 用自己的數據集訓練YOLOv8實例分割模型
用自己的數據集訓練YOLOv8實例分割模型
YOLOv8 于 2023 年 1 月 10 日推出。截至目前,這是計算機視覺領域分類、檢測和分割任務的最先進模型。該模型在準確性和執行時間方面都優于所有已知模型。
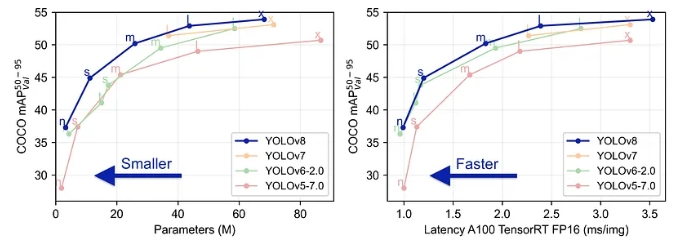
與之前的所有 YOLO 模型相比,ultralytics 團隊在使該模型更易于使用方面做得非常好 — 你甚至不必再克隆 git 存儲庫!
01創建圖像數據集
在這篇文章中,我創建了一個非常簡單的示例,展示了在數據上訓練 YOLOv8 所需執行的所有操作,特別是針對分割任務。數據集很小,并且模型“易于學習”,這樣我們就可以在簡單的 CPU 上訓練幾秒鐘后得到令人滿意的結果。
我們將創建一個黑色背景白色圓圈的數據集。圓圈的大小各不相同。我們將訓練一個模型來分割圖像內的圓圈。
數據集如下所示:
數據集是使用以下代碼生成的:
import numpy as np from PIL import Image from skimage import draw import random from pathlib import Path def create_image(path, img_size, min_radius): path.parent.mkdir( parents=True, exist_ok=True ) arr = np.zeros((img_size, img_size)).astype(np.uint8) center_x = random.randint(min_radius, (img_size-min_radius)) center_y = random.randint(min_radius, (img_size-min_radius)) max_radius = min(center_x, center_y, img_size - center_x, img_size - center_y) radius = random.randint(min_radius, max_radius) row_indxs, column_idxs = draw.ellipse(center_x, center_y, radius, radius, shape=arr.shape) arr[row_indxs, column_idxs] = 255 im = Image.fromarray(arr) im.save(path) def create_images(data_root_path, train_num, val_num, test_num, img_size=640, min_radius=10): data_root_path = Path(data_root_path) for i in range(train_num): create_image(data_root_path / 'train' / 'images' / f'img_{i}.png', img_size, min_radius) for i in range(val_num): create_image(data_root_path / 'val' / 'images' / f'img_{i}.png', img_size, min_radius) for i in range(test_num): create_image(data_root_path / 'test' / 'images' / f'img_{i}.png', img_size, min_radius) create_images('datasets', train_num=120, val_num=40, test_num=40, img_size=120, min_radius=10)
02創建標簽
現在有了圖像數據集,我們需要為圖像創建標簽。通常,需要為此做一些手動工作,但由于我們創建的數據集非常簡單,因此創建生成標簽的代碼非常容易:
from rasterio import features
def create_label(image_path, label_path):
arr = np.asarray(Image.open(image_path))
# There may be a better way to do it, but this is what I have found so far
cords = list(features.shapes(arr, mask=(arr >0)))[0][0]['coordinates'][0]
