

作者|湯昕宇
隨著大語言模型的發展,其在執行許多自然語言處理任務上取得了巨大的成功。但是,大語言模型對于提示是非常敏感的,提示中微小的變化都會導致大語言模型在執行任務時產生巨大的性能波動。因此,許多工作對大語言模型的提示進行了研究。本文主要從增強的提示方法,提示的自動優化和關于提示的分析三個方面,調研了大語言模型提示的最新進展。
增強的提示方法
盡管基本的CoT提示策略在復雜推理任務中展示出了強大的能力,但它仍然面臨著一些問題,比如推理過程存在錯誤和不穩定等。因此,一系列的研究通過增強的提示方法激發大語言模型的能力,從而完成更通用的任務。
Explanation Selection Using Unlabeled Data for Chain-of-Thought Prompting
作者:Xi Ye, Greg Durrett
https://arxiv.org/abs/2302.04813
這篇論文討論了如何優化大語言模型的解釋式提示,以提高其在文本推理任務上的表現。
作者提出了一種新穎的兩階段框架,以黑盒方式優化這些解釋式提示。首先,為每個提示中的樣例生成多種候選解釋,并使用兩個指標:對數似然和新例子上的準確性來評估這些解釋。然后,通過評估這些組合對來尋找最有效的解釋組合。文章證明了這種方法在各種文本推理任務上,包括問答、數學推理和自然語言推理中,能夠提高提示的有效性。
此外,這篇工作還強調了他們評估的指標的有效性,有助于識別和優先考慮效果最好的解釋組合,從而優化所需的計算資源。
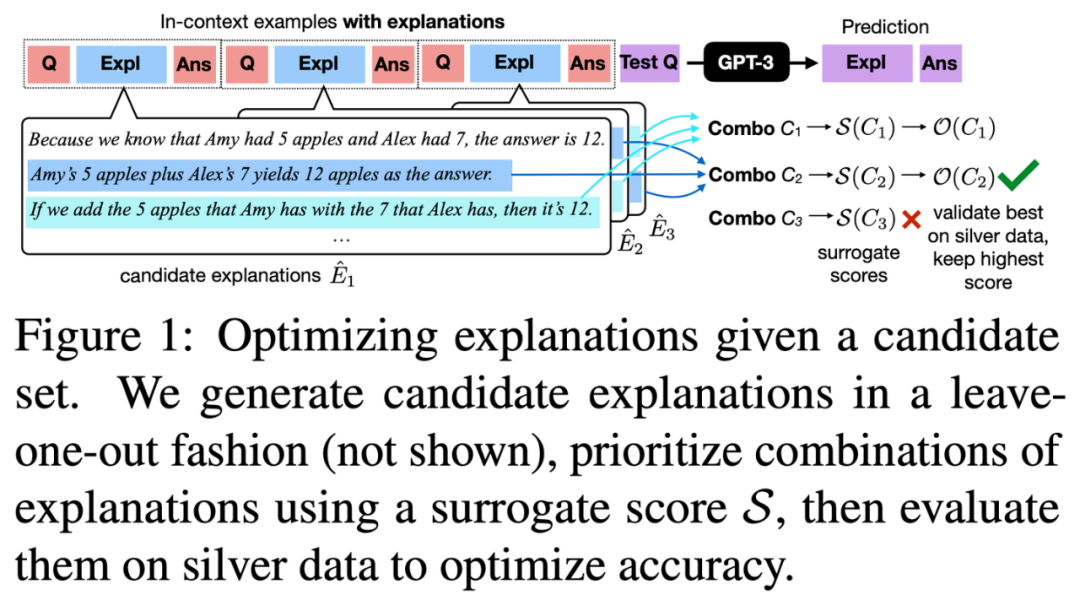
Explanation Selection Using Unlabeled Data for Chain-of-Thought Prompting
CoF-CoT: Enhancing Large Language Models with Coarse-to-Fine Chain-of-Thought Prompting for Multi-domain NLU Tasks
