

來源:中國指揮與控制學會
作者:黃海濤 田虎 鄭曉龍 曾大軍
在線社交網絡面臨著網絡社交機器人操控的威脅,而現有的檢測算法還不能緩解這種威脅。如何有效利用人工智能技術檢測社交機器人,規避其潛在的風險并保障網絡的良好生態,是當前亟需解決的重要任務。
隨著互聯網與信息技術的蓬勃發展,在線社交網絡吸引了大量用戶,成為現今網絡空間的重要組成部分。自從在線社交網絡出現以來,網絡社交機器人就與在線社交網絡相伴而生。根據Grimme等人的定義,網絡社交機器人涵蓋多種自動化與半自動化智能體,這些智能體通過在網絡空間中進行單向或多方向的通信來實現特定的目的,并非僅涵蓋在線社交網絡中的機器人。但在本文中,我們只考慮被廣泛研究的在線社交網絡中的社交機器人,這些機器人主要通過與其他賬戶建立好友關系、發布或轉發帖子來實現其所有者的特定目的。
由于其自動化特性,網絡社交機器人可以用于實現某些需要持續很長時間的有益于網絡空間健康發展的簡單功能。但同時,我們也應當看到目前網絡社交機器人產生的問題和引發的社會矛盾遠大于其所能提供的收益。網絡社交機器人可能造成用戶隱私泄露的問題:在臉書、推特等社交媒體上,大量用戶輕易相信未知賬號,愿意接受好友請求或反向關注那些關注他們的用戶。除信息泄漏外,網絡社交機器人也在給用戶造成經濟損失:它們串通協作推廣低價值股票,或是為特定應用程序和銷售商品打廣告。網絡社交機器人對于民主政治、社會分裂和政治沖突的影響也不容忽視:在2016年的美國總統大選中,社交機器人在假新聞傳播的早期階段極大擴展了相關新聞的影響范圍,危及總統選舉的公正性。2018年佛羅里達校園槍擊案后,社交機器人的活動加劇了推特用戶關于控槍問題的情緒極化現象,進一步撕裂美國社會共識。部分推特社交機器人在北京冬奧會期間通過放大爭議等方式制造有關冬奧會的政治沖突,加劇了奧運會相關輿論宣傳的泛政治化。
綜上所述,未受到規范的網絡社交機器人活動已經引發了各方面的多種損失與問題,網絡空間面臨著嚴峻的被操控風險,必須引起我們高度重視,力求通過科學界與產業界的高度合作,盡量遏制惡意網絡社交機器人的蔓延。
一、網絡社交機器人的產生背景
