") 如何提高Simulink仿真性能呢?有哪些使用技巧?
如何提高Simulink仿真性能呢?有哪些使用技巧?
無論模型的復(fù)雜程度如何,每個 Simulink 用戶都希望提高仿真性能。本文介紹了許多實用技巧和技術(shù),來幫助您在仿真工作流中獲得最佳的性能。
提高仿真性能的第一步
您首先需要查看您的仿真工作流,搞清楚針對模型所需要運行的編輯、初始化和仿真的次數(shù)。例如,以下四種常見工作流具有非常不同的特征。仿真模式和性能選項的最佳選擇將取決于您正在使用的這四個工作流中的哪一個。 第一個工作流是“編輯-更新-重復(fù)”(圖1)。當(dāng)您按 Ctrl+D 以確保模型更新時,這個工作流是典型的,但您還沒有準(zhǔn)備好進行仿真驗證;當(dāng)您對模型進行大量修改時,此工作流是典型的。
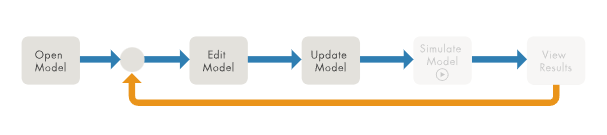
圖1:“編輯-更新-重復(fù)”工作流 第二個工作流是“編輯-仿真-重復(fù)”工作流,它需要每次編輯結(jié)構(gòu)并初始化模型(圖2)。
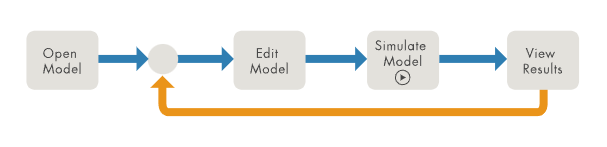
圖2:“編輯-仿真-重復(fù)”工作流 第三個工作流是“調(diào)參-仿真-重復(fù)”(圖3)。它關(guān)注于一些參數(shù)的迭代調(diào)優(yōu),不需要編輯模型結(jié)構(gòu)。
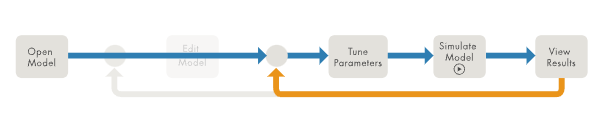
圖3:“調(diào)參-仿真-重復(fù)”工作流 第四個工作流是 multisim 工作流(圖4)。通常是跑那些驗證過的模型的仿真,其中分擔(dān)執(zhí)行將有所幫助【譯者注:如利用多核并行】
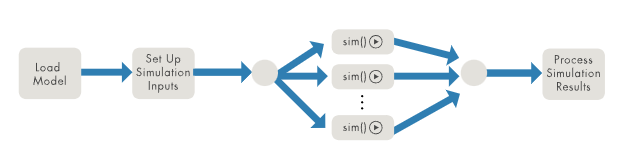
圖4:multisim 工作流
影響我們選擇性能解決方案的另一個因素是仿真的哪個階段在總耗時中占主導(dǎo)地位。您可以在 Simulink 中返回的 SimulationMetadata 對象中使用計時信息。SimulationOutput 對象,以查看初始化或執(zhí)行所占用的總時間的比例。例如,在下面的例子中,我們可以說這個模型的性能是由執(zhí)行時間決定的,所以我們應(yīng)該關(guān)注性能解決方案來加速模型的執(zhí)行,而不是初始化。 您可以查看在最常見的工作流中使用的模型的仿真元數(shù)據(jù),以進一步了解仿真屬性。
SimulationMetadata 對象包含關(guān)于仿真運行的信息,包括模型信息、定時信息和執(zhí)行信息等。你可以通過訪問 out.SimulationMetadata.TimingInfo 屬性來獲取計時信息。仿真元數(shù)據(jù)的計時信息示例如下:
WallClockTimestampStart: '2021-12-16 1015'
WallClockTimestampStop: '2021-12-16 1044'
InitializationElapsedWallTime: 0.6918
ExecutionElapsedWallTime: 87.8463
TerminationElapsedWallTime: 0.4087
TotalElapsedWallTime: 88.9468
ProfilerData: 'Profiler is not enabled'
根據(jù)您特定的仿真工作流程和模型特征(初始化時間與執(zhí)行時間等),您可以快速參考下面的表1來選擇并嘗試正確的技術(shù)。
| 編輯-更新-重復(fù) | 編輯-仿真-重復(fù) | 調(diào)參-仿真-重復(fù) | multisim | |
| 仿真模式 | x | x | x | |
| 快速啟動 | x | x | ||
| 仿真緩存 | x | x | x | x |
| 模型引用-并行編譯 | x | x | ||
| 模型引用-增量加載和重新編譯 | x | x | ||
| Simulink Profiler | x | x | x | x |
