

1. 查詢模型的本質
查詢模型的本質就是:為不同的應用場景選擇最合適的存儲引擎,充分發揮各個存儲引擎的優勢。
在系統中,讀接口的數量遠超寫接口,但我深信:==再簡單的寫也是復雜,再復雜的讀也是簡單。==
為什么呢?因為,想做好查詢只需為不同的應用場景選擇最合適的存儲引擎,從而充分發揮底層存儲引擎的優勢,然后所面對的高性能、高并發等技術問題就迎刃而解了。
如下圖所示:
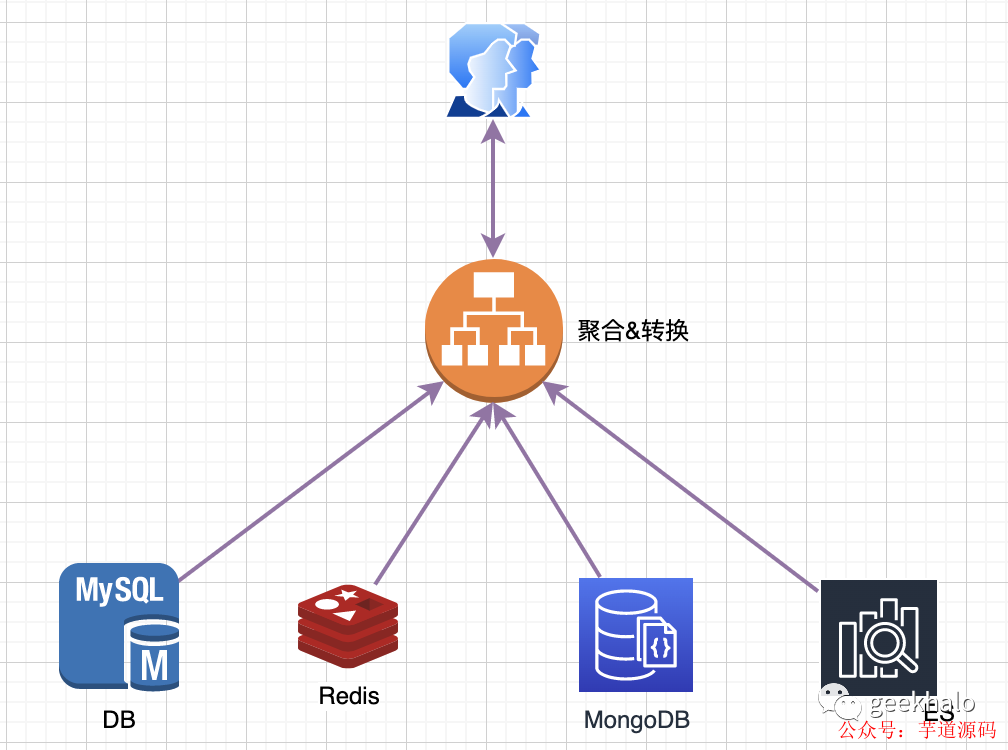
面對一個查詢請求,我們需要:
接受并解析用戶請求;
從各個存儲引擎中獲取數據;
對數據進行加工,包括數據聚合、數據關聯、數據轉換等;
將最終結果返回用戶;
1.1. 常見存儲引擎的特征
技術選型唯一原則:==僅僅使用它的成名之作,萬萬不可被花里胡哨的東西干擾你的判斷。==
簡單列舉下常見的存儲引擎:
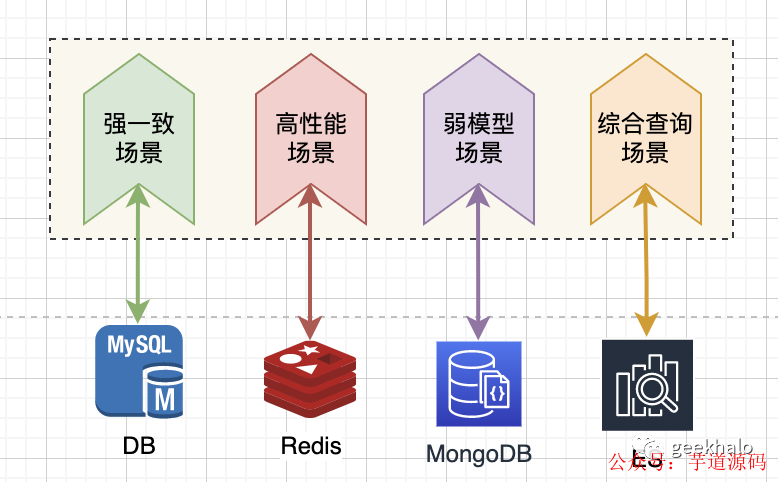
1.關系數據庫。
【特點】提供事務機制對數據強一致性進行保障,其ACID四大特性更是建模利器;
【場景】適用于一致性要求高的金融或類金融場景,比如銀行、支付、訂單等;
2.Redis。
【特點】基于內存的鍵值存儲引擎,具有高性能和低延遲;支持豐富的數據結構(字符串、哈希、列表、集合、有序集合等)和功能(發布訂閱、事務等),提供豐富的持久化選項;
【場景】:緩存、會話存儲、計數器、排行榜、分布式鎖等對性能和實時性要求較高的場景;
3.Elasticsearch。
【特點】全文搜索和分析引擎,建立在Lucene庫之上。擅長水平擴展、近實時搜索、全文搜索和復雜查詢等功能;支持分布式架構、自動分片和數據冗余;
