

到2034年高密度邏輯晶體管密度將從今天的283MTx/mm2增加到757MTx/mm2。 在 2024 年 SEMI 國(guó)際戰(zhàn)略研討會(huì)上,筆者從技術(shù)、經(jīng)濟(jì)和可持續(xù)發(fā)展的角度審視十年后邏輯電路將走向何方。 為了理解邏輯電路,筆者相信了解前沿邏輯器件的構(gòu)成是有用的。TechInsights 提供了詳細(xì)的封裝分析報(bào)告,筆者為 10 種 7 納米和 5 納米級(jí)設(shè)備做了報(bào)告,包括英特爾和 AMD 微處理器、蘋果A系列和M系列處理器,NVIDIA GPU和其他設(shè)備。圖 1 說(shuō)明了芯片區(qū)域的構(gòu)成。
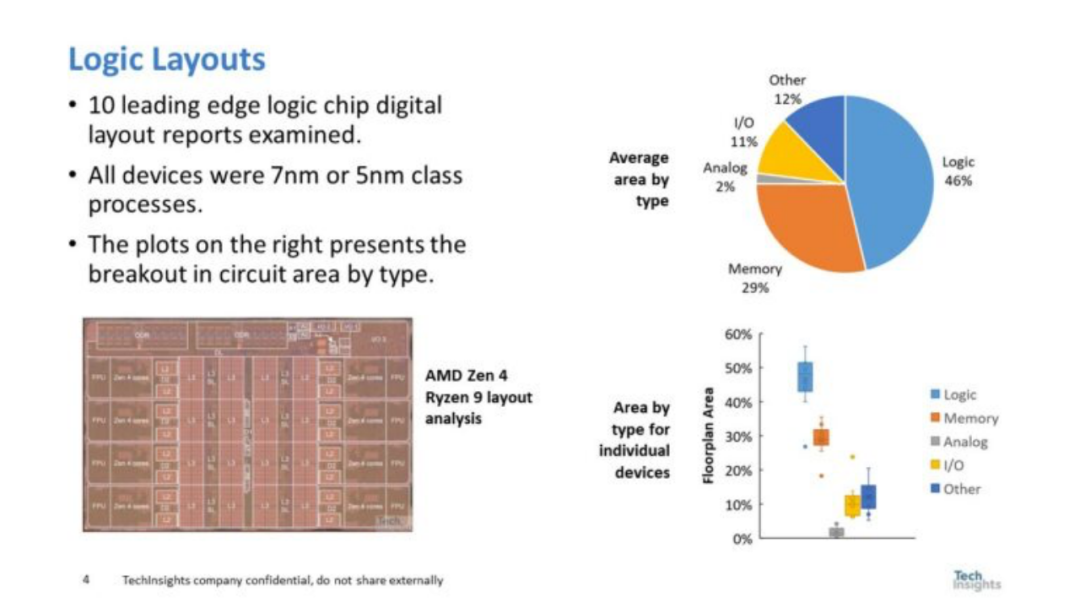
圖 1. 邏輯布局
從圖 1 中可以看出,邏輯部分占芯片面積略小于二分之一,內(nèi)存部分略小于芯片面積的三分之一,而 I/O、模擬和其他部分則占平衡。有趣的是,實(shí)際測(cè)量的 SRAM 內(nèi)存面積比筆者通常聽到人們談?wù)摰钠舷到y(tǒng) (SOC) 產(chǎn)品的百分比要小得多。 單一邏輯幾乎占據(jù)了芯片面積的一半,所以從邏輯部分開始設(shè)計(jì)是有意義的。邏輯設(shè)計(jì)是使用標(biāo)準(zhǔn)單元完成的,圖 2 是標(biāo)準(zhǔn)單元的平面圖。
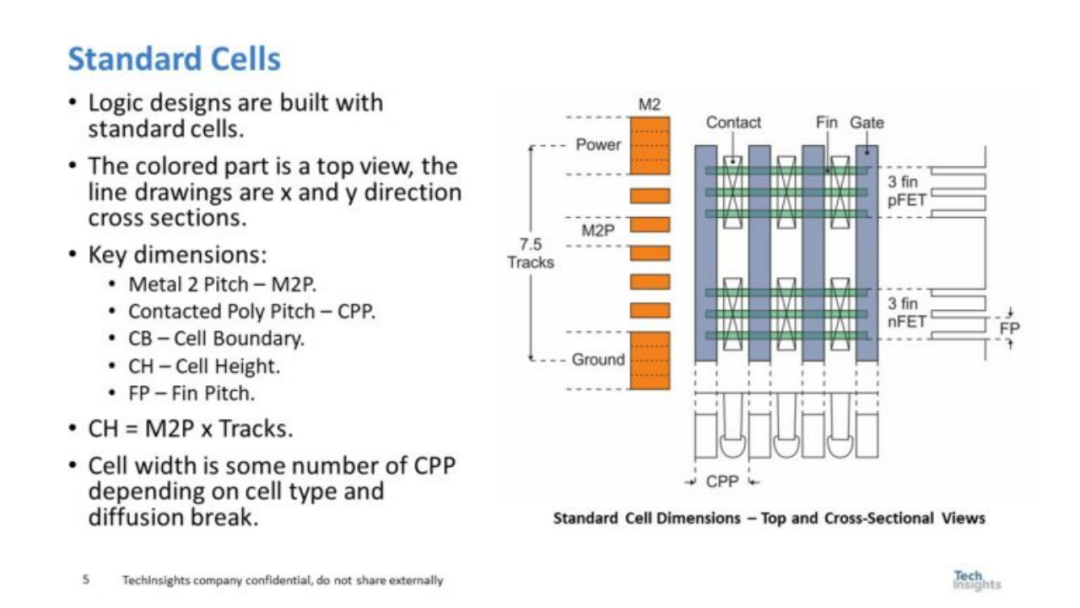
圖 2. 標(biāo)準(zhǔn)單元
