 為什么Agent落地這么難?AI最大賽道Agent機遇全解析
為什么Agent落地這么難?AI最大賽道Agent機遇全解析
01狂飆的Agent—Agent 2023大事記
“如果一篇論文提出了某種不同的訓練方法,OpenAI內部會嗤之以鼻,認為都是我們玩剩下的。但是當新的AI Agent論文出來時,我們會十分認真且興奮地討論。普通人、創業者和極客在構建AI Agents方面相比OpenAI這樣的公司更有優勢。” -- OpenAI聯創Andrej Karpathy
如果說現在還有什么AI領域的“點子”能讓OpenAI為之興奮,那非Agent莫屬。從一個學界研究的概念到走入大眾視野,Agent只用了短短不到一年時間。如果大模型是未來水電煤一般的基礎設施,那么Agent則是未來用戶接觸、使用AI的方式。我們梳理了今年Agent狂飆突進的重要milestone,從中也可以窺見它的核心發展脈絡。
2023.3.16,微軟發布Microsoft 365 Copilot,引發業界巨大反響,提示了一種基于LLM的應用開發范式,也即今天形成行業共識的Agent。
2023.4,以AutoGPT為代表的Autonomous Agent 熱度快速躥升,AutoGPT成為GitHub歷史上star數增長最快的項目。同期比較受關注的類似項目包括:TaskMatrix.ai,HuggingGPT, AgentGPT, Toolformer, BabyAGI等等。
2023.6,OpenAI 應用研究主管 Lilian Weng 發布博文《LLM Powered Autonomous Agents》進一步推動了agent的熱度,Lilian提出Agent = 大型語言模型+記憶+規劃技能+工具使用。
多Agent框架相繼發布,相對于單一Agent框架能夠更好地解決復雜問題。目前比較火的多Agent框架包括:Camel(4月發布,3.4k star), MetaGPT(8月發布,29.7k star), AutoGen(9月發布,微軟團隊,13.6k star)
2023.11.6,OpenAI DevDay,推出其官方Agent開發框架Assistant API,賦能開發者更加高效方便地基于GPT模型進行的Agent開發。
02 Agent Landscape概覽
Agent吸引了大量創業者投身其中,據我們不完全統計,今年下半年在海外拿到知名創投機構投資的Agent項目已超過20家。在此我們做個基本梳理,方便大家了解目前市場上的整體情況: 從創投行業角度,當下LLM based Agent領域初創公司可大致分為兩類:
中間層infra
提供實用可復用的Agent框架,降低開發Agent 的復雜度,并為Agent的合作提供機制設計。該類項目主要從模塊化、適配性、協作等幾方面進行創新。其中拿到知名機構投資的代表項目包括:AutoGPT、Imbue、Voiceflow、Fixie AI、Reworked、Cognosys、Induced ai等。