現今社交網絡已經深度融入到每個人的生活當中,臉書、微博等平臺已經擁有億萬活躍用戶,具備令人驚嘆的推廣傳播效果的同時也為網絡社交機器人惡意操縱信息傳播提供了可乘之機。同時,信息技術的發展也使得能夠接觸到網絡社交機器人等相關技術的人群呈爆炸性增長,Github等開源程序社區上可以公開獲取的網絡社交機器人程序框架和功能完備的計算機程序已有很多。基于這些框架或程序進行二次開發的難度較低,這也是為網絡社交機器人泛濫的提供了技術便利。此外,人工智能技術的發展也大幅提升了網絡社交機器人的識別難度和智能水平。目前,社交機器人已經進化成具有晝夜節律、盜用他人賬戶信息、能夠通過轉發正常推文和模擬點擊等行為掩蓋真實目標的智能體,使得許多曾經有效的關鍵特征失效,大大提高了識別和檢測難度。在可預見的未來,基于效果拔群的ChatGPT等預訓練語言模型和styleGAN等圖像生成技術自主生成具有較高迷惑性消息并進行發布的網絡社交機器人很有可能代替現有的需要人工編寫所發布消息的網絡社交機器人。這種智能水平的提高會進一步提升正常用戶識別和算法檢測的難度,造成更大的倫理風險。
為了保護社交媒體平臺或在線討論社區產品不被社交機器人控制,同時維持平臺用戶活躍性的目的,很多互聯網公司已經開發和部署網絡社交機器人檢測算法。比如微信團隊已經發表了多個有關網絡社交機器人檢測的研究工作,并在微信平臺上部署了相應的檢測算法,取得了很好的檢測效果。推特與臉書雖沒有發表過相關論文,但這些平臺也都在批量暫停網絡社交機器人賬戶,表明其也擁有較強的反制措施。新生代的網絡社交機器人就是在這樣的持續檢測環境中產生,他們已經通過了所在平臺的檢測機制,并在這樣的生成-檢測對抗中不斷加強,逐漸提高其迷惑性和檢測難度。
二、網絡社交機器人檢測存在的技術挑戰
(一)社交機器人持續進化,規避檢測能力加強
2015年以前出現的網絡社交機器人比較簡單,呈現出明顯的非智能化和機器人之間相互關聯的弱點,經過特征或模型設計很容易與正常用戶區分開來。但在2017年,Cresci等人的研究論文證實,新出現的網絡社交機器人與早期的網絡社交機器人完全不同,它們普遍使用非常詳細的偽造的或是盜用的個人信息,能夠模仿晝夜節律,且僅在大量正常的推文中穿插少量帶有特定目的的推文。在這次社會調查中,人工分類新機器人僅有24%的準確率,也正是這類機器人可以吸引大量正常用戶的關注。在這種進化過程中,社交機器人通過改變偽裝手段的方式,極大提高了其檢測難度,造成檢測算法必須面對社交機器人持續進化、規避檢測能力不斷增強的挑戰。
(二)網絡社交機器人協調傳播行為較為復雜