作者:Hoang H. Nguyen, Ye Liu, Chenwei Zhang, Tao Zhang, Philip S. Yu
https://arxiv.org/abs/2310.14623
盡管思維鏈的方法在推理任務中頗受歡迎,但其在自然語言理解任務中的潛力尚未被充分挖掘。
本文受到大語言模型進行多步推理的啟發,提出了從粗到細的思維鏈(CoF-CoT)方法,該方法將自然語言理解任務分解為多個推理步驟,用基于語義的抽象意義表示結構化知識作為中間步驟,以捕捉話語的細微差別和多樣結構,以便大語言模型獲取并利用關鍵概念以從不同的粒度解決任務。
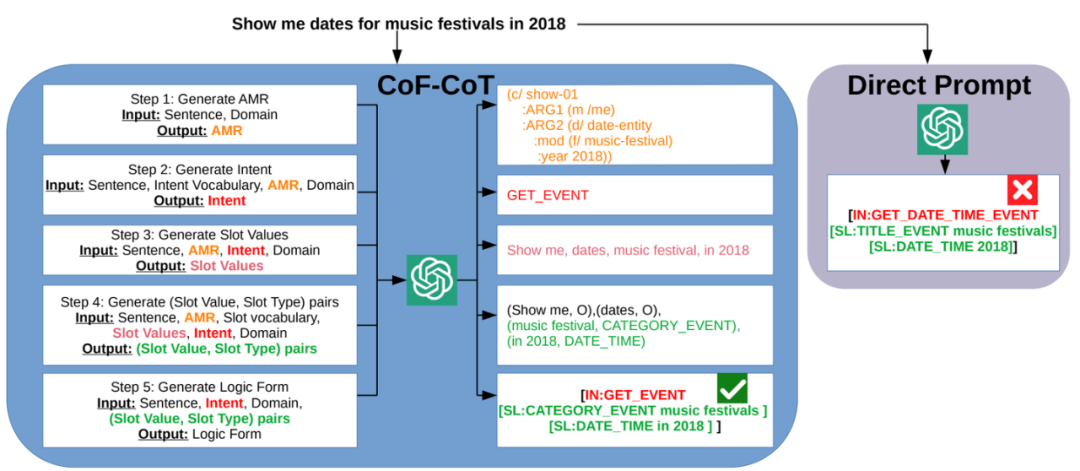
CoF-CoT
Chain of Code: Reasoning with a Language Model-Augmented Code Emulator
作者:Chengshu Li, Jacky Liang, Andy Zeng, Xinyun Chen, Karol Hausman, Dorsa Sadigh, Sergey Levine, Li Fei-Fei, Fei Xia, Brian Ichter
https://arxiv.org/abs/2312.04474
代碼提供了構建復雜程序和進行精確計算的通用語法結構,當與代碼解釋器配對時,大語言模型可以利用編寫代碼的能力來改進思維鏈推理。因此,代碼可以幫助語言模型更好地進行推理,特別是在涉及邏輯和語義混合的任務中。
本文提出了代碼鏈(Chain of Code),旨在提升語言模型在處理邏輯、算術以及語義任務時的推理能力。利用大語言模型將語義子任務格式轉化為靈活的偽代碼,解釋器可以明確捕捉到未定義的行為,并將其交給大語言模型來模擬執行。實驗表明,“代碼鏈”在各種基準測試中都超越了“思維鏈”(Chain of Thought)和其他基線方法;在BIG-Bench Hard測試中,“代碼鏈”達到了84%的準確率,比“思維鏈”高出12%。

Chain of Code
