") nginx內(nèi)存池源碼設(shè)計
nginx內(nèi)存池源碼設(shè)計
造輪子內(nèi)存池原因引入
作為C/C++程序員, 相較JAVA程序員的一個重大特征是我們可以直接訪問內(nèi)存, 自己管理內(nèi)存, 這個可以說是我們的特色, 也是我們的苦楚了.
java可以有虛擬機(jī)幫助管理內(nèi)存, 但是我們只能自己管理內(nèi)存, 一不小心產(chǎn)生了內(nèi)存泄漏問題, 又特別是服務(wù)器的內(nèi)存泄漏問題, 進(jìn)程不死去, 泄漏的內(nèi)存就一直無法回收.
所以對于內(nèi)存的管理一直是我們C系列程序員深挖的事情.
所以對于C++有智能指針這個東西. 還有內(nèi)存池組件. 內(nèi)存池組件也不能完全避免內(nèi)存泄漏, 但是它可以很好的幫助我們定位內(nèi)存泄漏的點, 以及可以減少內(nèi)存申請和釋放的次數(shù), 提高效率
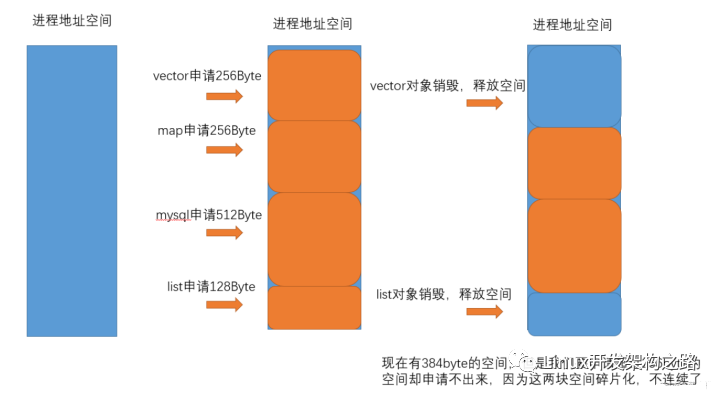
大量的malloc/free小內(nèi)存所帶來的弊端
弊端
- malloc/free的底層是調(diào)用系統(tǒng)調(diào)用, 這兩者庫函數(shù)是對于系統(tǒng)調(diào)用的封裝, 頻繁的系統(tǒng)調(diào)用所帶來的用戶內(nèi)核態(tài)切換花費大量時間, 大大降低系統(tǒng)執(zhí)行效率
- 頻繁的申請小內(nèi)存, 帶來的大量內(nèi)存碎片, 內(nèi)存使用率低下且導(dǎo)致無法申請大塊的內(nèi)存
- 沒有內(nèi)存回收機(jī)制, 很容易造成內(nèi)存泄漏
內(nèi)存碎片出現(xiàn)原因解釋
- 內(nèi)部內(nèi)存碎片定義: 已經(jīng)被分配出去了(明確分配到一個進(jìn)程), 但是無法被利用的空間
- 內(nèi)存分配的起始地址 一定要是 4, 8, 16整除地址
- 內(nèi)存是按照頁進(jìn)行分配的, 中間會產(chǎn)生外部內(nèi)存碎片, 無法分配給進(jìn)程
- 內(nèi)部內(nèi)存碎片:頻繁的申請小塊內(nèi)存導(dǎo)致了內(nèi)存不連續(xù)性,中間的小內(nèi)存間隙又不足以滿足我們的內(nèi)存申請要求, 無法申請出去利用起來, 這個就是內(nèi)部內(nèi)存碎片.
出現(xiàn)場景
最為典型的場景就是高并發(fā)是的頻繁內(nèi)存申請, 釋放. (http請求) (tcp連接)
大牛解決措施(nginx內(nèi)存池)
nginx內(nèi)存池, 公認(rèn)的設(shè)計方式非常巧妙的一款內(nèi)存池設(shè)計組件, 專門針對高并發(fā)下面的大量的內(nèi)存申請釋放而產(chǎn)生的.
