

作者:潘梓正,莫納什大學博士生
最近看到有些問題[1]說為什么Transformer中的FFN一直沒有大的改動。21年剛入學做ViT的時候就想這個問題,現在讀博生涯也快結束了,剛好看到這個問題,打算稍微寫寫, 也算是對這個地方做一個小總結吧。
1. Transformer與FFN
Transformer的基本單位就是一層block這里,一個block包含 MSA + FFN,目前公認的說法是,
?Attention作為token-mixer做spatial interaction。
?FFN(又稱MLP)在后面作為channel-mixer進一步增強representation。
從2017至今,過去絕大部分Transformer優化,尤其是針對NLP tasks的Efficient Transformer都是在Attention上的,因為文本有顯著的long sequence問題。安利一個很好的總結Efficient Transformers: A Survey [2], 來自大佬Yi Tay[3]。到了ViT上又有一堆attention[4]改進,這個repo一直在更新,總結的有點多,可以當輔助資料查閱。
而FFN這里,自從Transformer提出基本就是一個 Linear Proj + Activation + Linear Proj的結構,整體改動十分incremental。
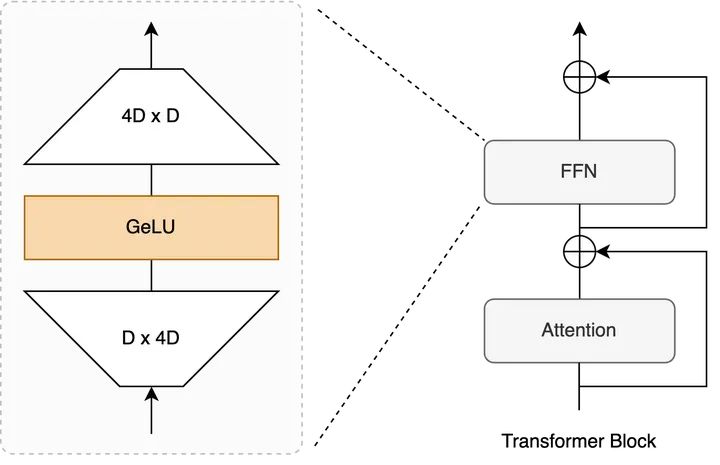
Transformer Block示意圖 + FFN內部
2. Activation Function
經歷了ReLU, GeLU,Swish, SwiGLU等等,基本都是empirical observations,但都是為了給representation加上非線性變換做增強。
?ReLU對pruning挺有幫助,尤其是過去對CNN做pruning的工作,激活值為0大致意味著某個channel不重要,可以去掉。相關工作可查這個repo[5]。即便如此,ReLU造成dead neurons,因此在Transformer上逐漸被拋棄。
?GeLU在過去一段時間占比相當大,直到現在ViT上使用十分廣泛,當然也有用Swish的,如MobileViT[6]。
?Gated Linear Units目前在LLM上非常流行,其效果和分析來源于GLU Variants Improve Transformer[7]。如PaLM和LLaMA都采用了SwiGLU, 谷歌的Gemma使用GeGLU。
不過,從個人經驗上來看(偏CV),改變FFN中間的activation function,基本不會有極大的性能差距,總體的性能提升會顯得incremental。NLP上估計會幫助reduce overfitting, improve generalization,但是與其花時間改這個地方不如好好clean data。。。目前來說
3. Linear Projections
說白了就是一個matrix multiplication, 已經幾乎是GPU上的大部分人改model的時候遇到的最小基本單位。dense matrix multiplication的加速很難,目前基本靠GPU更新迭代。
不過有一個例外:小矩陣乘法可以結合軟硬件同時加速,比如instant-ngp的tiny cuda nn, 64 x 64這種級別的matrix multiplication可以使得網絡權重直接放到register, 激活值放到shared memory, 這樣運算極快。
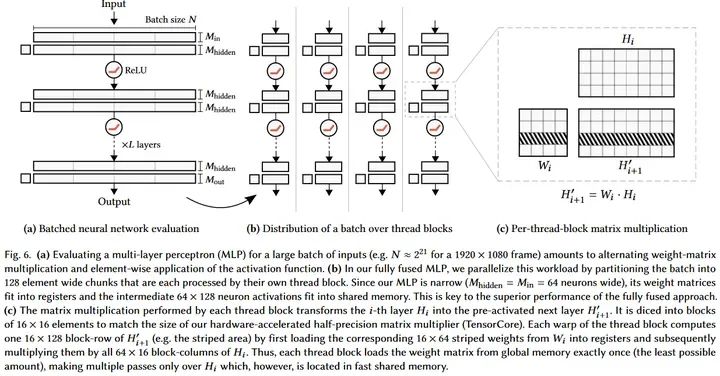
Source: https://github.com/nvlabs/tiny-cuda-nn
但是這對今天的LLM和ViT來講不現實,最小的ViT-Tiny中,FFN也是個192 x (4 x 192)這種級別,更不用說LLM這種能> 10000的。
那為什么Linear Projection在Transformer里就需要這么大?
