 以太網存儲網絡的擁塞管理連載方案(三)
以太網存儲網絡的擁塞管理連載方案(三)
第3 層優先權流量控制
在OSI 模型的第3 層,流量由IPv4 或IPv6 源地址和目標地址標識。如圖7-5 所示,IP 標頭(v4 和v6)包含一個6 位DSCP 字段,允許多達64 種分類,但并非所有分類都被使用。
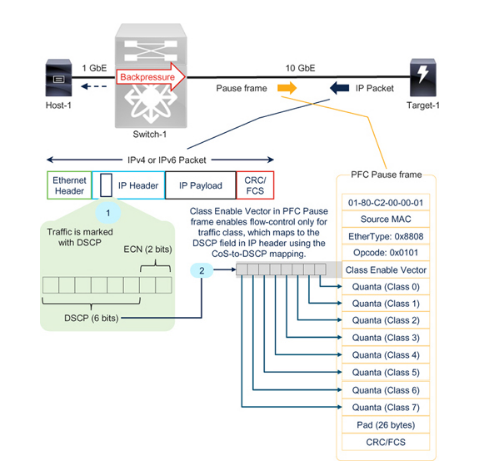
Figure 7-5IP 數據包的DSCP 字段與PFC 暫停幀中的類啟用向量之間的關系
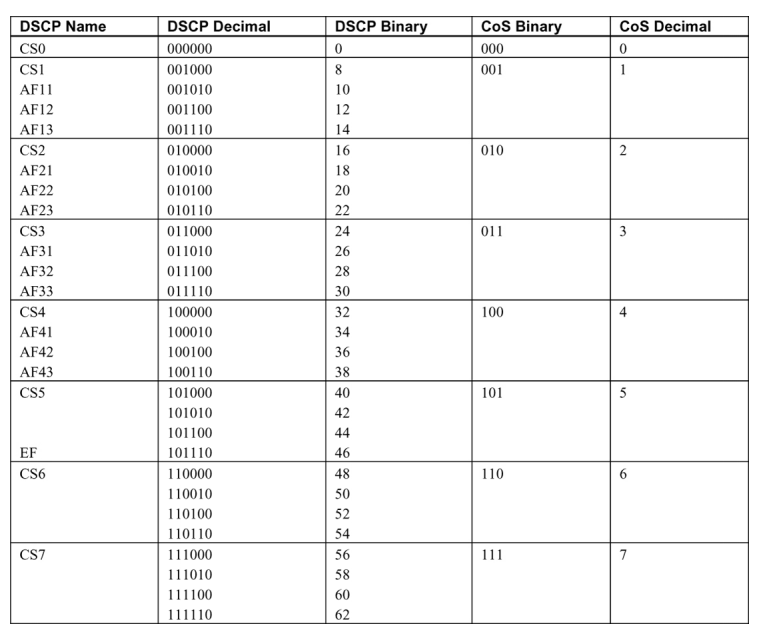
但PFC 暫停幀只攜帶八個流量類別的quanta值,因此需要進行映射(表7-1)才能成功實現第3 層PFC。這就是所謂的CoS 到DSCP 或DSCP 到CoS 映射。
在圖7-5 中,Host-1、Switch-1 和Target-1 同意將CS3 用于無損流量。目標-1 在IP 頭中標記DSCP 值24(二進制CS3 或011000)。Switch-1 將CS3 標記的IP 數據包(請參閱表7-1 中的映射)分配到一個無損隊列。當該隊列超過暫停閾值時,Switch-1 會發送一個類啟用向量為00001000 的PFC 暫停幀。因此,Target-1 會停止傳輸CS3 標記的IP 數據包,而不會影響其他類別的流量。要使CS4 流量也能實現無損行為,類啟用矢量應為00011000。
Table 7-1以太網VLAN CoS 和IP DSCP 映射
要了解Cisco Nexus 9000 交換機上的默認CoS 到DSCP 和DSCP 到CoS 映射,請使用NX-OS 命令show system internal ipqos global-defaults。
融合以太網網絡
如第1 章所述,在同一網絡中允許有損和無損流量的以太網網絡在本書中稱為融合以太網網絡。除PFC 外,融合以太網網絡還需要以下功能:
Bandwidth guarantee: 當無損流量和有損流量共享以太網鏈路時,必須合理分配帶寬,以免一種流量消耗掉鏈路的全部容量,導致另一種流量處于饑餓狀態。帶寬保證通過增強傳輸選擇(ETS)來實現,這是一項IEEE 標準(IEEE 802.1Qaz)。
Consistent configuration: 要成功運行PFC,直接連接的設備必須對無損和有損流量的定義以及帶寬的保證程度有一致的理解。要在所有網絡設備上一致地進行這些更改,手動操作既慢又容易出錯。更好的方法是在直接連接的設備中使用自動發現功能。數據中心橋接交換(DCBX)提供這種發現和廣告功能,它是一種IEEE 標準(IEEE 802.1Qaz)。DCBX 是另一個IEEE 標準(IEEE 802.1AB-2005)--鏈路層發現協議(LLDP)的擴展。
PFC、ETS 和DCBX 屬于IEEE 標準類別,稱為數據中心橋接(DCB)。它還有許多其他名稱,如數據中心以太網(DCE)、聚合以太網(CE)、聚合增強以太網(CEE)等。
請注意,某些文獻中使用的術語--融合網絡或融合以太網網絡--指的是不考慮無損行為而承載存儲和非存儲流量的網絡。不過,本書將此類網絡稱為共享存儲網絡。共享存儲網絡的一個子類別是聚合網絡,即配置為同時傳輸有損和無損流量的網絡。例如,當網絡傳輸無損RoCE 和有損HTTP/Web 流量時,它被稱為共享存儲網絡和聚合網絡。當網絡承載有損iSCSI 和有損HTTP/Web 流量時,它被稱為共享存儲網絡,而不是聚合網絡。如果你的理解不同,本書無意改變。不過,本書使用聚合網絡來表達網絡承載有損和無損流量,因此啟用了PFC、ETS 和(大部分)DCBX。
配置無損以太網
與默認啟用B2B 流量控制的光纖通道不同,配置以太網流量控制需要額外的步驟,并需要了解服務質量(QoS) 和模塊化QoS CLI (MQC)。這些配置細節不在本文討論范圍之內。有關這些主題的深入教學內容已在參考文獻部分列出。為便于理解,本章僅對QoS 概念進行了簡化解釋,并特意忽略了實施細節。
啟用PFC 需要以下步驟:
1. Classifying and marking the traffic: 對流量進行分類和標記是第一步,因為各種類型的流量(如存儲、語音、視頻、網絡和FTP)都可能在同一個端口上。分類是通過第2 層的以太網VLAN CoS 字段實現的。在第2 層邊界之外或幀未標記VLAN 時,則使用IP 報頭中的DSCP 字段。終端設備可以在向網絡發送幀之前對其進行標記,網絡可以信任這些標記。另外,邊緣交換端口也可以自行對數據包進行分類和標記。
2. Flow-control and bandwidth allocation: 分類后,必須確定哪些流量需要無損行為,哪些流量需要有損行為。無損流量由PFC 進行流量控制。如前所述,由PFC 進行流量控制的流量類別稱為無無損類別。交換端口還必須為無損類提供帶寬保證,如鏈路容量的50%。其他類別的流量不受流量控制,但仍可保證其帶寬。不丟棄類中的流量變為無損,而所有其他類中的流量保持不變(有損)。
3. Consistent implementation:最后,QoS 配置必須在所有終端設備和交換機上一致應用。例如,如果一臺交換機為CoS 3 啟用了無損行為,而同一網絡中的另一臺交換機卻為CoS 4 啟用了無損行為,那么結果將是無損流量變成有損流量。此外,QoS 配置錯誤還可能導致擁塞和更多問題。如前所述,DCBX 或軟件定義網絡技術可以簡化實施過程。
配置這些步驟取決于交換機類型及其架構,通常需要一定的學習時間。雖然使用自動化或圖形用戶界面可以簡化配置,但排除擁塞問題需要了解實現這些功能的命令。
請注意以下有關配置無損以太網的要點:
1. 我們建議使用供應商提供的QoS 配置,而不是自定義配置。如果供應商文檔中使用CoS 3 作為不丟棄類,那么最好在您的環境中使用相同的分類。雖然從技術上講可以更改分類,但與供應商文檔保持一致可使您的環境與全球其他部署保持一致。用戶可以直接復制/粘貼配置命令,而且在故障排除過程中,他們不必記住無損類的不同CoS 值。
2. 正如前面"暫停閾值"和"恢復閾值"部分所述,我們建議避免更改默認或供應商建議的數據中心內短距離鏈路暫停閾值和恢復閾值的PFC 配置。自定義這些值需要了解設備的緩沖區分配和隊列架構。如果更改不當,可能會導致暫停幀延遲發送或在需要時提前發送,從而導致性能下降。不過,長距離無損以太網鏈路需要更改這些閾值。
3. 根據設備的用例和能力,可能會有多個無損類別。例如,一個無損類用于FCoE,而另一個無損類用于RoCEv2。在這種情況下,一個無損類中的流量控制不會干擾其他無損類中的流量控制。PFC 暫停幀中的"類啟用矢量"(Class Enable Vector)可啟用相應流量類的位及其量值。
4. 在配置將流量類別(DSCP)分配到不丟棄隊列后,交換機會對所有標記了DSCP 值的數據包使用逐跳流量控制。如果終端設備錯誤地標記了數據包,交換機將無法得知,并將有損流量分配到無損隊列,或將無損流量分配到有損隊列。
本書將無損類別的流量稱為無損流量,將其他流量稱為有損流量,而不考慮分類、標記、帶寬分配和特定設備的實施細節。
專用和融合以太網網絡
將網絡配置為融合以太網網絡(有損和無損流量)并不一定意味著有損和無損流量可以同時運行。例如,假設你配置了一個網絡,50% 的帶寬分配給無損流量,50% 的帶寬分配給其他流量。如果當時沒有無損流量,那么在數據層,該網絡與其他有損以太網網絡沒有任何區別。另一方面,如果無損類中沒有流量,該網絡就會像專用無損網絡一樣運行。換句話說,它"配置"為融合網絡,但"運行"為專用網絡。
請看下面的例子。
1. Cisco UCS Servers: Cisco UCS 服務器使用融合以太網在同一鏈路上傳輸無損(光纖通道和RoCE)和有損(TCP/IP)流量。但是,如果沒有服務器通過光纖通道或RoCE 使用存儲,則內部鏈路將永遠不會報告"暫停"幀,盡管聚合以太網的配置仍應用于這些鏈路。有關Cisco UCS 服務器的更多詳細信息,請參閱第9 章"Cisco UCS 服務器中的擁塞管理"。
2. FCoE on Cisco MDS Switches: 雖然Cisco MDS 交換機上的FCoE 端口是為融合以太網配置的,但它們只能處理無損流量,不能發送/接收有損類流量。
