 如何通過優化RTL減少功耗
如何通過優化RTL減少功耗
隨著各種消費類設備智能化的巨大增長,這些應用正變得更加以數據為中心data-centric和計算密集型computation intensive。從IC設計的角度來看,這增強了早已經存在的power vs area trade-off的挑戰。
對于功耗估算來說,架構階段為時過早,物理設計階段為時已晚。有一種趨勢是在項目的RTL階段分析power hot spots。與后期分析相比,基于 RTL 的功耗分析更快、更容易執行,迭代時間更短。
本文介紹了在 RTL 級別應用的一些功耗優化技術。
消費類電器(電池驅動型)的大幅增加使功耗優化成為大多數片上系統 (SoC) 的基本需求。
在VLSI行業的早期階段,功耗分析被認為是一種后端活動。但隨著芯片復雜性的增加,必須將功耗分析轉移到前端階段,以確保正確的估計和優化,僅在后端階段進行優化就無法滿足要求。
此外,動態功耗計算很大程度上取決于驅動到 SoC 的輸入激勵;因此,使用功能驗證向量輸入進行分析似乎是必須的。因此,業界開始在 RTL 階段進行功耗分析。
在ASIC設計的不同階段,都有功耗優化的余地。
系統劃分為電壓域是在架構階段完成的,即使在單個電壓域下也能進行優化。當處理器處于休眠模式時,對電路進行Power gating(喚醒邏輯除外)可減少功耗浪費。這些是用于降低功耗的一些傳統方法。在多核處理器設計中,多個電壓域允許根據工作負載控制每個內核的電源電壓。在較高電壓下工作的核以較高的頻率工作,而施加較低電壓的核可以使用較低的頻率。
內存組織和模塊級時鐘門控則是架構級優化的另一個領域。
綜合階段的功耗降低歸因于晶體管尺寸調整和cell合并,以降低開關活動。另一種方法是將高開關活動的net分配給電容較低的引腳,將低開關活動的net分配給具有較高電容的邏輯引腳。綜合工具還通過將數據使能轉換為時鐘使能來實現時鐘門控。通過具有不同閾值電壓的cell映射設計中的非關鍵路徑和關鍵路徑來優化漏電功耗。
RTL level的功耗優化主要集中在降低register level的信號活動上。本文主要介紹 RTL 優化,它從更精細的級別實現功耗的優化控制。
II. 低功耗RTL
通常,實現 RTL 功耗優化包括對設計的以下方面進行優化。
寄存器級時鐘門控減少開關活動
基于有限狀態機(FSM)的上游和下游邏輯路徑門控
數據路徑未啟用時對數據路徑進行門控
減少組合電路中的冗余活動
本節介紹一些優化技術,方案和編碼示例。
A. 時鐘門控
在模塊級別插入Clock gate是一種普遍的降低功耗的方法。但是,只有在功耗需求非常嚴格的情況下,才采用寄存器級的Clock gate,這是由于寄存器級的Clock gate也會增加面積成本。
為了在寄存器級別啟用Clockgate,對于RTL的編寫方式是有一定的要求的。另一種選擇是手動配置綜合工具,為選定的寄存器插入Clockgate。在復雜的設計中,第二種選擇是不可行的。在這種情況下,應該利用RTL 的編寫方式自動綜合出Clockgate。
考慮場景,當 FIFO 滿并寫入時,生成 fifo wr 錯誤信號。示例代碼1不會綜合出Clock gate,而示例代碼2會綜合出Clock gate。
Listing 1. Code without CG Inference
always @(posedge clk or negedge reset) if (reset = 0) fifo_wr_err <= 0 else fifo_wr_err <= fifo_full & fifo_wr_en ;
Listing 2. Code with CG Insertion
always @(posedge clk or negedge reset) if (reset = 0) fifo_wr_err <= 0 else if (fifo_wr_en) fifo_wr_err <= fifo_full;
1) 時鐘門控效率:在不研究時鐘門控效率的情況下插入Clockgate也可能會反方向增加功耗。需要根據以下因素估計時鐘門控效率
總線中被時鐘門控的比特數
門控占總時鐘周期的百分比
數據在使能的Clockgate內toggle
僅當寄存器上的輸入發生變化時才啟用該門控。
Listing 3. Improved Clock Gating Efficiency
always @(posedge clk or negedge reset) if (reset = 0) fifo_wr_err <= 0 else if (value_en) fifo_wr_err <= nxt_fifo_wr_err; assign nxt_fifo_wr_err = fifo_full & fifo_wr_en; assign value_en = fifo_wr_err ? nxt_fifo_wr_err;