在最新的網絡社交機器人中,機器人之間的相互串通與關聯行為已經很難從社交關系中找到蛛絲馬跡,即機器人網絡演變成由隱藏實體所操控的為達成特定目標而采取協調行為的機器人群體,這些機器人彼此之間卻不存在社交關系。Agarwal等人通過分析推特社交機器人發現在社交機器人網絡中找不到為其他機器人提供信息的中心節點,印證了這一挑戰的存在。這使得我們必須仔細而嚴謹地思考網絡社交機器人在協調傳播特定目的信息時所表現出的特征以及協同行為的判斷標準,這無疑提高了社交機器人檢測難度。
(三)檢測算法開發環境與使用環境差異過大
檢測算法開發環境與使用環境差異過大有兩層含義:其一是指檢測算法于平穩的中性環境中開發,而實際使用環境完全不滿足此假設;其二是指我們希望檢測算法能夠在社交機器人尚未傳播虛假信息甚至是注冊時就能檢測到它們,但大部分現有算法僅能實現已傳播虛假信息的社交機器人的檢測功能。平穩中性的開發環境是指開發過程中使用固定數據集,即假設社交機器人不會產生進化、不會更改策略欺騙檢測算法,但這在實際部署檢測場景中并不成立,造成檢測算法實用效果嚴重受限。且現有檢測算法大多采用社交機器人的發布推文或社交行為特征,只能在認識到新的社交機器人種類出現之后開發對應的檢測算法,難以發揮期望的預防社交機器人的作用。以上兩方面原因造成目前開發的檢測算法并不是我們真正需要的檢測算法,構成我們開發新社交機器人檢測算法的嚴峻挑戰。
三、網絡社交機器人檢測的關鍵技術
現有的網絡社交機器人檢測方法普遍將社交機器人檢測處理成一個二分類問題,并不會對賬戶在特定時間上是否在進行攻擊或是賬戶屬于哪一類網絡社交機器人進行區分。但是,這種設計思路由于缺乏對于社交機器人的細致描述,不利于描述混合自動化行為與人工驅動行為的半機器人,也不利于研究人員理解不同類別社交機器人與人類的本質區別,已經成為網絡社交機器人檢測算法發展之路上的重大阻礙。現有的網絡社交機器人檢測方法可以依據其檢測網絡社交機器人的原理分為兩類,一類是基于賬戶特征的方法,另一類是基于網絡結構的方法,下面將對這兩類方法分別進行概述、介紹典型工作和分析優劣勢。兩類方法的分類框架及優缺點概括如圖1所示。
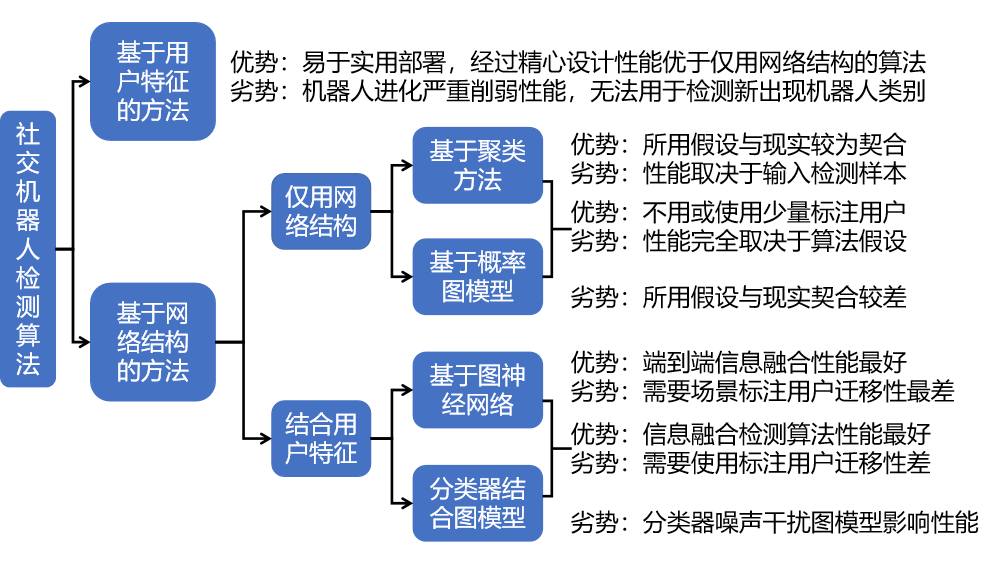
圖1 網絡社交機器人檢測算法分類框架圖
(一)基于賬戶特征的方法