| Solver Profiler | x | x | x | |
| 修改你的模型 | x | x | x | |
| 并行仿真 |
x |
表1:提高仿真性能的典型技術(shù)。
選擇正確的仿真模式
Simulink 提供了三種仿真模式:普通、加速和快速加速(圖5)。顧名思義,加速通常比普通快,快速加速更快。速度的每一次提高通常都意味著犧牲靈活性、交互性和/或診斷性。在許多情況下,如果您可以在沒有這些功能的情況下工作(至少暫時如此),那么仿真速度將得到改善。
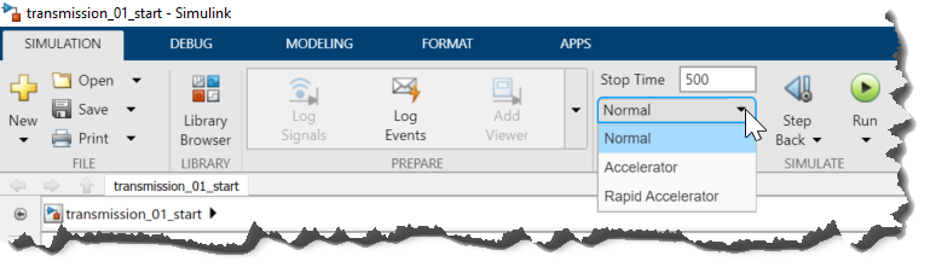
圖5:Simulink仿真模式
在正常模式下,Simulink 在每次仿真運行期間解釋您的模型。如果您經(jīng)常更改模型,這通常是首選的模式,因為它不需要像加速模式和快速加速模式那樣單獨的編譯步驟。
在加速模式下(Accelerator),Simulink 將模型編譯成內(nèi)存中的執(zhí)行引擎,從而消除了正常模式下塊到塊的解釋仿真的開銷。加速模式支持調(diào)試器和分析器,但只支持一組有限的運行時診斷。當(dāng)仿真時間比編譯時間長得多時,通常使用加速模式。
在快速加速模式(Rapid Accelerator)下,Simulink 將模型編譯為一個獨立的可執(zhí)行文件,它可以在單獨的進程中運行。只有當(dāng)整個模型能夠生成代碼時,才能使用快速加速模式。這種模式限制了仿真過程中與模型的交互。例如,快速加速模式不支持調(diào)試。
與加速模式一樣,當(dāng)您的仿真時間比一次性編譯時間長得多時,最好使用快速加速模式。 您可能想知道應(yīng)該為您的工作流選擇哪種模式。圖 6 顯示了假設(shè)模型仿真在普通、加速和快速加速模式下的性能。

圖6:一個假設(shè)模型在不同仿真模式下的性能
通常,當(dāng)您處于“開發(fā)”工作流中,您經(jīng)常修改模型并在修改之間執(zhí)行更新圖或簡短的仿真時,建議使用正常模式。相反,當(dāng)您希望運行多個仿真而不對模型進行結(jié)構(gòu)更改(例如添加或刪除塊)時,請使用快速加速模式。 如果您知道模型不會在運行之間被更改,您可以通過將 RapidAcceleratorUpToDateCheck 設(shè)置為“off”來指示 Simulink 跳過快速加速初始化。請記住,對不可調(diào)參數(shù)的更改將被忽略。如果您的模型遇到了阻止使用快速加速模式的限制,請使用加速模式代替。
當(dāng)加速模式對某些模型的好處大于其他模型時
有時,您可能會注意到某些模型比其他模型更受益于加速或快速加速模式。如果您的模型沒有看到很大的性能改進,則可能出現(xiàn)以下情況:
模型的算法主要包含在幾個復(fù)雜的塊中,例如快速傅立葉變換塊或查找表。小型模型在加速模式下可能運行較慢,因為本機塊是高度優(yōu)化的。相比之下,具有許多基本塊的模型更有可能從加速中受益。
您的模型包含大部分編譯代碼,例如來自 s 函數(shù),Stateflow 塊和 MATLAB functions 的代碼。使用編譯步驟不會進一步提高模型速度。
您的仿真運行包括初始化或終止階段。因為加速模式只在每次運行的仿真階段工作,如果它們需要耗時的初始化或終止階段,它們可能不會提供太大的改進。有關(guān)詳細信息,請參見本文的加速初始化階段一節(jié)。
您的模型包含無法編譯的塊,例如解釋執(zhí)行的 MATLAB Function 塊,或解釋模式下的 MATLAB 系統(tǒng)對象。
為仿真迭代啟用快速重啟
在典型的 Simulink 仿真工作流程中,當(dāng)您按下 Run 按鈕時,Simulink 將首先更新和編譯模型,然后仿真它。這個過程在以后的運行中重復(fù)。但是,如果您的仿真迭代只需要更改模型輸入或可調(diào)參數(shù),則通常不需要編輯模型結(jié)構(gòu)。對于這些工作流,初始化階段在第一次運行后通常是不必要的,并且在運行數(shù)百甚至數(shù)千次仿真時將迅速增加。 Simulink 提供了一個很好的功能,叫做快速重啟(Fast Restart)。顧名思義,它允許您通過只編譯一次模型來運行仿真迭代(圖7)。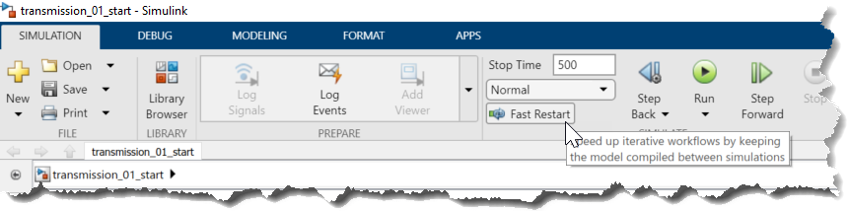
