 大模型時代下算力芯片的背后——高速互連技術會成為性能突破口?
大模型時代下算力芯片的背后——高速互連技術會成為性能突破口?
2023年,AI大模型實實在在地“從年頭火到年尾”。自ChatGPT成為AI大模型的第一個“出圈”應用,以聊天機器人的形式展示出AI大模型應用的強大能力后,全球各大科技公司都在加速推動AI大模型的應用,當然也吸引了眾多初創公司入局。一時間各種AI大模型涌現,無論是行業專用大模型還是通用認知大模型,都為更多創新的AI應用提供了技術支持。
但這種AI大模型背后的技術底層并不簡單,它需要海量的數據、復雜的算法和強大的算力來支撐。其中,算力可以說是人工智能發展最大的瓶頸,也是當前AI大模型的核心競爭力之一。
如果有關注微軟、谷歌、阿里巴巴、百度等國內外科技巨頭的動態,你會發現這些企業去年都在大量訂購GPU以及AI服務器等產品。有機構預計,AI大模型訓練對于算力的需求未來將會以每3.5個月翻一番的速度增長,需求暴增驅動了芯片企業的更新迭代,算力芯片在近幾年性能提升速度驚人。
去年11月,英偉達推出了當今全球最強的GPU芯片H200,Llama2 70B大模型訓練的性能相比上一代提高近一倍。然而在大模型時代,受限于芯片制造的物理極限,晶體管密度的提升幅度越來越小,即使單顆GPU算力提升已經非常高,但遠遠無法滿足大模型的訓練要求。
在可預見的未來,先進封裝以及芯片制造工藝所帶來的芯片性能提升將越來越難滿足AI大模型對算力的需求。于是在聚光燈下的算力芯片背后,高速互連技術開始被越來越多芯片企業和系統廠商所關注。
01. 高速互聯技術——從“四路泰坦”到計算集群
相信資深的PC玩家大概率都聽說過“四路泰坦”的傳說,這是指在配備四個PCIe插槽的主板上使用了四塊“泰坦”顯卡(這是當時最強的旗艦級顯卡型號),通過英偉達一種名為SLI的特殊互連技術將這四塊顯卡連接起來以大幅提升游戲圖形性能。
后來AMD也推出了與SLI類似的CrossFire(交火)技術,可以將不同型號的AMD顯卡連接起來,提升圖形性能。這是在PC領域,單個GPU性能有限的情況下,所出現的一種解決方案之一,同時也是高速互連技術的應用之一。
后來,因為PC端游戲的性能需求,已經被快速迭代的GPU性能所滿足,“多卡交火”在游戲中的實際性能也因為適配和性能損耗等問題提升不明顯,這種玩法隨后逐漸在消費級市場上被淘汰。
但前面我們也提到,盡管AI芯片算力近年提升神速,但在AI大模型訓練中仍是微不足道。為了給大模型訓練提供更強大的算力,業界所選擇的解決辦法是:類似顯卡“交火”般,將多個AI加速卡連接起來。
在大模型訓練應用中,往往會將幾百個甚至是上千個AI加速卡連接在一起,形成一個整體的系統,才能夠運行GPT、PaLM等大模型。
如此龐大的算力資源,首先遇到的瓶頸就是互連的通信效率。如果將AI算力系統看成一條工廠的流水線,那么互連技術就相當于流水線上的傳送帶。傳送帶移動速度太慢時,即使AI芯片產出的數據再多,都只會堆積起來,無法及時輸送到下一顆芯片上,從而限制整個工廠的效率。
所以,要怎樣將算力硬件連接起來,怎樣將這些算力資源更好地進行分配,實現運算效率最大化?