【場景】日志分析、實時監控、商業智能、搜索引擎、推薦系統等需要高效的實時全文搜索和分析功能的場景;
4.MongoDB。
【特點】面向文檔的NoSQL數據庫,以JSON風格的文檔格式存儲數據;支持動態模式、靈活的索引和復制集、分片等特性,可擴展性好,支持水平擴展;
【場景】大數據量、高寫入頻率、動態模式和靈活查詢的場景,如內容管理系統、用戶個性化數據存儲、實時分析等;
1.2. 讀接口三把利器
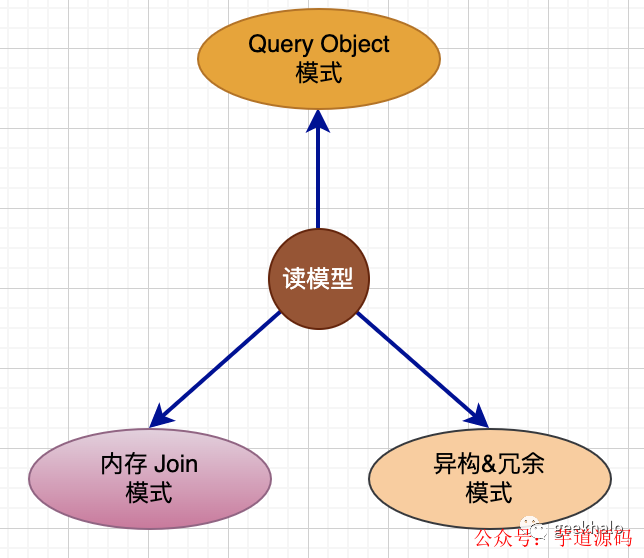
對于查詢請求,主要有三種模式:
1.Query Object 模式。基于 Query Object 建模,完成對單引擎的快速查詢;
通過對 Query Object 對象建模,便可以對查詢條件進行靈活管理;
無需寫 SQL,只需在 Query Object 上聲明好各種過濾條件,便能完成查詢。包括單條查詢、批量查詢、數量查詢、分頁查詢等
2.內存 Join 模式。基于 View Object 建模,完成對結果數據的聚合操作;
通過對 View Object 對象建模,便可以對返回結果進行靈活控制;
無需手寫關聯代碼,只需在 View Object 上聲明關聯關系,自動完成關聯數據的聚合;
3.異構&冗余模式。
CQRS 思想的體現,徹底的將寫模型和讀模型拆分開,從而最大限度的發揮存儲引擎優勢;
異構意味著冗余,冗余意味著數據不一致,該模式通過準實時巡檢、天級對賬來保障數據的最終一致性;
三大模式綜合使用如下:
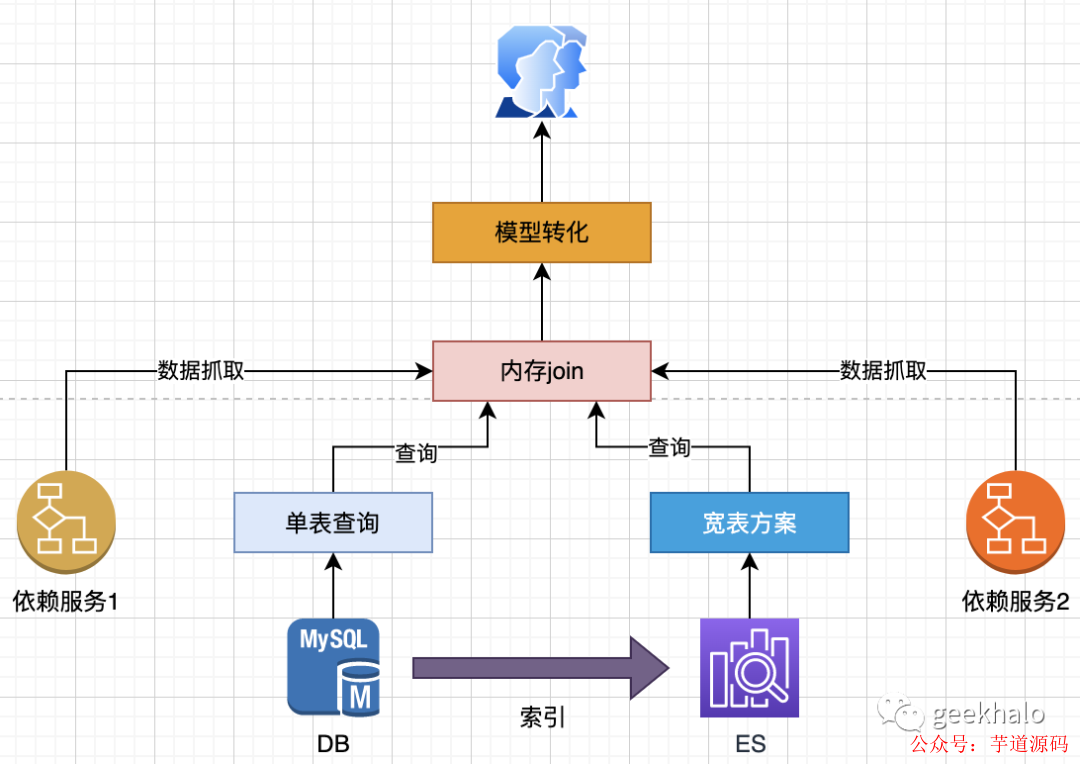
內存 Join 模式,從遠程服務、存儲引擎中獲取數據,完成數據的聚合操作,然后對聚合數據進行轉換,返回給用戶;
Query Object 模式,大大簡化對單引擎的查詢,讓你從繁重的 SQL(底層API) 中解放出來,大大提升開發效率;
異構&冗余模式,方便構建多副本異構數據模型,完成最繁瑣的數據同步和數據一致性保障;
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://github.com/YunaiV/ruoyi-vue-pro
視頻教程:https://doc.iocoder.cn/video/
2. Query Object 模式
這是最常見,也是應用最多的模型,主要用于解決單引擎的數據查詢。讓開發聚焦于查詢建模,而不再是繁雜易錯的技術細節。
我們以簡單的 MySQL 查詢為例,假如使用 MyBatis 作為系統的 ORM 框架,其核心流程如下:
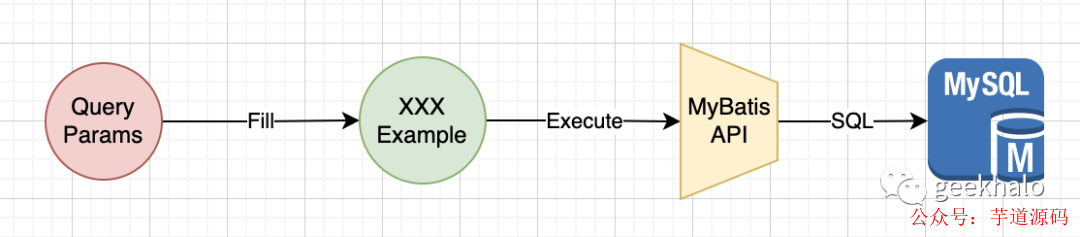
首先,我們會定義一組查詢對象;
當我們接收到參數后,把有效參數填充到 Example 對象;
然后,將 Example 對象傳入 MyBatis API 進行查詢;
MyBatis 根據 Mapper 配置,將 Example 對象轉換為對應的 SQL 和參數,并提交給 MySQL;
最終,MySQL 執行 SQL 獲取并返回查詢結果;
仔細思考下,這里面是不是存在很多“固定邏輯”,而我們每天寫的代碼是不是有很強的“重復性”?
