 適配器微調在推薦任務中的幾個關鍵因素
適配器微調在推薦任務中的幾個關鍵因素
本文對基于適配器的可遷移推薦系統進行了實驗探索和深入研究。發現在文本推薦方面,基于適配器的可遷移推薦取得了有競爭力的結果;在圖像推薦方面,基于適配器的可遷移推薦略落后于全量微調。后續本文對四種著名的適配器微調方法進行了基準測試,并深入研究了可能影響適配器微調在推薦任務中的幾個關鍵因素。

論文題目:
Exploring Adapter-based Transfer Learning for Recommender Systems: Empirical Studies and Practical Insights
論文鏈接:
https://arxiv.org/abs/2305.15036
代碼鏈接:
https://github.com/westlake-repl/Adapter4Rec/
研究動機
可遷移的推薦系統 (TransRec) 通常包含一個用戶編碼器和一個或多個基于模態的物品編碼器,其中基于模態的物品編碼器通常是經過預訓練的 ViT, BERT, RoBERTA, 與 GPT 等模型,他們往往包含很大的參數量。常見使用 TransRec 的范式是先經過一個源域數據集的預訓練之后再遷移到目標域,遷移的過程往往都需要再進行微調。
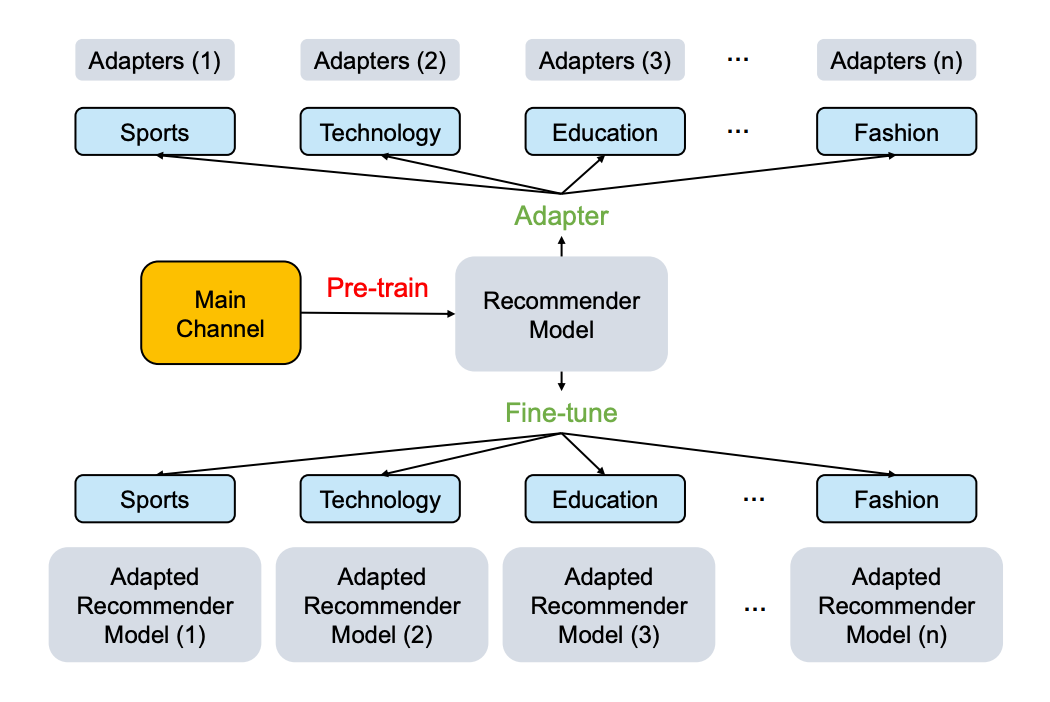