需要了解的關鍵一點是,即使是專用無損網絡,其配置也與融合網絡相同。上一節中解釋的流量分類、帶寬保證、流量控制等配置在這兩類網絡中都適用。不過,流量模式使兩者有所不同。對于擁塞檢測和故障排除,第一步是驗證配置,這對兩種類型的網絡都是一樣的。下一步是關注流量模式,這取決于網絡是只傳輸無損流量(專用),還是同時傳輸無損和有損流量(融合)。
了解無損以太網網絡中的擁塞問題
無損以太網網絡容易出現與光纖通道結構類似的擁塞,因為兩者都在直接連接的設備之間使用流量控制。而且,這種擁塞會向流量源蔓延,使許多共享相同網絡路徑和流量類別的其他設備受害。
第1 章"存儲網絡中的擁塞--概述"一節解釋了擁塞傳播的基本原理以及擁塞的各種原因和來源。本節將進一步闡述無損以太網網絡中的這些基礎知識。
慢速排空
與流量傳輸速率相比,處理速率較慢的終端設備稱為慢排泄設備,由此造成的擁塞稱為慢排泄。這種終端設備使用暫停幀來控制入口流量速率。這通常會導致該設備發送過多的暫停幀。這些幀在其連接的交換端口上被報告為入口暫停幀。
過度使用鏈接
當交換端口以最大速度傳輸數據,但傳輸的幀數超過了該鏈路的傳輸能力時,就會出現因過度使用而導致的擁塞。交換機會使用暫停幀來控制通過過度利用鏈路發送流量的上游設備的流量速率。這將導致高利用率或充分利用鏈路,而鏈路正是擁塞和向上游設備發送過多暫停幀的根源。
比特錯誤
比特錯誤可能干擾LLFC/PFC,導致擁塞或使現有擁塞惡化。當流量發送端在接收到的暫停幀中檢測到CRC 錯誤時,會丟棄已損壞的暫停幀,因此不會停止流量。下一個有效的暫停幀應能停止流量,但當下一個暫停幀停止流量時,緩沖區空間可能已滿。這可能會導致不丟幀類中的丟幀。
位錯誤的另一個重要影響是FCoE Fabric 的性能,因為即使只有一個數據包被丟棄,整個I/O 操作也會重新啟動。第1 章"鏈路上的位錯誤"一節解釋了這一概念。
由于這些原因,應盡快檢測位錯誤,找到其根本原因,并進行糾正更改。
單交換機無損以太網網絡中的擁塞蔓延
請參閱圖7-6 中的單交換機無損以太網網絡,該網絡連接40 臺主機和8 個目標。每臺主機通過無損類中的所有8 個存儲端口訪問存儲。在無損類中,主機之間不進行通信。同樣,目標也不會在無損類中相互通信。所有設備都與無損類之外的其他設備通信。
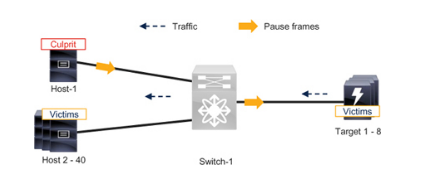
Figure 7-6單交換機無損以太網網絡中的擁塞問題
當主機(Host-1)成為慢排泄設備時,它會通過發送暫停幀來降低入口流量的速率。交換機可以緩沖一些幀,但最終其隊列會超過暫停閾值,因此會向八個目標發送暫停幀,以降低它們的速度。
這是意料之中的行為。但它也有副作用。PFC 會減慢無損類中的所有流量,無論流量目的地是哪里。因此,其他39 臺服務器即使沒有調用PFC,也會受到影響。
最后,在這個擁有40 臺主機和8 個目標的單交換機網絡中,一臺罪魁禍首主機就能使所有其他設備受害。這種無損以太網網絡中的擁塞擴散效應與類似的光纖通道結構并無不同,因為兩者都使用逐跳流量控制。
正如第4 章"故障排除光纖通道Fabric 中的擁塞"中"識別受影響的設備(受害者)"一節所述,目標是直接受害者,因為它們與主機1 直接通信。主機2 - 40 是間接受害者,因為它們與直接受害者(目標)進行通信。
邊緣核心無損以太網網絡中的擁塞蔓延
接下來,請看圖7-7,圖中顯示了一個具有三個主機邊緣交換機和一個核心交換機的邊緣-核心網絡。每個主機邊緣交換機連接200 臺主機,存儲邊緣交換機連接100 個目標。存儲流量保持在無損類。在無損類中,主機之間不進行通信。同樣,目標也不會在無損類中相互通信。所有設備都與無損類之外的其他設備通信。
當主機成為慢耗設備時,它會通過發送暫停幀來降低入口流量的速率。主機邊緣交換機可以緩沖一些幀,但最終其隊列會超過暫停閾值,因此它會向核心交換機發送暫停幀。這將減慢該邊緣交換機與核心交換機之間所有不丟棄類流量的速度,無論流量目標是什么,這將影響連接到同一邊緣交換機的多達199 臺主機。
此外,核心交換機可以緩沖一些幀,但最終其隊列也會超過暫停閾值,因此它會向在擁塞ISL 上發送流量的所有目標發送暫停幀。這些目標會減慢無損類中的流量,而不管流量的目的地是什么,這些目的地可能是連接到任何主機邊緣交換機的任何主機,甚至是連接到存儲邊緣交換機的主機(圖7-7 中未顯示)。
