想象的地步。
除此之外,將神經(jīng)網(wǎng)絡(luò)用于“圖像識(shí)別”還可能會(huì)導(dǎo)致另一個(gè)問題——過度擬合。簡單來說,過度擬合指的是系統(tǒng)訓(xùn)練的數(shù)據(jù)過于接近定制的數(shù)據(jù)模型的現(xiàn)象。這不僅會(huì)在大體上導(dǎo)致參數(shù)數(shù)量的增加(也就是進(jìn)一步計(jì)算支出的增加),還將削弱“圖像識(shí)別”在面臨新數(shù)據(jù)時(shí)其他常規(guī)功能的正常發(fā)揮。
真正的解決方案——卷積
幸運(yùn)的是,我們發(fā)現(xiàn),只要在神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)方式上做一個(gè)小小的改變,就能使大圖像的處理更具可操作性。改造后的神經(jīng)網(wǎng)絡(luò)被稱作“卷積神經(jīng)網(wǎng)絡(luò)”,也叫CNNs或ConvNets。
神經(jīng)網(wǎng)絡(luò)的優(yōu)勢之一在于它的普遍適應(yīng)性。但是,就像我們剛剛看到的,神經(jīng)網(wǎng)絡(luò)的這一優(yōu)勢在圖像處理上實(shí)際上是一種不利因素。而“卷積神經(jīng)網(wǎng)絡(luò)”能夠?qū)Υ俗鞒鲆环N有意識(shí)的權(quán)衡——為了得到一個(gè)更可行的解決方案,我們犧牲了神經(jīng)網(wǎng)絡(luò)的其他普遍性功能,設(shè)計(jì)出了一個(gè)專門用于圖像處理的網(wǎng)絡(luò)。
在任何一張圖像中,接近度與相似度的關(guān)聯(lián)性都是非常強(qiáng)的。準(zhǔn)確地說,“卷積神經(jīng)網(wǎng)絡(luò)”就是利用了這一原理。具體而言就是,在一張圖像中的兩個(gè)相鄰像素,比圖像中兩個(gè)分開的像素更具有關(guān)聯(lián)性。但是,在一個(gè)常規(guī)的神經(jīng)網(wǎng)絡(luò)中,每個(gè)像素都被連接到了單獨(dú)的神經(jīng)元。這樣一來,計(jì)算負(fù)擔(dān)自然加重了,而加重的計(jì)算負(fù)擔(dān)實(shí)際上是在削弱網(wǎng)絡(luò)的準(zhǔn)確程度。
卷積網(wǎng)絡(luò)通過削減許多不必要的連接來解決這一問題。運(yùn)用科技術(shù)語來說就是,“卷積網(wǎng)絡(luò)”按照關(guān)聯(lián)程度篩選不必要的連接,進(jìn)而使圖像處理過程在計(jì)算上更具有可操作性。“卷積網(wǎng)絡(luò)”有意地限制了連接,讓一個(gè)神經(jīng)元只接受來自之前圖層的小分段的輸入(假設(shè)是3×3或5×5像素),避免了過重的計(jì)算負(fù)擔(dān)。因此,每一個(gè)神經(jīng)元只需要負(fù)責(zé)處理圖像的一小部分(這與我們?nèi)祟惔竽X皮質(zhì)層的工作原理十分相似——大腦中的每一個(gè)神經(jīng)元只需要回應(yīng)整體視覺領(lǐng)域中的一小部分)。
“卷積神經(jīng)網(wǎng)絡(luò)”的內(nèi)在秘密
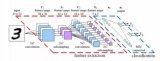
“卷積神經(jīng)網(wǎng)絡(luò)”究竟是如何篩選出不必要的連接的呢?秘密就在于兩個(gè)新添的新型圖層——卷積層和匯聚層。我們接下來將會(huì)通過一個(gè)實(shí)操案例:讓網(wǎng)絡(luò)判斷照片中是否有“奶奶”這一對(duì)象,把“卷積神經(jīng)網(wǎng)絡(luò)”的操作進(jìn)行分解,逐一描述。
第一步,“卷積層”。“卷積層”本身實(shí)際上也包含了幾個(gè)步驟:
1.首先,我們會(huì)將奶奶的照片分解成一些3×3像素的、重疊著的拼接圖塊。
2.然后,我們把每一個(gè)圖塊運(yùn)行于一個(gè)簡單的、單層的神經(jīng)網(wǎng)絡(luò),保持權(quán)衡不變。這一操作會(huì)使我們的拼接圖塊變成一個(gè)圖組。由于我們一開始就將原始圖像分解成了小的圖像(在這個(gè)案例中,我們是將其分解成了3×3像素的圖像),所以,用于圖像處理的神經(jīng)網(wǎng)絡(luò)也是比較好操作的。
