 智源研究院揭曉大模型測評結果,豆包與百川智能大模型表現優異
智源研究院揭曉大模型測評結果,豆包與百川智能大模型表現優異
5月18日,北京智源研究院發布了關于國內外各類開/閉源語言及多模態大模型性能評估的最新研究成果。此項研究覆蓋了140余個語言模型的綜合實力對比,包括其對中文文本理解和多模態圖文問答等任務的處理能力。
研究發現,盡管國內頭部語言模型在中文環境中的整體表現已接近國際一流水平,但仍存在能力發展不平衡的問題。
在多模態理解圖文問答任務中,開源和閉源模型表現相當,而國產模型則表現出色。此外,在中文語境下的文生圖能力方面,國產多模態模型與國際一流水平的差距相對較小。
具體到語言模型的排名,在中文語境下,字節跳動的豆包Skylark2以及OpenAI的GPT-4分別名列第一和第二。值得注意的是,國產大模型在理解中國用戶需求方面具有明顯優勢。
在語言模型客觀評價中,OpenAI的GPT-4和百川智能的Baichuan3分列第一和第二。同時,百度的文心一言4.0、智譜華章的GLM-4以及月之暗面的Kimi也躋身語言模型主客觀評價的前五名。
在多模態理解模型的客觀評價中,圖文問答方面,阿里巴巴的通義Qwen-vl-max和上海人工智能實驗室的InternVL-Chat-V1.5在某些指標上超越了OpenAI的GPT-4,LLaVA-Next-Yi-34B和上海人工智能實驗室的Intern-XComposer2-VL-7B緊隨其后。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
開源
+關注
關注
3文章
3358瀏覽量
42516 -
模型
+關注
關注
1文章
3248瀏覽量
48860 -
大模型
+關注
關注
2文章
2465瀏覽量
2752
發布評論請先 登錄
相關推薦
浪潮信息與智源研究院攜手共建大模型多元算力生態
近日,浪潮信息與北京智源人工智能研究院正式簽署戰略合作協議,雙方將緊密合作,共同構建大模型多元算力開源創新生態。 此次合作旨在提升大模型創新
浪潮信息與智源研究院達成戰略合作協議
近日,浪潮信息與智源研究院達成戰略合作協議,雙方將緊密協作共建大模型多元算力開源創新生態,提升大模型創新研發的算力效率,降低大模型應用開發的
百川智能發布Baichuan4-Finance金融大模型
近日,百川智能正式推出了其全鏈路領域增強的金融大模型——Baichuan4-Finance。這一創新產品的發布,標志著百川智能在金融
百川智能發布一站式大模型商業化解決方案
近日,百川智能正式推出了一站式大模型商業化解決方案,旨在為企業提供更加全面、高效的大模型應用服務。該解決方案以1+3產品矩陣為核心,包括全鏈路優質通用訓練數據、Baichuan4-Tu
【附實操視頻】聆思CSK6大模型開發板接入國內主流大模型(星火大模型、文心一言、豆包、kimi、智譜glm、通義千問)
輸出的結果進行語音合成實現端側播報。
目前已經接通文心一言、豆包、kimi、智譜glm、通義千問等國內主流大模型,詳細模板和操作步驟可以參考附件文檔。
發表于 08-22 10:12
智能硬件接入主流大模型做語音交互(附文心一言、豆包、kimi、智譜glm、通義千問示例)
本帖最后由 jf_40317719 于 2024-8-21 19:17 編輯
多模態交互離不開硬件載體,近期有不少開發者在研究聆思CSK6大模型開發板除了使用出廠示例自帶的星火大模型,能不能
發表于 08-21 19:13
摩爾線程攜手智源研究院完成基于Triton的大模型算子庫適配
近日,摩爾線程與北京智源人工智能研究院(簡稱:智源研究院)已順利完成基于Triton語言的高性能算子庫FlagGems的適配工作。得益于摩爾
大模型廠商“輸血”不斷,百川智能完成50億元A輪融資!
有重磅消息曝出:知名大模型公司百川智能已經成功收獲了價值50億元的A輪融資。由此,我們不禁感嘆,大模型廠商們的“輸血”和“續命”之戰,還在激烈的上演著。
百川智能完成50億元A輪融資
近日,國內領先的醫療AI大模型企業——百川智能,正式宣布完成了高達50億元人民幣的A輪融資,這一里程碑式的融資不僅彰顯了市場對其技術實力與未來發展潛力的高度認可,也為公司的后續發展奠定了堅實的資金基礎。
亞馬遜云科技接入百川智能和零一萬物基礎模型
近日,亞馬遜云科技在中國峰會上宣布,兩大中文基礎模型——百川智能的Baichuan2-7B和零一萬物的Yi-1.5 6B/9B/34B,即將或已正式登陸中國區域的SageMaker JumpStart。這一舉措為中國企業提供了豐
百川智能發布Baichuan 4大模型及首款AI助手“百小應”
百川智能近日發布了其新一代基座大模型Baichuan 4,并同步推出了首款AI助手“百小應”。這款AI助手是在Baichuan 4強大能力的基礎上,結合先進的搜索技術精心打造而成。
百川智能與北京大學將共建通用人工智能聯合實驗室
近日,百川智能與北京大學攜手合作,共同簽署了“北大——百川通用人工智能聯合實驗室”的共建協議,標志著雙方在人工智能領域邁出了堅實的合作步伐。
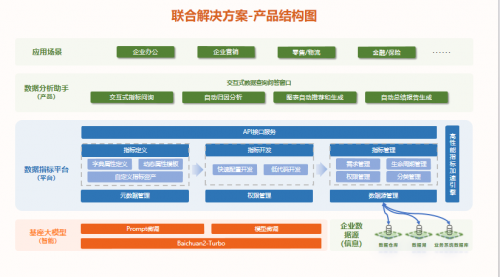
數勢聯動百川,發布首批大模型聯合解決方案,推動中國大模型價值落地
近日,行業領先的數據智能產品提供商北京數勢云創科技有限公司(以下簡稱“數勢科技”)和國內通用大模型廠商北京百川智能科技有限公司(以下簡稱“百川
百川智能發布超千億大模型Baichuan 3
百川智能近日發布了超千億參數的大語言模型Baichuan 3,引發了業界的廣泛關注。這款模型在多個權威通用能力評測中表現卓越,展現了其強大的





 工商網監
工商網監
評論