Vertical Agent
深入某個垂直領域,理解該領域專家的工作流,運用Agent 思路設計Copilot產品,用戶介入使 Agent思路更為可控。其中拿到知名機構投資的代表項目包括:Dropzone(安全領域)、Middleware(大模型可觀察性領域)、Parcha(Fintech領域)、Luda(游戲領域)、Outbound AI(醫療領域)、Fine(軟件開發領域)。
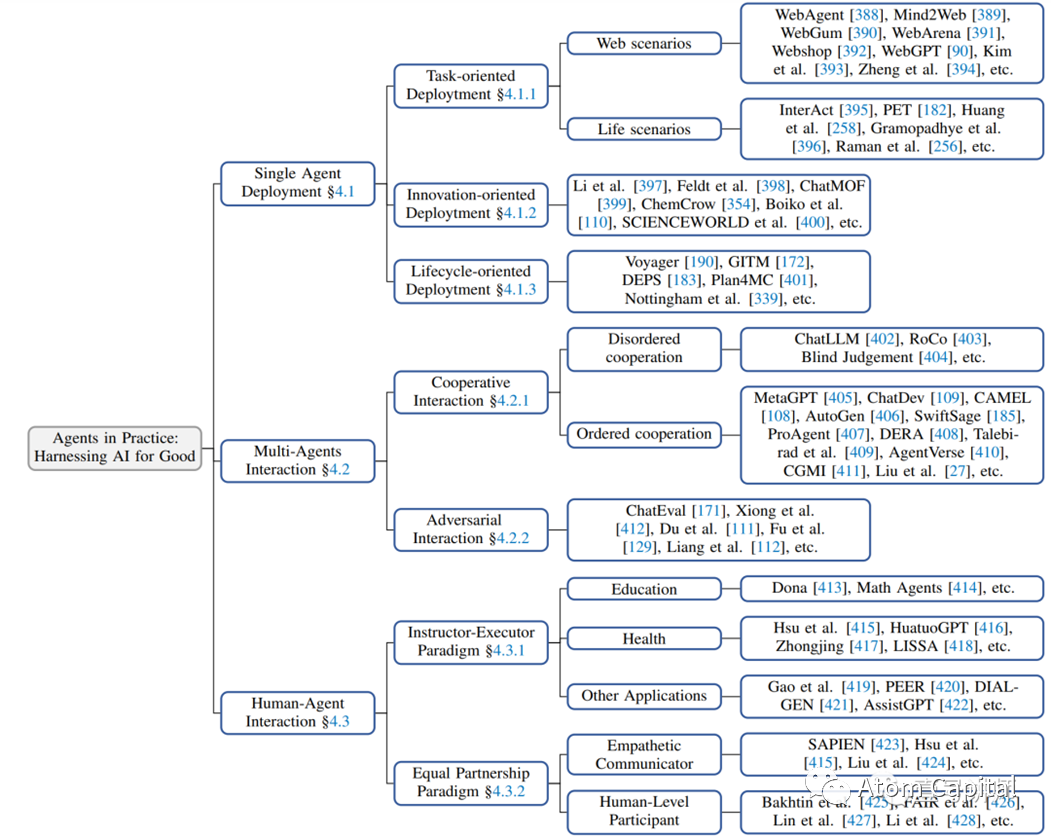
從Agent的互動/工作模式角度,復旦大學自然語言處理團隊(FudanNLP)在其 LLM-based Agents 綜述論文中,將Agent分成了三類:單一Agent, 多Agent以及人與Agent交互(按交互方式又分為指導-執行模式和平等合作模式)。如下圖所示:
03Agent落地:場景和挑戰
本次沙龍參與者既有學界資深的AI研究員,也有富有實戰經驗的一線Agent創業者。對于圍繞Agent大家關心的若干問題,我們進行了深入討論,以下是本次討論的一些精彩觀點:
Agent適合在哪些場景落地?
創業者們已經嘗試了各種落地場景,總結下來,以下幾點更契合Agent的落地。
做到比人(普通員工)好
客戶不一定要求Agent達到專家水平,很多場合只要比普通員工好就夠了。Agent PK的,實際上是月薪幾千元的員工。比如,公司IT部門要響應業務人員的各種需求(如臨時報表)。如果提供對話式UI,通過幾輪對話讓業務人員說明白需求,Agent來自動生成,做到這個,客戶已經愿意買單了。這樣IT團隊可以從瑣碎中解脫出來,做更重要的事。
Text to SQL
Text to SQL 在企業落地上有很多案例,以上例子本質上就是Text to SQL, 只不過多了很多新的數據來源:比如從商業化中最值錢的文檔(合同、財報、簡歷、招投標書等)中提取數據。把這些數據連同專家知識一起灌給大模型,把信息抽出來,通過Text to SQL來回答問題,這件事已經很值錢了,可復制性也很強。
寫代碼
幫程序員寫代碼這個場景毋庸多言。一個有趣的發現,是大模型些代碼大部分時間做的是寫正則表達式。正則表達式是個沒多少人會寫、但是很好用的東西。程序員調試,之前在這里經常花很多時間,用了大模型之后發現很快就能解決。這帶給我們一個啟發:有很多人類不擅長但AI很擅長的細分領域,是最適合Agent去落地探索的。
解決頭部問題是落地關鍵
我們看到在Agent領域有很多漂亮的Demo, 但能否將企業轉化成為真正的長期付費者,一個核心是當這個工具真的進入企業后,員工是不是可以真正把它用起來解決問題。Agent肯定會有不好用的地方,關鍵是要先能把大部分員工的頭部問題解決掉。做到這個,再出現一些小眾長尾問題,能讓大部分用戶覺得,這是人的問題而不是AI的問題,就好辦了(這種情況下,人會調整自己使用Agent的方式,比如更改詢問方式等等,通過人向AI靠攏的方式解決的一部分長尾問題)。
為什么Agent落地這么難?
