 基于大語言模型辯論的多智能體協作推理分析
基于大語言模型辯論的多智能體協作推理分析
背景及動機
最近,像ChatGPT這樣的大型語言模型(LLMs)在一定程度上展現出了通用智能 [1],并且 LLMs 已被廣泛用作各種應用中的基礎模型 [2,3]。為了解決依稀更復雜的任務,多個 LLMs 被引入來進行協作,不同的 LLMs 執行不同的子任務或同一任務的不同方面 [4,5]。有趣的是,這些 LLMs 是否擁有協作精神?它們是否能有效并高效地協作,實現一個共同的目標?
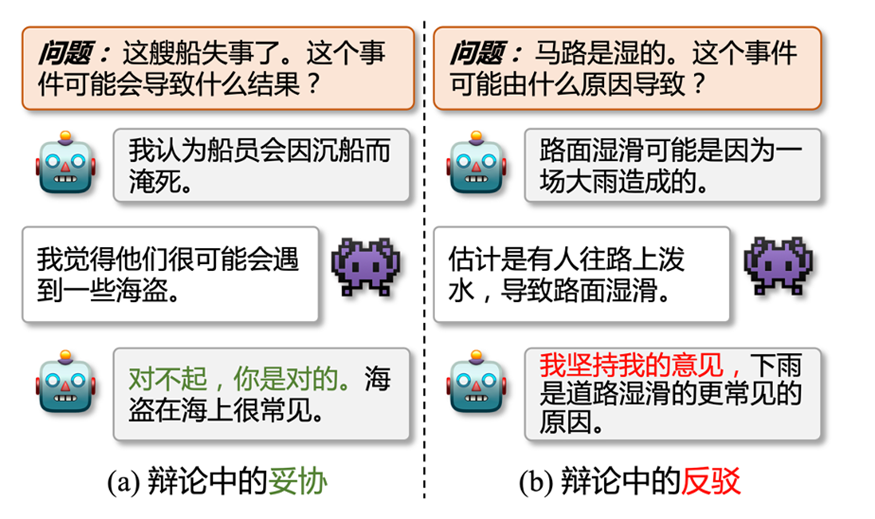
圖1: 辯論中的妥協 (a) 和反駁 (b),其中是正方,是反方
這篇論文中,我們探討了多個 LLMs 之間的一致性 (inter-consistency),這與現有的大部分研究不同,現有研究主要探討單個 LLM 內的自我一致性 (intra-consistency 或 self-consistency) 問題 [6,7]。基于我們的觀察和實驗,我們強調了LLMs協作中的可能存在的兩個主要問題。首先,LLMs 的觀點很容易發生改變。如圖1(a)所示,正方和反方 LLMs 給出了不同的預測結果,而正方很快就妥協并接受了反方的答案。所以,LLMs 到底有多容易改變自己的觀點,又有多大程度會堅持自己的觀點?其次,當 LLMs 堅持自己的意見時 (圖1(b)),他們進行協作時是否能在共同目標上達成共識?
受辯論理論 [8] 的啟發,我們設計了一個辯論框架 (FORD),以系統和定量地研究 LLMs 協作中的模型間不一致問題。基于 FORD,我們允許 LLMs 通過辯論探索它們自己的理解與其他 LLMs 的概念之間的差異。因此,這些結果不僅能夠鼓勵 LLMs 產生更多樣化的結果,也使得 LLMs 可以通過相互學習實現性能提升。
具體來說,我們以多項選擇的常識推理作為示例任務,因為常識推理任務是一類可能性 (plausible) 的任務,每個答案都是可能成立的,只是正確答案成立的可能性更高,所以常識推理任務更適合被用來進行辯論。為此我們制定了一個三階段的辯論來對齊現實世界的場景:(1)平等辯論:兩個具有可比能力的 LLMs 之間的辯論。(2)錯位辯論:能力水平差異較大的兩個 LLMs 之間的辯論。(3)圓桌辯論:兩個以上的 LLMs 之間的辯論。