Tree Prompting: Efficient Task Adaptation without Fine-Tuning
作者:John X. Morris, Chandan Singh, Alexander M. Rush, Jianfeng Gao, Yuntian Deng
https://arxiv.org/abs/2310.14034
盡管提示是讓語言模型適應新任務的常用方法,但在較小的語言模型中,相比于基于梯度的微調方法,這種方法在準確度上通常較低。
針對這一挑戰,本文提出了一種“樹形提示(Tree Prompting)”的方法。這種方法建立了一個決策樹狀的提示系統,將多個語言模型調用串聯起來,協同完成特定任務。在推理階段,每一次對語言模型的調用都依靠決策樹來高效地確定,基于前一次調用的結果進行決定。實驗結果表明,在各種分類任務的數據集上,樹形提示不僅提升了準確性,而且與微調方法相比更具有競爭力。
Tree Prompting
Everything of Thoughts: Defying the Law of Penrose Triangle for Thought Generation
作者:Ruomeng Ding, Chaoyun Zhang, Lu Wang, Yong Xu, Minghua Ma, Wei Zhang, Si Qin, Saravan Rajmohan, Qingwei Lin, Dongmei Zhang
https://arxiv.org/abs/2311.04254
有效的思維設計需要考慮三個關鍵方面:性能、效率和靈活性。然而,現有的思維設計最多只能體現這三個屬性中的兩個。為了突破現有思維范式的“彭羅斯三角形定律”局限,本文引入了一種創新的思維提示方法,稱為“Everything of Thought”(XoT)。