標(biāo)準(zhǔn)單元的高度通常被描述為Metal 2 Pitch(M2P)乘以磁道數(shù),但從圖的右側(cè)看,器件結(jié)構(gòu)的橫截面圖也必須與單元高度相匹配并受到設(shè)備物理的限制。依賴于接觸多晶硅間距(CPP)的單元寬度也是如此,并且在圖的底部可以看到再次受到物理約束的器件結(jié)構(gòu)的橫截面視圖。 圖 3 顯示了確定單元寬度和單元高度縮放實(shí)際限制的分析結(jié)果。筆者有一個(gè)演示文稿詳細(xì)介紹了縮放限制,在該演示文稿中,圖 2 和圖 3 之間有數(shù)十張幻燈片,但由于時(shí)間有限,筆者只能展示結(jié)論。

圖 3. 邏輯單元縮放
單元寬度縮放取決于 CPP,圖的左側(cè)說(shuō)明了 CPP 如何由柵極長(zhǎng)度 (Lg)、接觸寬度 (Wc) 和兩個(gè)接觸到柵極間隔物厚度 (Tsp) 組成。Lg 受泄漏限制,可接受泄漏的最小 Lg 取決于器件類型。具有控制無(wú)約束厚度溝道表面的單柵的平面器件被限制在大約30 nm。Fin FET和水平納米片(HNS)約束溝道厚度(~5nm),分別有3個(gè)和4個(gè)柵極。最后,二維材料引入小于 1nm 溝道厚度的非硅材料,并且可以生產(chǎn)低至約 5 nm 的 Lg。由于寄生效應(yīng),Wc 和 Tsp 的擴(kuò)展能力都有限。最重要的是,2D 器件可能會(huì)產(chǎn)生約 30 納米的 CPP,而當(dāng)今的 CPP 約為 50 納米。 圖的右側(cè)示出了單元高度縮放。HNS提供單納米片疊層代替多個(gè)鰭片。然后演變到具有CFET的堆疊器件消除了水平n-p間距,并堆疊nFet和pFET。目前150nm至200nm的電池高度可降低至約50nm。 CPP 和單元高度縮放的結(jié)合可以產(chǎn)生每平方毫米約 15 億個(gè)晶體管 (MTx/mm2) 的晶體管密度,而當(dāng)今的晶體管密度<300MTx/mm2。應(yīng)該指出的是,2D 材料可能是 2030 年中后期的技術(shù),因此 1,500 MTx/mm2不在此處討論的時(shí)間范圍內(nèi)。