圖7:在 Simulink 中啟用快速重啟
啟用“Fast Restart快速重啟”后,模型不會在每次運行后自動終止。相反,使用保存的初始化信息為下一組仿真再次自動初始化模型,而無需重新編譯。 當(dāng)使用 Fast Restart 時,模型將被鎖定,并且您將無法編輯模型結(jié)構(gòu)。在仿真完成之前,這可以防止模型發(fā)生任何結(jié)構(gòu)變化。但是,您仍然可以更改可調(diào)參數(shù)或更改輸入信號,并查看它們對仿真的影響。 您可以從上面所示的工具欄和使用 sim 和 parsim 函數(shù)的編程仿真中打開快速重啟。
使用仿真工作點
工程師通常會針對不同的輸入、邊界條件和操作條件對 Simulink 模型進行仿真迭代。在許多情況下,這些仿真共享一個共同的啟動階段,在這個階段中,模型從初始狀態(tài)轉(zhuǎn)換到其他狀態(tài)。例如,在測試各種控制順序之前,可能會使電動機加速。
使用仿真工作點,您可以在啟動階段結(jié)束時保存仿真快照,然后將其恢復(fù)為將來仿真的初始狀態(tài)。這種技術(shù)本身并不能提高仿真速度,但是它可以減少連續(xù)運行的總仿真時間,因為啟動階段只需要仿真一次(參見下面的圖8)。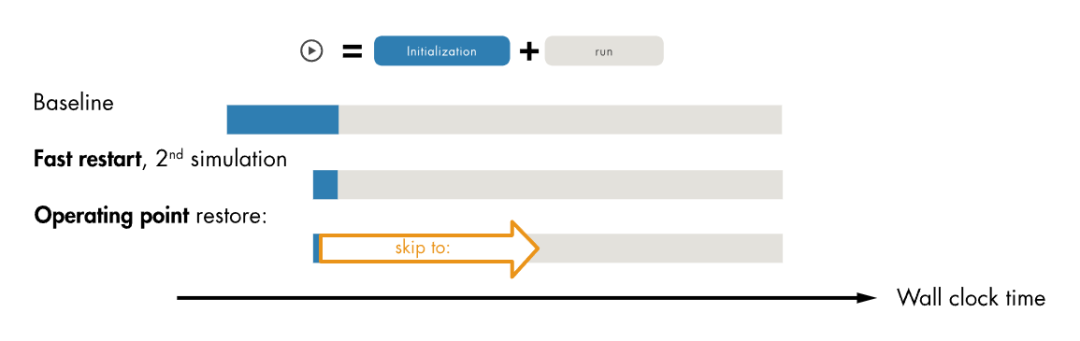
圖8:使用快速重啟和工作點恢復(fù)
并行運行多個仿真
通過使用 Simulink 和 Parallel Computing Toolbox 在多個處理核心之間分配仿真任務(wù),您可以減少運行多個獨立仿真所需的總時間。通過使用 MATLAB Parallel Server,您可以將仿真擴展到集群和云,從而進一步減少總體仿真時間。 并行運行仿真的常見用例包括蒙特卡羅分析、設(shè)計優(yōu)化和測試用例掃描。例如,您可以設(shè)置一個蒙特卡羅仿真,在該仿真中,您可以在預(yù)定范圍內(nèi)改變參數(shù)的值。
然后,您可以在多個核心上獨立并并行地對每個參數(shù)值執(zhí)行仿真。 您可以并行處理設(shè)計優(yōu)化中涉及的許多任務(wù),包括從測試數(shù)據(jù)中估計模型參數(shù)、調(diào)整控制器增益以獲得期望的響應(yīng)、優(yōu)化設(shè)計參數(shù)、執(zhí)行靈敏度分析和執(zhí)行魯棒性分析。總仿真時間隨著使用的處理器數(shù)量的增加而減少。
通常,關(guān)于如何設(shè)置并行多仿真運行,您有兩種選擇:Multiple Simulations 面板或調(diào)用 parsim 函數(shù)的腳本。您可以直接使用 Simulink 編輯器中的 Multiple simulation 面板設(shè)置和運行仿真(參見圖 9)。在 Multiple simulation 面板中,您可以為仿真指定塊參數(shù)和工作空間變量的值。通過選擇“使用并行”選項,您可以自動啟用仿真的并行執(zhí)行。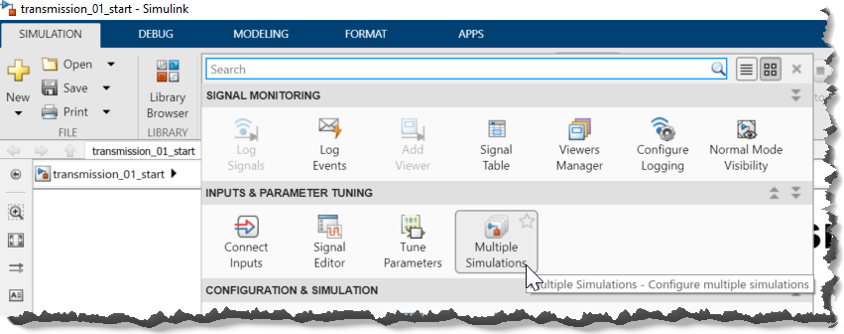
圖9:使用 multisim 面板啟動并行仿真 您還可以使用 parsim 構(gòu)造來使用 MATLAB 腳本啟動并行仿真。
使用模型引用和 Simulink 緩存
模型引用允許您使用模塊將一個模型包含在另一個模型中。這樣的每個實例都稱為模型引用。與子系統(tǒng)一樣,模型引用允許您組織大型模型層次結(jié)構(gòu)(圖10)。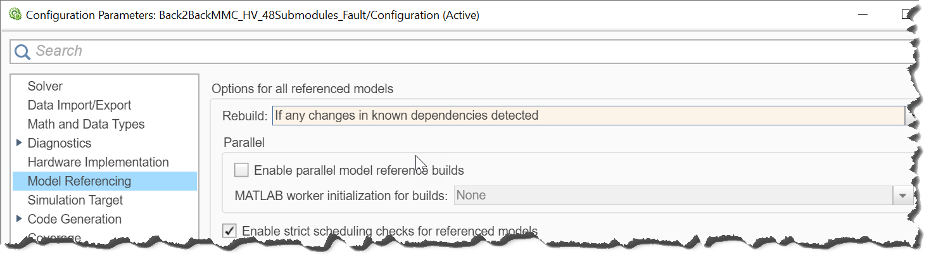
圖10:模型引用 rebuild 選項
使用模型引用有很多性能上的好處:
增量加載。被引用的模型只在需要時加載。
加速仿真。模型引用允許您將仿真的部分存儲在不同的模型文件中。如果仿真的大部分沒有改變,可以將其放在加速器模式下的模型引用中。該部分第一次只編譯一次,并在后續(xù)運行中更快地初始化和仿真。