因此,一臺故障設備會使整個網絡中的許多設備受害。在這個無損以太網網絡中,擁塞擴散的效果與在類似光纖通道結構中觀察到的效果相同。將圖7-7 與第6 章"網絡設計注意事項"一節中的示例進行比較。
正如第4 章"識別受影響設備(受害者)"一節所述,圖7-7 中的受害者可進一步分為直接受害者、間接受害者和同路徑受害者。
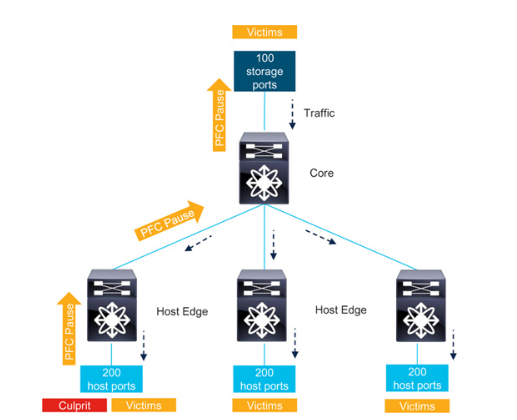
Figure 7-7邊緣核心無損以太網網絡中的擁塞問題
為了減少圖7-7 中擁塞的擴散,正如第6 章"增加單個交換機的流量定位"一節所述,如果目標及其主機連接到同一交換機,那么其他交換機上的終端設備就不會受害。
無損脊葉網絡中的擁塞擴散
請看圖7-8,了解無損葉脊網絡中的擁塞傳播。主機和目標不按特定順序連接到葉交換機。存儲流量保持在無損級。主機之間不在無損類中通信。同樣,目標也不會在無損類中相互通信。所有設備都與無損類之外的其他設備通信。由于等價多路徑(ECMP)的存在,主交換機和葉子交換機之間的所有鏈路都被統一使用。例如,從目標-1 到主機-1 的流量先到葉子-1,然后到所有四個主交換機,最后通過其所有上行鏈路到葉子-6。
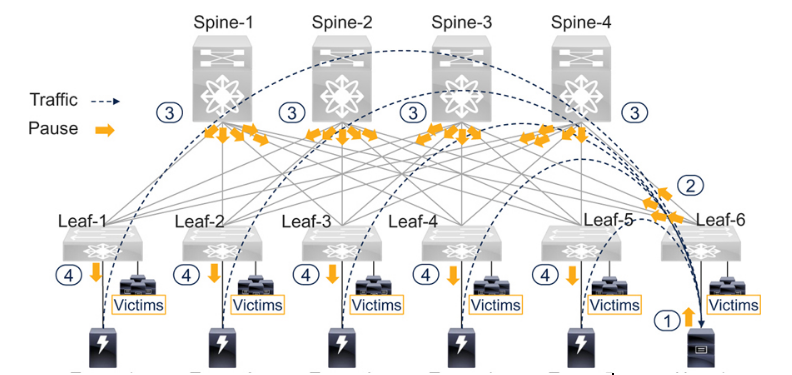
Figure 7-8無損以太網脊葉網絡中的擁塞問題
連接到Leaf-6 的Host-1 接收來自五個目標主機的流量,這些目標通過Leaf-5 交換機連接到Leaf-1。當Host-1 成為慢排空設備時,它會向Leaf-6 發送暫停幀,以減緩入口流量。最終,Leaf-6 的"暫停閾值"超標,因此它會向其上游鄰居發送暫停幀。這就減慢了從四個骨干交換機到Leaf-6 的流量,從而使連接到Leaf-6 并從任何其他葉交換機后面的任何其他目標接收流量的其他主機受害,盡管這些主機沒有調用PFC。
此外,骨干交換機超出了暫停閾值,因此它們會向所有向葉子6 發送流量的葉子交換機(葉子1 - 葉子5)發送暫停幀。這就減慢了來自葉子交換機的所有流量(無論其目的地如何),因此許多無關設備也受到了影響。
最后,與目標主機連接的葉子交換機(如Leaf-1)超過了暫停閾值,因此它們會向目標主機(如Target-1)發送暫停幀,以降低其速度。在Leaf-1 上,由于Target-1 會減慢無損類中的所有流量(無論其目的地如何),甚至連接到Leaf-6 并從Target-1 接收流量的主機也會受到影響。這些受害者往往被忽視,因為他們的流量仍在本地葉交換機上,而罪魁禍首卻連接到了不同的葉交換機上。但是,由于罪魁禍首會對目標造成不利影響,所有從這些目標接收流量的主機都會受到影響,無論它們位于何處。
正如第4 章"識別受影響設備(受害者)"一節所述,圖7-8 中的受害者可進一步分為直接受害者、間接受害者和同路徑受害者。
慢速排空
圖7-8 解釋了當Host-1 的處理速度低于向其傳輸幀的速度時(慢排空)的情況。但它的鏈路并未得到充分利用。例如,Host-1 以10 GbE 連接到Leaf-6,但它只能以5 Gbps 的速度接收流量,這是因為Host-1 內部存在其他問題,導致它無法處理超過5 Gbps 的入口流量,因此它調用了PFC。
主機邊緣鏈路的過度使用
當Host-1 能夠以其鏈路的全部容量(10 Gbps)處理入口流量時,就會出現因過度使用而導致的擁塞。它沒有調用PFC。然而,Leaf-6 接收到的流量(例如11 Gbps)超過了可以發送到Host-1 的流量,因此Leaf-6 調用PFC 來減緩來自骨干交換機的流量。
因排空緩慢和過度使用造成的擁堵比較
如果擁塞是由慢排空設備或過度使用主機邊緣鏈路造成的,那么對結構的影響也是一樣的。
區別在于邊緣交換端口。當擁塞由慢排空引起時,連接的邊緣交換端口會收到很多暫停幀,其出口利用率并不高。相反,當擁塞由過度使用造成時,邊緣交換端口不會收到暫停幀,而出口利用率卻很高。這種差異是檢測擁塞原因的基礎。
檢測無損以太網網絡中的擁塞問題
以下是無損以太網網絡擁塞檢測工作流程的關鍵因素。
檢測到什么
擁堵的影響是什么?換句話說,有多嚴重?
擁堵的原因是什么?
擁堵的根源(罪魁禍首)在哪里?
擁堵(受害者)擴散到哪里?
擁堵是什么時候發生的?