label_line = '0 ' + ' '.join([f'{int(cord[0])/arr.shape[0]} {int(cord[1])/arr.shape[1]}' for cord in cords])
label_path.parent.mkdir( parents=True, exist_ok=True )
with label_path.open('w') as f:
f.write(label_line)
for images_dir_path in [Path(f'datasets/{x}/images') for x in ['train', 'val', 'test']]:
for img_path in images_dir_path.iterdir():
label_path = img_path.parent.parent / 'labels' / f'{img_path.stem}.txt'
label_line = create_label(img_path, label_path)
以下是標簽文件內容的示例:
0 0.0767 0.08433 0.1417 0.08433 0.1417 0.0917 0.15843 0.0917 0.15843 0.1 0.1766 0.1 0.1766 0.10844 0.175 0.10844 0.175 0.1177 0.18432 0.1177 0.18432 0.14333 0.1918 0.14333 0.1918 0.20844 0.18432 0.20844 0.18432 0.225 0.175 0.225 0.175 0.24334 0.1766 0.24334 0.1766 0.2417 0.15843 0.2417 0.15843 0.25 0.1417 0.25 0.1417 0.25846 0.0767 0.25846 0.0767 0.25 0.05 0.25 0.05 0.2417 0.04174 0.2417 0.04174 0.24334 0.04333 0.24334 0.04333 0.225 0.025 0.225 0.025 0.20844 0.01766 0.20844 0.01766 0.14333 0.025 0.14333 0.025 0.1177 0.04333 0.1177 0.04333 0.10844 0.04174 0.10844 0.04174 0.1 0.05 0.1 0.05 0.0917 0.0767 0.0917 0.0767 0.08433
標簽對應于該圖像:
標簽內容只是一個文本行。每張圖像中只有一個對象(圓圈),每個對象在文件中由一行表示。如果每張圖像中有多個對象,則應為每個標記的對象創建一條線。
第一個 0 代表標簽的類別類型。因為我們只有一種類類型(圓形),所以總是 0。如果數據中有多個類,則應該將每個類映射到一個數字(0、1、2…),并在標簽文件中使用該數字。
所有其他數字表示標記對象的邊界多邊形的坐標。格式為
在處理圖像庫時獲取坐標的正確方向性總是令人困惑。所以為了明確這一點,對于YOLO來說,X坐標是從左到右,Y坐標是從上到下。
03YAML 配置
我們有了圖像和標簽。現在需要使用數據集配置創建一個 YAML 文件:
yaml_content = f'''
train: train/images
val: val/images
test: test/images
names: ['circle']
'''
with Path('data.yaml').open('w') as f:
f.write(yaml_content)
請注意,如果你有更多對象類類型,則需要按照在標簽文件中的順序將它們添加到名稱數組中。第一個是 0,第二個是 1,等等...
04數據集文件結構
讓我們看看使用 Linux 樹命令創建的文件結構:
tree .
data.yaml datasets/ ├── test │ ├── images │ │ ├── img_0.png │ │ ├── img_1.png │ │ ├── img_2.png │ │ ├── ... │ └── labels │ ├── img_0.txt │ ├── img_1.txt │ ├── img_2.txt │ ├── ... ├── train │ ├── images │ │ ├── img_0.png │ │ ├── img_1.png │ │ ├── img_2.png │ │ ├── ... │ └── labels │ ├── img_0.txt │ ├── img_1.txt │ ├── img_2.txt │ ├── ... |── val | ├── images │ │ ├── img_0.png │ │ ├── img_1.png │ │ ├── img_2.png │ │ ├── ... | └── labels │ ├── img_0.txt │ ├── img_1.txt │ ├── img_2.txt │ ├── ...
