") Nvidia 正在利用迄今為止最強(qiáng)大的芯片 H200 推動(dòng)人工智能革命
Nvidia 正在利用迄今為止最強(qiáng)大的芯片 H200 推動(dòng)人工智能革命
Nvidia 表示,H200 Tensor Core GPU 具有更大的內(nèi)存容量和帶寬,可加快生成 AI 和 HPC 工作負(fù)載的速度。
Nvidia H200 是首款提供 HBM3e 的 GPU,HBM3e 是更快、更大的內(nèi)存,可加速生成式 AI。
H200 芯片定于 2024 年第二季度發(fā)布,Nvidia 表示將與“全球系統(tǒng)制造商和云服務(wù)提供商”合作以實(shí)現(xiàn)廣泛可用性。
JAEALOT
Nvidia
OpenAI推出ChatGPT已經(jīng)一段時(shí)間了 ,全球?qū)I芯片的需求比以往任何時(shí)候都更加難以滿足。如今,大多數(shù)大型科技公司都將注意力集中在生成式人工智能上。對于制造數(shù)量最多、性能最高的圖形處理單元 (GPU) 的公司 Nvidia 公司來說,現(xiàn)在的情況從未如此好過。在發(fā)布了數(shù)十款芯片以滿足看似呈指數(shù)級增長的人工智能市場之后,這家圖形芯片巨頭展示了迄今為止最強(qiáng)大的 GPU——H200。
NVIDIA H200 Tensor Core GPU 誕生之際,Nvidia 正在努力捍衛(wèi)其 在 AI 計(jì)算領(lǐng)域的主導(dǎo)地位 ,面對 英特爾、AMD以及眾多芯片初創(chuàng)公司和 Amazon Web Services 等試圖搶占市場份額的云服務(wù)提供商。在生成人工智能工作負(fù)載驅(qū)動(dòng)的芯片需求激增的情況下,市場份額不斷增加。
為了保持在人工智能和高性能計(jì)算 (HPC) 硬件領(lǐng)域的領(lǐng)先地位,英偉達(dá)上月初公布了加快新 GPU 架構(gòu)開發(fā)的計(jì)劃。根據(jù)為投資者發(fā)布的路線圖 以及 SemiAnalysis的進(jìn)一步解釋,這個(gè)想法是要恢復(fù)到一年一次的產(chǎn)品推出節(jié)奏 。SemiAnalysis 的報(bào)告中寫道:“Nvidia 對 AI GPU 進(jìn)行年度更新的舉動(dòng)非常重要,并且會(huì)產(chǎn)生許多影響。”
這一切的開始就是 Nvidia 推出的 H200,它利用 Hopper 架構(gòu)來加速人工智能應(yīng)用程序。它是去年發(fā)布的H100 GPU的后續(xù)產(chǎn)品 ,也是此前 Nvidia 最強(qiáng)大的 AI GPU 芯片。簡而言之,H200 現(xiàn)在是 Nvidia 產(chǎn)品組合中最強(qiáng)大的 AI 芯片。