接下來看下面這張圖:
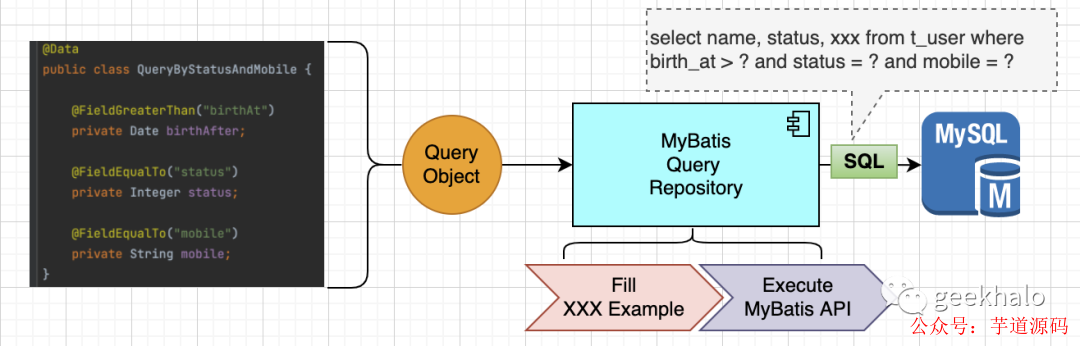
內核和核心流程沒有變化,但上層 API 出現巨大變化:
1.首先,引入了 Query Object:
將分散的查詢參數封裝到一個類中;
在查詢對象的屬性上多了一組注解,用于聲明該屬性與數據庫查詢條件的關系;
2.然后,多了一個核心組件 MyBatisQueryRepository:
從 Query Object 上讀取屬性和注解信息,并完成對 Example 對象的填充;
使用填充好的 Example 對象調用 MyBatis API,從而完成數據查詢;
在該模式下,開發 MyBatis 的單表查詢,只有一件事要做:按照業務要求對 Query Object 進行建模。
當然為了方便使用,QueryRepository 提供多種接口:
get:查詢單個對象;
listOf:查詢多個對象;
countOf:查詢數量;
pageOf:分頁查詢;
如對該部分感興趣,可研讀稍后文章。
該玩法支持復雜查詢嗎?
首先,不支持。對于復雜查詢,只能回歸到 MyBatis 底層 API。
【注】不要奢求一個框架或一個方案解決所有問題。使用 20% 的精力來解決 80% 的問題,那開發效率已經得到極大提升。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
項目地址:https://github.com/YunaiV/yudao-cloud
視頻教程:https://doc.iocoder.cn/video/
3. 內存 Join 模式
內存 Join 等同于關系數據庫的 Join 語句,只是將 Join 動作從數據層提升到了應用層。
其實我們每天都在寫這樣的重復代碼!!!