05訓練模型
現在我們有了圖像和標簽,可以開始訓練模型了。首先讓我們安裝這個包:
pip install ultralytics==8.0.38
ultralytics 庫變化非常快,有時會破壞 API,所以我更喜歡堅持使用一個版本。下面的代碼取決于版本 8.0.38(我寫這篇文章時的最新版本)。如果你升級到較新的版本,也許需要進行一些代碼調整才能使其正常工作。
開始訓練:
from ultralytics import YOLO
model = YOLO("yolov8n-seg.pt")
results = model.train(
batch=8,
device="cpu",
data="data.yaml",
epochs=7,
imgsz=120,
)
為了這篇文章的簡單性,我使用 Nano 模型 (yolov8n-seg),我僅在 CPU 上訓練它,只有 7 個 epoch。在我的筆記本電腦上進行訓練只花了幾秒鐘。
06理解結果
訓練完成后,你將在輸出末尾看到與此類似的一行:
Results saved to runs/segment/train60
讓我們看一下此處找到的一些結果:
驗證標注:
from IPython.display import Image as show_image show_image(filename="runs/segment/train60/val_batch0_labels.jpg")
在這里我們可以看到驗證集部分的真實標注。這應該幾乎完全對齊。如果你發現這些標注沒有很好地覆蓋物體,那么標注很可能是不正確的。
預測的驗證標簽:
show_image(filename="runs/segment/train60/val_batch0_pred.jpg")
在這里,我們可以看到訓練模型對部分驗證集(與我們上面看到的相同部分)所做的預測。這可以讓你了解模型的表現如何。請注意,為了創建此圖像,應選擇置信度閾值,此處使用的閾值是 0.5,這并不總是最佳閾值(我們將在稍后討論)。
精度曲線:
要理解這張圖表和下一張圖表,你需要熟悉精確度和召回率概念。這里很好地解釋了它們的工作原理。
show_image(filename="runs/segment/train60/MaskP_curve.png")
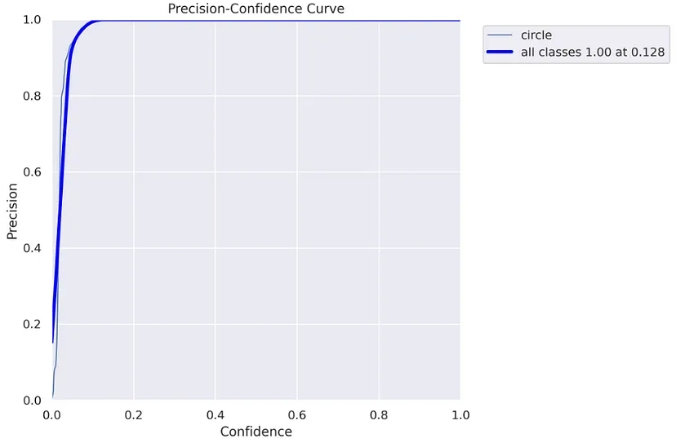
模型檢測到的每個對象都有一定的置信度,通常,如果在聲明“這是一個圓”時盡可能確定對你來說很重要,你將僅使用高置信度值(高置信度閾值)。當然,這需要權衡——你可能會錯過一些“圈子”。另一方面,如果你想“捕獲”盡可能多的“圓圈”,但要權衡其中一些不是真正的“圓圈”,可以同時使用低置信度值和高置信度值(低置信度閾值)。
上圖(以及下圖)可幫助你決定使用哪個置信閾值。在我們的例子中,我們可以看到,對于高于 0.128 的閾值,我們獲得 100% 的精度,這意味著所有對象都被正確預測。
請注意,因為我們實際上是在做分割任務,所以我們需要擔心另一個重要的閾值——IoU(交并集),如果你不熟悉,你可以在這里閱讀介紹文章。對于此圖表,使用的 IoU 為 0.5。
召回曲線:
show_image(filename="runs/segment/train60/MaskR_curve.png")
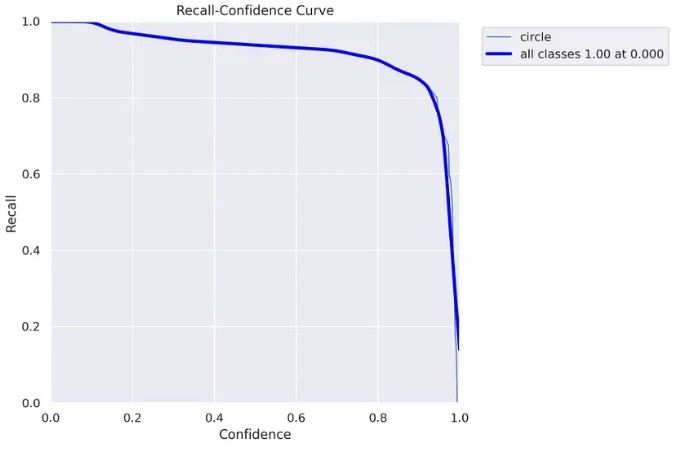 ? ?
? ?
在這里你可以看到召回率圖表,隨著置信度閾值的上升,召回率下降。這意味著你“抓住”的“圓圈”更少。
在這里你可以明白為什么在這種情況下使用 0.5 置信度閾值是一個壞主意。對于 0.5 的閾值,可以獲得大約 90% 的召回率。然而,在精度曲線中,我們看到對于高于 0.128 的閾值,我們獲得 100% 的精度,因此我們不需要達到 0.5,我們可以安全地使用 0.128 閾值并獲得 100% 的精度和幾乎 100% 記起 :)
精確率-召回率曲線:
這是精確率-召回率曲線的一個很好的解釋
show_image(filename="runs/segment/train60/MaskPR_curve.png")
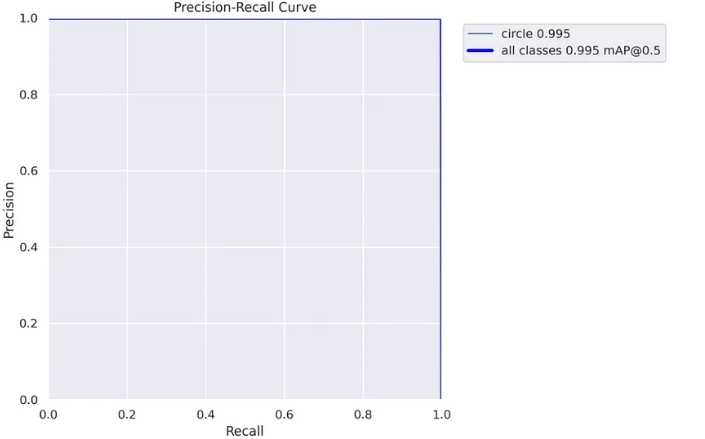 ?
?
這里我們可以清楚地看到之前得出的結論,對于這個模型,我們可以達到幾乎 100% 的精確率和 100% 的召回率。
這個圖表的缺點是我們看不到應該使用什么閾值,這就是為什么我們仍然需要上面的圖表。
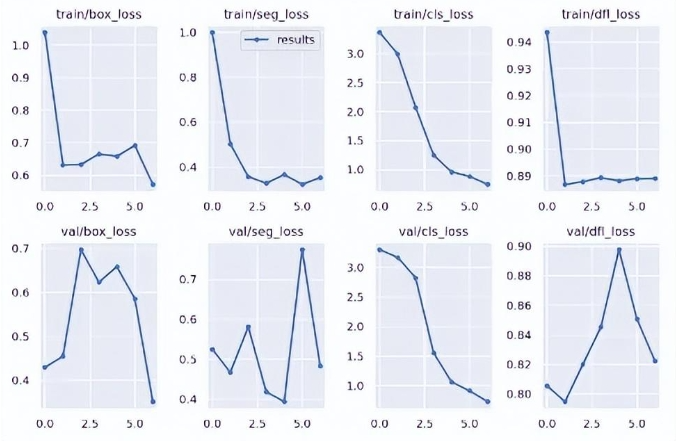
隨時間的推移損失