增量 rebuild。如果選擇的模型引用 Rebuild 選項是“如果檢測到已知依賴項中的任何更改”,則實現(xiàn)這些引用模型的仿真目標(biāo)不會在每次運行仿真時生成,而只會在引用模型和/或其任何依賴項或接口更改時重新生成。此選項比選擇“如果檢測到任何更改”選項要快,因為它跳過了計算模型校驗和的步驟。如果您確定在仿真過程中模型結(jié)構(gòu)沒有改變,則可以將 Rebuild 選項設(shè)置為“Never”以進一步加速該過程。
并行編譯。對于包含大型模型引用層次結(jié)構(gòu)的模型,您可以通過并行編譯引用模型來減少代碼生成和編譯時間。使用并行計算工具箱或 MATLAB 并行服務(wù)器,您可以在您的配置中跨多個 MATLAB worker 分發(fā)代碼生成和編譯任務(wù)。
模型引用通常在團隊環(huán)境中使用,在這種環(huán)境中,您可以基于其他人構(gòu)建的組件運行仿真。對于層次結(jié)構(gòu)中的每個模型,Simulink 可以將這些構(gòu)建的工件打包到具有. slxc 擴展名的單個 Simulink 緩存文件中(圖11)。
圖11:Simulink緩存文件
對于 Simulink 緩存文件,只要將 Rebuild 配置參數(shù)設(shè)置為“如果檢測到任何更改(默認)”或“如果檢測到已知依賴項的任何更改”,Simulink 只編譯過期的文件。您和您的團隊成員可以彼此共享這些 SLXC 文件和相應(yīng)的 Simulink 模型文件。 當(dāng)您在機器上運行仿真時,Simulink 將從每個模型的 SLXC 文件中提取必要的派生文件。
因此,Simulink 不需要執(zhí)行不必要的重新編譯,并更快地完成仿真。 另外,Simulink 緩存文件適用于多種類型的編譯工件,這些工件可能不是模型引用仿真目標(biāo)(例如,快速加速器目標(biāo))。共享這些 Simulink 緩存文件可以顯著降低基于團隊的工作流中的重新編譯成本。
分析模型的仿真瓶頸
在 Simulink 中有內(nèi)置的功能,可以幫助您系統(tǒng)地理解模型,識別仿真性能瓶頸,并提高仿真速度。
Performance Advisor
Performance Advisor可以與Simulink Profiler和Solver Profiler一起從debug選項卡啟動(圖12)。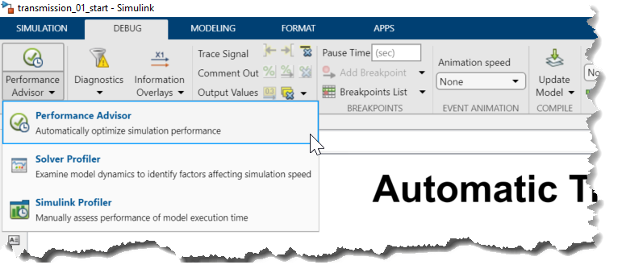
圖12:啟動 Performance Advisor
Performance Advisor 分析模型,并對可能導(dǎo)致仿真性能低下的條件和配置設(shè)置進行不同的檢查。Performance Advisor 提供了關(guān)于更好的模型配置設(shè)置的建議,以及自動或手動修復(fù)問題的機制。 一旦將建議的更改應(yīng)用到您的模型中,Performance Advisor 就可以驗證在提高性能方面發(fā)揮了多大作用(圖13)。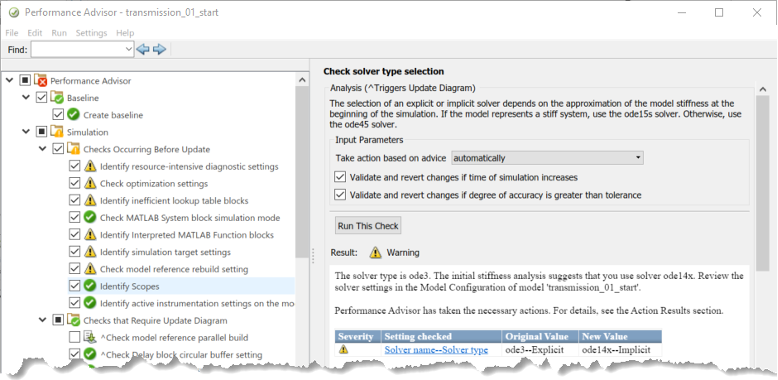
圖13:Simulink Performance Advisor
Simulink Profiler
在Simulink中,有兩種類型的分析器可以用來對仿真速度慢的模型進行分析。如果您不確定使用哪一個,請參考圖14快速入門。Simulink Profiler用于確定哪些塊占用最多的仿真時間;Solver Profiler分析了變步求解器執(zhí)行某些步驟的原因。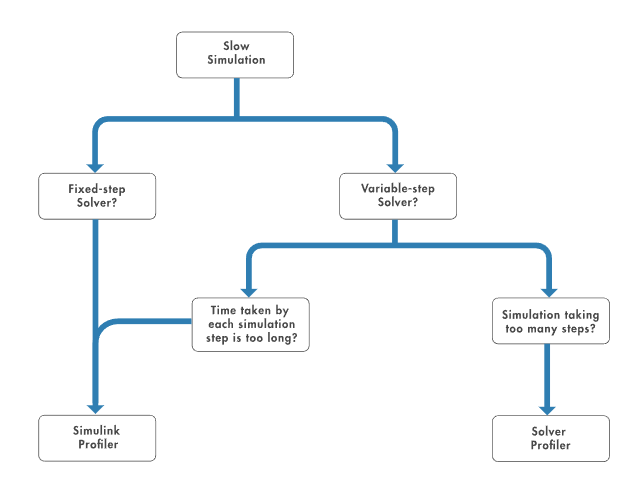
圖14:使用 Simulink Profiler 和 Solver Profiler
Simulink Profiler 允許您量化仿真的每個階段需要多少時間以及每個塊需要多少時間來仿真。在設(shè)計階段,Simulink Profiler 通常與正常模式一起使用,以便您可以檢查每個塊的時間成本。
使用 Simulink Profiler 可以生成大量的數(shù)據(jù)。為了盡量減少需要檢查的數(shù)據(jù)量,請關(guān)注那些花費最多時間和最頻繁調(diào)用的方法。