XoT運用了預訓練的強化學習和蒙特卡洛樹搜索,將外部領域知識整合進思維中,從而增強大語言模型的能力,并使其能夠高效地泛化到未見過的問題。通過利用蒙特卡羅搜索和大語言模型的協作思維修正框架,這種方法可以自主地產生高質量的全面認知映射,并且只需最少的大語言模型的交互。此外,XoT賦予了大語言模型進行無約束思維的能力,為具有多重解決方案的問題提供靈活的認知映射。實驗表明,XoT在包括24點游戲、8數碼、口袋魔方等多個具有挑戰性的多解決方案問題上超過了現有方法。
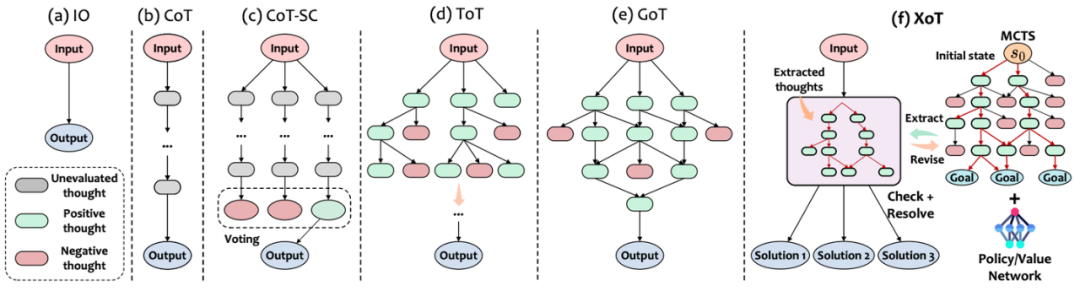
XoT
提示優化方法
提示是利用大語言模型解決各種任務的主要方法。由于提示的質量在很大程度上會影響大語言模型在特定任務中的表現,因此出現了一系列研究,旨在通過手動創建或自動優化來生成適當的任務提示。雖然手動創建任務提示更直觀,但這個過程非常耗時,更重要的是,模型對精心設計的提示非常敏感——不恰當的提示將導致任務表現不佳。因此,一系列的研究自動優化離散提示,以激發大語言模型解決特定任務的能力。
Prompt Optimization via Adversarial In-Context Learning
作者:Xuan Long Do, Yiran Zhao, Hannah Brown, Yuxi Xie, James Xu Zhao, Nancy F. Chen, Kenji Kawaguchi, Michael Qizhe Xie, Junxian He
https://arxiv.org/abs/2312.02614
adv-ICL方法借鑒了對抗生成網絡的思想,通過采用三個不同的大語言模型,分別作為生成器、辨別器和提示修改器來優化提示。在這個對抗性學習框架中,生成器和鑒別器之間進行類似于傳統對抗性學習的雙邊游戲,其中生成器嘗試生成足夠逼真的輸出以欺騙鑒別器。
具體來說,在每一輪中,首先給定包含一個任務指令和幾個樣例的輸入,生成器產生一個輸出。然后,辨別器的任務是將生成器的輸入輸出對分類為模型生成的數據還是真實數據。基于辨別器的損失,提示修改器會提出對生成器和辨別器提示的編輯,選擇最能改善對抗性損失的文本修改方法以優化提示。實驗表明,adv-ICL在11個生成和分類任務上取得了顯著的提升,包括總結、算術推理、機器翻譯、數據到文本生成,以及MMLU和Big-Bench Hard基準測試。