基于賬戶特征的方法普遍忽視網絡社交機器人組成機器人網絡協調傳播隱蔽關聯的特性,將社交機器人視為單獨賬號進行檢測。這種方式無法利用賬號協調傳播信息,需要大量已標注的賬號作為訓練樣本以訓練檢測算法,且樣本質量對于檢測算法性能影響很大。
基于賬戶特征的檢測方法總體技術框架如圖2所示,其類似于傳統的機器學習模型,由特征提取部分和分類器部分構成。分類器部分主要采用機器學習領域已經開發成熟的分類模型,故相關研究工作集中于如何進行特征工程或設計神經網絡模型以快速有效地提取賬戶特征方面。這也使得這種方法的有效性取決于社交機器人與正常用戶在多種特征上的統計差異。如果社交機器人通過進化等方式在某些關鍵特征上彌合與正常用戶之間的分布差異,這種方法的有效性就要大打折扣,研究人員也就不得不轉而開發新算法以解決危機。
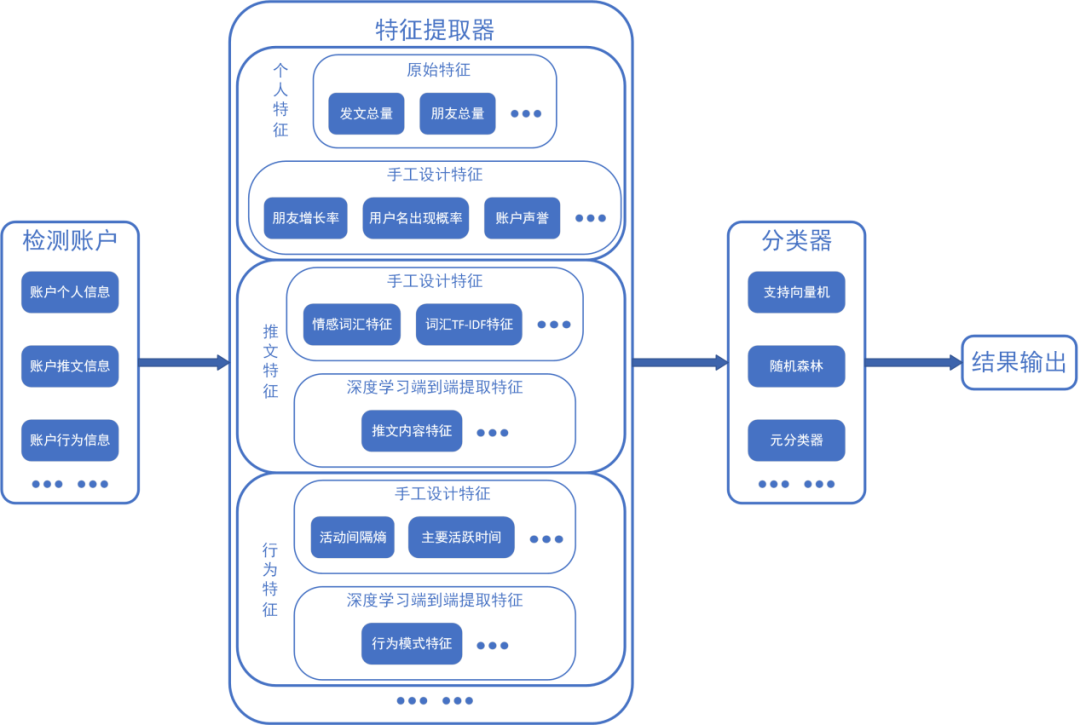
圖2 基于賬戶特征的檢測方法技術框架示意圖
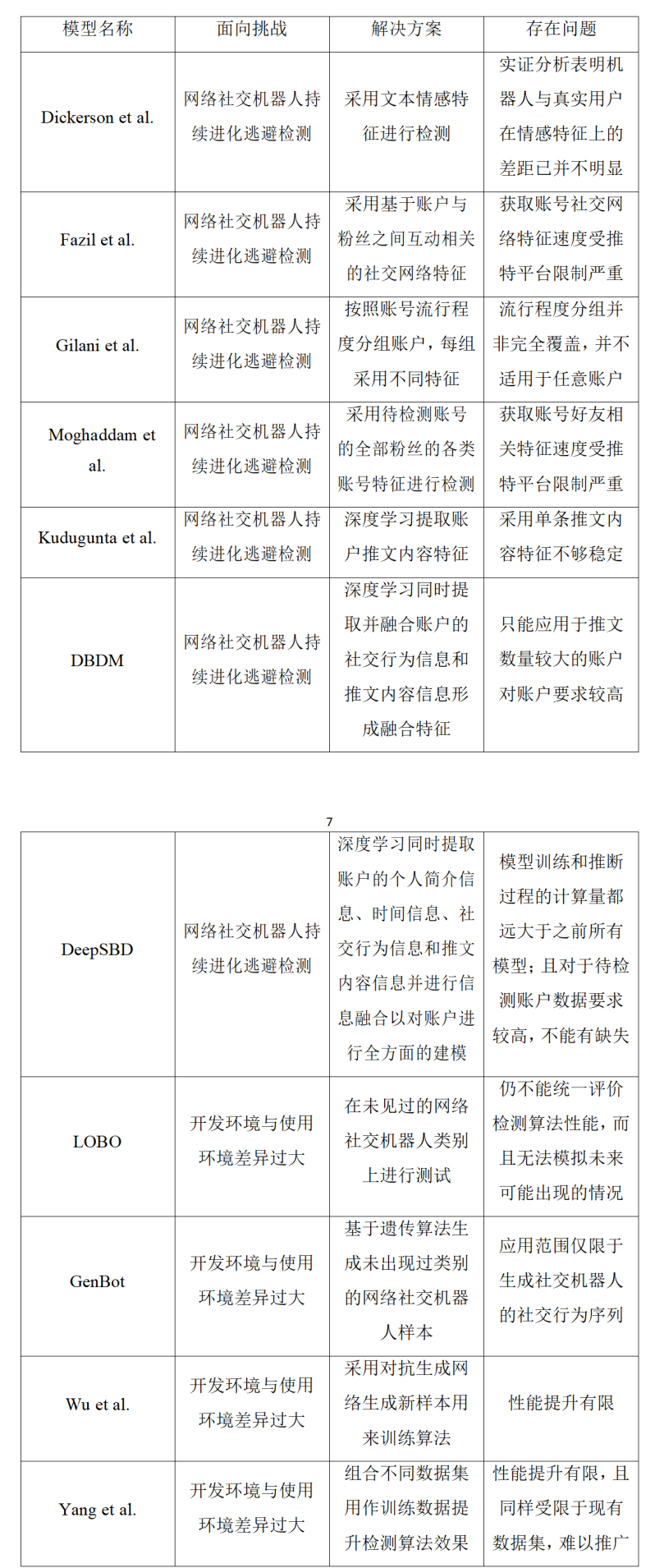
基于賬戶特征的方法因其檢測與部署服務門檻較低,相較于基于網絡結構的方法更加貼近實際應用,其中以Botometer為代表的公開檢測服務更是提高了公眾對于社交機器人的認識程度。Botometer主要通過由賬戶的個人特征、好友特征、時間相關特征、推文內容特征等構成的千余項特征執行推特上的社交機器人檢測任務,是一種面向推特各種類別社交機器人的通用檢測算法。但是受限于所采用的訓練數據和社交機器人的進化逃避檢測特性,Botometer的實際檢測準確率較低,難以發揮應有的維護社交網絡空間清朗的作用。研究人員為提升基于賬戶特征方法的性能付出了很多努力,產生的應對機器人進化逃避檢測和檢測算法開發環境與使用環境差異過大兩大挑戰的方式如表1所示。目前,研究人員逐步達成共識:網絡社交機器人難以操縱的特征或是操縱起來非常昂貴的特征是比較穩健的,較為適合應對網絡社交機器人進化逃避檢測的挑戰,比如待檢測賬號的全部粉絲的各類賬號特征。
表1 基于賬戶特征的方法解決兩類挑戰提出的算法
(二)基于網絡結構的方法
基于網絡結構的檢測方法可以按照是否使用賬戶特征再細分為兩類。不使用任何賬戶特征的一類不需要任何標注用戶或僅需少量種子節點用戶即可進行檢測,較有代表性的分別為基于聚類的方法和基于概率圖模型的方法。同時使用賬戶特征信息和機器人網絡協調傳播行為信息的一類則需要使用標注用戶,以標注用戶作為監督信號輔助推斷或以標注用戶訓練分類器,較有代表性的分別為基于圖神經網絡的方法以及結合分類器與概率圖模型的方法。