如何檢測
反應式方法:在擁堵事件發生后進行檢測并排除故障。
積極應對:實時檢測擁堵事件。
預測性:在擁堵事件發生之前進行預測。
從何處檢測
在交換機、主機/服務器或存儲陣列等設備上運行。
使用遠程監控平臺,如UCS 流量監控應用程序,詳見第9 章。
有關這些主題的詳細說明,請參閱第3 章"檢測光纖通道Fabric 中的擁塞"中的"擁塞檢測工作流程"一節。同樣的細節也適用于無損以太網網絡,因此在此不再贅述。本節僅提供適用于無損以太網網絡的簡要概述。
擁堵方向- 入口或出口
擁塞是有方向性的。擁塞通常發生在一個方向,而反方向可能不擁塞。試圖沿著錯誤的方向追蹤擁塞情況,并不能找到擁塞的源頭和原因。
例如,在圖7-8 所示的脊葉網絡中,在骨干交換機上,只有葉6 方向的流量會受到擁塞的影響。從Leaf-6 到骨干交換機的流量不受擁塞影響。
出口交換端口的擁塞會導致入口端口的擁塞,而入口端口的擁塞又會導致流向源的流量路徑上至少一些上游端口的出口擁塞。換句話說,出口擁塞會導致入口擁塞。入口擁塞不會導致出口擁塞。因此,出口方向的擁塞檢測工作流程和指標對于識別擁塞源更為重要。
圖7-9 顯示了圖7-8 所示脊葉網絡的一個子集。擁塞源是Host-1,它會導致Leaf-6 出現出口擁塞。這種出口擁塞導致連接到葉子交換機的葉子-6 端口出現入口擁塞。同樣的入口和出口擁塞順序一直持續到流量源(目標-1)。根據端口的位置,調查入口或出口方向的擁塞情況。
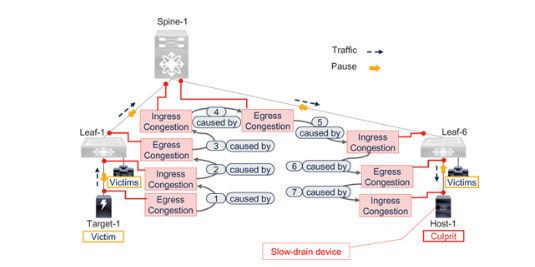
Figure 7-9無損脊葉網絡中的擁塞方向和流量方向
擁塞檢測指標
以下是有助于檢測無損以太網網絡擁塞情況的指標。
檢測流量暫停的指標,也稱為暫停幀監控。
流量暫停持續時間:端口因接收到鄰居的暫停幀而無法傳輸的時間。
流量暫停的次數:接收或發送的暫停幀數。
可用緩沖區的瞬時值:在流量接收器上,瞬時緩沖區利用率會顯示距離暫停閾值的距離,從而觸發暫停幀。
檢測丟幀的指標。
檢測位錯誤(如CRC 破壞幀)的指標。
檢測鏈路利用率的指標,如端口上接收和發送的幀的數量和大小。
用于檢測應用程序I/O 配置文件的指標,例如幀內I/O 操作的時間、大小、類型和速率。
這些指標類型與第3 章"光纖通道端口擁塞檢測指標"一節中解釋的指標類型相同。無損以太網端口沒有只針對光纖通道B2B 流量控制的指標,如鏈路重置協議或B2B 狀態更改機制。光纖通道端口會在剩余Tx-B2B 信用為零且持續時間較長時啟動信用損失恢復(通過鏈路重置協議)。無損以太網沒有類似的概念,無論端口被鄰居持續暫停多長時間。
如果以太網端口不報告指標或訪問指標不夠方便,變通方法是反向使用直接連接的鄰接端口的指標。例如
端口的入口利用率與其鄰居的出口利用率相同,反之亦然。
在大多數情況下,以太網端口發送的暫停幀與其鄰居接收的暫停幀相同。暫停幀有可能在中間損壞,從而無法被對等設備識別。在這種情況下,端口將繼續發送暫停幀,直到其隊列利用率低于恢復閾值。因此,在實際操作中,只需監控鏈路上一個端口的暫停幀即可。例如,在主機端口與其連接的交換端口之間的鏈路上,可以只監控其中一個端口上的TX 和RX 暫停。
這種跨相鄰設備的關聯最好在遠程監控平臺上進行。
流量暫停持續時間- TxWait 和RxWait
TxWait 是端口因接收到鄰居的暫停幀而無法傳輸的持續時間。它也稱為暫停持續時間。
RxWait 與反向的TxWait 類似。它是端口因發送暫停幀而無法接收流量的持續時間。
TxWait 和RxWait 可以轉換成更有意義的值,稱為TxWait 百分比,即端口在一定時間內無法傳輸的時間百分比。例如,20 秒內50%的TxWait 表示端口在10 秒內無法傳輸。
請注意以下有關TxWait 和RxWait 的要點:
1. TxWait 是因為Rx 暫停,而RxWait 是因為Tx 暫停。
2. 如果端口不報告TxWait,則可選擇在其鄰居上使用RxWait。
3. 優先使用TxWait 和RxWait(或檢測流量暫停持續時間的類似指標)來檢測無損以太網網絡中的擁塞情況。當TxWait 和RxWait 不可用時,使用其他指標,如暫停幀數。
4. 在撰寫本文時,Cisco MDS 和Nexus 7000 交換機收集FCoE 端口上的TxWait 和RxWait。Cisco Nexus 9000 交換機和Cisco UCS 服務器不收集TxWait 和RxWait。
以太網端口上的TxWait 和RxWait 與光纖通道端口上的TxWait 和RxWait 類似。本節簡要介紹顯示Cisco MDS 交換機FcoE 端口上TxWait 和RxWait 的命令。更多詳細信息請參閱第3 章"以微秒為單位的Tx Credit Unavailability(TxWait)"和"以微秒為單位的Rx Credit Unavailability(RxWait)"一節。
Raw and Percentage TxWait and RxWait
例7-5 顯示了Cisco MDS 交換機FCoE 端口的原始和百分比TxWait 和RxWait。MDS 交換機以2.5 微秒(μs)為增量報告TxWait 和RxWait,因此4 的值等于10 μs。例7-5 顯示過去1 秒內RxWait 為49%,這表明該端口在過去1 秒內向鄰居發送了暫停幀,以停止流量490 毫秒(ms)。