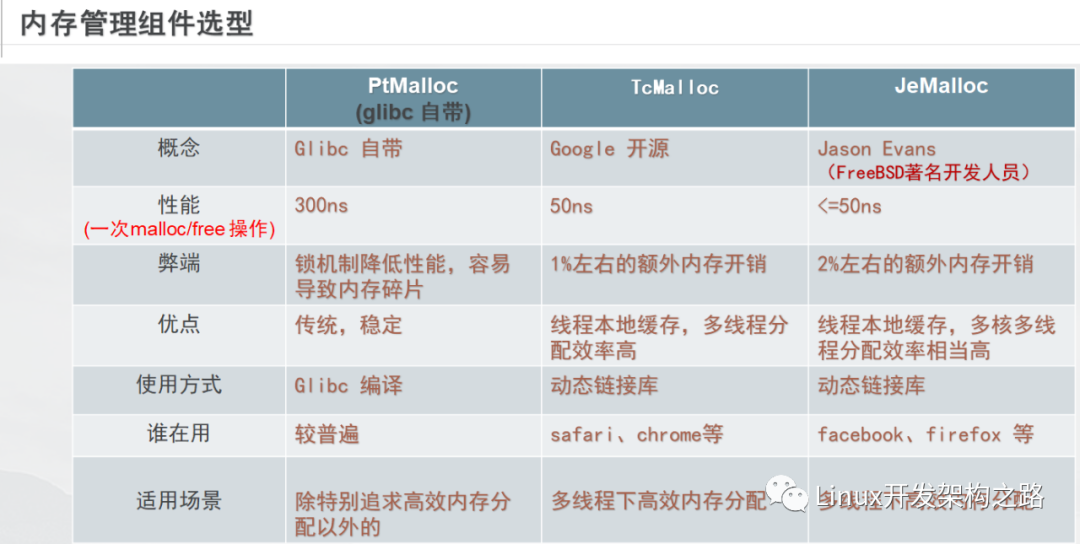
在系統(tǒng)層,我們可以使用高性能內(nèi)存管理組件 Tcmalloc Jemalloc(優(yōu)化效率和碎片問題)
在應(yīng)用層: 我們可以根據(jù)需求設(shè)計內(nèi)存池進(jìn)行管理 (高并發(fā)可以借助nginx內(nèi)存池設(shè)計)
內(nèi)存池技術(shù)
啥叫作內(nèi)存池技術(shù)
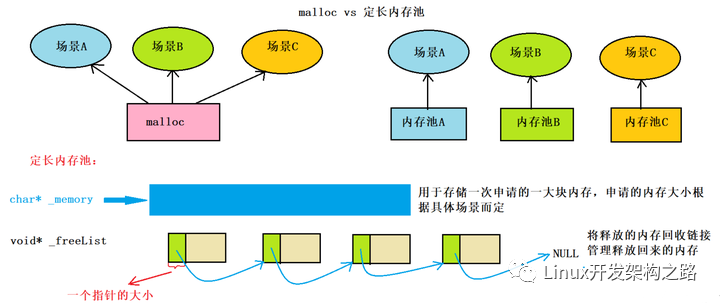
就是說在真正使用內(nèi)存之前, 先提前申請分配一定數(shù)量的、大小相等(一般情況下)的內(nèi)存塊留作備用, 當(dāng)需要分配內(nèi)存的時候, 直接從內(nèi)存塊中獲取. 如果內(nèi)存塊不夠了, 再申請新的內(nèi)存塊.
內(nèi)存池: 就是將這些提前申請的內(nèi)存塊組織管理起來的數(shù)據(jù)結(jié)構(gòu)
優(yōu)勢何在:統(tǒng)一對程序所使用的內(nèi)存進(jìn)行統(tǒng)一的分配和回收, 提前申請的塊, 然后將塊中的內(nèi)存合理的分配出去, 極大的減少了系統(tǒng)調(diào)用的次數(shù). 提高了內(nèi)存利用率. 統(tǒng)一的內(nèi)存分配回收使得內(nèi)存泄漏出現(xiàn)的概率大大降低
內(nèi)存池技術(shù)為啥可以解決上文弊端
高并發(fā)時系統(tǒng)調(diào)用頻繁(malloc free頻繁),降低了系統(tǒng)的執(zhí)行效率
- 內(nèi)存池提前預(yù)先分配大塊內(nèi)存,統(tǒng)一釋放,極大的減少了malloc 和 free 等函數(shù)的調(diào)用。
頻繁使用時增加了系統(tǒng)內(nèi)存的碎片,降低內(nèi)存使用效率
- 內(nèi)存池每次請求分配大小適度的內(nèi)存塊,最大避免了碎片的產(chǎn)生
沒有內(nèi)存回收機(jī)制,容易造成內(nèi)存泄漏
- 在生命周期結(jié)束后統(tǒng)一釋放內(nèi)存,極大的避免了內(nèi)存泄露的發(fā)生
高并發(fā)內(nèi)存池nginx內(nèi)存池源碼刨析
啥是高并發(fā)
系統(tǒng)能夠同時并行處理很多請求就是高并發(fā)
高并發(fā)具備的特征
- 響應(yīng)時間短
- 支持并發(fā)用戶數(shù)高
- 支持用戶接入量高
- 連接建立時間短
nginx_memory_pool為啥就適合高并發(fā)
內(nèi)存池生存時間應(yīng)該盡可能短,與請求或者連接具有相同的周期
減少碎片堆積和內(nèi)存泄漏
避免不同請求連接之間互相影響
一個連接或者一個請求就創(chuàng)建一個內(nèi)存池專門為其服務(wù), 內(nèi)存池的生命周期和連接的生命周期保持一致.