傳統的全參數微調 (Fine-tune All, FTA) 是很有效的方式,但它存在如下幾個問題:
1. 如上圖所示,推薦系統往往都包含一個主頻道和多個垂直頻道,如果想利用主頻道預訓練過的模型遷移至每個垂直頻道,則每個垂直通道的模型更新、維護和存儲都需要很多額外成本;
2. 全參數微調往往存在過擬合問題;
3. 昂貴的訓練成本,往往微調越大的模型所需要的 GPU 顯存越高。
這促使研究者們在 TransRec 中探索基于適配器 (Adapter) 的高效微調范式 (Adapter tuning, AdaT) 。AdaT 與傳統 FTA 的比較如下圖所示,AdaT 僅僅微調新插入的適配器和對應的 layer-normalization 層:
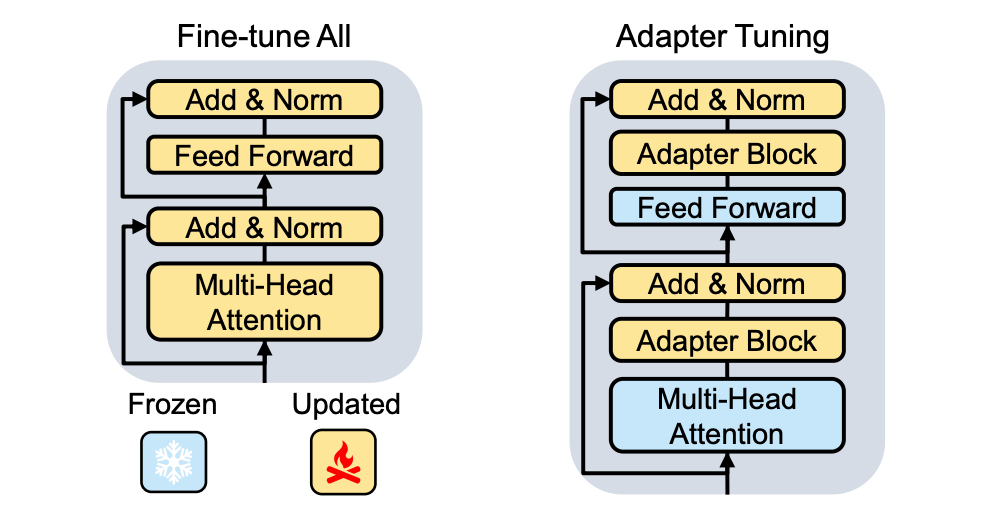
適配器是一種在 NLP 和 CV 中廣泛采用的參數高效方法用于解決高效遷移大規模基礎模型,然而在當前 TransRec 范式的推薦系統領域并沒有被系統的探究過該方法的有效性。針對于該有效性的探究,論文提出如下幾個關鍵研究問題:
RQ1: 基于適配器的 TransRec 性能上能否與典型的基于微調的 TransRec 相當?該結論適用于不同模態的場景嗎?
RQ2: 如果 RQ1 為正確或部分正確,那么這些 NLP 和 CV 社區當中流行的適配器性能又如何呢?
RQ3: 是否有因素影響這些基于適配器的 TransRec 模型的性能?