2) Clock Gating TradeOff:當我們努力實現 100% 的時鐘門控效率時,系統的面積將會增加。為了避免這種情況,我們可以TradeOff。在這里,我們組合了多個寄存器的使能,允許觸發器輸入處會有些冗余切換。這種TradeOff的默認值的建議是 3-4,這意味著在 3-4 個寄存器之間共享一個公共enable,但代價是Clock Gating效率降低。
寫入錯誤和讀取錯誤生成enable可以組合使用,以降低面積成本。
Listing 5. Combined Clock Gating Example 2
always @(posedge clk or negedge reset) if (reset = 0) fifo_wr_err <= 0 else if (fifo_en) fifo_wr_err <= nxt_fifo_wr_err; always @(posedge clk or negedge reset) if (reset = 0) fifo_rd_err <= 0 else if (fifo_en) fifo_rd_err <= nxt_fifo_rd_err; assign nxt_fifo_wr_err = fifo_full & fifo_wr_en; assign nxt_fifo_rd_err = fifo_empty & fifo_rd_en; assign fifo_en = fifo_wr_en | fifo_rd_en;
B. 基于FSM的控制
基于FSM狀態生成的信號可用于對發送和接收的所有邏輯進行門控。
Listing 6. Enable Generation based on FSM
assign transmit_cg_en = ?state_tx[IDLE]; assign receive_cg_en = ?state_rx[IDLE];
C. 數據路徑運算
數據路徑運算模塊(如乘法器)可能會在輸入端進行不必要的toggle,即使未啟用相應的計算。因此,以下技術可降低功耗。
時鐘門控為數據路徑操作提供輸入的時序邏輯
在輸入端使用鎖存器或者使用使能門控輸入
Listing 7. Gating Data Operator Input Toggling Method1
always @(posedge clk or negedge reset) if (reset = 0) begin mul_in1 <= 0 mul_in2 <= 0 end else if (mul_en) begin mul_in1 <= nxt_mul_in1; mul_in2 <= nxt_mul_in2; end
Listing 8. Gating Data Operator Input Method 2
assign mul_in1 = data_in1 &
{DATA_WIDTH{mul_en}};
assign mul_in2 = data_in2 &
{DATA_WIDTH{mul_en}};
D. 減少組合邏輯的toggle
組合邏輯的功耗可以通過避免不必要的輸入toggle來控制。這里可以考慮一個多路復用器作為示例,它是組合邏輯的常見模塊。
在下圖給出的示例電路中,我們有一個由兩個packetizers訪問的共享數據存儲器。在這里,我們確實有明顯的功耗浪費,因為當packetizer1 訪問數據時,packetizer2 的輸入將切換toggle,反之亦然。
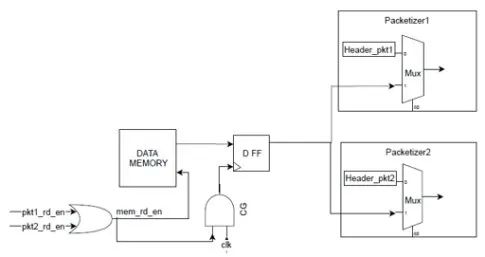
功耗更優化的設計將把輸入門控到packetizer中的 MUX。
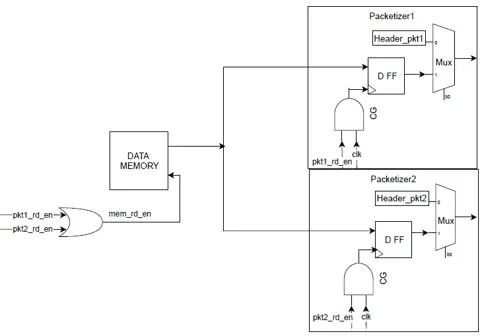
如果我們能把內存拆分成幾個部分,我們就可以進行更細粒度的gate,從而產生更有效的門控效率。但缺點是routing congestion和面積成本。
三、RTL功耗分析工具
ASIC 設計流程正在使用 RTL 分析工具在早期階段考慮分析功耗。
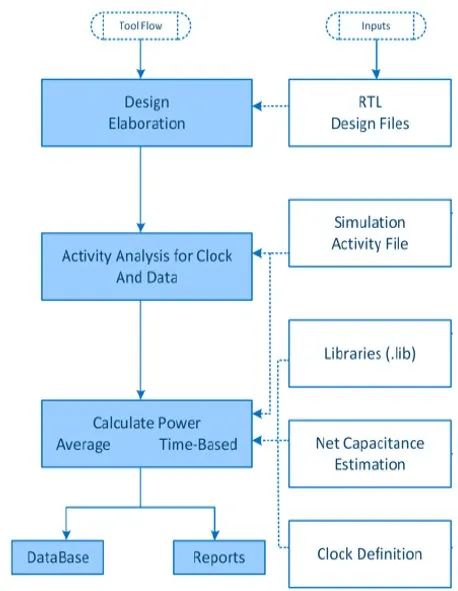
RTL設計文件使用VCD、SAIF或FSDB格式的仿真激勵文件,針對時鐘和數據toggle產生的功耗進行精心設計和分析。
審核編輯:黃飛
-
寄存器
+關注
關注
31文章
5336瀏覽量
120230 -
IC設計
+關注
關注
38文章
1295瀏覽量
103918 -
soc
+關注
關注
38文章
4161瀏覽量
218160 -
片上系統
+關注
關注
0文章
186瀏覽量
26807
原文標題:通過優化RTL減少功耗
文章出處:【微信號:數字芯片實驗室,微信公眾號:數字芯片實驗室】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
射頻識別芯片設計中時鐘樹功耗的優化與實現
優化 FPGA HLS 設計
為什么要優化FPGA功耗?
怎樣通過軟件控制的方式來優化并降低單片機的功耗?
RTL功耗優化
用Elaborated Design優化RTL的代碼
如何降低面積和功耗?如何優化電路時序?






 工商網監
工商網監
評論