目前最讓開發者頭疼的一個問題,是雖然很多Agent demo看起來能解各種問題,等真正應用在實踐中,特別是2B業務流程中,好像總是不工作。這也是為什么Agent被很多用戶戲稱為“玩具”——Agent想要真正落地非常難,但只有解決了這個問題才能開啟商業化的道路。這可能是Agent領域最關鍵的問題之一,圍繞Agent為何落地困難我們進行了深入探討,總結了實踐中碰到的挑戰以及背后更深層的原因。
從實踐層面,影響目前Agent落地的問題主要有如下兩方面:
API質量差,沒有形成生態
Agent在2B領域落地,有些類似ChatGPT Plugin搬到2B領域。但ChatGPT Plugin發布之后,實際落地的情況與預期有很大差距,我們分析背后原因在于兩個:一是背后的API不夠豐富、質量差(比如描述不清晰),二是試圖用一個模型解決所有的垂直問題(大模型對于垂直場景的理解未必足夠)。第一個問題在國內尤其嚴重。企業服務API生態在歐美非常成熟和開放,中國還很不完善,開發者很難賺到錢。這些讓Agent很難真正在生產環境落地。
開放場景 vs 封閉場景
Agent的落地效果與場景的封閉程度也很相關。一個典型的對比是Agent在法律助手 vs 出行預訂場景。前者場景不夠封閉,經常有新知識(如新的法律法規、新的判例)出現,API也不夠完善。要做成真正的律師“助手”還有比較大的挑戰,比較現實的是做成一個幫助律師整理文檔、搜索案例的提效工具。而后者場景封閉(可以窮舉)、API豐富(機票、酒店等都有明確的API),在落地中的效果要好很多。最理想的落地情況,是有大量垂直領域數據(給到大模型做預訓練)、場景封閉、問題基本可窮舉。
而從更深層的角度剖析,我們認為Agent之所以落地困難。背后的核心是大模型目前還缺乏解決相關應用領域的“世界模型”。
04Agent成功的關鍵 ——“世界模型”
上文所謂應用領域的世界模型,是指Agent落地到具體應用場景,要理解當下任務并預測未來情景,這需要超越簡單的文本學習,深入獲取領域知識、領域相關的私有數據以及相關任務的“過程數據”(即領域專家是如何分解任務、產生結果的)。大模型在訓練過程中,尤其缺乏“過程數據”,這讓世界模型的建立變得困難。
為什么大模型訓練為何會缺乏“過程數據”?
1)訓練語料問題。大模型學習主要的語料來源是網絡文字。但目前語料中,絕大多數都是關于“What”的,關于“How"的很少。尤其在2B業務領域,絕大多數的成功經驗和失敗教訓都不大可能被公開分享出來。前者多為創造價值的商業機密,而后者則很少會被主動分享,即使公開,也有很多美化及偏離事實的可能性,這可能會帶來大模型的錯誤歸因。
2)即使在“私有數據”中,關于過程的數據也依然很少。大量的所謂“經驗”是存在在相應崗位專家的大腦里的,并未以任何文字的形式被記錄下來。
舉個例子。在招聘領域,通常企業的用人標準會有“工作穩定”一項,但針對不同的崗位、不同的行業這個“工作穩定”所對應的標準是完全不一樣的。這些”知識”是人類HR/獵頭腦海中的經驗,針對崗位、公司的不同,自然就能把“工作穩定”對應到不同的標準,有時候甚至只是一個行業的“共識”,并沒有什么成文規定。但是讓大模型來做這件事,就需要詳細地把各個行業、崗位、工種、對應的“工作穩定”的標準寫下來告訴它(大模型在訓練語料中幾乎很難獲得這種很少出現在文字/語料中的專業“知識”),否則大模型缺失了這部分的“知識”,做“工作穩定”這一標準的篩選準確率自然就低,而千千萬萬個這樣的“知識點”就構成了一個招聘領域的“世界模型”。
3)缺乏大模型執行任務過程的“標注數據”,無法形成反饋-優化閉環。目前大模型基于網絡語料的學習,是每采取一個行動,都對應明確的Ground Truth. 大模型基于用戶對問題的反饋來不斷迭代升級。但Agent的問題在于,絕大多數agent執行到任務的最后一步,才是對用戶需求目標的達成,因而只有在最后那一步才有標注結果。對于其解決問題的中間過程,很多時候Agent得不到及時的反饋——做的是否正確、是否有更優的做法等等,這也讓Agent“自我進化"變得緩慢。
看好掌握領域“世界模型”的Vertical Agent
我們判斷,各領域“世界模型”的建立是AI走向落地的重要一環,也是AI向AGI發展的關鍵環節。現階段“世界模型”的缺乏,是大模型的“缺陷”也給大量做Vertical Agent的公司帶來了很大的機遇:構建垂直領域的“世界模型”需要相關公司做大量的工作收集、整理領域知識和私有數據、理解具體業務的工作流等等,是一個相當復雜的系統工程。尤其在法律、醫療、金融等數據龐雜、專業性極高的領域。一旦有Vertical Agent的公司能夠建立、掌握這些垂直行業的”世界模型“,也就擁有了在這個不確定時代極強的競爭壁壘。我們非常看好這類創業公司在未來的前景。
05Multi-Agent:為何它的效果明顯更好?