3.接下來,我們將會(huì)把這些輸出值排列在圖組中,用數(shù)字表示照片中各個(gè)區(qū)域的內(nèi)容,數(shù)軸分別代表高度、寬度和顏色。那么,我們就得到了每一個(gè)圖塊的三維數(shù)值表達(dá)。(如果我們討論的不是奶奶的照片,而是視頻,那么我們就會(huì)得到一個(gè)四維的數(shù)值表達(dá)了。)
說完“卷積層”,下一步是“匯聚層”。
“匯聚層”是將這個(gè)三維(或是四維)圖組的空間維度與采樣函數(shù)結(jié)合起來,輸出一個(gè)僅包含了圖像中相對(duì)重要的部分的聯(lián)合數(shù)組。這一聯(lián)合數(shù)組不僅能使計(jì)算負(fù)擔(dān)最小化,還能有效避免過度擬合的問題。
最后,我們會(huì)把從“匯聚層”中得出的采樣數(shù)組作為常規(guī)的、全方位連接的神經(jīng)網(wǎng)絡(luò)來使用。通過卷積和匯聚,我們大幅度地縮減了輸入的數(shù)量,因此,我們這時(shí)候得到的數(shù)組大小是一個(gè)正常普通網(wǎng)絡(luò)完全能夠處理的,不僅如此,這一數(shù)組還能保留原始數(shù)據(jù)中最重要的部分。這最后一步的輸出結(jié)果將最終顯示出系統(tǒng)有多少把握作出“照片中有奶奶”的判斷。
以上只是對(duì)“卷積神經(jīng)網(wǎng)絡(luò)”工作過程的簡單描述,現(xiàn)實(shí)中,其工作過程是更加復(fù)雜的。另外,跟我們這里的案例不同,現(xiàn)實(shí)中的“卷積神經(jīng)網(wǎng)絡(luò)”處理的內(nèi)容一般包含了上百個(gè),甚至上千個(gè)標(biāo)簽。
“卷積神經(jīng)網(wǎng)絡(luò)”的實(shí)施
重新開始建立一個(gè)“卷積神經(jīng)網(wǎng)絡(luò)”是一項(xiàng)非常耗時(shí)且昂貴的工作。不過,許多API最近已經(jīng)實(shí)現(xiàn)了——讓組織在沒有內(nèi)部計(jì)算機(jī)視覺或機(jī)器學(xué)習(xí)專家的幫助下,完成圖像分析的收集工作。
“谷歌云視覺”是谷歌的視覺識(shí)別API,它是以開源式TensorFlow框架為基礎(chǔ)的,采用了一個(gè)REST API。“谷歌云視覺”包含了一組相當(dāng)全面的標(biāo)簽,能夠檢測單個(gè)的對(duì)象和人臉。除此之外,它還具備一些附加功能,包括OCR和“谷歌圖像搜索”。
“IBM沃森視覺識(shí)別”技術(shù)是“沃森云開發(fā)者”的重要組成部分。它雖然涵蓋了大量的內(nèi)置類集,但實(shí)際上,它是根據(jù)你所提供的圖像來進(jìn)行定制類集的訓(xùn)練的。與“谷歌云視覺”一樣,“IBM沃森視覺識(shí)別”也具備許多極好的功能,比如OCR和NSFW檢測功能。
Clarif.ai是圖像識(shí)別服務(wù)的“后起之秀”,它采用了一個(gè)REST API。值得一提的是,Clarif.ai包含了大量的單元,能夠根據(jù)特定的情境定制不同的算法。像婚禮、旅游甚至食物。
上面的這些API更適用于一些普通的程序,但對(duì)于一些特殊的任務(wù),可能還是需要“對(duì)癥下藥”,制定專門的解決方案。不過值得慶幸的是,許多數(shù)據(jù)庫可以處理計(jì)算和優(yōu)化方面的工作,這或多或少地減輕了數(shù)據(jù)科學(xué)家和開發(fā)人員的壓力,讓他們有更多精力關(guān)注于模型訓(xùn)練。其中,大部分的數(shù)據(jù)庫,包括TensorFlow,深度學(xué)習(xí)4J和Theano,都已經(jīng)得到了廣泛、成功的應(yīng)用。
-
圖像識(shí)別
+關(guān)注
關(guān)注
9文章
520瀏覽量
38291
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于DSP的快速紙幣圖像識(shí)別技術(shù)研究
如何構(gòu)建基于圖像識(shí)別的印制線路板精密測試系統(tǒng)?
對(duì)于圖像識(shí)別的引入、原理、過程、應(yīng)用前景的深度剖析
簡單介紹圖像識(shí)別技術(shù)在各類行業(yè)的應(yīng)用
圖像識(shí)別技術(shù) 推動(dòng)智能科技時(shí)代發(fā)展
使用FPGA平臺(tái)實(shí)現(xiàn)遺傳算法的圖像識(shí)別的研究設(shè)計(jì)說明

卷積神經(jīng)網(wǎng)絡(luò)用于圖像識(shí)別的原理





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論