2. 數據集、LLMs及相關定義
我們在這里統一介紹實驗使用的數據集,LLMs,模型間不一致性的定義,以及使用的基線方法等。
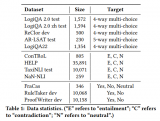
2.1 數據集(常識推理)
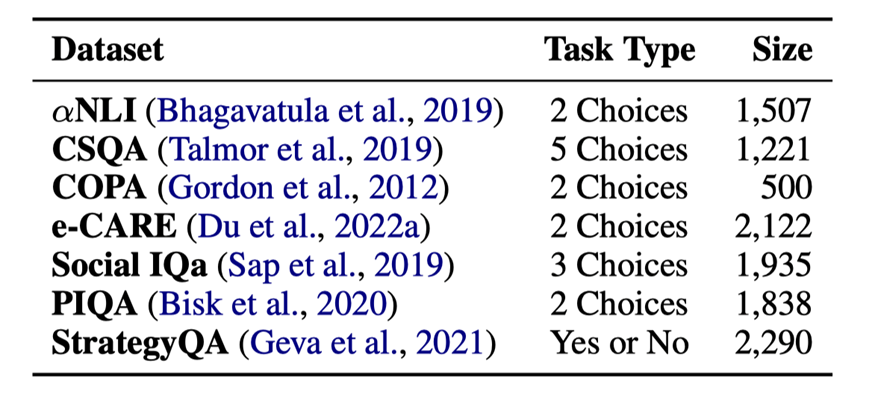
表1:7個常識推理數據的任務類型和大小
?NLI [9]:大規模的溯因推理數據集
?CommonsenseQA[10]:大規模的常識問答數據集
?COPA[11]:小規模的因果推理數據集
?e-CARE[12]:大規模的可解釋因果推理數據集
?SocialIQa [13]:有關日常事件的社會影響的常識推理數據集
?PIQA [14]:有關物理常識的自然語言推理數據集
?StrategyQA[15]:有關隱式推理策略的數據集
數據集的統計信息見表1。
2.2大語言模型(LLMs)
我們在辯論中使用了以下 6 個 LLMs 進行實驗:
?閉源模型
–gpt-3.5-turbo:記作ChatGPT,是一個對話補全模型
–gpt-3.5-turbo-0301:記作ChatGPT-0301,是gpt-3.5-turbo的迭代版本
–text-davinci-003:記作Davinci-003,是一個文本補全模型
–gpt-4:記做GPT-4,是一個更強的對話補全模型
?開源模型
–LLaMA-13B:記作LLaMA,是Meta公司開源的擁有13B參數的文本補全模型
–Vicuna-13B:記作Vicuna,是在70K指令數據上微調后的LLaMA模型
2.3模型間的不一致性 (INCON)
假設我們有 個 LLMs:,以及一個擁有 個樣例的數據集:。我們將 定義為 在 的預測結果。則模型間的不一致性 INCON 可以被定義為:
其中 是一個符號函數,當 中存在兩個任意的變量不相等, 取 1,否則 取 0。
2.4基線方法
我們定義了 3 種基線方法來和辯論框架進行對比:
?SingleLLM:只用一個 LLM 來執行推理
?Collaboration-Soft(Col-S):隨機相信其中一個 LLM 的結果,所以這個方法的性能是多個 LLMs 的性能的平均
