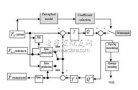
 多層感知機模型結構
多層感知機模型結構
多層感知機(MLP,Multilayer Perceptron)是一種基本且廣泛應用的人工神經網絡模型,其結構由多個層次組成,包括輸入層、一個或多個隱藏層以及輸出層。MLP以其強大的非線性映射能力和靈活的結構設計,在分類、回歸、模式識別等多個領域展現出卓越的性能。以下是對多層感知機模型結構的詳細闡述。
一、基本組成
1. 輸入層(Input Layer)
輸入層是MLP的第一層,負責接收外部輸入數據。輸入層中的神經元數量通常與輸入數據的特征維度相對應。例如,在圖像識別任務中,輸入層可能包含與圖像像素數量相等的神經元;在文本分類任務中,則可能根據詞嵌入的維度來確定輸入層神經元數量。輸入層的主要作用是將原始數據傳遞給后續的隱藏層進行處理。
2. 隱藏層(Hidden Layer)
隱藏層是MLP中位于輸入層和輸出層之間的層次,負責提取輸入數據的潛在特征并進行非線性變換。MLP可以包含一個或多個隱藏層,每個隱藏層由多個神經元組成。隱藏層中的神經元通過加權連接接收來自前一層神經元的輸出作為輸入,并產生自己的輸出作為下一層神經元的輸入。隱藏層的數量和每層神經元的數量是MLP設計中的重要參數,它們決定了網絡的復雜度和學習能力。
3. 輸出層(Output Layer)
輸出層是MLP的最后一層,負責產生最終的預測結果。輸出層神經元的數量通常與任務的目標數量相對應。例如,在二分類任務中,輸出層可能包含一個神經元,其輸出值表示屬于某個類別的概率;在多分類任務中,則可能包含與類別數量相等的神經元,每個神經元的輸出值表示屬于對應類別的概率。輸出層通常使用softmax函數等激活函數來將神經元的輸出轉換為概率分布形式。
二、神經元與連接
1. 神經元結構
MLP中的每個神經元都是一個基本的處理單元,它接收來自前一層神經元的加權輸入,并通過激活函數產生輸出。神經元的結構通常包括線性變換部分和激活函數部分。線性變換部分通過加權求和的方式計算輸入信號的加權和;激活函數部分則用于引入非線性因素,使得神經元能夠處理復雜的非線性關系。
2. 連接方式
MLP中的神經元之間通過加權連接相互連接。每個連接都有一個權重值,用于表示該連接對神經元輸出的影響程度。在訓練過程中,這些權重值會根據反向傳播算法進行更新,以最小化預測輸出與真實輸出之間的誤差。除了權重連接外,每個神經元還有一個偏置項(bias),用于調整神經元的激活閾值。
三、激活函數
激活函數是MLP中非常重要的組成部分,它用于引入非線性因素,使得神經網絡能夠處理復雜的非線性關系。常見的激活函數包括sigmoid函數、tanh函數和ReLU函數等。這些函數具有不同的特性和應用場景,可以根據具體任務的需求進行選擇。
- Sigmoid函數 :將輸入值映射到(0,1)區間內,適用于二分類任務的輸出層。然而,由于其梯度消失的問題,在深度神經網絡中較少使用。
- Tanh函數 :將輸入值映射到(-1,1)區間內,具有比sigmoid函數更好的梯度特性,因此在隱藏層中較為常用。
- ReLU函數 (Rectified Linear Unit):是當前深度學習中最為常用的激活函數之一。它對于所有正輸入值都輸出其本身,對于負輸入值則輸出0。ReLU函數具有計算簡單、梯度不會消失等優點,在深度神經網絡中表現出色。
四、訓練過程
MLP的訓練過程通常包括前向傳播和反向傳播兩個階段。
- 前向傳播 :在前向傳播階段,輸入數據從輸入層經過隱藏層逐層傳遞到輸出層,每一層的神經元根據當前權重和偏置計算輸出值。最終,輸出層產生預測結果。
- 反向傳播 :在反向傳播階段,根據預測結果與真實結果之間的誤差,通過反向傳播算法逐層更新權重和偏置。反向傳播算法基于鏈式法則計算誤差關于每個權重和偏置的梯度,并使用優化算法(如隨機梯度下降SGD、Adam等)來更新這些參數。通過不斷迭代前向傳播和反向傳播過程,MLP能夠逐漸學習到輸入數據與輸出之間的映射關系。
五、模型設計與優化
1. 模型設計
MLP的模型設計包括確定隱藏層的數量、每層神經元的數量以及激活函數等。這些設計參數的選擇對模型的性能有重要影響。一般來說,增加隱藏層的數量和每層神經元的數量可以提高模型的復雜度和學習能力,但也可能導致過擬合和計算量增加的問題。因此,在實際應用中需要根據具體任務和數據集的特點進行權衡和選擇。