問題的關鍵,首先要從單個服務器內部芯片的高速互連開始解決。
實際上,在計算機系統中,包含了CPU、GPU、內存、存儲設備等組件,這些組件都無法各自獨立運行,一般需要通過互連協議相互連接,進行通信和數據傳輸,才能夠協同完成計算工作。
比如PCIe作為最常見的高速互連標準之一,被廣泛用于CPU、GPU之間的高速互連。2003年PCI-SIG發布了PCIe 1.0規范,支持每通道傳輸速率為 2.5GT/s,最大總傳輸速率為4GB/s。在此之后的每一個版本迭代中,PCIe的傳輸速率都會以翻倍的速度增長,到2022年發布的PCIe 6.0規劃中,每通道傳輸速率已經提高至64GT/s。
然而大規模計算集群的互連,對帶寬、延遲、數據傳輸效率等都有更高要求,因此在PCIe之外,從2016年開始,各大芯片廠商都開始下場推出自家的服務器內部高速互連解決方案:英偉達在2016年推出了SLI的“高級版本”——NVLink,令多個GPU繞開PCIe直接進行互連,目前最新的NVLink 4.0已經可以實現900 GB/s的總雙向帶寬;AMD在2016年也推出了Infinity Fabric技術,外部帶寬可以達到 800GB/s ;英特爾在2019年發布了基于PCIe協議的開放性高速互連協議CXL1.0,主要是打通了CPU和其他設備的內存共享,支持CPU與其他加速器之間的高速互連,滿足異構計算要求,最新的CXL 3.0通過x16鏈路可以實現256GB/s的雙向帶寬。
可以發現,這些高速互連協議一般是由頭部芯片企業主導,但問題在于,近年來隨著算力需求的爆發,不斷有新玩家投入開發GPU、AI加速卡等產品。有數據顯示,全球范圍內已經有上百家公司布局GPU、AI加速卡領域,僅在中國就有60多家公司推出了各自的AI加速卡產品。
從好的角度看,新玩家的加入能夠為市場帶來更多的產品選擇,針對不同應用也能夠更容易選擇到合適的產品。但另一方面,AI算力系統與傳統的CPU服務器的通用解決方案不同,AI算力系統本身是一種深度定制化的系統。
各種形態的AI加速卡背后,是各大廠商采用了不同技術路線、不同產品定義,這導致了這些AI加速卡無法兼容通用平臺,需要各自定制硬件平臺。深度定制帶來的副作用就是,從芯片到算力系統,開發周期長、研發成本高,對于計算系統的高速互連拓撲架構設計、PCB設計以及制造工藝都要不斷突破與創新,這為AI服務器的性能提升帶來了不小的挑戰。
正因為如此,在大模型時代,業界亟待有一個開放的AI芯片設計規范,在芯片端或是AI加速卡等算力硬件端開始進行定義,以支持更強的算力硬件互連,創造出更強的AI算力系統。
02. 卡間互連速率翻倍,OAM標準要一統AI服務器?
早在2019年,開放計算組織OCP就成立了OAI(開放式加速器基礎設施)小組,包括Meta、微軟、百度與浪潮信息等宣布聯合制定OAM(OCP Accelerator Module開放加速模塊) 標準,用于指導 AI 硬件加速模塊和系統設計。 而OAM標準,就是為了解決上述提到AI加速卡硬件互相不兼容等一系列問題,提供一套指導AI硬件加速模塊和系統設計的標準,定義了AI硬件加速模塊本身、互連速率、互連拓撲、主板、機箱、供電、散熱以及系統管理等系列設計規范。
在互連速率方面,基于OAM規范能夠實現四階脈沖調制方案(PAM4,4-Level Pulse Amplitude Modulation即四電平脈沖幅度調制)的單通道56Gbps高速信號互連速率。而在不歸零編碼 (NRZ, non-return-to-zero line code)碼型下,PCIe 5.0最大只支持32Gbps的傳輸速率。
具體來說,OAM1.0規范下GPU之間支持多種高速互連通信協議,這些通信協議的物理層大多是基于以太網協議或者PCIe協議,其中基于以太網協議能夠支持56Gbps的互連速率,基于PCIe則最高支持PCIe 5.0,也就是32Gbps。 OAM的出現,得到了業內眾多企業的支持和參與,包括大家耳熟能詳的英偉達、英特爾、AMD、微軟、阿里巴巴、谷歌、浪潮信息等AI芯片企業、互聯網企業、系統廠商等,大有一統AI服務器的趨勢。
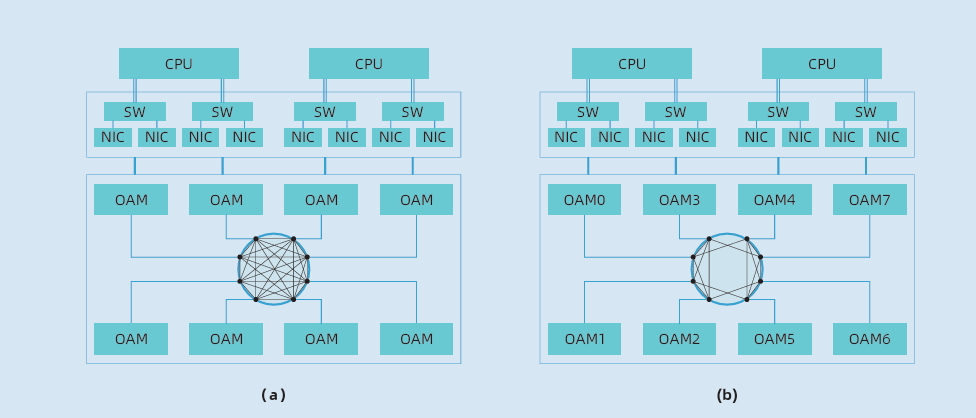
開放加速計算節點系統架構: 主流OAM互連拓撲 (a) FC (b) HCM
值得一提的是,其中作為系統廠商中的一員,浪潮信息第一個實現了符合OAM規范的8卡互連的AI系統,首次提供了全互連(Fully-connected)和混合立體互連HCM (Hybrid Cube Mesh)兩種互連拓撲。