?Collaboration-Hard(Col-H):只相信一致的預測,不一致的的預測都看作是錯誤的
3.辯論框架 (FORD)
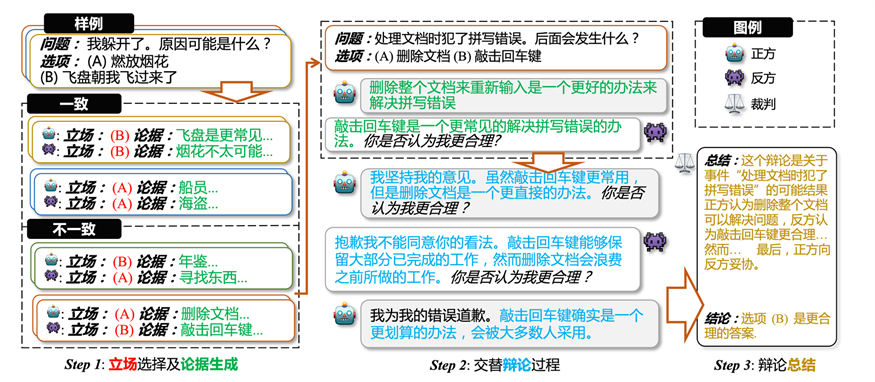
圖2 辯論框架,(1) LLMs 對每一個樣例,獨立地給出選項和解釋作為立場和論據;(2) 在立場不一致的樣例上面,基于第一步的論據,LLMs 交替式地進行辯論;(3) 裁判對辯論過程進行總結并給出最終的辯論結果
?Step1:對于給定的每個樣例,每個 LLM 都單獨進行回答,生成一個答案和解釋,答案和解釋則作為相關 LLM 在此樣例上的立場和初始論據。根據 LLMs 在每個樣例上的立場,把樣例分為立場一致的樣例和立場不一致的樣例,只有立場不一致的樣例才會進行辯論。
?Step2:對于每個立場不一致的樣例,基于初始的兩個論據,LLMs 交替地進行辯論。在辯論期間,LLMs 可以堅持自己的看法,也可以向其它更合理的看法妥協,每次辯論都會生成一個新的立場和新的論據,但是新的立場不會放入辯論過程中。辯論會在達成共識或者是輪次達到上限時停止。
?Step3:最后我們會根據辯論過程中立場的變化,使用啟發式的方法,對辯論進行最后的總結,并得到最終的辯論結果。當 LLMs 達成共識的時候,一致的立場作為最終結果,若沒達成一致,則不同論據的立場進行投票得到最終結果。
4.實驗
考慮到不同 LLMs 在不同數據集上的表現,我們設置一下辯論進行討論 (對于兩個 LLMs 的辯論來說,& 符號左邊是正方,右邊是反方):
?平等辯論
–ChatGPT& Davinci-003
–ChatGPT& ChatGPT-0301
–LLaMA& Vicuna
?錯位辯論
–ChatGPT& GPT-4
–LLaMA& ChatGPT
?圓桌辯論
–ChatGPT & Davinci-003 & GPT-4 (錯位的圓桌辯論)
–ChatGPT & Davinci-003 & ChatGPT-0301 (平等的圓桌辯論)
4.1平等辯論
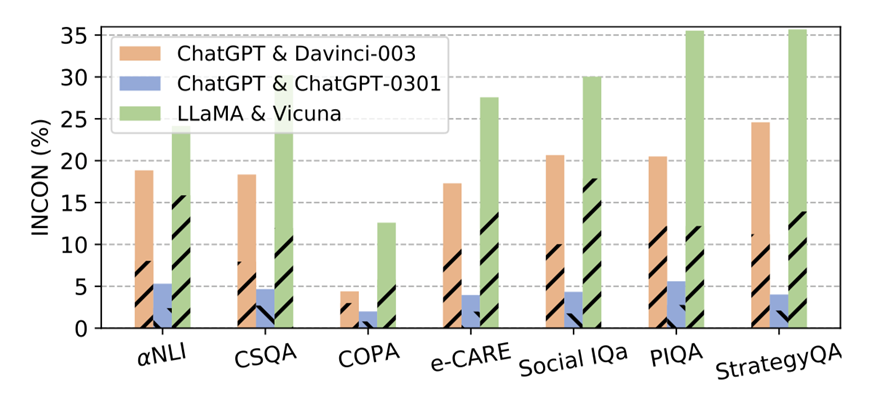
圖 3:平等辯論中,各 LLMs 對在不同數據集上的不一致性。虛線部分代表正方模型預測錯誤而反方模型預測正確帶來的不一致性。
4.1.1不一致性