Nvidia 超大規(guī)模和 HPC 副總裁 Ian Buck 認(rèn)為,“借助業(yè)界領(lǐng)先的端到端 AI 超級計(jì)算平臺(tái) Nvidia H200,可以更快地解決世界上一些最重要的挑戰(zhàn)。” 一般來說,GPU 在人工智能應(yīng)用中表現(xiàn)出色,因?yàn)樗鼈兡軌驁?zhí)行大量并行矩陣乘法,這是神經(jīng)網(wǎng)絡(luò)運(yùn)行的關(guān)鍵操作。
它們在構(gòu)建人工智能模型的訓(xùn)練階段和隨后的“推理”階段都發(fā)揮著至關(guān)重要的作用,在“推理”階段,用戶將數(shù)據(jù)輸入到人工智能模型中,并提供相應(yīng)的結(jié)果。Buck 指出:“要通過生成式 AI 和 HPC 應(yīng)用程序創(chuàng)建智能,必須使用大容量、快速的 GPU 內(nèi)存高速有效地處理大量數(shù)據(jù)。”
因此,引入 H200 將帶來進(jìn)一步的性能飛躍,包括與 H100 相比,Llama 2(一個(gè) 700 億參數(shù)的 LLM)的推理速度幾乎翻倍。據(jù) Nvidia 稱,未來的軟件更新預(yù)計(jì)會(huì)帶來 H200 的額外性能領(lǐng)先優(yōu)勢和改進(jìn)。
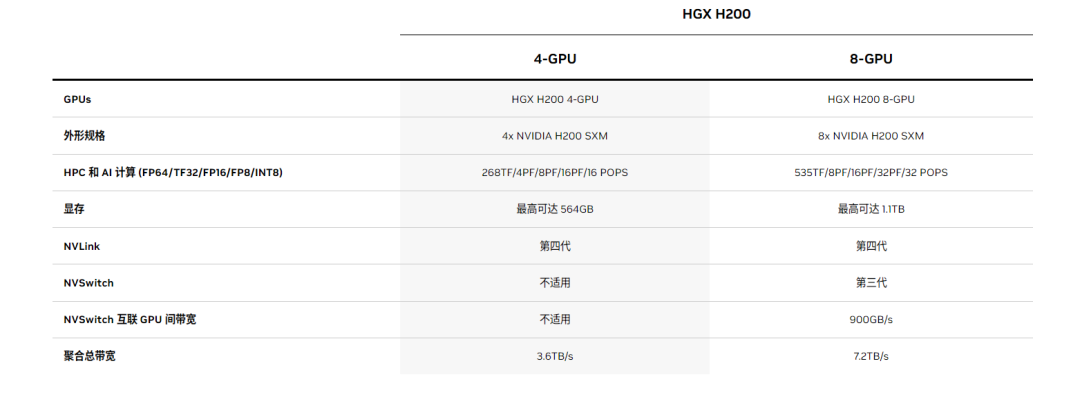
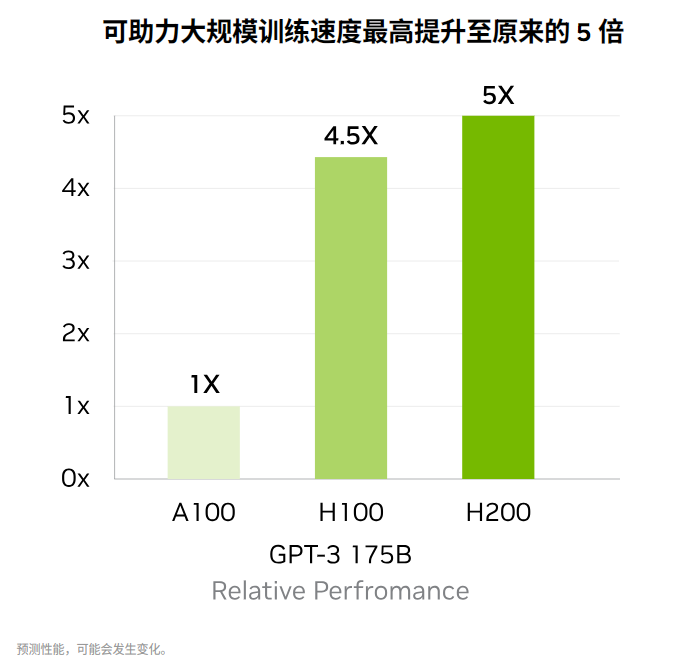
雖然 H200 看起來與 H100 基本相似,但其內(nèi)存的修改有明顯的增強(qiáng)。新的 GPU 引入了一種創(chuàng)新且更快的內(nèi)存規(guī)范,稱為 HBM3e。這將 GPU 的內(nèi)存帶寬提升至每秒 4.8 TB,比 H100 的每秒 3.35 TB 明顯增加。它將總內(nèi)存容量從前代產(chǎn)品的 80GB 擴(kuò)展至 141GB。
“Nvidia H200 是首款提供 HBM3e 的 GPU,HBM3e 速度更快、內(nèi)存更大,可加速生成式 AI 和大型語言模型 (LLM),同時(shí)推進(jìn) HPC 工作負(fù)載的科學(xué)計(jì)算。憑借 HBM3e,NVIDIA H200 以每秒 4.8 TB 的速度提供 141GB 內(nèi)存,與前身 NVIDIA A100 相比,容量幾乎翻倍,帶寬增加 2.4 倍。”該芯片巨頭 表示。
結(jié)合實(shí)際情況來看,OpenAI 經(jīng)常提到面臨 GPU 資源短缺,導(dǎo)致 ChatGPT 性能下降的問題。為了維持任何水平的服務(wù),該公司采取速率限制。理論上,加入H200可以緩解當(dāng)前運(yùn)行ChatGPT的AI語言模型的資源限制,使它們能夠有效地迎合更廣泛的客戶群。
Nvidia 還表示,它將提供多種外形規(guī)格的 H200。其中包括四路和八路配置的 Nvidia HGX H200 服務(wù)器主板,與 HGX H100 系統(tǒng)的硬件和軟件兼容。它還將在 Nvidia GH200 Grace Hopper Superchip 中提供,它將 CPU 和 GPU 組合到一個(gè)封裝中。