業界主流AI服務器大多為8卡互連,主要采用的拓撲架構有全互連和混合立方互連兩種。根據不同的神經網絡模型應用,兩種互連拓撲各有優勢,但針對大模型應用,全互連拓撲會更有優勢。
簡單來說,我們將單一服務器中的加速卡標號為0到7,全互連拓撲架構中每一張加速卡互相之間都能夠進行通信,比如0號跟1號到7號加速卡都能直接進行通信;混合立方互連拓撲架構中,0號到7號加速卡之間通過組成一個或者多個雙向環的方式進行通信,加速卡彼此之間都只能跟附近兩張加速卡進行通信,比如0號可以跟7號和1號直接進行通信,7號可以直接跟6號和0號進行通信。
從上面的描述中很容易能夠感知到全互連拓撲會相對復雜,事實也確實如此。相比其他廠商采用的混合互連拓撲架構,全互連的拓撲設計在同樣的PCB材料疊層內,高速信號的總線長度是其他混合互連結構的一倍,這對PCB的設計和制造,帶來了新的挑戰。
03. 從56G到112G,高速互連帶來的新挑戰
在OAM標準實現了高速互連系統的各種設計規范后,基于OAM規范,更復雜的拓撲設計,更高的互連速率,都給PCB的設計、選材和制造工藝帶來了挑戰。目前業界在探索OAM規范下從56G提升到112G的互連技術,而更高的信號速率,意味著信號在PCB中傳輸時,信號完整性和信號質量更容易受到干擾。
在服務器一般應用的PCB中,一般采用十層以上甚至數十層的設計,以承載復雜的電路拓撲。而要實現一個可支持8張OAM互連的基板,則需要20~30層的PCB。同時為了保證信號傳輸質量,又需要采用長度相等、相位相反的互補信號來傳輸同一個信號,以減少噪音和EMI(電磁干擾),也就是說所有走線的數量需要翻倍。同時走線的寬度和間距需要由始至終保持一致,如果在連接路徑上有其他的布線或者焊盤、過孔等阻礙,就需要從PCB有限的空間內找到合適的路徑,給設計能力帶來很大挑戰。
對于高速互連的PCB,實際上連接器的設計也會對系統性能造成很大影響,比如高速信號經過連接器時造成的損耗等,會降低信號完整性。據了解,為了保證112G高速信號完整性,浪潮信息的工程師根據更低損耗的連接器的各項SI特性,優化了信號走線布局,提高了連接器整體帶寬。同時通過對背板連接器、網絡接口,甚至線纜等進行仿真優化,有效保障了112G信號設計的可靠性。
為了實現112G高速互連,還需要在PCB的材料上下功夫,需要尋找更低損耗的樹酯、玻璃纖維及更平滑的銅箔,以確保這些材料加工之后能夠符合信號設計可靠度的規范。為此,浪潮信息調研了業界幾乎所有的PCB板材,建立了一套完善的PCB材料電性數據庫,包括針對銅箔平坦度、表面拉力、高溫影響性、蝕刻制程誤差、介電損耗等匯整了3000多筆寶貴的測試數據。
而基于這些測試數據,可以更有針對性地優化高速信號設計,最終損耗性能可優化提升8%,為112G高速互連技術的落地打下基礎。
112Gpbs高速互連技術既需要科學的發散,也要做到工程的收斂:通過科學的發散尋找創新的可能性,通過工程的收斂尋找“可行性”。創新的可能性空間包括了材料、工藝、方法、管理運營等等,而可行性則是尋找“最大化或最小化”,是尋找最優解的過程。
04. 寫在最后
算力系統就像由長短不一的木板組成的木桶,每個部件的發展程度各不相同,難免會出現一些短板。特別是應用于AI大模型的算力集群中,單一的算力芯片可能能夠發揮100%的性能,但在系統中可能只能發揮80%。當將無數顆算力芯片看成一個整體時,這樣的性能損耗疊加起來是巨大的,而高速互連技術,能夠在很大程度上補足這方面的短板,激活算力硬件100%的性能。
可以說,在AI大模型的需求下,高速互連技術已經成為算力系統的新瓶頸之一,更高效的互連技術將有機會令算力集群達到前所未有的高度。當然,算力產業可能也會找到更加創新的算力解決方案。但毋庸置疑,高速互連技術在產業中占有的重要地位,未來將不亞于單一的AI芯片,高速互連技術加持的高性能算力集群能夠持續推動AI大模型應用普惠,讓AI應用落地變得更加輕松。
-
人工智能
+關注
關注
1792文章
47442瀏覽量
239006 -
GPU芯片
+關注
關注
1文章
303瀏覽量
5857 -
大模型
+關注
關注
2文章
2491瀏覽量
2871
原文標題:大模型時代下算力芯片的背后——高速互連技術會成為性能突破口?
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ChatGPT背后的算力芯片





 工商網監
工商網監
評論