常見的說法是Knowledge Neurons。tokens在前一層attention做global interaction之后,通過FFN的參數中存放著大量training過程中學習到的比較抽象的knowledge來進一步update。目前有些studies是說明這件事的,如
?Transformer Feed-Forward Layers Are Key-Value Memories[8]
?Knowledge Neurons in Pretrained Transformers[9]
?...
問題來了,如果FFN存儲著Transformer的knowledge,那么注定了這個地方不好做壓縮加速:
?FFN變小意味著model capacity也變小,大概率會讓整體performance變得很差。我自己也有過一些ViT上的實驗 (相信其他人也做過),兩個FC中間會有個hidden dimension的expansion ratio,一般設置為4。把這個地方調小會發現怎么都不如大點好。當然太大也不行,因為FFN這里的expansion ratio決定了整個Transformer 在推理時的peak memory consumption,有可能造成out-of-memory (OOM) error,所以大部分我們看到的expansion ration也就在4倍,一個比較合適的performance-memory trade-off.
?FFN中的activations非低秩。過去convnet上大家又發現activations有明顯的低秩特性,所以可以通過low rank做加速,如Kaiming的這篇文章[10],如下圖所示。但是FFN中間的outputs很難看出低秩的特性,實際做網絡壓縮的時候會發現pruning FFN的trade-off明顯不如convnets,而unstructured pruning又對硬件不友好。
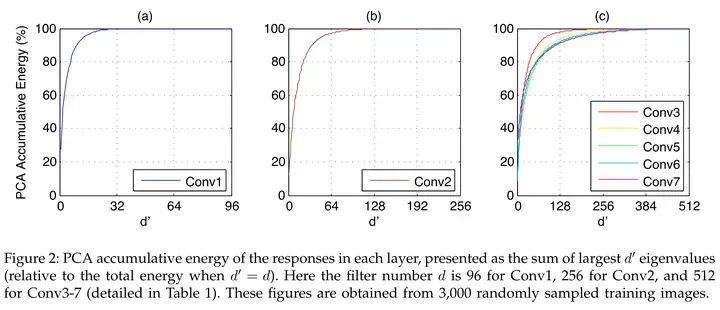
Source: Zhang et.al, Accelerating Very Deep Convolutional Networks for Classification and Detection
4. 所以FFN真的改不動了嗎?
當然不是。
我們想改動一個model or module的時候,無非是兩個動機:1)Performance。2)Efficiency。
性能上,目前在NLP上可以做Gated MLP[11], 如Mamba[12]的block中,或者DeepMind的新結構Griffin[13]。
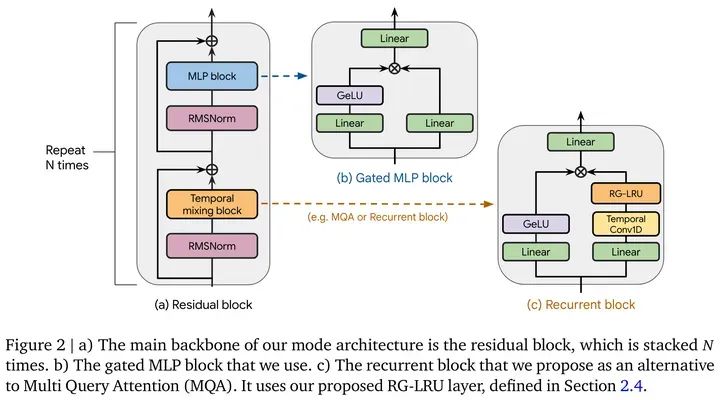
Source: Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
但是難說這個地方的性能提升是不是來自于更多的參數量和模型復雜度。
在CV上,有個心照不宣的trick,那就是加depthwise convolution引入locality,試過的朋友都知道這個地方的提升在CV任務上有多明顯,例如CIFAR100上,DeiT-Ti可以漲接近10個點這樣子。。。
但是呢,鑒于最原始的FFN依然是目前采用最廣泛的,并且conv引入了inductive bias,破壞了原先permutation invariant的sequence(因為卷積要求規整的shape,width x height)。大規模ViT訓練依然沒有采用depthwise conv,如CLIP, DINOv2, SAM, etc。
效率上,目前最promising是改成 **Mixture-of-Expert (MoE)**,但其實。。。GPT4和Mixtral 8x7B沒出來之前基本是Google在solo,沒人關注。當然現在時代變了,Mixtral 8x7B讓MoE起死回生。最近這個地方的paper相當多,簡單列幾個自己感興趣的:
?Soft MoE: From Sparse to Soft Mixtures of Experts[14]
?LoRA MoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin[15]
?DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models[16]
5. 達到AGI需要什么結構?
目前這個階段,沒人知道一周以后會有什么大新聞,就像Sora悄無聲息放出來,一夜之間干掉U-Net,我也沒法說什么結構是最有效的。
總體上,目前沒有任何結構能真的完全beat Transformer,Mamba 目前 也不行,如這篇[17]發現 copy and paste不太行,scaling和in-context能力也有待查看。
考慮到未來擴展,優秀的結構應該滿足這么幾個東西,個人按重要性排序:
?Scaling Law。如果model很難通過scale up提升性能,意義不大(針對AGI來講)。但是建議大家不要針對這個地方過度攻擊學術界paper,學術界很難有資源進行這種實驗,路都是一步一步踩出來的,提出一個新architecture需要勇氣和信心,給一些寬容。嗯,說的就是Mamba。
?In-Context Learning能力。這個能力需要強大的retrieval能力和足夠的capacity,而對于Transformer來講,retrieval靠Attention,capacity靠FFN。scaling帶來的是兩者協同提升,進而涌現強大的in-context learning能力。
?Better Efficiency。說到底這也是為什么我們想換掉Transformer。做過的朋友都知道Transformer訓練太耗卡了,無論是NLP還是CV上。部署的時候又不像CNN可以做bn conv融合,inference memory大,low-bit quantization效果上也不如CNN,大概率是attention這個地方low-bit損失大。在滿足1,2的情況下,如果一個新結構能在speed, memory上展現出優勢那非常有潛力。Mamba能火有很大一部分原因是引入hardware-aware的實現,極大提升了原先SSM的計算效率。
?Life-long learning。知識是不斷更新的,訓練一個LLM需要海量tokens,強如OpenAI也不可能每次Common Crawl[18]放出新data就從頭訓一遍,目前比較實際的方案是持續訓練,但依然很耗資源。未來的結構需要更高效且持久地學習新知識。
Hallucination問題我反倒覺得不是大問題,畢竟人也有幻覺,比如對于不知道的,或自以為是的東西很自信的胡說一通,強推Hinton懟Gary Marcus這個視頻[19]。我現在寫的東西再過幾年回來看,說不定也是個Hallucination。。。
總結: FFN因為結構最簡單但是最有效,被大家沿用至今。相比之下,Transformer改進的大部分精力都在Attention這個更明顯的bottleneck上,有機會再寫個文章聊一聊這里。
審核編輯:黃飛
-
gpu
+關注
關注
28文章
4860瀏覽量
130165 -
Transformer
+關注
關注
0文章
147瀏覽量
6273 -
nlp
+關注
關注
1文章
489瀏覽量
22361
原文標題:聊一聊Transformer中的FFN
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從焊接角度聊一聊,設計PCB的5個建議

來聊一聊Altium中Fill,Polygon Pour,Plane的區別和用法
聊一聊stm32的低功耗調試
聊一聊7系列FPGA的供電部分
聊一聊FPGA的片內資源相關知識
聊一聊IIC總線設計
小米米聊2月19日停止服務 米聊宣布關閉服務器

聊一聊華為云彈性公網IP的那些事兒





 工商網監
工商網監

評論