仿寫nginx內(nèi)存池
實現(xiàn)思路
- 對于每個請求或者連接都會建立相應(yīng)的內(nèi)存池,建立好內(nèi)存池之后,我們可以直接從內(nèi)存池中申請所需要的內(nèi)存,不用去管內(nèi)存的釋放,當(dāng)內(nèi)存池使用完成之后一次性銷毀內(nèi)存池。
- 區(qū)分大小內(nèi)存塊的申請和釋放,大于內(nèi)存池塊最大尺寸的定義為大內(nèi)存塊,使用單獨的大內(nèi)存塊鏈表保存,即時分配和釋放
- 小于等于池尺寸的定義為小內(nèi)存塊,直接從預(yù)先分配的內(nèi)存塊中提取,不夠就擴(kuò)充池中的內(nèi)存,在生命周期內(nèi)對小塊內(nèi)存不做釋放,直到最后統(tǒng)一銷毀。
內(nèi)存池大小, 以及內(nèi)存對齊的宏定義
#define MP_ALIGNMENT 32
#define MP_PAGE_SIZE 4096
#define MP_MAX_ALLOC_FROM_POOL (MP_PAGE_SIZE-1)
#define mp_align_ptr(p, alignment) (void *)((((size_t)p)+(alignment-1)) & ~(alignment-1))
//分配內(nèi)存起點對齊
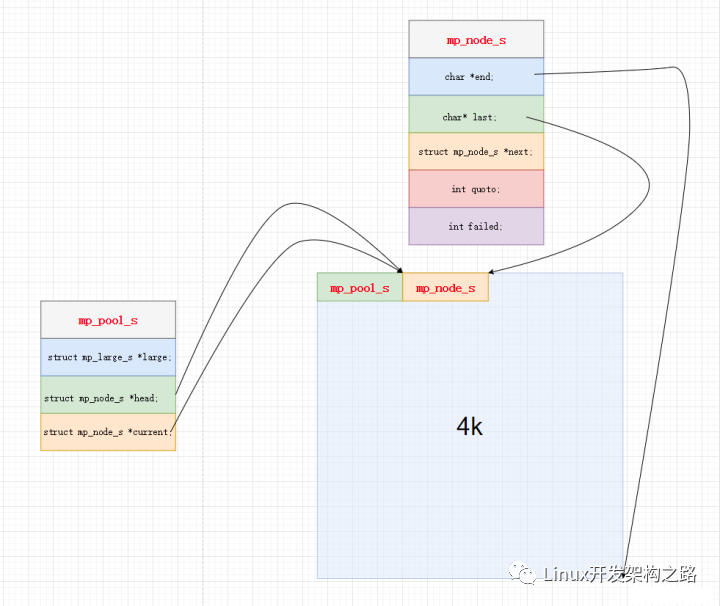
結(jié)構(gòu)定義以及圖解分析
typedef struct mp_large_s {
struct mp_large_s* next;
void* alloc;//data區(qū)
} mp_large_s;
typedef struct mp_node_s {
unsigned char* last;//下一次內(nèi)存分配的起點
unsigned char* end;//當(dāng)前內(nèi)存塊末尾
size_t failed;//當(dāng)前內(nèi)存塊分配失敗的次數(shù)
struct mp_node_s* next;
} mp_node_s;
typedef struct mp_pool_s {
mp_large_s* large;//指向大塊內(nèi)存起點
mp_node_s* current;//指向當(dāng)前可分配的小內(nèi)存塊起點
int max;//小塊最大內(nèi)存
mp_node_s head[0];//存儲地址, 不占據(jù)內(nèi)存,變長結(jié)構(gòu)體技巧
//存儲首塊小內(nèi)存塊head地址
} mp_pool_s;
mp_pool_s 內(nèi)存池結(jié)構(gòu)
- large 指向第一個大塊
- current 指向當(dāng)前可分配的小塊
- head 始終指向第一塊小塊
mp_node_s 小塊內(nèi)存結(jié)構(gòu)
- last 下一次內(nèi)存分配的起點, 本次內(nèi)存分配的終點
- end 塊內(nèi)存末尾
- failed 當(dāng)前內(nèi)存塊申請內(nèi)存的失敗次數(shù), nginx采取的方式是失敗次數(shù)達(dá)到一定程度就更換current,current是開始嘗試分配的內(nèi)存塊, 也就是說失敗達(dá)到一定次數(shù), 就不再申請這個內(nèi)存塊了.