我們首先執行辯論框架的第一步,來得到不同辯論中,LLMs之間的不一致性。結果如圖3所示,我們可以得到以下結論:
?不同類型(文本補全和對話補全,有無指令微調)的LLMs之間(ChatGPT & Davinci-003, LLaMA & Vicuna)在幾乎所有數據集上都持有20%-30%的INCON,即使它們是基于相同的基礎模型開發的。每個條形中的虛線部分對INCON的貢獻接近50%,這意味著每個LLMs對中的LLM擁有可比但截然不同的能力。
?對于ChatGPT & ChatGPT-0301,ChatGPT-0301在功能上并不會完全覆蓋ChatGPT。這表明LLMs在迭代過程中獲得了新的能力的同時,也會失去一些現有的能力。因此,使用更新的LLMs來復現不可用的早期版本的LLMs的結果并不會令人信服。
4.1.2 平等辯論的結果
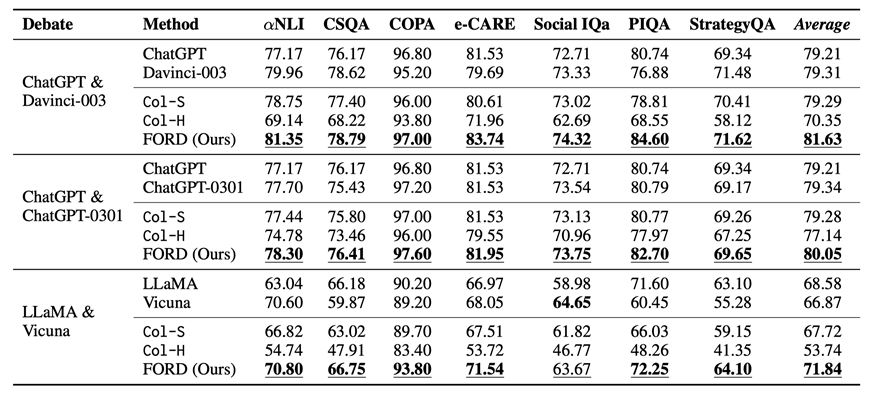
表 2:平等辯論及基線方法在不同數據上的表現。帶下劃線的數字表示在三種協作模型中最好的結果,加粗的數字代表在單模型和協作模型中最好的結果。Average表示不同模型在所有數據集上的平均性能。
平等辯論及基線方法的表現如表 2 所示,我們可以得到以下結論:
?FORD在幾乎所有數據集上都優于Col-S和Col-H,以及相應的單一LLM(除了 Social IQa 上的 LLaMA & Vicuna)。這是因為FORD可以讓 LLMs 從更全面、更精確的視角來看待問題。這意味著具有可比能力的LLMs擁有協作精神,可以有效且高效地實現共同目標。
?而 FORD 在 ChatGPT & ChatGPT-0301 上并沒有獲得像其他辯論那樣多的提升。這主要是由于它們的能力非常相似,導致它們通常對每個樣本都有相似的看法,使得性能提升微不足道。
?在每個數據集上,ChatGPT & ChatGPT-0301 具有更高的性能下限 (Col-H),這表明我們可以選擇類似的模型進行辯論獲得保守的收益。然而 ChatGPT & Davinci-003 具有更高的性能上限 (FORD),這表明我們可以選擇能力可比但差異較大的 LLMs 進行辯論以獲得更好的性能。
4.1.3辯論中不一致性的變化
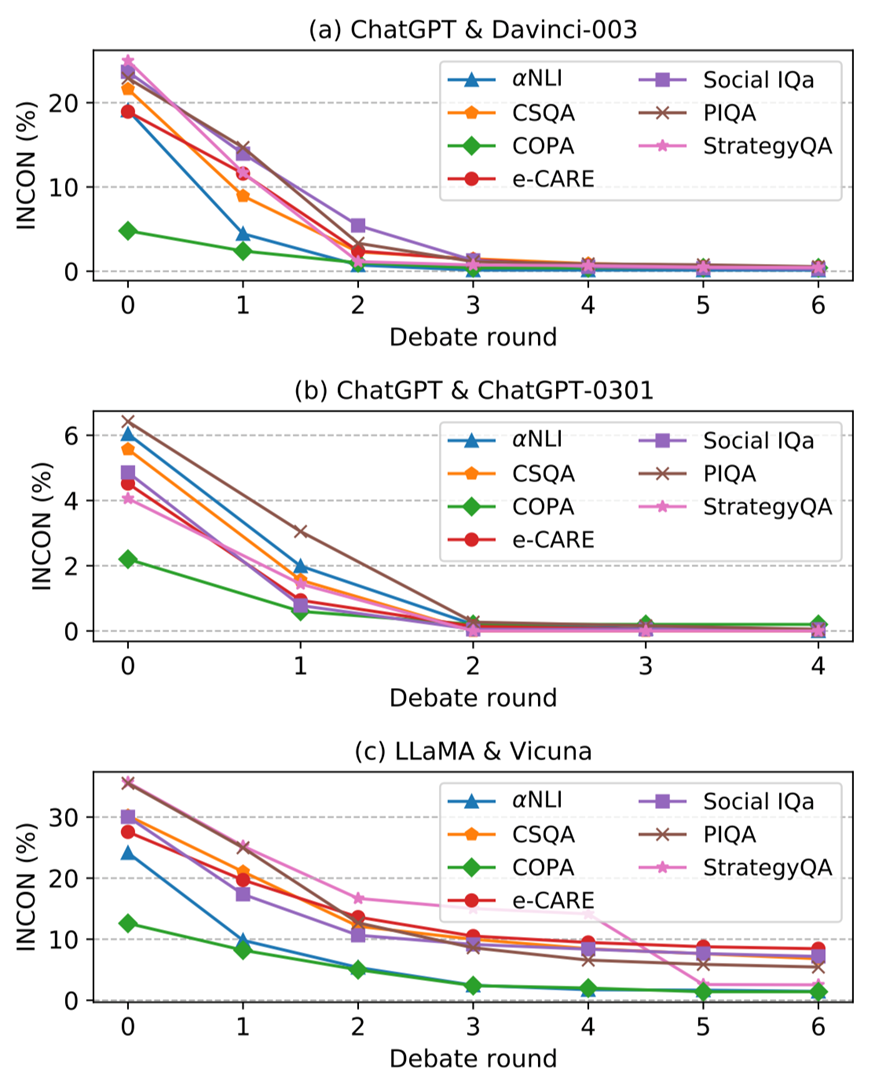