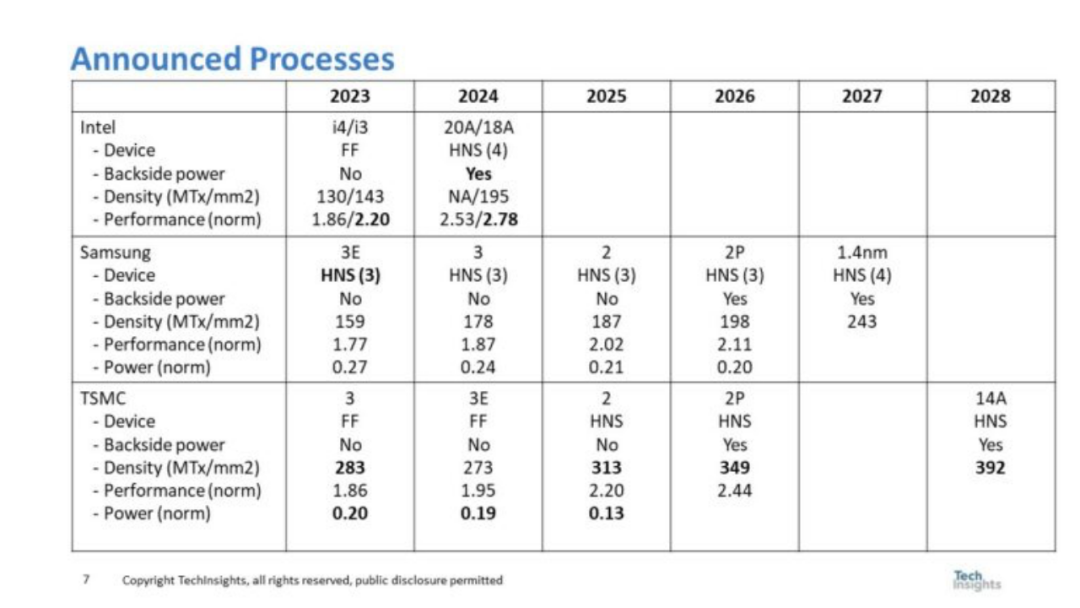
圖 4. 三大巨頭公布的流程
圖 4 總結(jié)了英特爾、三星和臺(tái)積電宣布的工藝進(jìn)程。對(duì)于每個(gè)公司和年份,都會(huì)顯示設(shè)備類型、是否使用背面電源、密度、功率和性能(如果有)。 在圖 4 中,領(lǐng)先的性能和技術(shù)創(chuàng)新以粗體突出顯示。三星是第一個(gè)在2023年投產(chǎn)HNS的公司,而英特爾直到2024年才會(huì)推出HNS,臺(tái)積電直到2025年才會(huì)推出。英特爾是第一個(gè)在2024年將背面電源引入生產(chǎn)的公司,三星和臺(tái)積電要到2026年才會(huì)引入背面電源。 筆者的分析得出結(jié)論,英特爾是i3的性能領(lǐng)先者,并維持這一狀態(tài)所示期間,臺(tái)積電有功率領(lǐng)先(英特爾數(shù)據(jù)不可用)和密度領(lǐng)先。
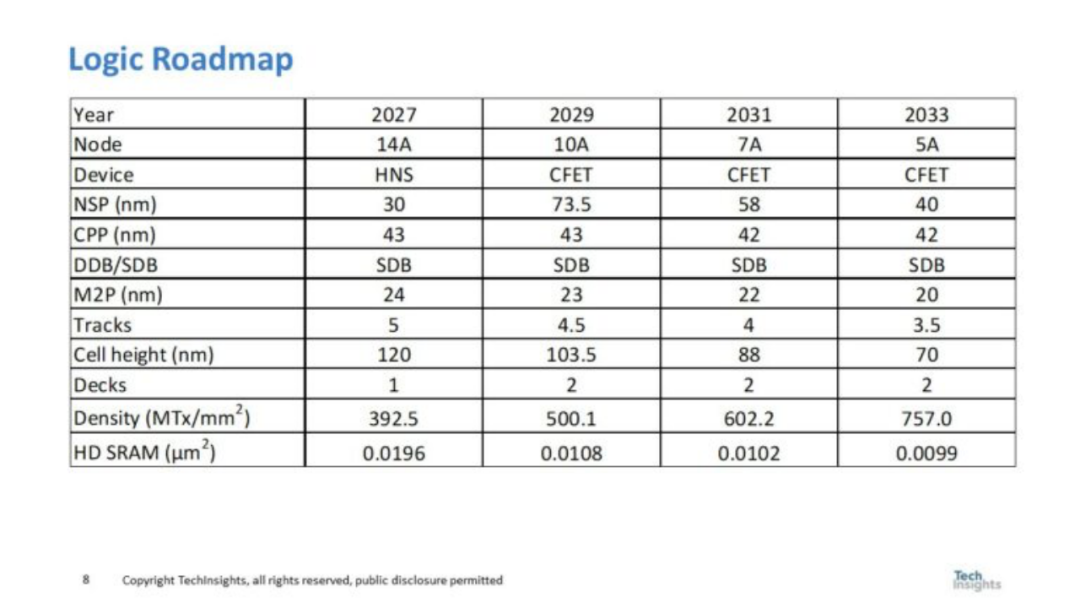
圖 5. 邏輯路線圖
圖 5 展示了邏輯路線圖,并包括預(yù)計(jì)的 SRAM 單元尺寸。從圖 5 中,筆者預(yù)計(jì) CFET 將在 2029 年左右推出,從而提高邏輯密度,并將 SRAM 單元尺寸縮小近一半(SRAM單元尺寸的縮放幾乎停止在前沿)。筆者預(yù)計(jì)到 2034 年邏輯密度將達(dá)到757MTx/mm2。 邏輯晶體管密度預(yù)測(cè)和 SRAM 晶體管密度預(yù)測(cè)如圖 6 所示。
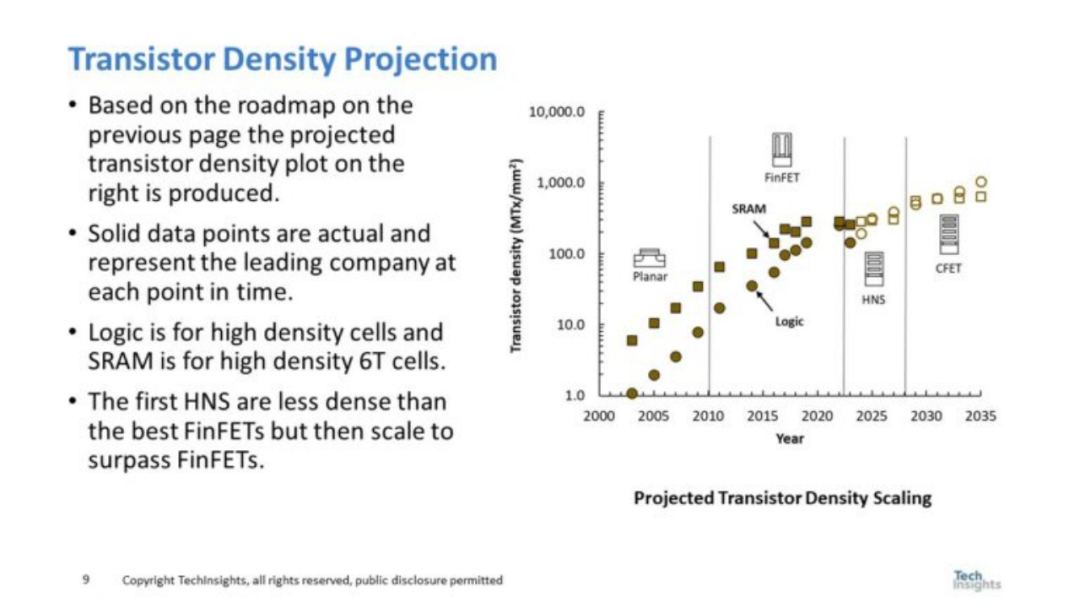