mp_large_s 大塊內(nèi)存塊
- 正常的申請, 然后使用鏈表連接管理起來.
- alloc 內(nèi)存塊, 分配內(nèi)存塊
函數(shù)原型以及功能敘述
//函數(shù)申明
mp_pool_s *mp_create_pool(size_t size);//創(chuàng)建內(nèi)存池
void mp_destory_pool( mp_pool_s *pool);//銷毀內(nèi)存池
void *mp_alloc(mp_pool_s *pool, size_t size);
//從內(nèi)存池中申請并且進(jìn)行字節(jié)對齊
void *mp_nalloc(mp_pool_s *pool, size_t size);
//從內(nèi)存池中申請不進(jìn)行字節(jié)對齊
void *mp_calloc(mp_pool_s *pool, size_t size);
//模擬calloc
void mp_free(mp_pool_s *pool, void *p);
void mp_reset_pool(struct mp_pool_s *pool);
//重置內(nèi)存池
static void *mp_alloc_block(struct mp_pool_s *pool, size_t size);
//申請小塊內(nèi)存
static void *mp_alloc_large(struct mp_pool_s *pool, size_t size);
//申請大塊內(nèi)存
對應(yīng)nginx函數(shù)原型
重點函數(shù)分塊細(xì)節(jié)刨析
mp_create_pool: 創(chuàng)建線程池
第一塊內(nèi)存: 大小設(shè)置為 size + sizeof(node) + sizeof(pool) ?
mp_node_s head[0] 啥意思?
mp_pool_s* mp_create_pool(size_t size) {
struct mp_pool_s *p = NULL;
int ret = posix_memalign((void **)&p, MP_ALIGNMENT, size + sizeof(mp_pool_s) + sizeof(mp_node_s));
if (ret) {
return NULL;
}
//內(nèi)存池小塊的大小限制
p- >max = (size < MP_MAX_ALLOC_FROM_POOL) ? size : MP_MAX_ALLOC_FROM_POOL;
p- >current = p- >head;//第一塊為當(dāng)前塊
p- >large = NULL;
p- >head- >last = (unsigned char *)p + sizeof( mp_pool_s) + sizeof(mp_node_s);
p- >head- >end = p- >head- >last + size;
p- >head- >failed = 0;
return p;
}
看完了代碼來回答一下問題
- 為了盡可能地避免內(nèi)存碎片地產(chǎn)生, 小內(nèi)存地申請, 于是我采取地方式是將 memory pool內(nèi)存池也放入到首塊內(nèi)存中地方式. 同時所有地node結(jié)點信息也都統(tǒng)一存儲在每一個內(nèi)存塊中.
- head[0] : 是一種常用于變長結(jié)構(gòu)體地技巧, 不占用內(nèi)存, 僅僅只是表示一個地址信息, 存儲head node 的地址.