請注意,TxWait 僅針對VL3 進行測量。這是用于CoS3 流量的FCoE 類別,使用PFC 進行流量控制。

Example 7-5交換機上顯示接口中的TxWait 和RxWait
TxWait 和RxWait 歷史圖表
Cisco MDS 交換機顯示三個TxWait 和RxWait 歷史記錄圖。
每列顯示每秒的累計TxWait 或RxWait。
每列顯示每分鐘的累計TxWait 或RxWait。
每列顯示每小時的累計TxWait 或RxWait。
有關輸出示例,請參閱第3 章"TxWait 歷史圖表"部分,FC 和FCoE 接口的輸出示例相同。
TxWait and RxWait History in OBFL
如例7-6 所示,當TxWait 和RxWait 的值在20 秒間隔內增加100 毫秒或更多時,Cisco MDS 交換機會在板載故障日志(OBFL) 緩沖區中記錄這兩個值。

請參閱第3 章"TxWait History Graphs(TxWait 歷史記錄圖表)"一節,了解該輸出的詳細說明,FC 和FCoE 接口的輸出相同。有關OBFL 的詳細信息,請參閱第4 章OBFL 命令- show logging onboard 部分。
Number of Pause Frames
當TxWait 和RxWait 不可用時,下一個選擇是了解以太網端口發送和接收的暫停幀數。
這些計數器類似于光纖通道端口上的"信元轉換為零"計數器,只是沒有那么具體,因為只有一些quanta不為零的暫停幀才會真正停止流量。
以下是使用暫停幀數檢測擁塞的一些要點:
1. 在撰寫本報告時,大多數實現都不會單獨計算暫停(非零quanta)和非暫停(零quanta)。暫停幀計數是兩種暫停幀類型的總和。
2. 在正常情況下,暫停幀計數器的增量可能很小,不會對應用性能產生任何影響。當邊緣端口上的暫停幀計數增量很小,而上游端口上的暫停幀計數不增量時,這表明擁塞已被該交換機的緩沖區吸收。這種情況不會危及其他設備,因此不像擁塞擴散那樣令人擔憂。它只是說明LLFC/PFC 運行良好。
3. 暫停幀計數只能作為上次清除計數器后的累計值報告。大量的暫停計數并不能說明擁塞是昨天、上周還是上個月發生的。在撰寫本文時,除了Cisco MDS 和Nexus 7000 交換機外,Cisco 設備只能提供累計的暫停幀計數,因為這兩種交換機會保留帶有時間和日期戳的歷史記錄。
例7-7 顯示了Cisco UCS Fabric Interconnect 上的入口和出口PFC 暫停幀。運行NX-OS 命令show interface priority-flow-control 兩次,每次間隔10 秒。輸出結果如下:
1. 以太網1/1 和以太網1/8 使用LLFC(操作關閉),而以太網1/1/7 使用PFC(操作打開)。
2.以太網1/1/7 僅在CoS 3 中使用PFC。VL bmap 顯示PFC 暫停幀中的類啟用向量(圖7-4)。它采用十六進制格式。0x8 的二進制值為1000。從右側讀取并從0 開始,第3 位被啟用。這表明CoS 3 流量被分配到了不丟棄類。同樣,VL vmap 值為0x28 意味著為CoS 3 和CoS 5 啟用了PFC,因為0x28 的二進制值為101000。
3. RxPPP 和TxPPP 顯示所有類別中PFC 暫停幀的總計數。PPP 表示每優先級暫停。
4. 以太網1/1 在這10 秒內沒有出現入口或出口擁塞,因為TxPPP 和RxPPP 計數器沒有變化,盡管暫停幀是在較早的未知時間發送和接收的。
5. 以太網1/8 出現了出口擁塞,因為RxPPP 計數在10 秒內增加了1456(846831773 - 846830317)。它沒有出現入口擁塞,因為TxPPP 計數器保持不變。
6. 以太網1/1/7 出現入口擁塞,因為TxPPP 計數在10 秒內增加了38(1406361419 - 1406361381)。它沒有出現出口擁塞,因為RxPPP 計數器保持不變。
7. 對以太網1/8 (1456 個) 和以太網1/1/7 (38 個) 10 秒間隔內的暫停幀數量進行比較后發現,以太網1/8 的擁塞情況更為嚴重,盡管方向相反。
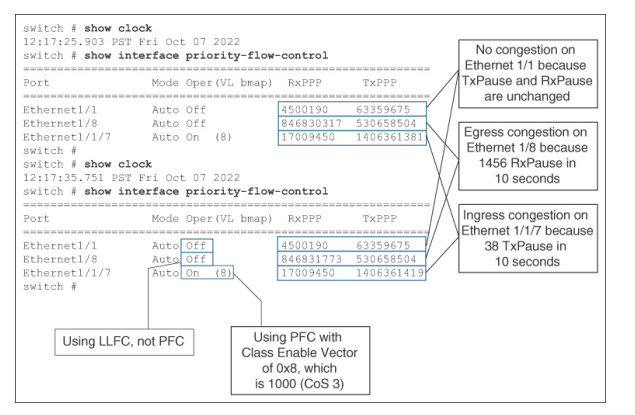
Example 7-7Pause frame count in show interface priority-flow-control on Cisco UCS
“show interface priority-flow-control”是Cisco Nexus 9000 交換機和Cisco UCS 服務器上檢測和排除擁塞故障的主要命令,因為它非常簡單。但它顯示的是所有類別的暫停幀的總計數,這沒有問題,因為大多數環境可能只對單個流量類別使用PFC。
要查找Cisco Nexus 9000 交換機上每個類的暫停幀計數,請使用NX-OS 命令show queuing interface。例7-8 顯示了以太網1/1 上入口和出口方向的擁塞指示。在類級別上,只有CoS 1 出現擁塞,而CoS 3 沒有任何擁塞跡象。此外,請注意在執行該命令時,CoS 1 處于暫停的活動狀態。要找到處于激活狀態的RxPause 或TxPause 必須非常幸運。如果在多次快速執行該命令時RxPause(ox TxPause)一直處于活動狀態,則表明直連鄰居是一個慢耗盡設備,導致嚴重擁塞。