show_image(filename="runs/segment/train60/results.png")
 ?
?
在這里,你可以看到不同損失在訓練過程中如何變化,以及它們在每個時期后在驗證集上的表現如何。
關于損失,以及可以從這些圖表中得出的結論,有很多話要說,但是,這超出了本文的范圍。我只是想說你可以在這里找到它:)
07使用訓練好的模型
可以在結果目錄中找到的另一件事是模型本身。以下是如何在新圖像上使用該模型:
my_model = YOLO('runs/segment/train60/weights/best.pt')
results = list(my_model('datasets/test/images/img_5.png', conf=0.128))
result = results[0]
結果列表可能有多個值,每個值對應一個檢測到的對象。因為在此示例中,每個圖像中只有一個對象,所以我們采用第一個列表項。
你可以看到我在這里傳遞了我們之前找到的最佳置信度閾值 (0.128)。
有兩種方法可以獲取檢測到的對象在圖像中的實際位置。選擇正確的方法取決于你打算如何處理結果。我將展示這兩種方式。
result.masks.segments
[array([[ 0.10156, 0.34375],
[ 0.09375, 0.35156],
[ 0.09375, 0.35937],
[ 0.078125, 0.375],
[ 0.070312, 0.375],
[ 0.0625, 0.38281],
[ 0.38281, 0.71094],
[ 0.39062, 0.71094],
[ 0.39844, 0.70312],
[ 0.39844, 0.69531],
[ 0.41406, 0.67969],
[ 0.42187, 0.67969],
[ 0.44531, 0.46875],
[ 0.42969, 0.45312],
[ 0.42969, 0.41406],
[ 0.42187, 0.40625],
[ 0.41406, 0.40625],
[ 0.39844, 0.39062],
[ 0.39844, 0.38281],
[ 0.39062, 0.375],
[ 0.38281, 0.375],
[ 0.35156, 0.34375]], dtype=float32)]
這將返回對象的邊界多邊形,類似于我們傳遞標記數據的格式。
第二種方式:
result.masks.masks
tensor([[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]])
這將返回一個形狀為 (1, 128, 128) 的張量,表示圖像中的所有像素。作為對象一部分的像素接收 1,背景像素接收 0。
我們來看看面具是什么樣子的:
import torchvision.transforms as T T.ToPILImage()(result.masks.masks).show()
圖像的預測分割
這是原始圖像:
雖然并不完美,但對于很多應用來說已經足夠好了,而且 IoU 肯定高于 0.5。
08結束語
總之,與之前的 Yolo 版本相比,新的 ultralytics 庫更容易使用,尤其是對于分割任務,它現在是一等公民。你可以發現 Yolov5 也是 ultralytics 新軟件包的一部分,所以如果你不想使用新的 Yolo 版本(它仍然是新的和實驗性的),你可以使用眾所周知的 yolov5:
轉自新缸中之腦
審核編輯:湯梓紅
-
Linux
+關注
關注
87文章
11320瀏覽量
209832 -
命令
+關注
關注
5文章
688瀏覽量
22055 -
模型
+關注
關注
1文章
3261瀏覽量
48916 -
數據集
+關注
關注
4文章
1208瀏覽量
24737
原文標題:用自己的數據集訓練YOLOv8實例分割模型
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于YOLOv8實現自定義姿態評估模型訓練

TensorRT 8.6 C++開發環境配置與YOLOv8實例分割推理演示
在AI愛克斯開發板上用OpenVINO?加速YOLOv8分類模型

在AI愛克斯開發板上用OpenVINO?加速YOLOv8目標檢測模型

AI愛克斯開發板上使用OpenVINO加速YOLOv8目標檢測模型

在AI愛克斯開發板上用OpenVINO?加速YOLOv8-seg實例分割模型
教你如何用兩行代碼搞定YOLOv8各種模型推理

在AI愛克斯開發板上用OpenVINO?加速YOLOv8-seg實例分割模型
三種主流模型部署框架YOLOv8推理演示

YOLOv8實現旋轉對象檢測
YOLOv8中的損失函數解析






 工商網監
工商網監
評論