圖 6. 晶體管密度預(yù)測(cè)
邏輯和SRAM的晶體管密度縮放都在變慢,但更大程度上SRAM和邏輯現(xiàn)在具有相似的晶體管密度。 圖7 總結(jié)了臺(tái)積電邏輯和 SRAM 相比的模擬縮放數(shù)據(jù)。模擬和 I/O 縮放也都比邏輯縮放慢。
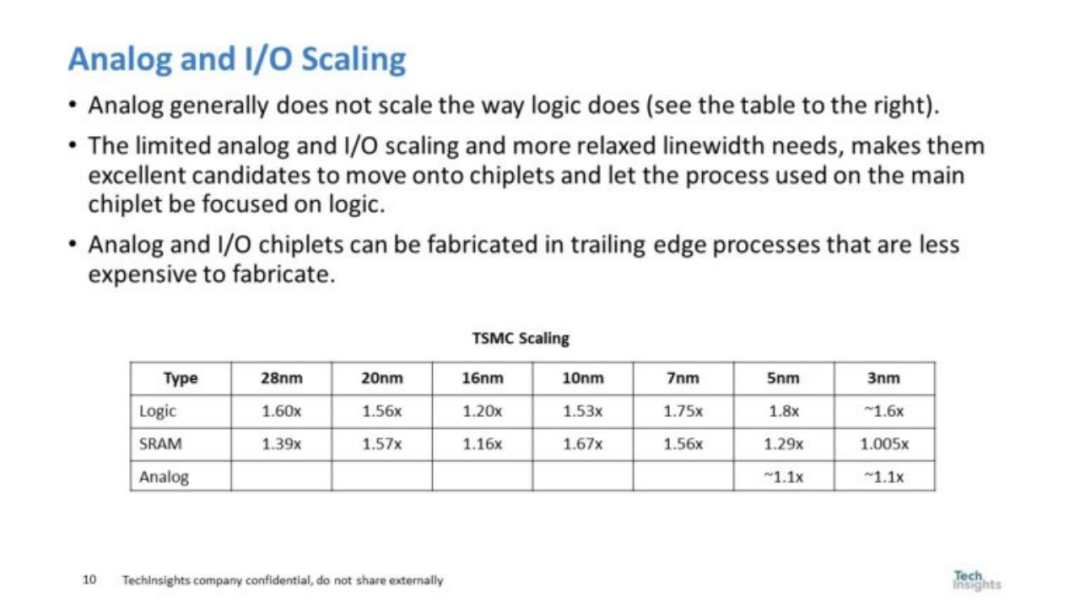
圖 7. 模擬和 I/O 縮放
對(duì)于較慢的 SRAM 以及模擬和 I/O 擴(kuò)展,一個(gè)可能的解決方案是小芯片。小芯片可以實(shí)現(xiàn)更便宜、更優(yōu)化的工藝來(lái)制造 SRAM 和 I/O。
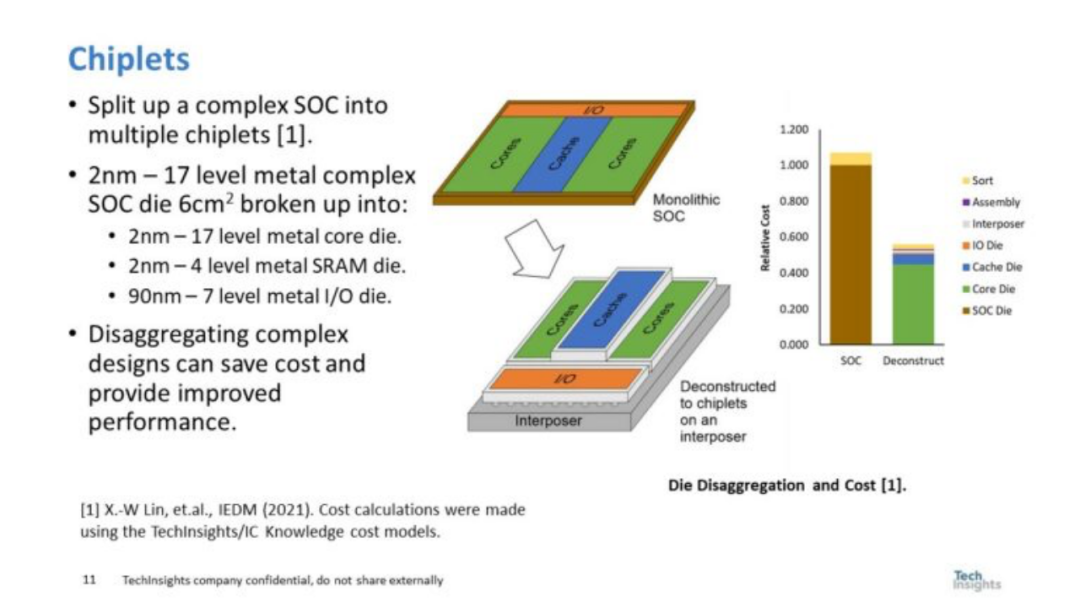
圖 8. 小芯片
圖8右側(cè)的圖形來(lái)自2021年我與Synopsys合作撰寫的一篇論文。我們的結(jié)論是,即使考慮到增加的封裝/組裝成本,將大型SOC分解成小芯片也可以將成本降低一半。
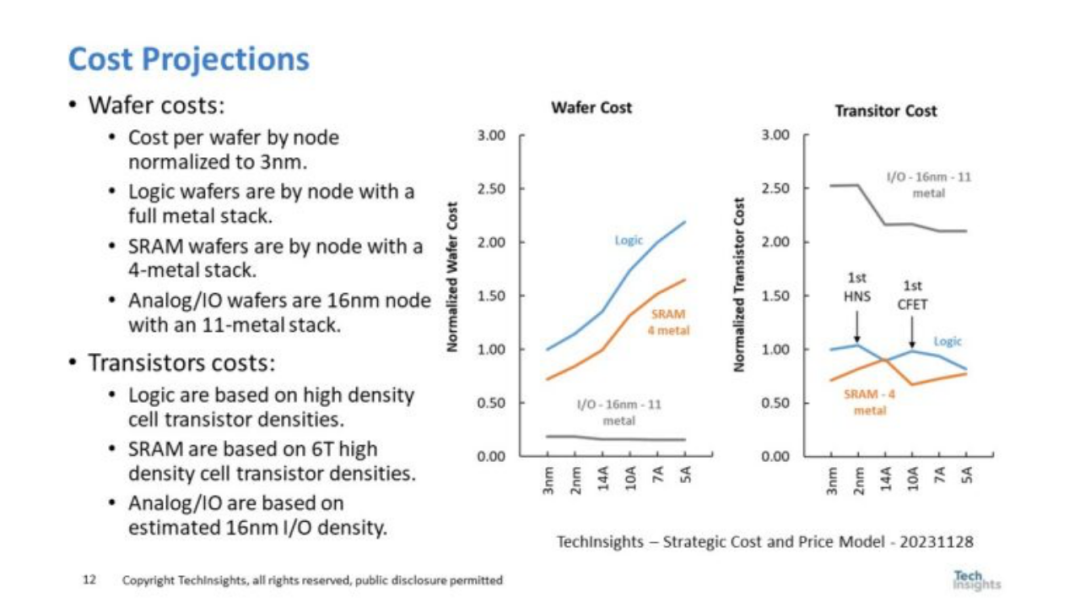
圖 9. 成本預(yù)測(cè)
圖 9 顯示了邏輯、SRAM 和 I/O 的標(biāo)準(zhǔn)化晶圓和晶體管成本。右圖顯示了標(biāo)準(zhǔn)化晶圓成本。邏輯晶圓成本針對(duì)金屬層數(shù)量不斷增加的全金屬堆棧。SRAM 晶圓具有相同的節(jié)點(diǎn),但由于 SRAM 的布局更為規(guī)則,因此僅限于 4 個(gè)金屬層。I/O晶圓成本基于16nm-11金屬工藝。筆者選擇 16nm 來(lái)獲得成本最低的 FinFET 節(jié)點(diǎn),以確保足夠的 I/O 性能。 右圖是晶圓成本換算成晶體管成本。