針對于 RQ1, 論文在兩種物品模態(即文本和圖像)上對基于適配器和基于全參數微調的 TransRec 進行了嚴格的比較研究。其中包括采用兩種流行的推薦架構(即 SASRec 和 CPC)以及四種強大的模態編碼(即 BERT、RoBERTa、ViT 和 MAE)。
針對于 RQ2, 論文對 NLP 和 CV 中廣泛采用的四種適配器進行了基準測試。還加入了 LoRA、Prompt-tuning 和 layer-normalization tuning 的結果,以進行綜合比較。
針對于 RQ3, 該文章進行了不同策略的性能比較,這些策略包括插入適配器的方式和位置,以及是否調整相應的 layer-normalization 等。除此之外,論文還研究了 TransRec 在源域和目標域中的數據縮放效應,以考察在使用較大數據集預訓練 TransRec 時 AdaT 的有效性。
網絡架構
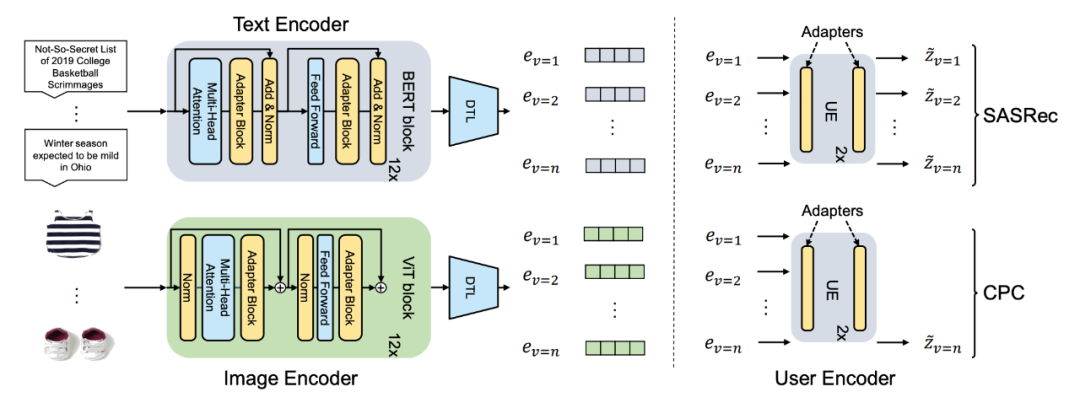
TransRec 架構包含兩個子模塊,即物品編碼器和用戶編碼器,這兩個模塊都基于 Transformer 模塊。論文采用插入適配器到物品和用戶編碼器當中。基于適配器的 TransRec 架構如下圖所示。論文采用 SASRec 和 CPC 框架對 TransRec 進行二元交叉熵 (BCE) 損失訓練。
實驗設置