首先介紹不使用任何賬戶特征的完全基于網絡結構的方法。其中,基于聚類的方法的基本假設是不同的正常用戶社交行為之間存在較高異質性,用戶社交行為相似性較高則說明受到同一主體控制。這類方法的研究專注于網絡機器人社交行為信息提取方式,通過抽取對于網絡社交機器人檢測更加有效的信息提升檢測算法的性能。基于概率圖模型的方法的基本假設是社交機器人主要與社交機器人相互連接,難以與正常用戶建立社交關系。這類方法的研究專注于改進概率圖模型算法和修正網絡結構的方式,以引入更加符合實際情況的假設從而提升網絡社交機器人檢測算法的性能。由于這兩類方法不使用任何標注信息或僅使用少量標注信息,故其社交機器人檢測工作實質上是依賴于研究人員基于領域先驗知識所做假設來進行的,所以算法性能取決于研究人員的理解認知程度以及在算法中所采取的假設與實際情形的契合程度。相比之下,基于聚類的方法其基本假設與現實契合程度高于基于概率圖模型的方法。Cresci等人發現社交網絡中用戶的相似行為呈現出對數正態分布特性,證實了正常用戶行為具有較高的異質性。Yang等人發現社交機器人并不會形成緊密連接的社區,80%的機器人專注于與正常用戶建立社交關系。
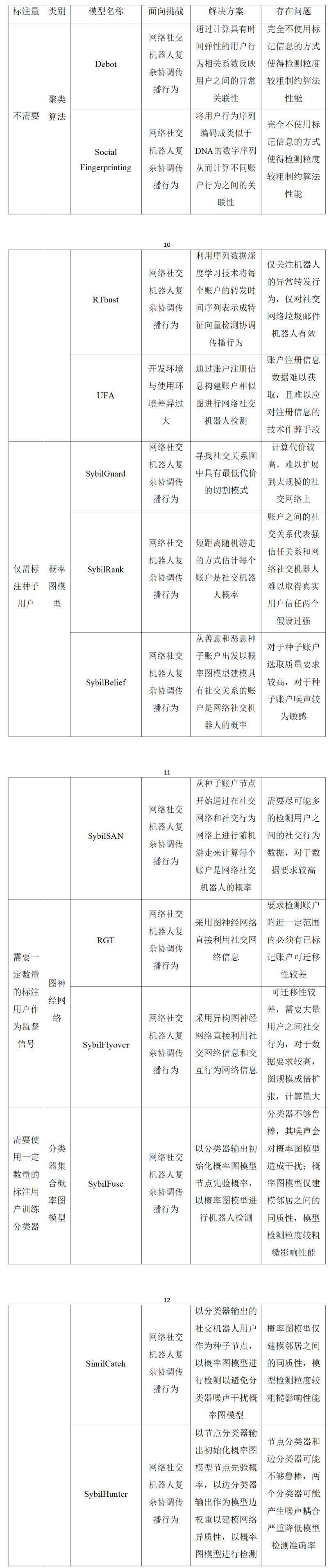
同時使用賬戶特征信息和機器人網絡協調傳播行為信息的檢測方法的初衷則是將用戶特征信息與網絡結構信息融合起來,以詳細的賬戶或行為信息補充較為粗糙的社交關聯信息來細化檢測粒度,以社交關聯信息指導檢測對抗僅依賴賬戶特征無法解決的機器人不斷進化逃避檢測問題。這種指導思想使得經過精心設計的同時使用賬戶特征和網絡結構的方法性能優于僅使用賬戶特征或網絡結構的方法。將用戶特征與網絡結構結合起來的方式主要有兩種:其一是圖神經網絡,這是一類端到端的將節點信息和結構信息結合起來的方法;其二是以分類器先將節點特征聚合起來形成先驗概率,再將先驗概率輸入概率圖模型,集成結構信息形成檢測結果的形式。這兩類方法仍然需要使用標注用戶數據,其中基于圖神經網絡的方法以標注信息作為監督信號以半監督直接推導的方式進行檢測,甚至需要待檢測賬戶網絡結構附近存在標注用戶,造成檢測算法可遷移性較差。