mp_alloc 帶字節(jié)對齊的內(nèi)存申請
首先按照size大小選擇內(nèi)存分配方式, 小于等于線程池小塊最大大小限制就從已有小塊中申請, 小塊不足就調(diào)用mp_alloc_block創(chuàng)建新的小塊 否則就調(diào)用 mp_alloc_large 申請創(chuàng)建一個大塊內(nèi)存
mp_align_ptr 用于字節(jié)對齊
void *mp_alloc(mp_pool_s *pool, size_t size) {
mp_node_s* p = NULL;
unsigned char* m = NULL;
if (size <= MP_MAX_ALLOC_FROM_POOL) {//從小塊中分配
p = pool- >current;
do {//循環(huán)嘗試從現(xiàn)有小塊中申請
m = mp_align_ptr(p- >last, MP_ALIGNMENT);
if ((size_t)(p- >end - m) >= size) {
p- >last = m + size;
return m;
}
p = p- >next;
} while (p);
//說明小塊中都分配失敗了, 于是從新申請一個小塊
return mp_alloc_block(pool, size);
}
//從大塊中分配
return mp_alloc_large(pool, size);
}
mp_alloc_block 申請創(chuàng)建新的小塊內(nèi)存
psize 大小等于mp_node_s結(jié)點內(nèi)存大小 + 實際可用內(nèi)存塊大小
搞清楚內(nèi)存塊組成:結(jié)點信息 + 實際可用內(nèi)存塊
返回的內(nèi)存是實際可用內(nèi)存的起始地址
//申請小塊內(nèi)存
void *mp_alloc_block(struct mp_pool_s *pool, size_t size) {
unsigned char* m = NULL;
size_t psize = 0;//內(nèi)存池每一塊的大小
psize = (size_t)((unsigned char*)pool- >head- >end - (unsigned char*)pool- >head);
int ret = posix_memalign((void**)&m, MP_ALIGNMENT, psize);
if (ret) return NULL;
//此時已經(jīng)分配出來一個新的塊了
mp_node_s* new_node, *p, *current;
new_node = (mp_node_s*)m;
new_node- >end = m + psize;
new_node- >failed = 0;
new_node- >next = NULL;
m += sizeof(mp_node_s);//跳過node
//對于m進(jìn)行地址起點內(nèi)存對齊
m = mp_align_ptr(m, MP_ALIGNMENT);
new_node- >last = m + size;
current = pool- >current;
//循環(huán)尋找新的可分配內(nèi)存塊起點current
for (p = current; p- >next; p = p- >next) {
if (p- >failed++ > 4) {
current = p- >next;
}
}
//將new_node連接到最后一塊內(nèi)存上, 并且嘗試跟新pool- >current
pool- >current = current ? current : new_node;
p- >next = new_node;
return m;
}
mp_alloc_large 申請創(chuàng)建新的大塊內(nèi)存
大塊內(nèi)存參考nginx_pool 采取采取的是malloc分配
先分配出來所需大塊內(nèi)存. 在pool的large鏈表中尋找是否存在空閑的alloc. 存在則將內(nèi)存掛在上面返回. 尋找5次還沒有找到就另外申請一個新的large結(jié)點掛載內(nèi)存, 鏈接到large list中管理
mp_large_s* node 是從內(nèi)存池中分配的, 也就是從小塊中分配的 why? 減少內(nèi)存碎片, 將大塊的node信息放入小塊內(nèi)存中,避免小內(nèi)存的申請, 減少內(nèi)存碎片
留疑? 空閑的alloc從何而來?
void *mp_alloc_large(struct mp_pool_s *pool, size_t size) {
void* p = malloc(size);
if (p == NULL) return NULL;
mp_large_s* l = NULL;
size_t cnt = 0;
for (l = pool- >large; l; l = l- >next) {
if (l- >alloc) {
l- >alloc = p;
return p;
}
if (cnt++ > 3) {
break;//為了提高效率, 檢查前5個塊, 沒有空閑alloc就從新申請large
}
}
l = mp_alloc(pool, sizeof(struct mp_large_s));
if (l == NULL) {
free(p);
return NULL;
}
l- >alloc = p;
l- >next = pool- >large;
pool- >large = l;
return p;
}
空閑的alloc是被free掉了空閑出來的. 雖然nginx采取的是小塊不單獨回收, 最后統(tǒng)一回收, 因為小塊的回收非常難以控制, 不清楚何時可以回收. 但是對于大塊nginx提供了free回收接口.