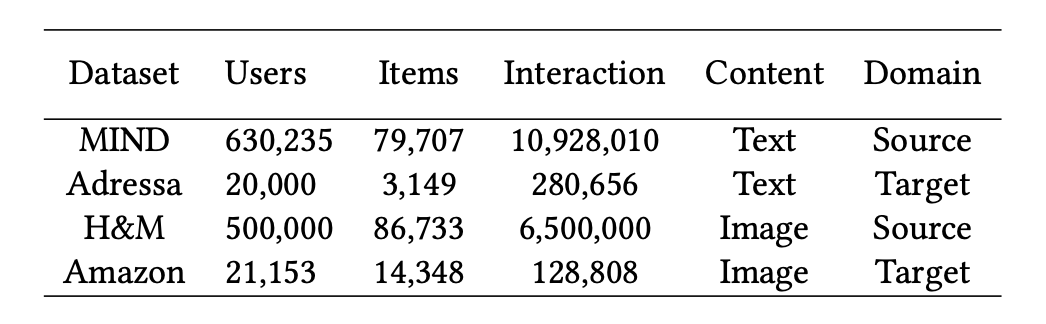
數據集:論文用兩種模式對基于適配器的 TransRec 進行了評估。對于具有文本模態的物品,使用 MIND 英語新聞推薦數據集作為源域,并使用 Adressa 挪威語新聞推薦數據集作為目標域。對于視覺模態,使用亞馬遜用于服裝和鞋類的評論數據集作為目標域,并使用 H&M 個性化時尚推薦數據集作為源域。
預訓練模型的使用:文本模態采用 bert-base-uncased 和 roberta-base 模型;圖片模態采用 vit-base-patch16-224 和 vit-mae-base 模型。
評價標準:論文采用 "leave-one-out"的策略來分割數據集:交互序列中的最后一項用于評估,最后一項之前的一項用于驗證,其余的用于訓練。評估指標采用 HR@10(命中率)和 NDCG@10(歸一化累計收益)。所有實驗結果均為測試集的結果。
主要發現
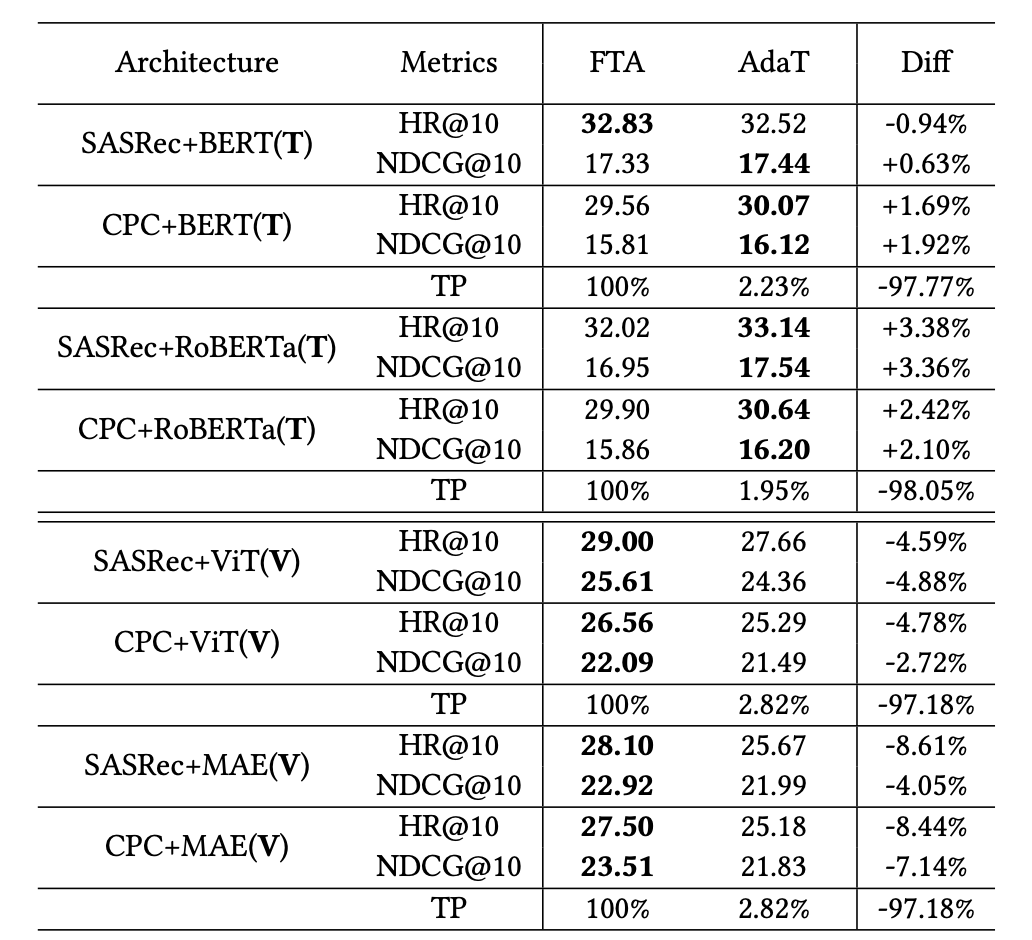
RQ1: 在文本內容中,使用 AdaT 的 TransRec 可獲得與 FTA 相當的性能,但在視覺場景中性能有所下降。
對比 FTA 和 AdaT 在文本和圖片場景下的實驗結果如下表所示:
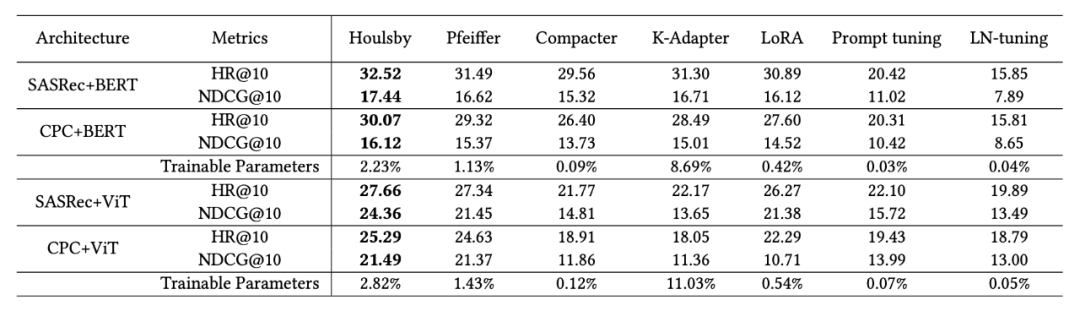