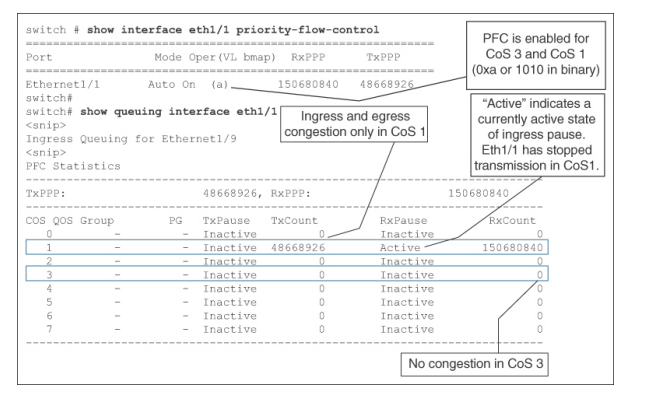
Example 7-8Per-priority Pause frame count and current state in show queuing interface
Cisco Nexus 9000 交換機和Cisco UCS 服務器上的show interface 命令也會顯示暫停計數器(例7-9)。但這些都是LLFC 計數器,啟用PFC 時不會遞增。
Example 7-9LLFC Pause counter in show interface
Frame Drops or Discards
使用LLFC 或PFC 時,不應丟棄幀。但是,如果端口在超過暫停閾值后仍繼續接收流量,且其緩沖區凈空已完全耗盡,端口就會丟棄幀。丟棄幀的另一種情況是在嚴重擁塞時,幀在隊列中停留的時間超過了暫停超時或PFC 看門狗時間間隔(稍后解釋),隊列會清空所有數據包。
由于各種原因,大多數以太網端口都會報告丟棄或丟棄的幀。請參閱例7-9,其中顯示了NX-OS 命令show interface 中的輸入和輸出丟棄情況。這是無損和其他類別的集體計數。
使用NX-OS 命令show queuing interface 查找每個流量類別的丟包情況。請參考例7-10。它顯示已為CoS 3 和CoS 4 啟用了PFC。該輸出所使用的交換機支持兩個無損隊列。分配給CoS 值較小(3) 的無損隊列中的數據包丟棄顯示在"Low Pause Drop Pkts "下面。同樣,分配給CoS 值較大(4) 的無損隊列中的丟包顯示在"高暫停丟包"下。Low(低)和High(高)指的是較小和較大的CoS 值。CoS 3 的無損類別丟棄了255 個數據包,而分配給CoS 4 流量的無損類別沒有丟棄任何數據包。
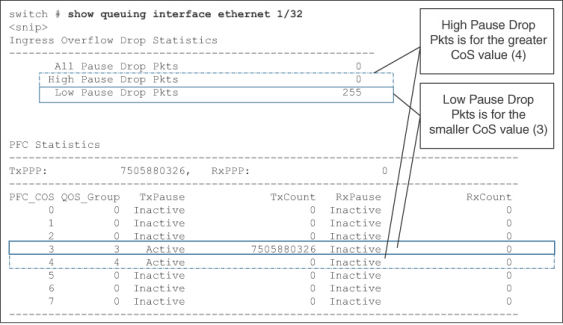
Example 7-10Packet drops per no-drop class
Bit Errors
檢測以太網端口位錯誤的主要方法是CRC、stomped CRC 和FEC。
CRC Counters
發送方對幀內容計算幀校驗序列(FCS)多項式,并將計算結果置于幀的CRC 字段中。接收方收到幀后,對幀內容計算相同的FCS 多項式。如果計算輸出與CRC 字段的內容不匹配,則該幀未通過CRC 校驗,稱為CRC 損壞幀。因此,接收器會遞增輸入的CRC 計數器。
需要記住的一個要點是,只有當比特錯誤出現在幀內時,CRC 計數器才會遞增。但如果比特錯誤在幀邊界之外,或者如果流量較低導致鏈路上的幀較少,那么即使鏈路上存在比特錯誤,CRC 計數器也可能不會遞增。第2 章案例研究- 一家在線零售商演示了這種情況。
例7-9 使用NX-OS 命令show interface 顯示Cisco Nexus 9000 交換機和Cisco UCS 服務器上的CRC 錯誤。
使用CRC 計數器檢測位錯誤時,一個重要的考慮因素是交換機的直通式或存儲轉發式結構。第2 章"檢測和丟棄CRC 損壞幀的能力"一節將詳細解釋這一點。簡而言之,直通式交換機可減少端口到端口的交換延遲。但這些交換機無法丟棄CRC 破壞的幀,因為它們在接收到完整的幀之前就開始傳輸幀,而且CRC 字段位于幀的末尾。在這種情況下,同一個CRC 損壞的幀會導致其路徑上不同交換機上多個端口的CRC 計數器遞增,從而使檢測比特錯誤源變得復雜。如果交換機支持堆疊CRC,則可在一定程度上降低這種復雜性,具體說明見下節。
Stomped CRC Counters
Stomped CRC 計數器有助于在使用直通式交換機的網絡中查找位錯誤的位置。更確切地說,這些計數器有助于找到不存在位錯誤的地方。
當直通交換機支持踩踏CRC 功能時,它會在損壞幀的CRC/FCS 字段中編碼一個特殊值。這就是所謂的"幀踩踏"。如前所述,交換機不能丟棄損壞的幀,因為它已經開始傳輸。但交換機可以踩幀,因為它知道幀已損壞,而且尚未傳輸幀末的CRC 字段。當下一個交換機檢測到被踩踏的幀時,它只會遞增被踩踏的CRC 計數,而不會遞增CRC 計數。對所有這些端口進行比較后,就可以排除有踩踏CRC 錯誤的端口,對有CRC 計數器的端口/鏈路進行調查。損壞的幀最終會在目的地或存儲轉發交換機上丟棄。
例7-9 使用NX-OS 命令show 界面顯示了Cisco Nexus 9000 交換機和Cisco UCS 服務器上的Stomped CRC 錯誤。
Forward Error Correction
啟用FEC 時,發送方會在比特流中增加一些額外的奇偶校驗位。接收器可利用這些奇偶校驗位檢測和恢復有限的比特錯誤。
當FEC 能夠恢復損壞的比特時:
經校正的FEC 計數器增量,以及
CRC 計數器不會遞增,因為FEC 已在較低層恢復了比特錯誤,比特將按照發送方發送的方式移交給成幀層。
當FEC 無法恢復損壞的比特時:
FEC 未校正塊計數器增量,以及
如果位錯誤發生在一個幀內,CRC 計數器可能會遞增。
在Cisco Nexus 9000 交換機上,使用命令show hardware internal tah mac hwlib show mac_errors fp-port 顯示FEC Correctable 和FEC UnCorrectable 計數器。如例7-11 所示,這是一條模塊級命令,因此使用前必須使用NX-OS 命令attach module。