有趣的是,I/O 晶體管非常大,即使在低成本 16nm 晶圓上,它們的成本也是最高的(I/O 晶體管尺寸基于 TechInsights 對(duì)實(shí)際 I/O 晶體管的測(cè)量)。 邏輯晶體管成本在 2nm 處上升,這是第一個(gè)臺(tái)積電 HNS 片節(jié)點(diǎn),其收縮幅度不大。我們預(yù)計(jì)第二代 HNS 節(jié)點(diǎn)在 14A 時(shí)的收縮會(huì)更大((這與臺(tái)積電第一個(gè)FinFET節(jié)點(diǎn)類似)。同樣,第一個(gè)CFET節(jié)點(diǎn)的成本也增加了一個(gè)節(jié)點(diǎn)的晶體管成本。除了一次性 CFET 縮小之外,由于縮小有限,SRAM 晶體管成本呈上升趨勢(shì)。該分析的底線是,盡管 Chiplet 可以提供一次性的好處,但晶體管成本的降低幅度將會(huì)不大。

圖10 結(jié)論
總之,筆者預(yù)測(cè),到2034年高密度邏輯晶體管密度將從今天的283MTx/mm2增加到757MTx/mm2。由于CFET的變化,SRAM單元尺寸將從今天的0.0209um2縮小到0.0099um2。邏輯晶體管成本將降至0.82x,SRAM將增加到1.09x,L/0將增加到目前成本的0.83倍。
芯片巨頭們已著手研發(fā)下一代CFET技術(shù) 英特爾(Intel) 和臺(tái)積電將在國(guó)際電子元件會(huì)議(IEDM) 公布垂直堆疊式(CFET) 場(chǎng)效晶體管進(jìn)展,使CFET 成為十年內(nèi)最可能接替閘極全環(huán)電晶(GAA ) 晶體管的下一代先進(jìn)制程。 