Simulink Profiler 識別仿真速度慢的緣由,以便您可以手動評估仿真執(zhí)行時間的性能。您還可以用輕量級塊替換計算量最大的塊,以加速仿真(圖15)。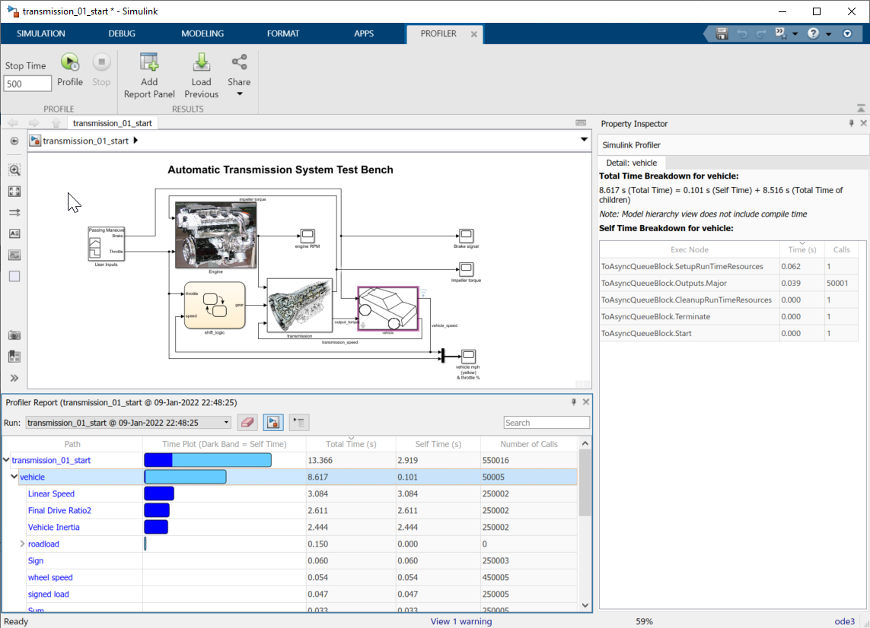
圖15:Simulink Profiler
Solver Profiler
當(dāng)使用可變步長求解器模型仿真的速度變慢、需要太多小步長或停止響應(yīng)時,Solver Profiler 可以幫助您理解求解器的行為并識別影響仿真速度的因素。 多種因素會影響求解器的行為并限制仿真速度。Solver Profiler 記錄并報告模型仿真時發(fā)生的所有主要事件:
討論二階導(dǎo)數(shù)過零事件
求解器異常事件
解算器重置事件
雅可比矩陣計算事件
如果您的模型包含 Simscape 塊,您還可以使用 Simscape Results Explore 查看這些塊的各種物理量。
Solver Profiler 顯示有關(guān)仿真、求解器設(shè)置、事件和錯誤的圖形和統(tǒng)計信息。您可以使用這些數(shù)據(jù)來識別模型中導(dǎo)致仿真瓶頸的位置,并采取措施,例如更新系統(tǒng)的剛度以獲得更好的仿真性能。
Solver Profiler 通常與可變步長求解器一起使用,以幫助解釋為什么你的仿真需要太多步或為什么一個步長如此之小。另一方面,如果您關(guān)注的是為什么每個仿真步需要很長時間才能完成,或者如果您使用的是固定步長求解器,那么在前一節(jié)中討論的Simulink Profiler就是適合的工具(圖16)。
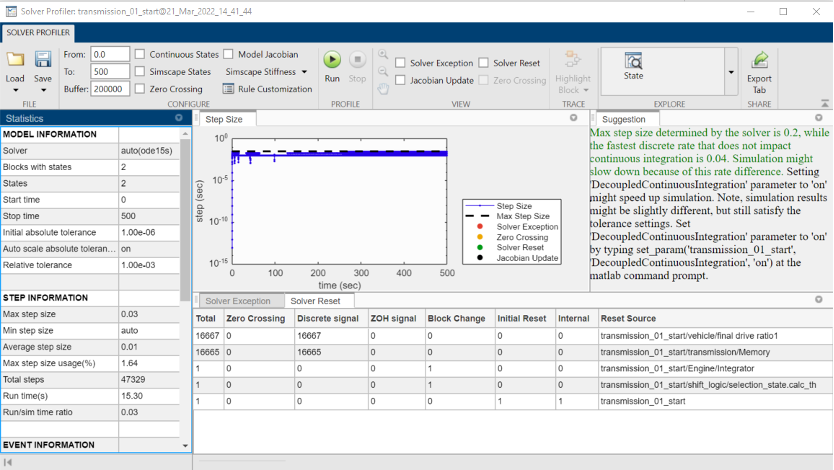
圖16:Solver Profiler
修改和簡化你的模型
到目前為止描述的大多數(shù)技術(shù)只需要對模型本身進行很少的更改(如果有的話)。您可以通過應(yīng)用涉及對模型進行修改的技術(shù)來實現(xiàn)額外的性能提升。
加速初始化階段
當(dāng)您更新或打開模型時,Simulink 將運行掩碼初始化代碼。如果您有復(fù)雜的掩碼初始化命令,其中包含許多對 set_param 的調(diào)用,請考慮將對 set_param() 的連續(xù)調(diào)用合并為具有多個參數(shù)對的單個調(diào)用。這可以減少與這些調(diào)用相關(guān)的開銷。
如果您使用 MATLAB 腳本來加載和初始化數(shù)據(jù),您通常可以通過加載 mat 文件來提高性能。缺點是 mat 文件中的數(shù)據(jù)不是人類可讀的形式,因此可能比腳本更難處理。但是,加載通常比等效腳本更快地初始化數(shù)據(jù)。 進一步了解:
數(shù)據(jù)導(dǎo)入和導(dǎo)出:https://ww2.mathworks.cn/help/matlab/data-import-and-export.html
降低模型復(fù)雜度
在不犧牲保真度的情況下簡化模型是提高仿真性能的有效方法。以下是降低模型復(fù)雜性的三種方法。
用較低保真度的替代方案替換子系統(tǒng)。
在許多情況下,您可以通過使用以下方法之一替換復(fù)雜的子系統(tǒng)模型來簡化您的模型:
使用系統(tǒng)識別工具箱從測量的輸入輸出數(shù)據(jù)創(chuàng)建的線性或非線性動態(tài)模型
使用基于模型的標(biāo)定工具箱創(chuàng)建的高保真非線性統(tǒng)計模型
使用 Simulink Control Design 創(chuàng)建的線性模型
查找表
您可以在庫中維護子系統(tǒng)的兩種表示,并使用不同的子系統(tǒng)來管理它們。
減少塊的數(shù)量。
當(dāng)您減少模型中的塊數(shù)量時,在仿真期間需要更新的塊就會更少,從而得到更快的仿真運行。向量化是減少塊計數(shù)的一種方法。例如,如果您有幾個并行信號,它們經(jīng)歷了類似的一組計算,請嘗試將它們組合成一個向量并執(zhí)行單個計算。另一種方法是在配置參數(shù)的 optimization > General 部分中啟用 Block Reduction 優(yōu)化。