mp_free_large 回收大塊內(nèi)存資源
void mp_free_large(mp_pool_s *pool, void *p) {
mp_large_s* l = NULL;
for (l = pool- >large; l; l = l- >next) {
if (p == l- >alloc) {
free(l- >alloc);
l- >alloc = NULL;
return ;
}
}
}
整體代碼附下
#ifndef _MPOOL_H_
#define _MPOOL_H_
#include < stdlib.h >
#include < stdio.h >
#include < string.h >
#include < unistd.h >
#include < fcntl.h >
#define MP_ALIGNMENT 32
#define MP_PAGE_SIZE 4096
#define MP_MAX_ALLOC_FROM_POOL (MP_PAGE_SIZE-1)
#define mp_align_ptr(p, alignment) (void *)((((size_t)p)+(alignment-1)) & ~(alignment-1))
//內(nèi)存起點對齊
typedef struct mp_large_s {
struct mp_large_s* next;
void* alloc;//data區(qū)
} mp_large_s;
typedef struct mp_node_s {
unsigned char* last;//下一次內(nèi)存分配的起點
unsigned char* end;//當(dāng)前內(nèi)存塊末尾
size_t failed;//當(dāng)前內(nèi)存塊分配失敗的次數(shù)
struct mp_node_s* next;
} mp_node_s;
typedef struct mp_pool_s {
mp_large_s* large;//指向大塊內(nèi)存起點
mp_node_s* current;//指向當(dāng)前可分配的小內(nèi)存塊起點
int max;//小塊最大內(nèi)存
mp_node_s head[0];//存儲地址, 不占據(jù)內(nèi)存,變長結(jié)構(gòu)體技巧
//存儲首塊小內(nèi)存塊head地址
} mp_pool_s;
//函數(shù)申明
mp_pool_s *mp_create_pool(size_t size);//創(chuàng)建內(nèi)存池
void mp_destory_pool( mp_pool_s *pool);//銷毀內(nèi)存池
void *mp_alloc(mp_pool_s *pool, size_t size);
//從內(nèi)存池中申請并且進(jìn)行字節(jié)對齊
void *mp_nalloc(mp_pool_s *pool, size_t size);
//從內(nèi)存池中申請不進(jìn)行字節(jié)對齊
void *mp_calloc(mp_pool_s *pool, size_t size);
//模擬calloc
void mp_free(mp_pool_s *pool, void *p);
void mp_reset_pool(struct mp_pool_s *pool);
//重置內(nèi)存池
static void *mp_alloc_block(struct mp_pool_s *pool, size_t size);
//申請小塊內(nèi)存
static void *mp_alloc_large(struct mp_pool_s *pool, size_t size);
//申請大塊內(nèi)存
mp_pool_s* mp_create_pool(size_t size) {
struct mp_pool_s *p = NULL;
int ret = posix_memalign((void **)&p, MP_ALIGNMENT, size + sizeof(mp_pool_s) + sizeof(mp_node_s));
if (ret) {
return NULL;
}
//內(nèi)存池小塊的大小限制
p- >max = (size < MP_MAX_ALLOC_FROM_POOL) ? size : MP_MAX_ALLOC_FROM_POOL;
p- >current = p- >head;//第一塊為當(dāng)前塊
p- >large = NULL;
p- >head- >last = (unsigned char *)p + sizeof( mp_pool_s) + sizeof(mp_node_s);
p- >head- >end = p- >head- >last + size;
p- >head- >failed = 0;
return p;
}
void mp_destory_pool( mp_pool_s *pool) {
//先銷毀大塊
mp_large_s* l = NULL;
mp_node_s* p = pool- >head- >next, *q = NULL;
for (l = pool- >large; l; l = l- >next) {
if (l- >alloc) {
free(l- >alloc);
l- >alloc = NULL;
}
}
//然后銷毀小塊內(nèi)存
while (p) {
q = p- >next;
free(p);
p = q;
}
free(pool);
}
//申請小塊內(nèi)存
void *mp_alloc_block(struct mp_pool_s *pool, size_t size) {
unsigned char* m = NULL;
size_t psize = 0;//內(nèi)存池每一塊的大小
psize = (size_t)((unsigned char*)pool- >head- >end - (unsigned char*)pool- >head);
int ret = posix_memalign((void**)&m, MP_ALIGNMENT, psize);
if (ret) return NULL;
//此時已經(jīng)分配出來一個新的塊了
mp_node_s* new_node, *p, *current;
new_node = (mp_node_s*)m;