圖 4:隨著辯論的進行,(a) ChatGPT & Davinci-003, (b)ChatGPT & ChatGPT-0301, 以及 (c) LLaMA & Vicuna 的不一致性(INCON) 變化。
圖 4 展示了平等辯論的不一致性INCON隨著辯論輪次的變化,從中我們可以總結如下結論:
?對于每場公平辯論,每個數據集的每一輪后INCON都會逐漸下降。這是因為 LLMs 可以從彼此之間的差異中學習從而達成一致,這表明能力可比的LLMs可以進行辯論并在共同目標上達成共識。
?對于 ChatGPT &Davinci-003 和 ChatGPT &ChatGPT-0301,INCON在所有數據集上幾乎下降到 0,而LLaMA & Vicuna 經過辯論后仍然存在較為明顯的不一致性。我們認為這是由于它們的能力差距造成的。
?ChatGPT & ChatGPT-0301 的INCON經過 2 輪就實現了收斂,比其他公平辯論要早。這主要是因為它們的能力非常相似,導致它們更早達成共識。
4.2錯位辯論
4.2.1辯論結果
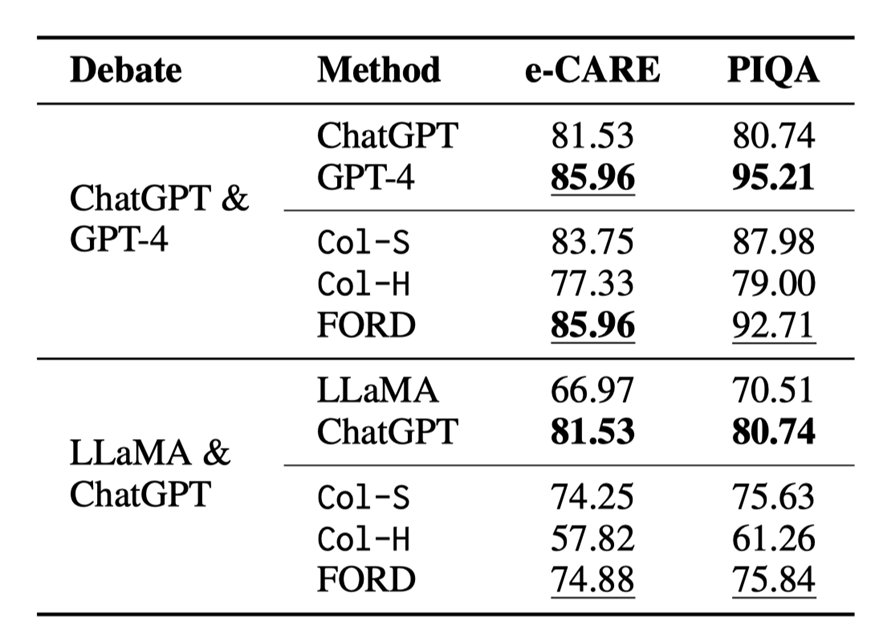
表 3:錯位辯論的結果
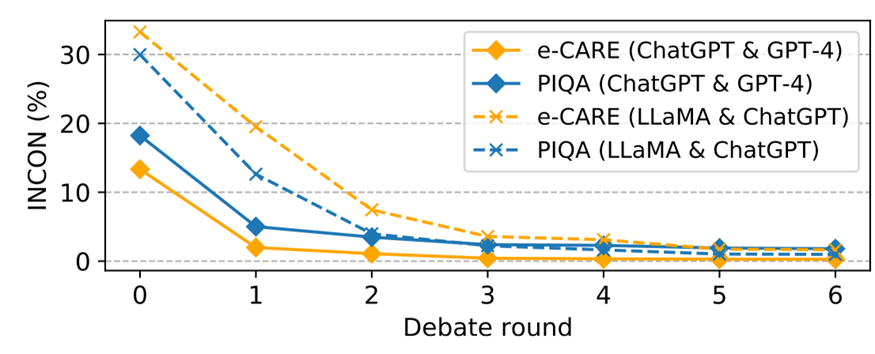
圖 5:錯位辯論中不一致性的變化
由于資源所限,我們只在 e-CARE 和 PIQA 上進行錯位辯論,錯位辯論的結果如表 3 和圖 5 所示,我們可以得出以下結論:
?FORD 可以輕松超越Col-S 和Col-H,以及較弱的那一個 LLM,但比不上較強的那一個 LLMs。似乎錯位辯論存在一個性能上限,這個上限與較強的 LLMs 的性能有關。這表明能力不匹配的LLMs很難有效地合作實現共同目標。
?即使能力不匹配,LLMs 之間的INCON 仍然繼續下降。這些表明能力不匹配的 LLMs 仍然具有達成共識的協作精神,但會受到能力較差的 LLMs 的干擾。
?與平等辯論相比,占主導地位的 LLMs(GPT-4 和ChatGPT)可能會被較弱的 LLMs 分散注意力,但將 ChatGPT & Davinci-003 和 LLaMA & Vicuna 中的 Davinci-003 以及 Vicuna 分別換成GPT-4 和 ChatGPT,FORD還是會獲得顯著的提升。