2. 模型優化
為了提高MLP的性能和泛化能力,通常會采用一系列優化策略和技術。以下是一些關鍵的模型優化方法:
3. 正則化
正則化是防止過擬合的有效手段之一。在MLP中,常用的正則化方法包括L1正則化、L2正則化(也稱為權重衰減)以及Dropout。
- L1正則化和L2正則化 :通過在損失函數中添加權重的絕對值(L1)或平方(L2)作為懲罰項,來限制模型的復雜度。L1正則化有助于產生稀疏權重矩陣,而L2正則化則傾向于產生較小的權重值,兩者都能在一定程度上減少過擬合。
- Dropout :在訓練過程中,隨機丟棄(即設置為0)神經網絡中的一部分神經元及其連接。這種方法可以看作是對多個小型網絡進行訓練,并取它們的平均結果,從而有效減少過擬合,提高模型的泛化能力。
4. 學習率調整
學習率是優化算法中一個重要的超參數,它決定了權重更新的步長。過大的學習率可能導致訓練過程不穩定,甚至無法收斂;而過小的學習率則會使訓練過程過于緩慢。因此,在訓練過程中動態調整學習率是非常必要的。常見的學習率調整策略包括學習率衰減、學習率預熱(warmup)以及使用自適應學習率算法(如Adam、RMSprop等)。
5. 批量大小與批標準化
- 批量大小 :批量大小(batch size)是指每次迭代中用于更新權重的樣本數量。較大的批量大小可以提高內存利用率和并行計算效率,但可能降低模型的泛化能力;較小的批量大小則有助于更快地收斂到更好的局部最優解,但訓練過程可能更加不穩定。選擇合適的批量大小是平衡訓練速度和性能的關鍵。
- 批標準化 :批標準化(Batch Normalization, BN)是一種通過規范化每一層神經元的輸入來加速訓練的技術。它可以減少內部協變量偏移(Internal Covariate Shift)問題,使得模型訓練更加穩定,同時也有助于提高模型的泛化能力。
6. 初始化策略
權重的初始值對神經網絡的訓練過程和最終性能有很大影響。良好的初始化策略可以幫助模型更快地收斂到全局最優解。在MLP中,常用的初始化方法包括隨機初始化(如均勻分布或正態分布初始化)、Xavier/Glorot初始化和He初始化等。這些方法旨在保持輸入和輸出的方差一致,從而避免梯度消失或爆炸的問題。
7. 早停法
早停法(Early Stopping)是一種簡單而有效的防止過擬合的方法。在訓練過程中,除了使用驗證集來評估模型性能外,還可以設置一個“早停”條件。當模型在驗證集上的性能開始下降時(即出現過擬合的跡象),立即停止訓練,并返回在驗證集上表現最好的模型參數。這種方法可以有效地避免在訓練集上過擬合,同時保留模型在未知數據上的泛化能力。
六、應用場景與挑戰
MLP作為一種通用的神經網絡模型,具有廣泛的應用場景,包括但不限于分類、回歸、聚類、降維等任務。然而,隨著深度學習技術的不斷發展,MLP也面臨著一些挑戰和限制:
- 計算資源消耗大 :尤其是在處理大規模數據集和高維特征時,MLP的訓練和推理過程需要消耗大量的計算資源和時間。
- 難以捕捉局部特征 :與卷積神經網絡(CNN)等專門設計的網絡結構相比,MLP在處理具有局部結構特征的數據(如圖像、音頻等)時可能表現不佳。
- 超參數調整復雜 :MLP的性能很大程度上取決于其結構設計和超參數的選擇。然而,這些超參數的調整往往依賴于經驗和試錯法,缺乏系統性的指導原則。
盡管如此,MLP作為深度學習領域的基礎模型之一,其簡單性和靈活性仍然使其在許多實際應用中發揮著重要作用。隨著技術的不斷進步和算法的不斷優化,相信MLP的性能和應用范圍將會得到進一步的提升和拓展。
-
人工神經網絡
+關注
關注
1文章
120瀏覽量
14644 -
模型
+關注
關注
1文章
3262瀏覽量
48916 -
神經元
+關注
關注
1文章
363瀏覽量
18470
發布評論請先 登錄
相關推薦
基于結構化平均感知機的分詞器Java實現
分詞工具Hanlp基于感知機的中文分詞框架
如何使用Keras框架搭建一個小型的神經網絡多層感知器
Watson感知模型分析
人工智能–多層感知器基礎知識解讀
一個結合監督學習的多層感知機模型
解讀CV架構回歸多層感知機;自動生成模型動畫

基于結構感知的雙編碼器解碼器模型
多層感知機(MLP)的設計與實現





 工商網監
工商網監
評論