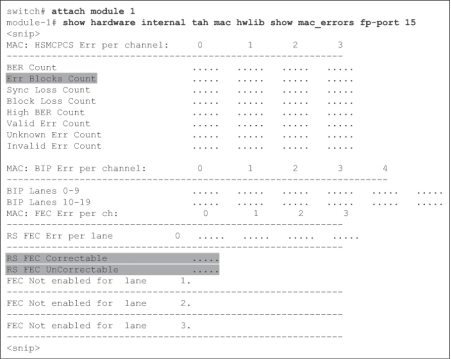


Example 7-11FEC Counters on Cisco Nexus 9000 switches
switch# attach module 1
module-1# show hardware internal tah mac hwlib show mac_errors fp-port 15
MAC: HSMCPCS Err per channel: 0 1 2 3
------------------------------------------------------------
BER Count ..... ..... ..... .....
Err Blocks Count ..... ..... ..... .....
Sync Loss Count ..... ..... ..... .....
Block Loss Count ..... ..... ..... .....
High BER Count ..... ..... ..... .....
Valid Err Count ..... ..... ..... .....
Unknown Err Count ..... ..... ..... .....
Invalid Err Count ..... ..... ..... .....
MAC: BIP Err per channel: 0 1 2 3 4
--------------------------------------------------------------------
BIP Lanes 0-9 ..... ..... ..... ..... ..... .....
BIP Lanes 10-19 ..... ..... ..... ..... ..... .....
MAC: FEC Err per ch: 0 1 2 3
------------------------------------------------------------
RS FEC Err per lane 0 ..... ..... ..... .....
------------------------------------------------------------
RS FEC Correctable .....
RS FEC UnCorrectable .....
FEC Not enabled for lane 1.
------------------------------------------------------------
FEC Not enabled for lane 2.
------------------------------------------------------------
FEC Not enabled for lane 3.
------------------------------------------------------------
FEC 計數器不僅能檢測比特錯誤,還能預測網絡的健康狀況。第2 章"案例研究--一家在線零售商"一節對此進行了演示。
有關FEC 的詳細說明,請參閱第2 章"前向糾錯"一節。由于光纖通道重復使用以太網IEEE 803.2 標準中的FEC 代碼,因此以太網網絡也適用相同的細節。但術語可能有所不同。以太網稱為"塊",而光纖通道稱為"傳輸字"。請參閱示例7-11,其中顯示了錯誤塊計數。當啟用FEC 且無法恢復比特錯誤時,該計數器會遞增。同樣,FEC 塊、FEC 幀和FEC 編解碼器指的是攜帶FEC 有效載荷和奇偶校驗位的同一實體。這些細節將在第2 章中解釋,此處不再贅述。
Link Utilization
例7-9 顯示了用于計算Cisco Nexus 9000 交換機和Cisco UCS 服務器上鏈路利用率的多個計數器。
接口速度
累計輸入和輸出字節
30 秒和5 分鐘的平均輸入和輸出率。這些值通過輸入和輸出字節累積值的差值(delta)計算,然后除以輪詢間隔。
Txload 和Rxload 就像百分比利用率。負載越高,鏈路利用率越高。255/255 的負載是100% 的利用率。負載和百分比利用率都是用吞吐量除以鏈路速度計算得出的。
大多數以太網端口都會報告類似的計數器。
審核編輯:劉清
-
以太網
+關注
關注
40文章
5441瀏覽量
172035 -
二進制
+關注
關注
2文章
795瀏覽量
41691 -
VLAN
+關注
關注
1文章
279瀏覽量
35698 -
PFC
+關注
關注
47文章
974瀏覽量
106171 -
存儲網絡
+關注
關注
0文章
31瀏覽量
8125
原文標題:以太網存儲網絡的擁塞管理連載(三)
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
以太網存儲網絡的擁塞管理連載方案(一)
以太網存儲網絡的擁塞管理連載方案(二)
以太網存儲網絡的擁塞管理連載案例(六)

工業以太網的實現方案和現場實際應用情況
基于BOOTP的工業以太網IP儀表的智能化管理策略

Silabs以太網方案






 工商網監
工商網監
評論