最近半年Agent領域一個明顯的趨勢是“Multi-Agent”框架的流行。很多開發者發現,當事先給Agent設定不同的角色(如產品經理、程序員、UI/UE等等),再讓這些Agents一起“協作”完成一個任務時,要比AutoGPT這種單一Agent框架效果好很多,任務完成度更高。相比單一Agent,Multi-Agent除了給大模型設定了角色,好像也沒有提供更多的增量信息。為什么這個框架會明顯的有效呢?
我們認為有如下幾點原因: 角色扮演有引導性,更容易讓它聚焦到相關的概率區間
大模型本質是概率模型,每次輸出都不一樣。它在訓練過程接受了豐富的語料,面對一個問題時,大模型有很多不同的角度和觀點,但它自己并不知道應該找哪一個切入。這時如果用戶給它一個角色,讓它聚焦到一個身份、一種觀點上去,它更容易進入到一個與問題相關性更高的概率空間,把其中的專業內容挖掘出來。給大模型一個身份看似沒有增量信息,其實一個“角色”背后已經隱含了很多與角色相關的信息。
讓大模型做更多的“算力消耗”,System1 vs System2
OpenAI聯創Andrej曾經分享過,他認為Prompt Engineering中思維鏈(Chain of Thought)之所以有用,就是類似“Let's think step by step“這樣的Prompt,讓大模型在輸出的時候消耗了更多的算力。這點跟人腦類似,人腦在解一個復雜問題時會消耗更多能量。而Multi-Agent正是這樣一套能讓大模型輸出更多、從而消耗更多算力的機制。大模型其實跟人腦的System1類似,特點是不論用戶給它的問題難度如何,它的思考時間(對應背后的計算量)是一樣的。而目前在Prompt層所做的思維鏈、Multi-Agent等等工作,都為了讓大模型從System1向System2發展,越復雜的問題思考得越久。通過Multi-Agent框架,可以讓它消耗更多的算力、做更多思維層次的計算和思考,更有可能更好地解決復雜任務。
這又引申出了許多創業者遇到的一個問題:并非所有問題都需要System2的能力,如何區分面對的問題需要System 1還是System2解決呢?如果都用System1的方式解決,那么復雜問題得不到很好的解決;如果都用System2的方式解決,那么又會“殺雞用牛刀”,既浪費算力、又拉長了反饋時間。最好的方式是能針對問題做好分流。這意味著Agent需要對海量的新問題做實時判斷,該用哪種方式解決,而這是絕大多數Agent很難做到的。目前有些創業者在探索先用大模型對問題做一遍意圖識別(分類器),再分流到不同的解決方式中去做具體執行。但在很多垂直領域(如法律等),把這個“分類器”做準確的難度依然很大。
結合多個大模型的最強能力
前面兩個角度,是如何通過Multi-Agent激發大模型發揮能力,背后對應的是一個能力強大的單一大模型。還存在另一種視角,就是Multi-Agent用來結合多個大模型的特色能力。雖然目前OpenAI在大模型領域“一騎絕塵”,我們也觀察到其他頭部大模型更注重在一些獨特能力上的訓練(比如更強調與人類的共情能力、更加注重alignment等)。在未來,當這些各有所長的大模型都進入生產,Multi-Agent框架會很方便地融合各家大模型的優勢“為我所用”。
06多模態:對比大語言模型有哪些提升?
大語言模型正在向多模態大模型發展,對比大語言模型,它帶來的能力提升有哪些,有什么深刻的變化?對創業者又多了哪些機遇?