假如有一個需求,實現我的訂單接口,返回值里面需要包括 用戶信息(User)、收獲地址信息(Address)、商品信息(Product)等。而這些信息沒有在一個數據庫,甚至分散在不同的服務,需要調用遠程接口才能獲取到。由于無法使用數據庫的 join 語句,所以就出現了如下接口:
查詢我的訂單并將其轉換為 OrderDetail 集合:

獲取 User 信息,并填充到 OrderDetail 對象:
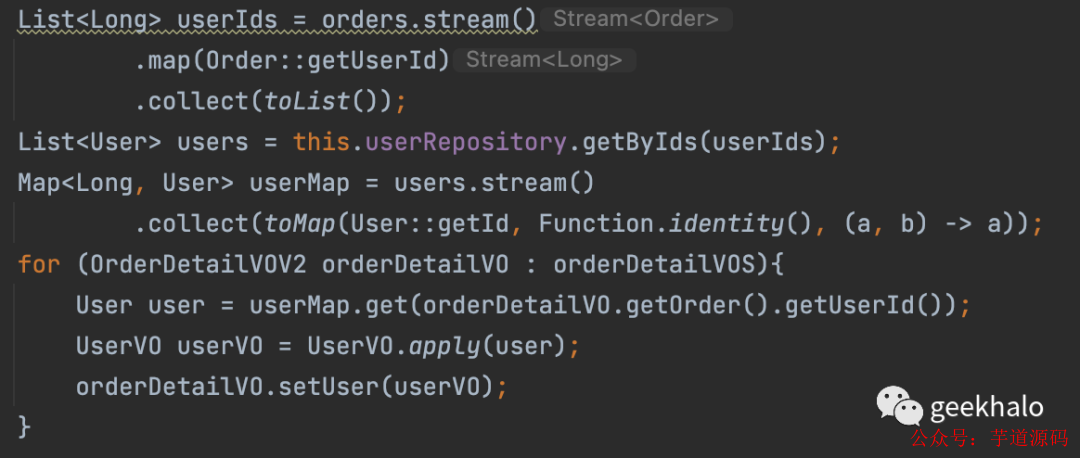
獲取 Address 信息,并填充到 OrderDetail 對象:
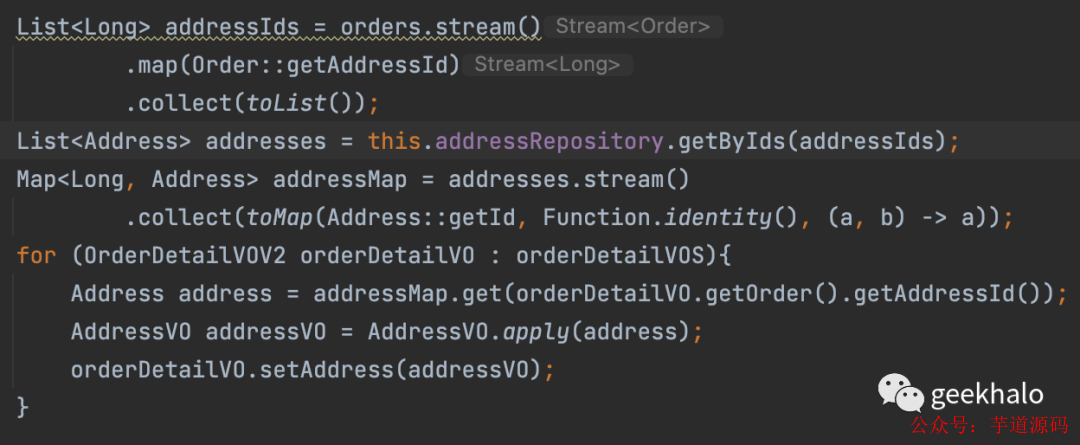
獲取 Product 信息,并填充到 OrderDetail 對象:
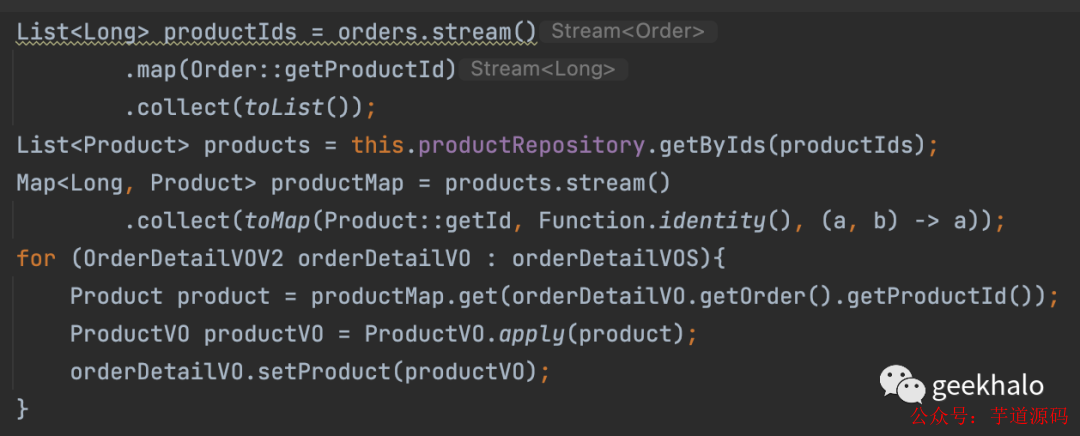
最后,返回填充好的 OrderDetail 集合;
仔細觀察上面的代碼,你是找到了“重復邏輯”?
如果,又要開發一個購物車列表呢?購物車列表和我的訂單是否存在重復邏輯?
思考完之后,請看 內存 Join 模式:
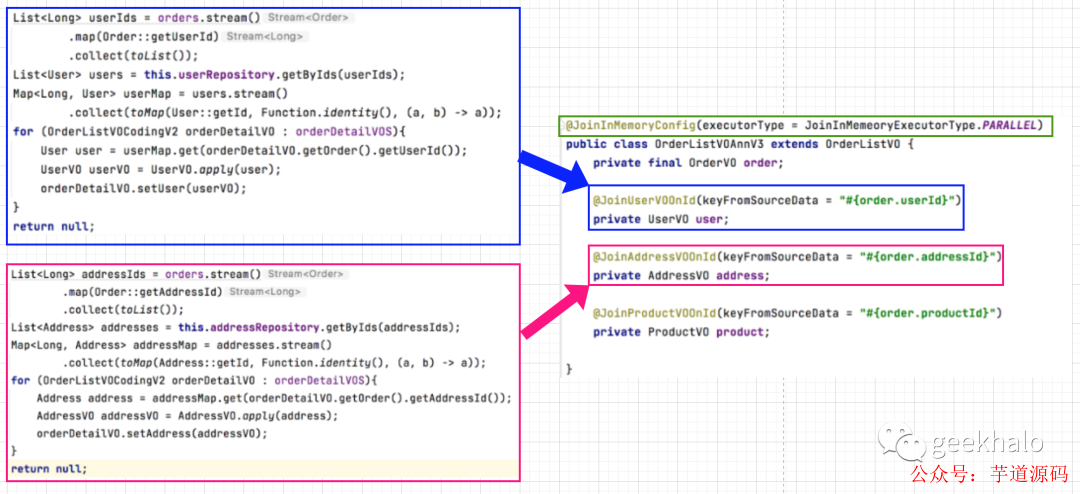