使用基于幀的處理。
在基于幀的處理中,樣品是分批處理的,而不是一次處理一個。例如,如果您的模型包含模數(shù)轉(zhuǎn)換器,則可以在緩沖區(qū)中收集輸出樣本,并通過單一操作(例如快速傅立葉變換)處理緩沖區(qū)。以這種方式處理數(shù)據(jù)塊可以減少必須調(diào)用模型中的塊的次數(shù)。通常,調(diào)度開銷隨著幀大小的增加而減少。然而,更大的幀會消耗更多的內(nèi)存,并且內(nèi)存限制會對復(fù)雜模型的性能產(chǎn)生不利影響。嘗試不同的幀大小,以找到一個最大限度地提高基于幀的處理的性能優(yōu)勢,而不會導(dǎo)致內(nèi)存問題。
減少交互
一般來說,模型的互動性越強,仿真所需的時間就越長。本節(jié)中的技巧說明了通過放棄一些交互性來提高性能的方法。
關(guān)閉調(diào)試診斷開關(guān)。
有些啟用了診斷功能的模型仿真速度明顯較慢。您可以在“配置參數(shù)”對話框的“診斷”窗格中禁用它們。 注意:array bounds exceeded 與 solver data inconsistency 診斷項可能會導(dǎo)致模型運行時性能明顯降低。
禁用仿真動畫。
默認情況下,Stateflow chart 突出顯示當(dāng)前的活動狀態(tài),并將模型運行時發(fā)生的狀態(tài)轉(zhuǎn)換動畫化。這個特性對調(diào)試很有用,但它會減慢仿真速度。要加速仿真,請關(guān)閉所有 Stateflow chart 或禁用動畫。同樣,如果您正在使用 Simulink 3D Animation、SimMechanics 可視化、FlightGear 或其他 3D 動畫包,請考慮禁用動畫或降低場景保真度以提高性能【譯者注:尤其是 3D 動畫,一定要開著的話,最好得有一塊性能還過得去的獨立顯卡】。
調(diào)整特定于查看器的參數(shù),并通過啟用的子系統(tǒng)管理查看器。
如果您的模型包含一個顯示大量數(shù)據(jù)點的示波器查看器,并且您無法消除示波器,請嘗試調(diào)整查看器參數(shù)從而在速度與保真度之間折衷。但是,請注意,通過使用抽取來減少繪制的數(shù)據(jù)點的數(shù)量,您可能會錯過短暫的瞬變和其他現(xiàn)象,這些現(xiàn)象在使用更多數(shù)據(jù)點時可能會很明顯。您可以將查看器放置在已啟用的子系統(tǒng)中,以更精確地控制啟用哪些可視化以及何時啟用。
使用 MATLAB functions 代替解釋執(zhí)行的 MATLAB Function 塊
要在 Simulink 模型中調(diào)用 MATLAB 函數(shù),請使用 MATLAB functions 而不是解釋的 MATLAB Function 塊或 MATLAB S-function。MATLAB function 是更快的選擇。它支持生成可嵌入的 C 代碼。雖然 MATLAB function 不支持所有 MATLAB 函數(shù),但它所支持的 MATLAB 語言子集是廣泛的。 要快速找到模型中的所有解釋執(zhí)行的 MATLAB Function 塊,請使用 Performance Advisor。
你記錄大量的數(shù)據(jù)集。當(dāng)記錄大量數(shù)據(jù)時(例如,在包括 To Workspace、To File 或 Scope 塊的模型中),使用抽取或?qū)⒂涗浀妮敵鱿拗茷榉抡娴淖詈笠徊糠帧1苊庥涗浫哂鄶?shù)據(jù)(例如,只記錄一次時間)和無關(guān)數(shù)據(jù)(例如,在可行的情況下記錄整數(shù)值而不是雙精度)。日志覆蓋(Logging override)還可以用于控制記錄哪些信號,而無需為加速模式重新編譯仿真目標(biāo)。
其他有用的技術(shù)
以下技術(shù)適用于一些特定的模型;如果您的模型屬于下面描述的模式,您可能可以使用這些模式來提高仿真速度。
優(yōu)化硬件加速