new_node- >end = m + psize;
new_node- >failed = 0;
new_node- >next = NULL;
m += sizeof(mp_node_s);//跳過node
//對于m進(jìn)行地址起點內(nèi)存對齊
m = mp_align_ptr(m, MP_ALIGNMENT);
new_node- >last = m + size;
current = pool- >current;
for (p = current; p- >next; p = p- >next) {
if (p- >failed++ > 4) {
current = p- >next;
}
}
//將new_node連接到最后一塊內(nèi)存上, 并且嘗試跟新pool- >current
pool- >current = current ? current : new_node;
p- >next = new_node;
return m;
}
//申請大塊內(nèi)存
void *mp_alloc_large(struct mp_pool_s *pool, size_t size) {
void* p = malloc(size);
if (p == NULL) return NULL;
mp_large_s* l = NULL;
size_t cnt = 0;
for (l = pool- >large; l; l = l- >next) {
if (l- >alloc) {
l- >alloc = p;
return p;
}
if (cnt++ > 3) {
break;//為了提高效率, 檢查前5個塊, 沒有空閑alloc就從新申請large
}
}
l = mp_alloc(pool, sizeof(struct mp_large_s));
if (l == NULL) {
free(p);
return NULL;
}
l- >alloc = p;
l- >next = pool- >large;
pool- >large = l;
return p;
}
//帶有字節(jié)對齊的申請
void *mp_alloc(mp_pool_s *pool, size_t size) {
mp_node_s* p = NULL;
unsigned char* m = NULL;
if (size < MP_MAX_ALLOC_FROM_POOL) {//從小塊中分配
p = pool- >current;
do {
m = mp_align_ptr(p- >last, MP_ALIGNMENT);
if ((size_t)(p- >end - m) >= size) {
p- >last = m + size;
return m;
}
p = p- >next;
} while (p);
//說明小塊中都分配失敗了, 于是從新申請一個小塊
return mp_alloc_block(pool, size);
}
//從大塊中分配
return mp_alloc_large(pool, size);
}
//不帶字節(jié)對齊的從內(nèi)存池中申請內(nèi)存
void *mp_nalloc(mp_pool_s *pool, size_t size) {
mp_node_s* p = NULL;
unsigned char* m = NULL;
if (size < MP_MAX_ALLOC_FROM_POOL) {//從小塊中分配
p = pool- >current;
do {
m = p- >last;
if ((size_t)(p- >end - m) >= size) {
p- >last = m + size;
return m;
}
p = p- >next;
} while (p);
//說明小塊中都分配失敗了, 于是從新申請一個小塊
return mp_alloc_block(pool, size);
}
//從大塊中分配
return mp_alloc_large(pool, size);
}
void *mp_calloc(struct mp_pool_s *pool, size_t size) {
void *p = mp_alloc(pool, size);
if (p) {
memset(p, 0, size);
}
return p;
}
void mp_free(mp_pool_s *pool, void *p) {
mp_large_s* l = NULL;
for (l = pool- >large; l; l = l- >next) {
if (p == l- >alloc) {
free(l- >alloc);
l- >alloc = NULL;
return ;
}
}
}
#endif
-
內(nèi)存
+關(guān)注
關(guān)注
8文章
3028瀏覽量
74076 -
JAVA
+關(guān)注
關(guān)注
19文章
2969瀏覽量
104780 -
程序
+關(guān)注
關(guān)注
117文章
3787瀏覽量
81069 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4332瀏覽量
62653 -
nginx
+關(guān)注
關(guān)注
0文章
150瀏覽量
12181
發(fā)布評論請先 登錄
相關(guān)推薦
C++內(nèi)存池的設(shè)計與實現(xiàn)
基于DWC_ether_qos的以太網(wǎng)驅(qū)動開發(fā)-LWIP的內(nèi)存池介紹
內(nèi)存池可以調(diào)節(jié)內(nèi)存的大小嗎
內(nèi)存池的概念和實現(xiàn)原理概述
關(guān)于RT-Thread內(nèi)存管理的內(nèi)存池簡析
RT-Thread內(nèi)存管理之內(nèi)存池實現(xiàn)分析
Linux 內(nèi)存池源碼淺析
LibTorch-based推理引擎優(yōu)化內(nèi)存使用和線程池
什么是內(nèi)存池

高并發(fā)內(nèi)存池項目實現(xiàn)
了解連接池、線程池、內(nèi)存池、異步請求池
如何實現(xiàn)一個高性能內(nèi)存池
內(nèi)存池的使用場景
Nginx目錄結(jié)構(gòu)有哪些
內(nèi)存池主要解決的問題





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論