而結合分類器與概率圖模型的算法同樣需要大量標注數據用來訓練分類器,還會因為分類器不夠魯棒,被進化逃避檢測的機器人特征信息欺騙,從而將噪聲傳入概率圖模型中,產生檢測效果仍然不盡如人意的問題。研究人員為提升基于網絡結構的方法的檢測效果,在應對社交機器人的復雜協調傳播行為挑戰方面做出了很多努力,典型方案如表2所示。但同時,我們也要注意到,因考慮動態網絡結構或早期檢測難度較高,故基于網絡結構的方法很少考慮開發環境與使用環境差異過大這個問題。
表2 基于網絡結構的方法解決兩類挑戰提出的算法
四、網絡社交機器人檢測的未來研究展望
目前,網絡社交機器人檢測仍然不能很好地解決三大挑戰,所以說網絡社交機器人檢測的發展仍然任重道遠,需要學術界和產業界的通力合作,只有這樣才能將網絡社交機器人操縱信息傳播、操控輿論等危害降到最低。對此提出未來的合作與發展方向:
(一)學術界與產業界需要在算法和數據方面通力合作
目前,對于學術界來說,網絡社交機器人檢測任務最大的困難在于數據集缺失和質量低下的現狀以及缺乏實際部署測試場景。現有數據集主要是各種類別網絡社交機器人的混合數據集且僅有是否為機器人的二值化標注信息。況且大量數據集是通過網絡社交機器人賬戶與隨機抽取的正常用戶賬戶組成的,對于這樣毫不相關的兩類賬戶來說,其檢測分類難度相對較低,容易造成檢測算法性能較差的問題。另外,現有數據集大多通過眾包形式人工標注或是通過蜜罐賬號引誘獲取,人類標注準確性不足、蜜罐賬號不具備普遍適用性,這也是現有數據集質量較差的重要原因。而學術界因不受產品效益制約,在檢測算法設計方面拘束較少,在研究過程中積累了很多值得參考的經驗。所以,雙方合作能夠更好地解決社交機器人檢測問題。
(二)不同學科需要在網絡社交機器人理解與識別方面通力合作
網絡社交機器人檢測研究需要集成各個學科的力量。網絡社交機器人的問題不單單是技術的問題,更是信息傳播的問題和社會的問題;當前研究普遍傾向于多極分化:計算機相關學科主要關注通過人工智能技術檢測網絡社交機器人,復雜系統相關學科主要關注社交機器人網絡及其行為演化分析,社會科學領域各學科則主要關注類似于確權問題、公平性問題、信息傳播問題等等。這種分裂的現狀使得各學科難以參考其他學科的先進研究成果,也不利于對網絡社交機器人進行詳細的類別劃分,有礙于研究人員深入認識網絡社交機器人。所以說,社交機器人的理解與識別需要各個學科聯合起來,從影響、技術、信息傳播、認知方式等多個角度思考,進行深入詳細的歸類和闡釋。