?LLaMA & ChatGPT 的 FORD 似乎表現還遠遠沒有達到可能存在的上限,這是因為 LLaMA 沒有能力對其它模型的論據進行評估,只會不斷表明自己的立場,這更加分散了 ChatGPT 的注意力。
4.2.2辯論的主導程度 dominance
為了進一步分析,我們為 LLMs 辯論引入了一個新的指標:辯論的主導程度dominance。例如,正方LLM 的dominance 被定義為反方 LLM 妥協的樣本的比例,反之亦然。dominance 直接反映了 LLMs 在辯論中堅持自己觀點的程度。
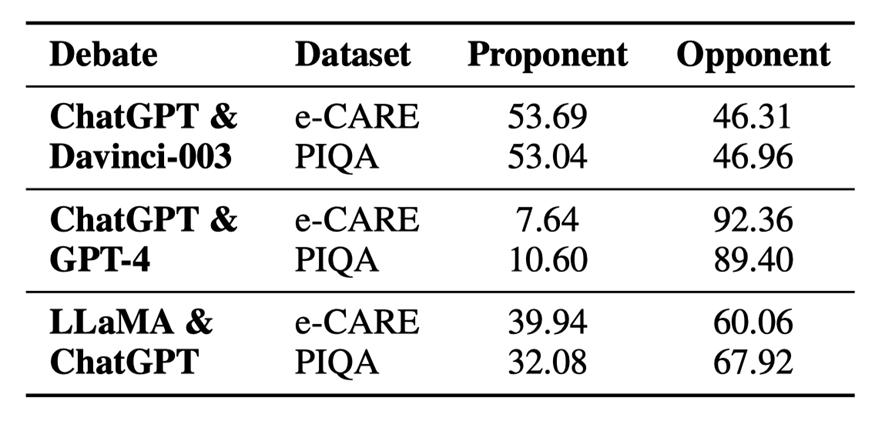
表 4:不同辯論中不同模型的主導程度
以公平辯論 (ChatGPT & Davinci-003) 為例,表 4 顯示 ChatGPT& Davinci003 在兩個數據集上取得了相似的主導程度。它解釋了為什么可比的 LLMs 可以進行辯論來妥協或堅持更合理的觀點來提高性能。因此,我們將其作為錯位辯論的參考,如表4所示,我們可以得出結論:
?實力較強的 LLMs(GPT-4和ChatGPT)在不匹配的辯論中占據絕對優勢。這與人類的場景類似,在與比自己更強的人辯論時,自己很容易被帶入到對方的思考過程中并認可對方的想法。因此,實力較強的LLMs更有可能堅持自己的觀點。當更強的 LLMs 對少數樣本缺乏信心時,它們更容易受到較弱的 LLMs 的干擾。
?然而,LLaMA & ChatGPT 并沒有表現出如此大的主導程度差距。這主要是因為 LLaMA 幾乎沒有辯論的能力。它無法評估其它模型的論點,大多數時候只會生成 “選項(x)更合理” 之類的句子,這會讓 ChatGPT 搖擺不定。
4.2.3圓桌辯論
在許多場景中,辯論或者是討論并不局限于 2 個參與者,例如醫療診斷和法庭陪審團,都需要多個參與者,所以我們設計了有 3 個 LLMs 參與的圓桌辯論:一個錯位的圓桌辯論 ChatGPT & Davinci-003 & GPT-4 (記為 R1),一個平等的圓桌辯論 ChatGPT & Davinci-003 & ChatGPT-0301 (記為 R2)。我們選取 e-CARE 和 PIQA 作為圓桌辯論的數據集。