英特爾的 GAA 設(shè)計(jì)堆疊式 CFET 晶體管架構(gòu)是在 imec 的幫助下開發(fā)的,設(shè)計(jì)旨在增加晶體管密度,通過(guò)將 n 和 p 兩種 MOS 器件相互堆疊在一起,并允許堆疊 8 個(gè)納米片(RibbonFET 使用的 4 個(gè)納米片的兩倍)來(lái)實(shí)現(xiàn)更高的密度。目前,英特爾正在研究?jī)煞N類型的 CFET,包括單片式和順序式,但尚未確定最終采用哪一種,或者是否還會(huì)有其他類型的設(shè)計(jì)出現(xiàn),未來(lái)應(yīng)該會(huì)有更多細(xì)節(jié)信息公布。
此前在 2021 年的“英特爾加速創(chuàng)新:制程工藝和封裝技術(shù)線上發(fā)布會(huì)”上,英特爾已經(jīng)確認(rèn)了 RibbonFET 將成歷史,在其 20A 工藝上,將引入采用 Gate All Around(GAA)設(shè)計(jì)的 RibbonFET 晶體管架構(gòu),以取代自 2011 年推出的 FinFET 晶體管架構(gòu)。新技術(shù)將加快了晶體管開關(guān)速度,同時(shí)實(shí)現(xiàn)與多鰭結(jié)構(gòu)相同的驅(qū)動(dòng)電流,但占用的空間更小。 雖然,大多數(shù)早期研究以學(xué)術(shù)界為主,但英特爾和臺(tái)積電等半導(dǎo)體企業(yè)現(xiàn)在已經(jīng)開始這一領(lǐng)域的研發(fā),借此積極探索這種下一代先進(jìn)晶體管技術(shù)。
審核編輯:黃飛
-
amd
+關(guān)注
關(guān)注
25文章
5532瀏覽量
135328 -
邏輯電路
+關(guān)注
關(guān)注
13文章
499瀏覽量
42992 -
sram
+關(guān)注
關(guān)注
6文章
778瀏覽量
115385 -
微處理器
+關(guān)注
關(guān)注
11文章