從一個簡單問題類比說起
我們先從討論一個簡單的問題開始:聾子和瞎子,一個沒有聽覺,一個沒有視覺,哪個智力水平高?實際上瞎子的智力水平更高。這背后的原因是語言比視覺對人腦來說更加重要。視覺給我們的反饋,不如語言的反饋那么復雜。這是個抽象程度的問題,語言比視覺抽象程度更高,人和動物的區別是人有語言。所以,目前視覺等多模態模型,對于模型能力并沒有一個質的提升。
具體解釋一下,目前的多模態模型,是通過某種connection把視覺和文字兩個模態的數據對齊 --先訓練單模態,再通過對齊,去做成多模態。它還沒有真正從預訓練的時候,就把文字、視覺綁在一起從頭訓練,因為現階段跨模態對齊的數據還是太少了。大家認為可行的思路還是先訓練單模態然后再做對齊。除了語言模型,目前其他模態的encoder能力和量級相比都差很遠(比語言模型小1-2個數量級)。所以現在這條路效率最高,一下能通過語言模態賦予其他模態更高級的能力。這種多個模態對齊的多模態大模型,在能力上不會有突破式的飛躍,因為核心能力已經在語言模型里面了。
多模態帶來的好處
視覺比語言有更多的信息。目前大模型都是基于Transformer架構,這個架構本身跟語言關系不大,它只是在處理token之間的關系,最后再把這些token折換成語言。從這個意義上來說,不同模態的”語料“之間并沒有質的區別。因此,考慮多模態的影響,要考慮視覺中究竟包含了多少語言里沒有的信息。比如,視頻中有很多關于現實世界的“common sense"(如空間位置、重力、光影等等),在語言中是缺失的,這部分信息的補足對于建立對真實的”世界模型"是很有幫助的。這對于后續大模型在自動駕駛、機器人等需要與真實世界互動的場景中落地有很大意義。比如,聾子和瞎子能干什么不同的事情?瞎子是不能開車的。如果GPT有了視力,是可以開車的,無人駕駛可以靠GPT來理解周圍的環境。
多模態極大增強了交互的輸入輸出帶寬。許多用文字很難描述、或者需要非常長、復雜的文檔才能描述的關系、內容,可以通過畫圖的形式給到大模型,輸出也是如此。這讓人機交互的輸入輸出帶寬一下大了很多倍,帶來的直接效果是大模型處理同樣任務的效果更好、效率更高,也一定程度上解決了token限制的問題。Context輸入一下子擴大了很多。比如,可以給大模型幾萬行代碼對應的架構圖,它可以很快整理出模塊之間的關系,這是沒有多模態之前無法達到的。
07對Agent未來的幾個預判
最后分享幾個我們對Agent未來發展的預判,與大家探討:
AI Native工作流
Agent在2B領域落地,目前是按照人類工作的流程切分的,沒有考慮到機器,也沒有“人機協作”的概念。只是沿用過去的流程把機器加入很可能已經不是最優方式——既無法發揮機器的最大效率,人類員工也不適應。因而做2B場景的Agent,需要重新思考人機協同的工作模式下,什么樣的工作流程是最優的,再自上而下地重塑工作流。AI native的工作流應當是什么樣?這是個開放性問題,并沒有明確的答案,但這個問題可能會定義下一代的企業級軟件,是值得現階段的初創公司去深入思考和探索的重點問題。
真正的多模態
未來可以有一開始就把多種模態的語料一起訓練的多模態大模型。或者,等視覺模態encoder的能力和量級可以跟現在的大語言模型等量齊觀,用它來輔助做決策,或者兩個大模型共同做決策,可能會爆發很大的潛力,帶來突破式發展。
Agent的自我進化
隨著AI能力的逐步增強,未來Agent將如何演化?也許,它們可以實現“自我進化”。比如,自己生產出新的Agent,或者設計出適合Agent協作的全新的組織結構來完成復雜的任務,就如同人類發展出了適應人類社會的復雜協作模式和分工體系。這是一個很值得思考的前沿方向,背后是Agent之間的通訊及協作模式。目前這個方向的研究還非常的少,我們覺得是很值得探索的一個領域。
審核編輯:劉清
-
SQL
+關注
關注
1文章
773瀏覽量
44239 -
GPT
+關注
關注
0文章
359瀏覽量
15500 -
OpenAI
+關注
關注
9文章
1123瀏覽量
6676 -
ChatGPT
+關注
關注
29文章
1566瀏覽量
8022 -
LLM
+關注
關注
0文章
298瀏覽量
389
原文標題:Atom Capital:AI最大賽道Agent機遇全解析
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
研華AI Agent引領工業物聯網應用革新
工廠數字化轉型難成功?AI Agent或成破局關鍵
黑芝麻智能與RockAI聯手發布AI Agent解決方案
【書籍評測活動NO.55】AI Agent應用與項目實戰
黑芝麻智能與RockAI發布AI Agent解決方案
富匙科技推出AI Agent,加速東南亞市場拓展
2024 AI+硬件創新大賽獲獎名單出爐
微軟Dynamics365集成10大自主AI Agent,引領智能自動化新時代
定義AI Agent四大核心能力,榮耀IFA劇透端側AI創新進展

NVIDIA 攜手全球合作伙伴推出 NIM Agent Blueprints,助力企業打造屬于自己的 AI
基于Qwen-Agent與OpenVINO構建本地AI智能體

艾為電子榮獲釘釘AI助理創造大賽企業賽道二等獎






 工商網監
工商網監
評論