(三)同時采用用戶特征與網絡結構的檢測方法是未來的發展方向
單獨使用結構信息進行檢測會因信息不充分只能采用鄰居同質性假設,產生檢測粒度粗糙問題影響算法性能;單獨使用用戶特征信息進行檢測又會因為將賬號視為單獨個體,難以對抗機器人進化逃避檢測問題。況且,在機器人賬號創建初期,其賬號特征與正常用戶差距并不太大。因此,將用戶特征信息與網絡結構融合起來,以用戶特征指導基于網絡結構的檢測方法,同時建模網絡的同質性與異質性,細化其檢測粒度才能實現高準確度高可靠性的機器人檢測算法。
(四)網絡社交機器人的早期檢測算法與注冊時檢測算法才是真正需求
目前的檢測手段大多只能檢測已經開始根據特定目的散播消息的機器人,難以應對新產生的機器人類別,無法將尚未散播消息的機器人與正常用戶區別開來,更無法在注冊賬號階段就將機器人攔截下來。這樣的算法只能算是亡羊補牢,在發現機器人的社會影響之后避免其進一步擴散,無法實現防患于未然。想要徹底杜絕機器人對網絡環境的惡意影響,只有在其尚未發帖的構建社交網絡階段甚至是注冊時就將其標記出來,一旦出現問題,立刻暫停賬號。所以說,網絡社交機器人早期檢測算法與注冊時檢測算法才是真正需要的檢測算法。
綜上所述,現有的網絡社交機器人檢測算法仍不能緩解機器人操控網絡環境的風險。未來需要學術界各學科之間、學術界與產業界通力合作,深化對于網絡社交機器人的認識,制定更加精確、全面的檢測算法訓練和測試數據集,構建高精度的能夠對抗進化的全自動和半自動機器人的檢測算法。在此基礎上,全面厘清機器人與正常用戶之間的區別,構建有效的早期檢測算法,實現防患于未然的效果。
審核編輯:湯梓紅
-
機器人
+關注
關注
212文章
29274瀏覽量
210842 -
網絡
+關注
關注
14文章
7712瀏覽量
90128 -
人工智能
+關注
關注
1804文章
48444瀏覽量
244841 -
檢測算法
+關注
關注
0文章
121瀏覽量
25402
原文標題:社交機器人檢測研究概述與展望
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
智能機器人的三大關鍵技術詳解
哈工大:服務機器人的六大關鍵技術
智能語音機器人
淺析機器人技術及其應用
基于深度學習技術的智能機器人
機器人技術和機器學習
Cobot機器人的關鍵技術解析






 工商網監
工商網監

評論