2329瀏覽量
83376 -
晶體管
+關(guān)注
關(guān)注
77文章
9882瀏覽量
139866
原文標(biāo)題:10張圖,看未來(lái)十年邏輯電路將走向何方
文章出處:【微信號(hào):ICViews,微信公眾號(hào):半導(dǎo)體產(chǎn)業(yè)縱橫】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
變阻器的未來(lái)發(fā)展趨勢(shì)和前景如何?是否有替代品出現(xiàn)?
工業(yè)電機(jī)行業(yè)現(xiàn)狀及未來(lái)發(fā)展趨勢(shì)分析
開關(guān)電源發(fā)展趨勢(shì)及發(fā)展前景
您看好電動(dòng)汽車的未來(lái)發(fā)展趨勢(shì)嗎?
藍(lán)牙技術(shù)未來(lái)的發(fā)展趨勢(shì)
盾構(gòu)未來(lái)發(fā)展趨勢(shì)和展望
靈動(dòng)微對(duì)于未來(lái)MCU發(fā)展趨勢(shì)分析
自動(dòng)化測(cè)試技術(shù)發(fā)展趨勢(shì)展望分析,不看肯定后悔
蜂窩手機(jī)音頻架構(gòu)的未來(lái)發(fā)展趨勢(shì)是什么
未來(lái)PLC的發(fā)展趨勢(shì)將會(huì)如何?
消費(fèi)升級(jí)下摩托車TBOX市場(chǎng)未來(lái)十年CAN數(shù)據(jù)應(yīng)用發(fā)展趨勢(shì)展望
展望未來(lái)十年 信通院發(fā)布ICT深度觀察十大趨勢(shì)
DC電源模塊的發(fā)展趨勢(shì)和前景展望






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論