單指令多數(shù)據(jù)(SIMD)是一種數(shù)據(jù)級并行處理技術(shù),可以同時對多個數(shù)據(jù)點執(zhí)行相同的操作。許多現(xiàn)代 CPU 都有 SIMD 指令,例如,一次執(zhí)行多個加法或乘法。對于支持塊上的計算密集型操作,SIMD 指令可以提高仿真性能。 Simulink 在所有使用代碼生成技術(shù)的仿真模式(例如,加速器或快速加速器模式)中支持 SIMD 硬件加速。
Simulink 提供了一個 configset 參數(shù)來控制仿真目標(biāo)面板中的 SIMD 類型。對于硬件加速選項,默認選擇(“利用通用硬件”)在所有 X86 cpu 上都可用,不需要重新構(gòu)建。另一種選擇(“利用本地硬件”)依賴于 CPU。如果您的 CPU 支持較新的 SIMD 指令集,如 SSE2/AVX2/AVX512,那么這種選擇可以提供更快的仿真速度(圖17)。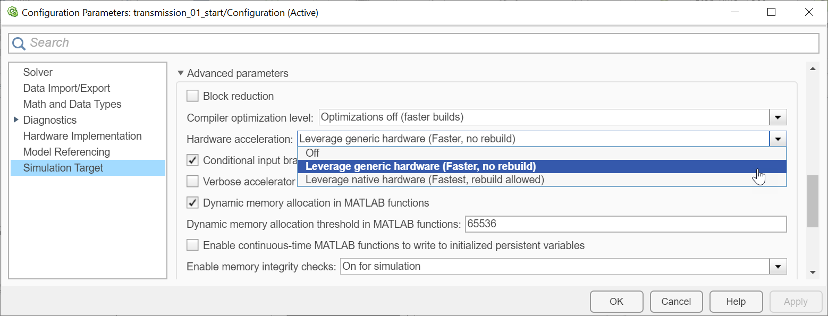
圖17:配置硬件加速選項 當(dāng)您使用仿真目標(biāo)時,有許多因素可以確定 SIMD 是否可用,或者 SIMD 是否可以提高仿真速度。您可以使用前面描述的性能顧問在仿真目標(biāo)下運行一個帶有“檢查硬件加速設(shè)置”的檢查,以了解 SIMD 是否對您的特定模型有幫助。
利用多核仿真
在 Simulink 中,有幾種不同的技術(shù)可以通過調(diào)度模型的某些部分用于多核執(zhí)行來加速單個仿真。這些技術(shù)并不適用于所有的模型,但可能對您的特定用例有用。
數(shù)據(jù)流域的多核仿真。
如果您在 Simulink 中建模和仿真計算密集型信號處理或多速率信號處理系統(tǒng),數(shù)據(jù)流域(dataflow domain)將提高性能。數(shù)據(jù)流域是使用計算同步數(shù)據(jù)流模型進行仿真的一種新的執(zhí)行域。數(shù)據(jù)流執(zhí)行域是數(shù)據(jù)驅(qū)動的,可以使用多個 CPU 核進行仿真。 通過使用 Property Inspector 將 domain 參數(shù)設(shè)置為 dataflow,可以指定 dataflow 作為子系統(tǒng)的執(zhí)行域。數(shù)據(jù)流域自動劃分您的模型,并使用多線程仿真系統(tǒng),以獲得更好的仿真性能(圖18)。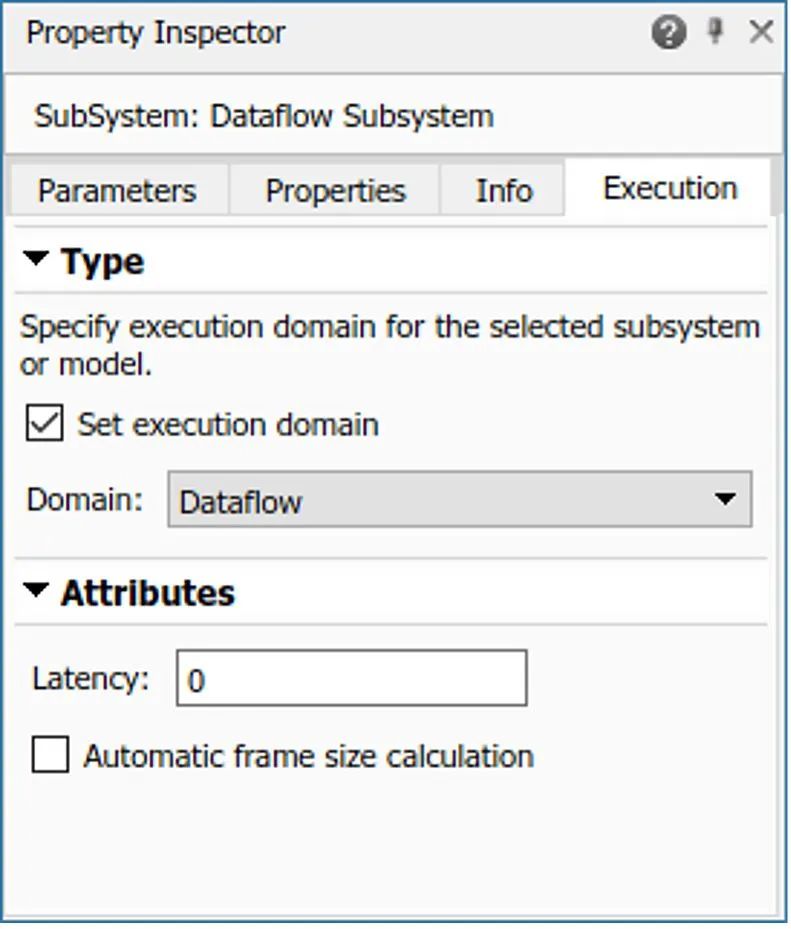
圖18:數(shù)據(jù)流執(zhí)行域 您可以使用多核選項卡上的運行分析按鈕來對數(shù)據(jù)流域進行仿真性能分析。它可以分析模型,計算每個塊的執(zhí)行時間,找到模型中存在的并行性,并將其劃分為多個線程。它可以建議一個延遲值,通過流水線執(zhí)行塊來進一步提高仿真吞吐量。下面圖 19 中的分析建議將延遲設(shè)置為從 0 到 2 以獲得最佳性能。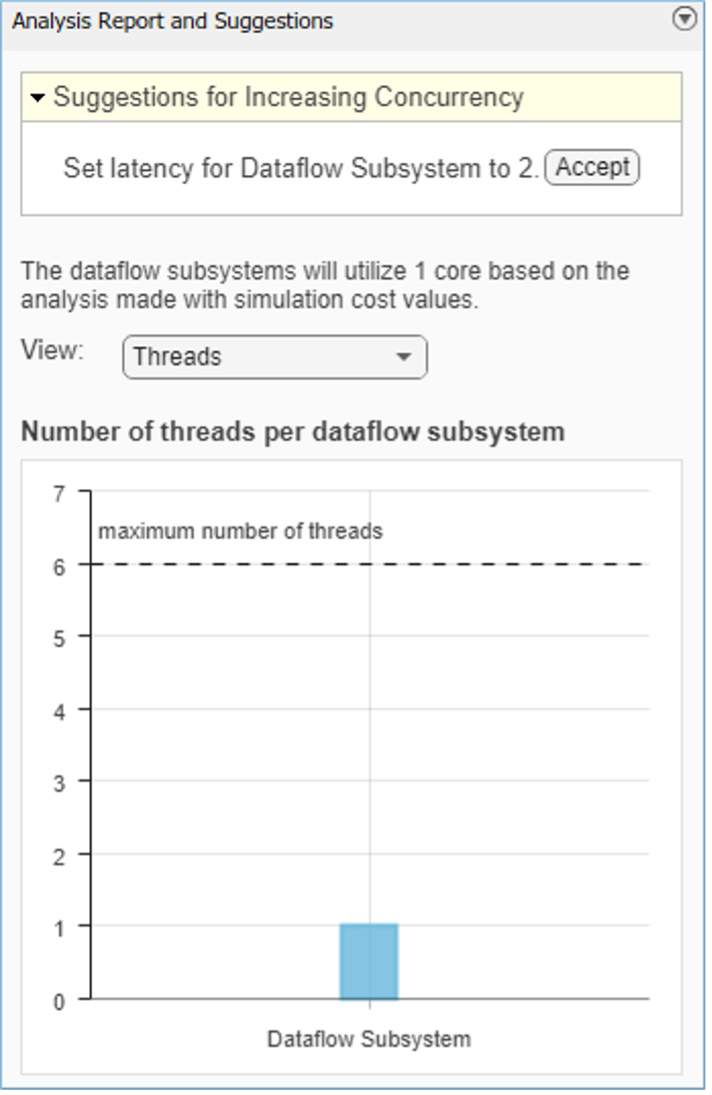
圖19:分析數(shù)據(jù)流域的仿真性能
具有協(xié)同仿真組件的多核仿真。
您的仿真模型可能包括協(xié)同仿真的組件。協(xié)同仿真組件可以是一個 s-function 塊,它被實現(xiàn)為 Simulink 和第三方工具或自定義代碼之間的協(xié)同仿真網(wǎng)關(guān)。它也可以是導(dǎo)入到 Simulink 的聯(lián)合仿真模式下的 FMU 或加速器模式下的模型塊。如果這些協(xié)同仿真組件是線程安全的,那么這些組件就可以在多個線程上運行。線程安全意味著塊可以與訪問共享數(shù)據(jù)、資源和對象的多個線程一起工作,而不會產(chǎn)生任何沖突。 并不是所有的模型都有可以在多線程上運行的協(xié)同仿真組件。另外,多線程協(xié)同仿真只支持普通仿真模式。默認情況下,Simulink 將所有符合條件的模型和塊配置為準(zhǔn)備多線程執(zhí)行。如果性能可以提高,Simulink 將自動在多線程上運行所有模型。