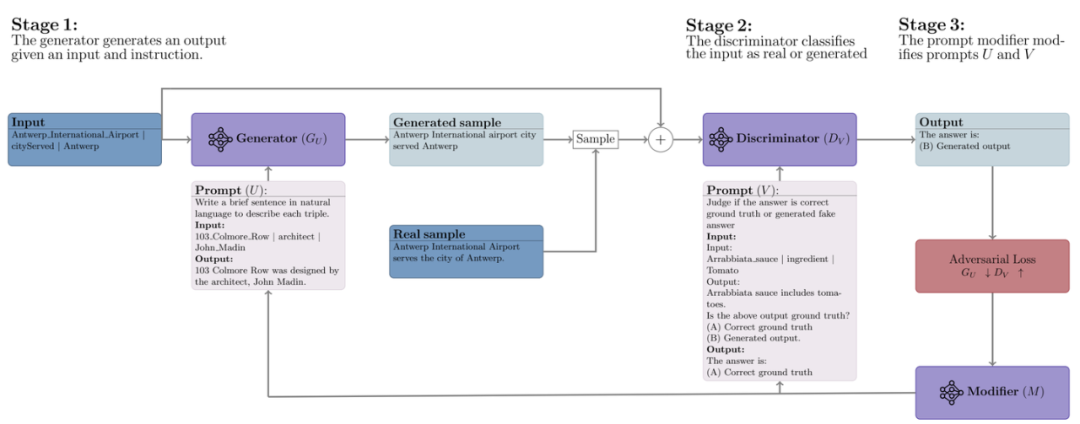
adv-ICL
Black-Box Prompt Optimization: Aligning Large Language Models without Model Training
作者:Jiale Cheng, Xiao Liu, Kehan Zheng, Pei Ke, Hongning Wang, Yuxiao Dong, Jie Tang, Minlie Huang
https://arxiv.org/abs/2311.04155
雖然大語言模型在多種任務中展現了令人印象深刻的成功,但這些模型往往與人類的意圖不完全對齊。為了使大語言模型更好地遵循用戶指令,現有的方法主要集中在對模型進行額外的訓練上。然而,額外訓練大語言模型通常計算開銷很大;并且,黑盒模型往往無法進行用戶需求的訓練。
本文提出了BPO的方法,從不同的視角——通過優化用戶的提示,來適應大語言模型的輸入理解,從而在不更新大語言模型參數的情況下實現用戶意圖。實驗表明,通過BPO對齊的大語言模型在性能上可以勝過使用PPO和DPO對齊的相同模型,并且將BPO與PPO或DPO結合,還可以帶來額外的性能提升。
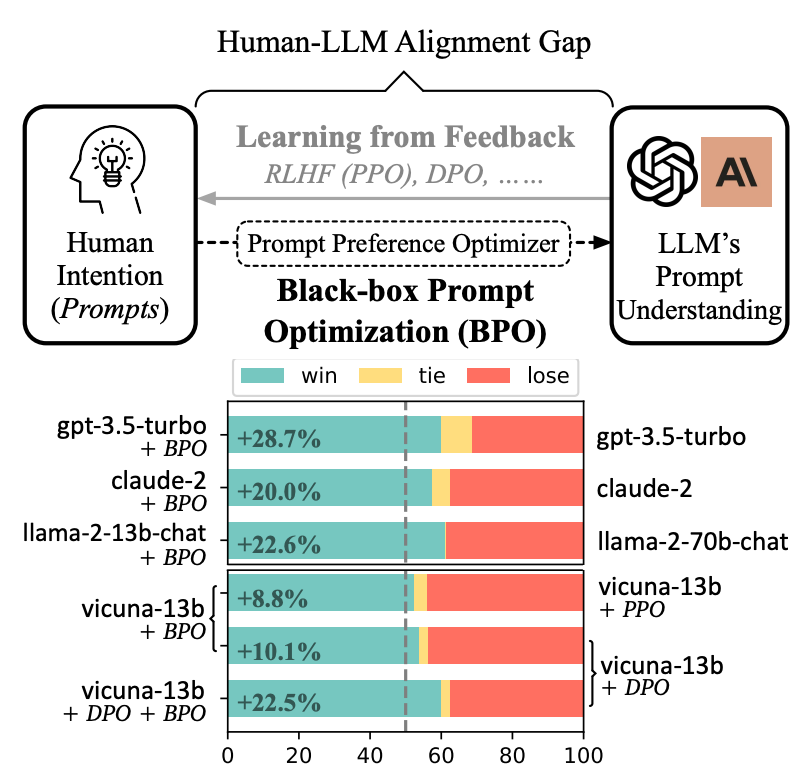
BPO
Robust Prompt Optimization for Large Language Models Against Distribution Shifts
作者:Moxin Li, Wenjie Wang, Fuli Feng, Yixin Cao, Jizhi Zhang, Tat-Seng Chua
https://arxiv.org/abs/2305.13954
大語言模型在多種自然語言處理任務中展現了顯著的能力。然而,它們的效果高度依賴于任務的提示。本文發現,雖然自動的提示優化技術使用帶標注的任務數據能帶來性能上的提升,但這些自動提示優化的技術容易受到分布偏移的影響,這在實際應用場景中是很常見的。基于此,本文提出了一個新問題,針對分布變化對大語言模型進行穩定的提示優化,這要求在具有標簽的源數據上優化的提示同時能夠泛化到未標記的目標數據上。