可以看到:
大量繁雜冗余代碼被簡單的 @Join注解 取代
還可以開啟并發模型,使用多線程技術加快接口響應速度
整體流程如下:
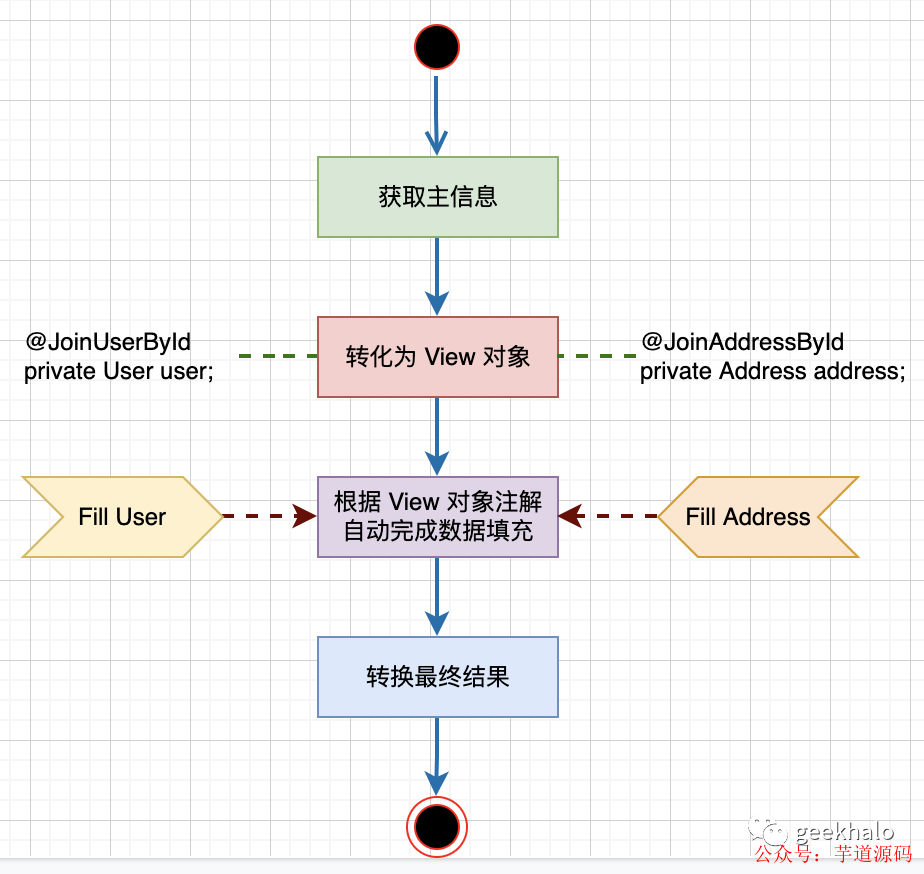
我們通過對 View Object 建模便能對返回數據進行控制,從而大大簡化對返回結果的開發成本。
如對該部分感興趣,可研讀稍后文章。
4. 異構&冗余模式
異構冗余模式,主要用于多存儲引擎的場景,旨在保障多存儲引擎間數據的一致性。
比如,在一個復雜的系統中,核心數據存儲于 MySQL,使用 Redis 進行緩存加速,使用 ES 完成全文檢索。如何設計系統,才能保障 MySQL 中的數據與 Redis、ES 的數據始終保持同步,從而實現最終一致性。
看似很簡單,但真正實現起來卻到處是坑,在深入思索后得出兩個特征:
存在決策節點并具備強順序性。按照決策節點給出的變更順序,依次在異構引擎上進行回放,便能實現兩者的最終一致性;
存在權威的“源信息”,發現不一致時可以使用源頭信息對數據進行自動修復;
從而,推導出該場景下的最佳實踐:
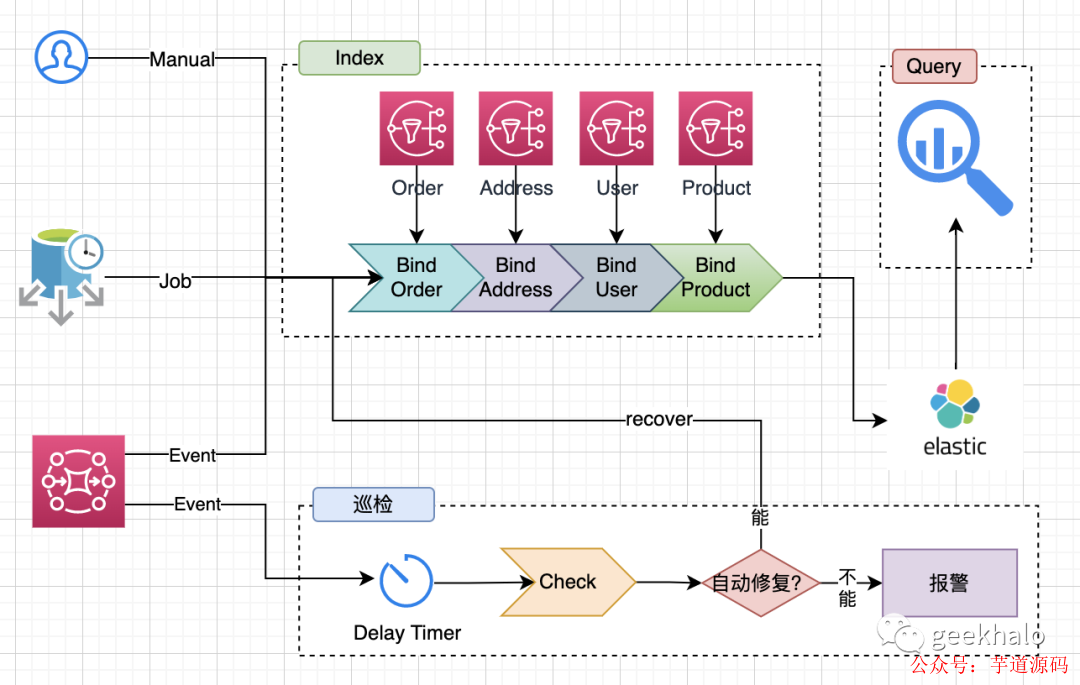