RQ2: 與其他流行的參數高效微調的方法相比,經典的Houlsby 適配器在 TransRec 中取得了最佳效果。
對比常用不同的參數高效微調方法的基準測試:
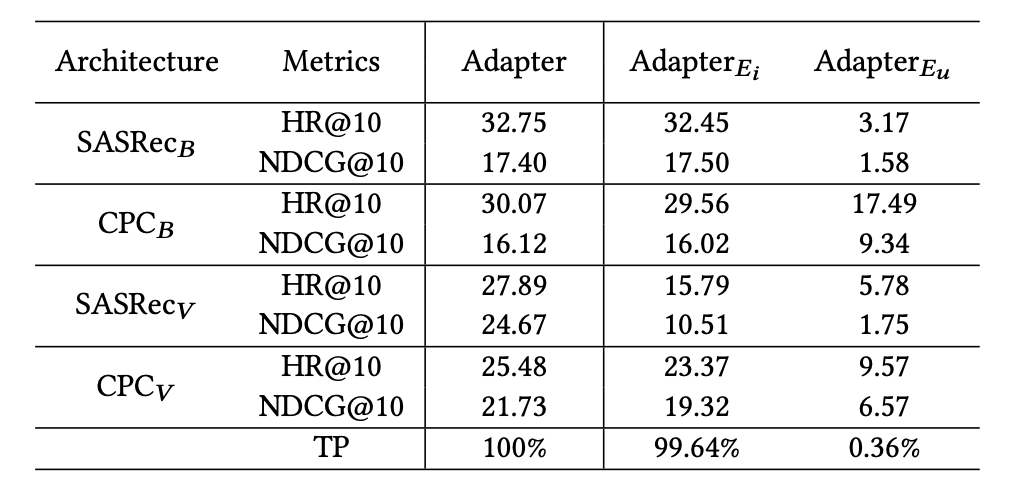
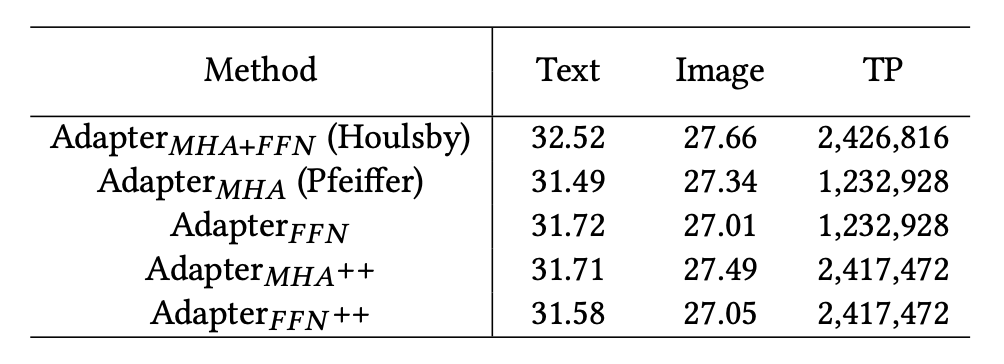
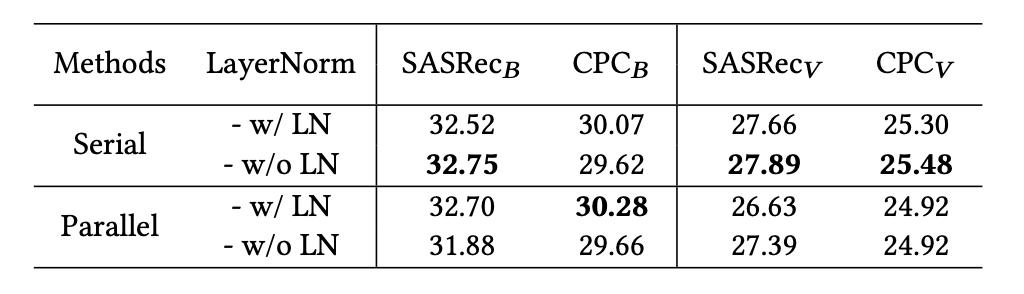
RQ3: 該文章認為,TransRec 應為用戶和物品編碼器放置適配器,以獲得最佳效果。插入位置同樣也很重要,Transformer當中的FFN (Feed-Forward Network) 和 MHA (Multi-Head Attentions) 的后面一層都需要單獨的適配器模塊。其次插入方式 (串行或并行) 和 LayerNorm 優化等其他因素對于推薦任務的性能上并不重要。
插入適配器的位置到物品 (Ei) 或用戶編碼器 (Eu) 的性能對比:
插入適配器到 MHA 和 FFN 之后的位置的性能對比:
采用序列和并行插入的性能對比:
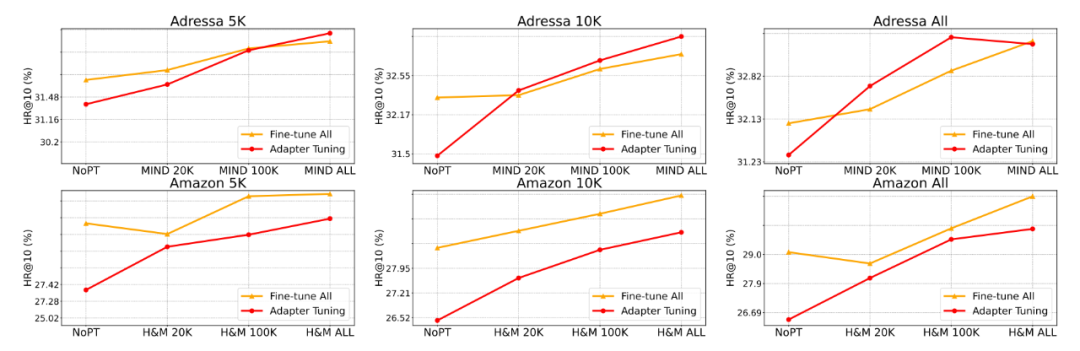
除此之外,該文章還進行了充分的數據縮放實驗,發現 TransRec 的遷移學習中如果有更多預訓練的源領域數據,目標域性能會有更大的提升:
總結