為了解決這個問題,本文提出了一種名為“泛化提示優化”(Generalized Prompt Optimization)的框架,將來自目標組的未標記數據納入提示優化中。廣泛的實驗結果表明,本文提出的框架在未標注的目標數據上有顯著的性能提升,并且在源數據上保持了性能。這表明該方法在在面對分布變化時,展現出處理真實世界數據時的有效性和魯棒性。
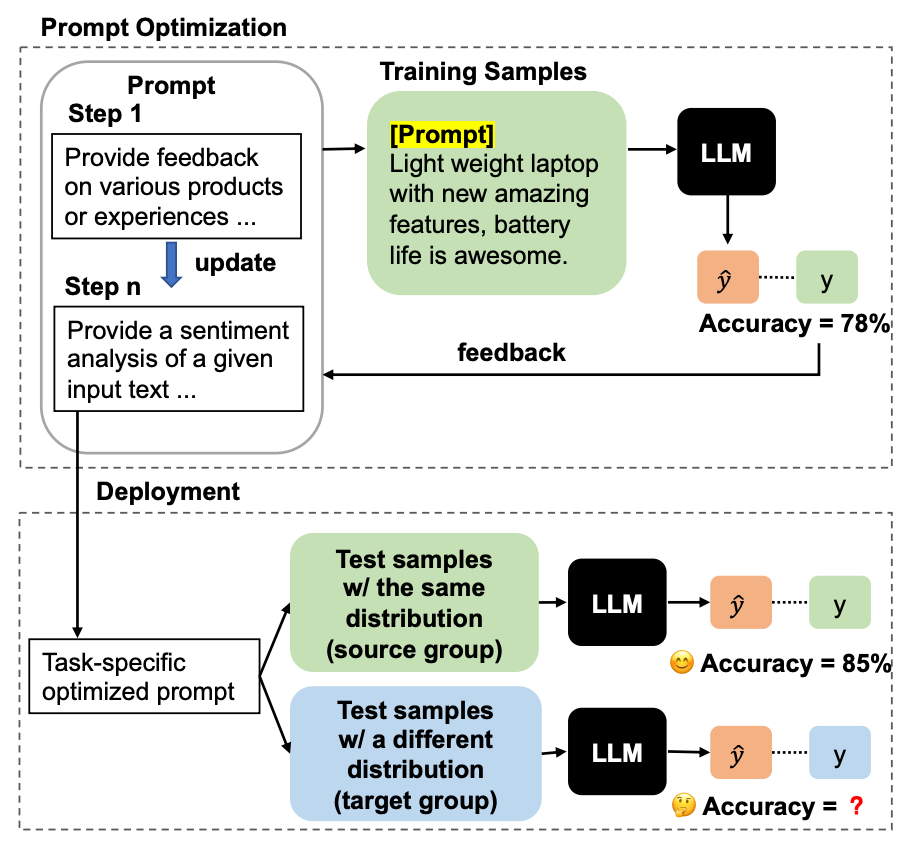
Robust Prompt Optimization
InstOptima: Evolutionary Multi-objective Instruction Optimization via Large Language Model-based Instruction Operators
作者:Heng Yang, Ke Li
https://arxiv.org/abs/2310.17630
在大語言模型中,基于指令的語言建模受到了顯著的關注。然而,指令工程的效率仍然較低,最近的研究集中在自動化生成指令上,但它們主要旨在提高性能,而沒有考慮影響指令質量的其他重要目標,例如指令長度和困惑度。
因此,本文提出了一種新穎的方法(InstOptima),將指令生成視為一個進化的多目標優化問題。與基于文本編輯的方法不同,本文的方法利用大語言模型來模擬指令操作,包括變異和交叉。此外,本文的方法還為這些操作引入了一個目標引導機制,允許大語言模型理解目標并提高生成指令的質量。實驗結果證明了InstOptima在自動化生成指令和提升指令質量方面的有效性。
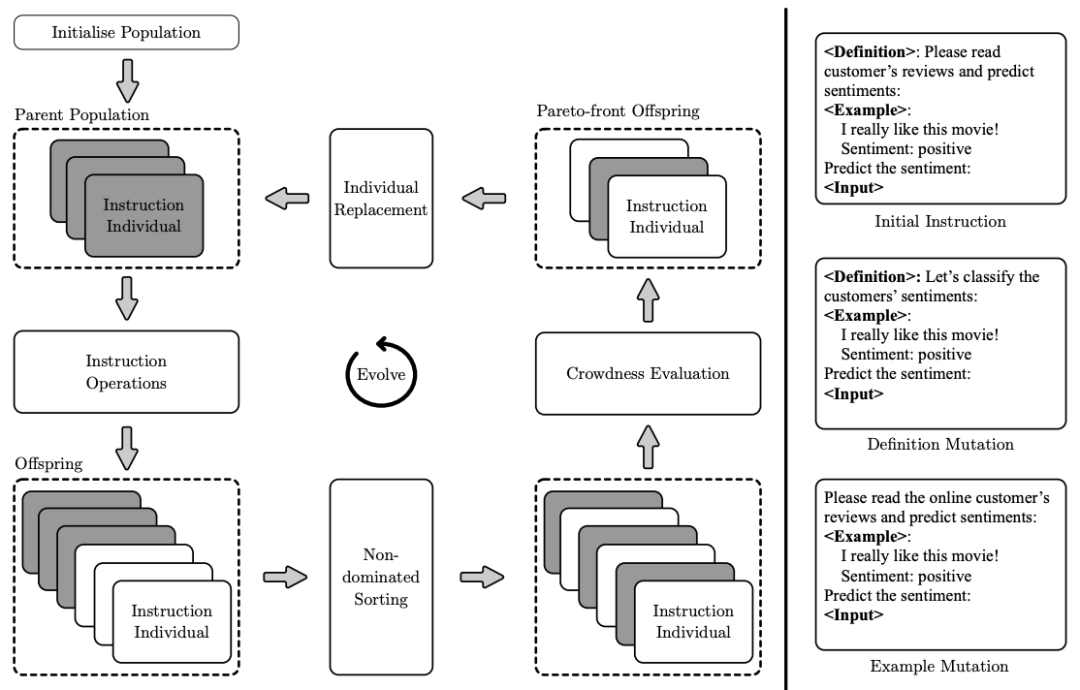
InstOptima
關于提示的分析
How are Prompts Different in Terms of Sensitivity?