整體架構分為如下幾部分:
索引:主要完成數據的構建,從多個系統中拉取數據完成數據的裝配,并按所需結構對數據進行轉化;
巡檢:對系統中的數據進行實時巡檢或定時對賬,發現系統中不一致的數據并完成數據的自動修復。如遇數據無法修復的場景,自動進行報警,人工介入進行處理;
查詢:充分發揮存儲引擎的優勢,提供業務查詢能力,常與 Query Object 模式 和 內存 Join 模式 結合使用;
通過對最佳實踐的封裝,可以在同一套組件、同一個數據模型基礎上,完成對 索引&更新、巡檢&修復 兩大流程的融合,大大降低研發工作量。
如對該部分感興趣,可研讀稍后文章。
5. 小結
查詢模型的本質就是:為不同的應用場景選擇最合適的存儲引擎,然后充分發揮各個存儲引擎的優勢。
基于此提出三個模式:
Query Object 模式。通過 Query Object 建模,實現對查詢條件的靈活管理。無需寫 SQL,只需在 Query Object 上聲明好各種過濾條件,便能完成常規查詢。包括單條查詢、批量查詢、數量查詢、分頁查詢等;
內存 Join 模式。基于 View Object 建模,實現對返回結果的靈活控制。無需手寫關聯代碼,只需在 View Object 上聲明關聯關系,自動完成關聯數據的聚合;
異構&冗余模式。CQRS 思想的體現,徹底的將寫模型和讀模型拆分開,通過準實時巡檢、天級對賬來保障數據的最終一致性,從而最大限度的發揮存儲引擎優勢;
-
接口
+關注
關注
33文章
8833瀏覽量
152726 -
多線程
+關注
關注
0文章
279瀏覽量
20171 -
模型
+關注
關注
1文章
3442瀏覽量
49658
原文標題:DDD死黨:查詢模型的本質
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
電機的本質運行原理是什么
XML數據流基于組著色的XPath查詢模型
一種新的查詢意圖識別模型
"Scalable, Distributed Systems Using Akka, Spring Boot, DDD, and Java--轉"

可從GraphQL查詢生成Java模型的Apollo HarmonyOS
用好DDD必須先過Spring Data這關
一文理解DDD領域驅動設計
DDD驅動如何設計?如何進行領域建模?
DDD學習與感悟——向屎山沖鋒





 工商網監
工商網監

評論