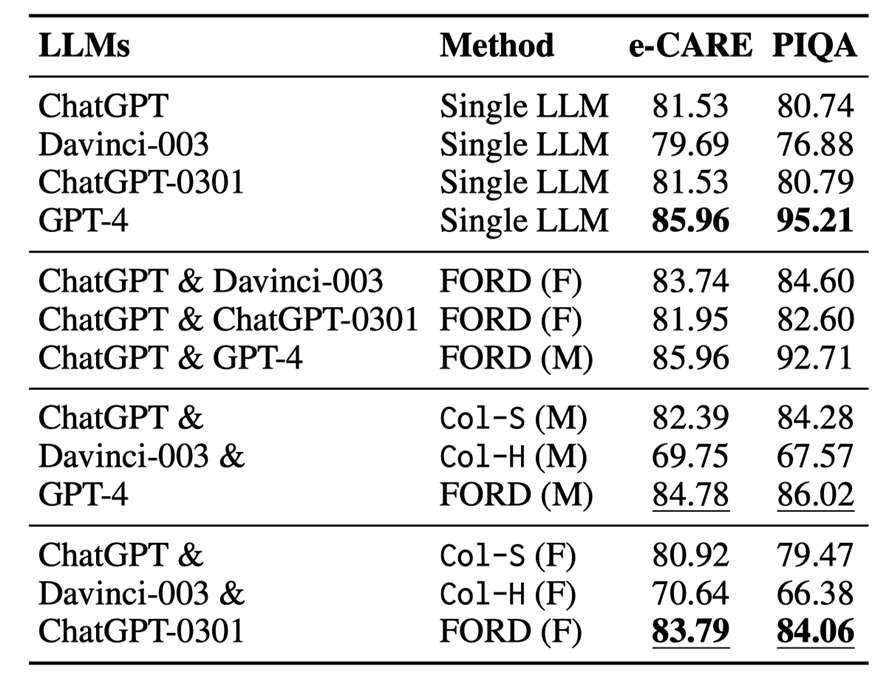
表 5:圓桌辯論與單模型以及雙模型辯論結果,M 代表錯位辯論,F 代表平等辯論
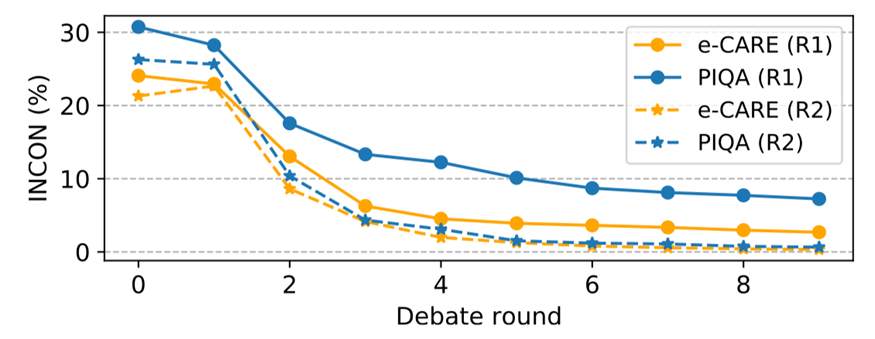
圖 6:圓桌辯論的不一致性變化
圓桌辯論的結果如表 5 和圖 6 所示,我們可以進行分析得到以下結論:
?在兩種圓桌辯論中,FORD 的表現均明顯優于Col-S 和Col-H。然而R1 中的 FORD 遠不如GPT-4,如果有更多較弱的 LLMs,那么較強的LLMs 可能會更容易被誤導,并且不那么占主導地位(請參閱文章附錄中的表 10)。FORD 在 R2 上的表現優于所有單一LLMs,這證明兩個以上可比的LLMs可以有效且高效地協作以實現共同目標。
?圓桌辯論中的INCON 明顯下降,表明兩個以上LLMs仍然具備協作精神并達成共識。
?圓桌辯論R1 性能表現超越了 R2。這表明更換一個較強的 LLMs 可以提高辯論的表現,盡管較強的 LLMs 可能會被其他較弱的 LLMs 誤導。
在 R2 中,FORD 超過了平等辯論 ChatGPT &ChatGPT0301,而與 ChatGPT &Davinci-003 取得了相似的結果,這是因為ChatGPT和ChatGPT-0301沒有太多區別,導致辯論中引入的新信息很少。
5. 分析
5.1使用 GPT-4 作為辯論的裁判
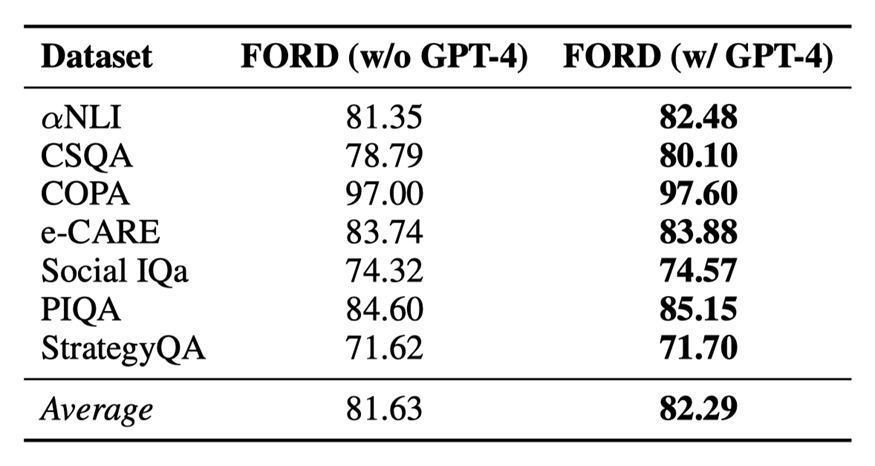
表6:GPT-4作為裁判對辯論結果的影響
每次辯論中不同的論點可能有不同的說服力。而且,在人類辯論中,有一個具有強大評估能力的人類裁判來總結辯論并得出最終結論。受此啟發,我們研究使用 GPT-4 作為裁判來執行 FORD 中的第 3 步,并在兩個公平辯論中進行實驗。實驗結果如表 6 所示:
?GPT-4作為裁判可以進一步提升辯論的性能。主要是因為GPT4可以給更有說服力的論點賦予更高的權重,從而得出更精確的結論。
?同時,啟發式的方法作為裁判也可以以一個較低的成本達到一個較理想的結果。
5.2辯論順序的影響

表7:不同辯論順序對辯論的影響,*代表更換順序的辯論結果