文章發現了兩個事實:1)在文本推薦方面,與微調所有參數 (FTA) 相比,AdaT 取得了有競爭力的結果;2)在圖像推薦方面,AdaT 性能良好,但略落后于 FTA。
論文對四種著名的 AdaT 方法進行了基準測試,發現經典的 Houlsby 適配器性能最佳。隨后,該文章深入研究了可能影響 AdaT 在推薦任務中的結果的幾個關鍵因素。最后,論文發現 TransRec 的 AdaT 和 FTA 符合理想的數據縮放效應——TransRec 在增大源領域數據時能提升性能。
該工作為模態推薦模型的參數高效遷移學習提供了重要指導。它對推薦系統社區的基礎模型也有重要的實際意義,是實現推薦系統社區“one model for all”的目標上重要的一環。該方向未來的工作包括探究圖片推薦當中如何提升 AdaT 的性能以及引入更多不同的模態等。
審核編輯:黃飛
-
編碼器
+關注
關注
45文章
3664瀏覽量
135208 -
適配器
+關注
關注
8文章
1970瀏覽量
68239 -
推薦系統
+關注
關注
1文章
43瀏覽量
10092 -
數據集
+關注
關注
4文章
1209瀏覽量
24814
原文標題:WSDM 2024 | 系統探究適配器微調對于可遷移推薦的影響
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦








 工商網監
工商網監
評論