For Each 子系統(tǒng)多核仿真。
For Each 子系統(tǒng)是 Simulink 中的一個子系統(tǒng),它在仿真步中對輸入信號或掩碼參數(shù)數(shù)組中的子數(shù)組的每個元素重復(fù)算法執(zhí)行。如果您的模型包含計算密集的 For Each 子系統(tǒng),您可以通過在多線程上執(zhí)行 For Each 子系統(tǒng)迭代來潛在地加速仿真。
For Each 子系統(tǒng)的多核仿真只支持快速加速仿真模式。默認情況下,for Each 子系統(tǒng)的多線程仿真支持是被啟用狀態(tài)。Simulink 將自動對仿真進行動態(tài)配置。只有在檢測到性能優(yōu)勢時才并行執(zhí)行才會被啟用。您可以使用模型參數(shù)“multithreaddsim”手動選擇加入或退出多線程仿真。
具體實踐及效果對比
為了說明這些技術(shù)在實際項目中的相對有效性,我們通過將上面建議的一些更改應(yīng)用于自動變速器系統(tǒng)模型(圖20)來測量仿真時間性能改進。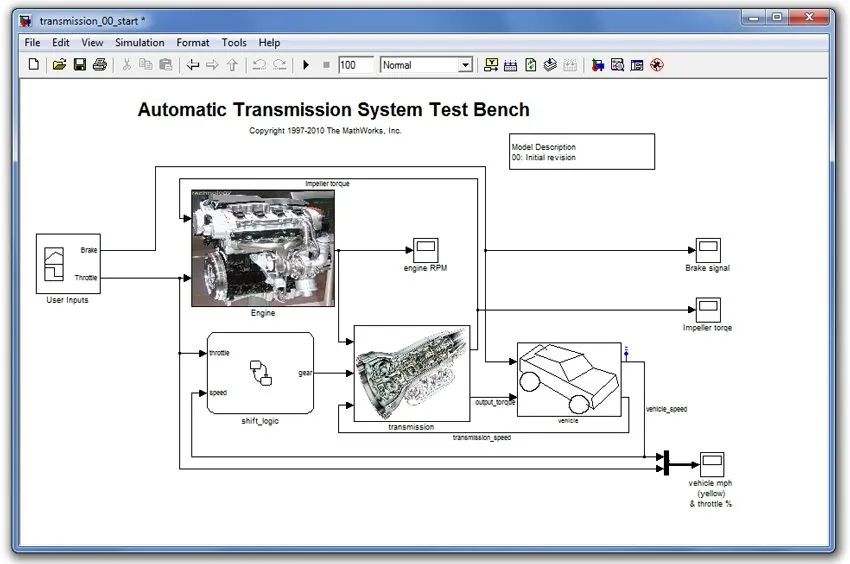
圖20:某自動變速器系統(tǒng)的 Simulink 模型 為了提高性能,我們首先使用 Performance Advisor 運行檢查,并提出以下建議更改:
禁用了檢查求解器數(shù)據(jù)不一致、按奇異矩陣除法、Inf NaN 塊輸出、仿真范圍檢查和超出數(shù)組邊界等代價較高的診斷項
將解釋執(zhí)行的 MATLAB Function 塊替換為 MATLAB functions(此更改具有最大的單一效果)。
啟用 Block reduction 優(yōu)化
關(guān)閉并注釋掉 Scope
這些變化將仿真時間從平均 57 秒減少到 3.3 秒。使用優(yōu)化的模型,我們現(xiàn)在可以應(yīng)用快速加速和并行仿真來比較這些技術(shù)的性能(表2)。
| 原始模型,正常模式,串行執(zhí)行,快速重啟 | 5731 秒 |
| 改進模型,正常模式,串行執(zhí)行,快速重啟 | 328 秒 |
| 改進模型,正常模式,串行執(zhí)行,快速重啟 | 307 秒 |
| 改進模型,快速加速模式,串行執(zhí)行,帶 RapidAcceleratorUpToDateCheck Off | 236 秒 |
| 改進模型,正常模式,并行仿真,快速重啟(4 個 worker) | 198 秒 |
| 改進模型,快速加速模式,并行仿真,與 RapidAcceleratorUpToDateCheck Off (4 個 worker) |
85 秒 |
表 2:Time for 100 iterations of each model for 2000 seconds of simulation time. System used: Lenovo T490s with Intel Core i7-8665U CPU (1.9 GHz, 2112 MHz, 4 Cores), 32 GB DDR4 2400 MHz PC4-19200 SODIMM, Drive: 1 TB SSD, Windows 10 Enterprise, MATLAB R2022a.
審核編輯:劉清
-
simulink仿真
+關(guān)注
關(guān)注
0文章
75瀏覽量
8584
原文標(biāo)題:實用技能技巧 | 提高 Simulink 仿真性能
文章出處:【微信號:MATLAB,微信公眾號:MATLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
如何利用MATLAB的simulink建立仿真模型呢
simulink建模與仿真 下載
Simulink建模與仿真教材

simulink仿真pdf

MIMO-OFDM的matlab和simulink仿真程序或
Simulink建模和仿真
SIMULINK仿真





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論