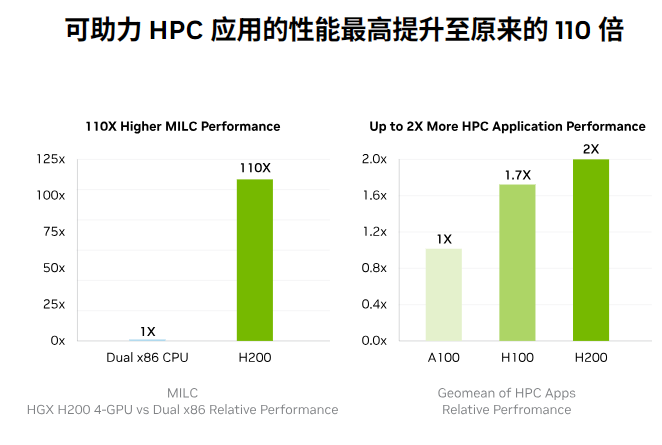
“通過這些選項(xiàng),H200 可以部署在各種類型的數(shù)據(jù)中心中,包括本地、云、混合云和邊緣。NVIDIA 的 全球合作伙伴服務(wù)器制造商生態(tài)系統(tǒng) (包括華擎 Rack、華碩、戴爾科技、Eviden、技嘉、惠普企業(yè)、英格拉科技、聯(lián)想、QCT、Supermicro、緯創(chuàng)資通和 Wiwynn)可以使用 H200 更新其現(xiàn)有系統(tǒng)。” 。
據(jù)美國芯片巨頭亞馬遜網(wǎng)絡(luò)服務(wù)(AWS)稱,除了CoreWeave、Lambda、和烏爾特爾。目前,英偉達(dá)在AI GPU市場處于領(lǐng)先地位。
然而,AWS、谷歌、微軟等主要參與者以及 AMD 等傳統(tǒng) AI 和 HPC 實(shí)體正在積極準(zhǔn)備 其下一代處理器用于訓(xùn)練和推理。為了應(yīng)對這種競爭格局,Nvidia 加快了基于 B100 和 X100 的產(chǎn)品進(jìn)度。
-
芯片
+關(guān)注
關(guān)注
456文章
50950瀏覽量
424729 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5021瀏覽量
103255 -
人工智能
+關(guān)注
關(guān)注
1792文章
47425瀏覽量
238956
發(fā)布評論請先 登錄
相關(guān)推薦
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第6章人AI與能源科學(xué)讀后感
《AI for Science:人工智能驅(qū)動(dòng)科學(xué)創(chuàng)新》第一章人工智能驅(qū)動(dòng)的科學(xué)創(chuàng)新學(xué)習(xí)心得
英偉達(dá)H200芯片將大規(guī)模交付
OpenAI聯(lián)手Nvidia發(fā)布首臺(tái)Nvidia DGX H200
英偉達(dá)H200性能顯著提升,年內(nèi)將推出B200新一代AI半導(dǎo)體
英偉達(dá)H200顯卡參數(shù)是什么
英偉達(dá)H200上市時(shí)間
英偉達(dá)H200帶寬狂飆
英偉達(dá)H200算力怎么樣
英偉達(dá)H200能作為普通顯卡使用嗎
英偉達(dá)H200顯卡價(jià)格
英偉達(dá)H200和H100的比較
英偉達(dá)H200參數(shù)說明
Stability AI推出迄今為止更小、更高效的1.6B語言模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論