作者:Sheng Lu, Hendrik Schuff, Iryna Gurevych
https://arxiv.org/abs/2311.07230
上下文學習(ICL)已成為十分受歡迎的學習范式之一。盡管目前有越來越多的工作關注于提示工程,但在比較不同模型和任務提示效果的方面,缺乏系統性地分析。因此,本文提出了一種基于函數敏感性的全面提示分析。
本文的分析揭示了敏感性是模型性能的一種無監督代理指標,它與準確度呈現出強烈的負相關關系。本文使用基于梯度的顯著性分數展示了不同提示如何影響輸入對輸出的相關性,從而產生不同水平的敏感性。此外,本文引入了一種基于敏感性感知的解碼方式,將敏感性估計作為懲罰項納入標準的貪婪解碼中。實驗表明,這種方法在輸入信息稀缺時十分有效。
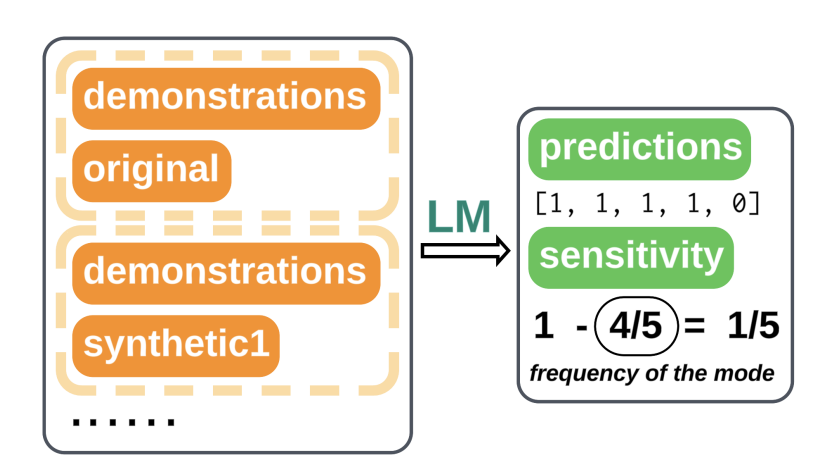
How are Prompts Different in Terms of Sensitivity?
The language of prompting: What linguistic properties make a prompt successful?
作者:Alina Leidinger, Robert van Rooij, Ekaterina Shutova
https://arxiv.org/abs/2311.01967
盡管大語言模型的表現高度依賴于提示的選擇,目前仍缺乏對于提示的語言屬性如何與任務表現相關聯的系統性分析。
在這項工作中,文章研究了不同大小、預訓練和指令調優過的大語言模型,在語義上等價但在語言結構上有所不同的提示上的表現。本文著重考察了諸如語氣、時態、情感等語法屬性,以及通過同義詞使用引入的詞匯-語義變化。研究結果與普遍的假設相悖,大語言模型在低困惑度的提示上達到最優表現,這些提示反映了預訓練或指令調優數據中使用的語言。提示在不同數據集或模型之間的可遷移性較差,且性能通常不能通過困惑度、詞頻、歧義性或提示長度來解釋。
審核編輯:黃飛
-
生成器
+關注
關注
7文章
322瀏覽量
21440 -
語言模型
+關注
關注
0文章
552瀏覽量
10519 -
自然語言處理
+關注
關注
1文章
624瀏覽量
13823
原文標題:一文速覽大語言模型提示最新進展
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
風光互補技術及應用新進展
風光互補技術原理及最新進展
DIY懷表設計正式啟動,請關注最新進展。
車聯網技術的最新進展
VisionFive 2 AOSP最新進展即將發布!
Topic醫療開發平臺的最新進展
工業機器人市場的最新進展淺析
ASML***的最新進展

百度首席技術官王海峰解讀文心大模型的關鍵技術和最新進展






 工商網監
工商網監

評論