就像模型訓練過程中不同的初始化可能會產生不同的結果一樣,辯論框架的步驟 2 中的辯論順序可能會影響結果,我們進行消融研究來研究辯論順序的影響。實驗結果如表 7 所示:
當我們將 Davinci-003 作為正方,ChatGPT 作為反方時,FORD 仍然優于Col-S和Col-H,以及相應的單一 LLM,獲得與原始辯論順序相似的結果。這進一步支持了上文的發現對辯論順序不敏感。
5.3樣例分析

圖7:樣例分析
在 Debate 1 中,正方 (ChatGPT) 認為選項 (A) 更合理,而反方 (Davinci-003) 則認為選項 (B) 更好。正方指出,這個問題的關鍵在于“舊年鑒”。反方最終向正方妥協。通過這場辯論,一個 LLMs 可以提供另一個 LLMs 忽視的細節,從而產生更有說服力的可解釋信息和更準確的決策。
6. 結論
我們探討了不同 LLMs 之間的不一致問題。然后我們使用辯論框架 FORD 來考察 LLMs 是否能夠有效地協作,通過辯論最終達成共識。為此我們探索了三個現實世界的辯論場景公平辯論、不匹配辯論和圓桌辯論。我們發現 LLMs 擁有協作精神,能夠就共同目標達成共識。辯論可以提高 LLMs 的表現和相互一致性。當辯論不匹配時,較強的 LLMs 可能會被較弱的 LLMs 分散注意力。這些發現有助于未來開發更有效的多 LLMs 協作方法。
-
語言模型
+關注
關注
0文章
527瀏覽量
10290 -
智能體
+關注
關注
1文章
152瀏覽量
10593 -
ChatGPT
+關注
關注
29文章
1563瀏覽量
7791
原文標題:EMNLP2023 | 基于大語言模型辯論的多智能體協作推理分析
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大型語言模型的邏輯推理能力探究
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】大語言模型的應用
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
基于多Agent系統的智能家庭網絡研究
壓縮模型會加速推理嗎?
AscendCL快速入門——模型推理篇(上)
利用大語言模型做多模態任務






 工商網監
工商網監
評論