") 如何使用原子類型
如何使用原子類型
一、何為原子操作
原子操作:顧名思義就是不可分割的操作,該操作只存在未開始和已完成兩種狀態(tài),不存在中間狀態(tài);
原子類型:原子庫(kù)中定義的數(shù)據(jù)類型,對(duì)這些類型的所有操作都是原子的,包括通過原子類模板std::atomic< T >實(shí)例化的數(shù)據(jù)類型,也都是支持原子操作的。
二、如何使用原子類型
2.1 原子庫(kù)atomic支持的原子操作
原子庫(kù)< atomic >中提供了一些基本原子類型,也可以通過原子類模板實(shí)例化一個(gè)原子對(duì)象,下面列出一些基本原子類型及相應(yīng)的特化模板如下:
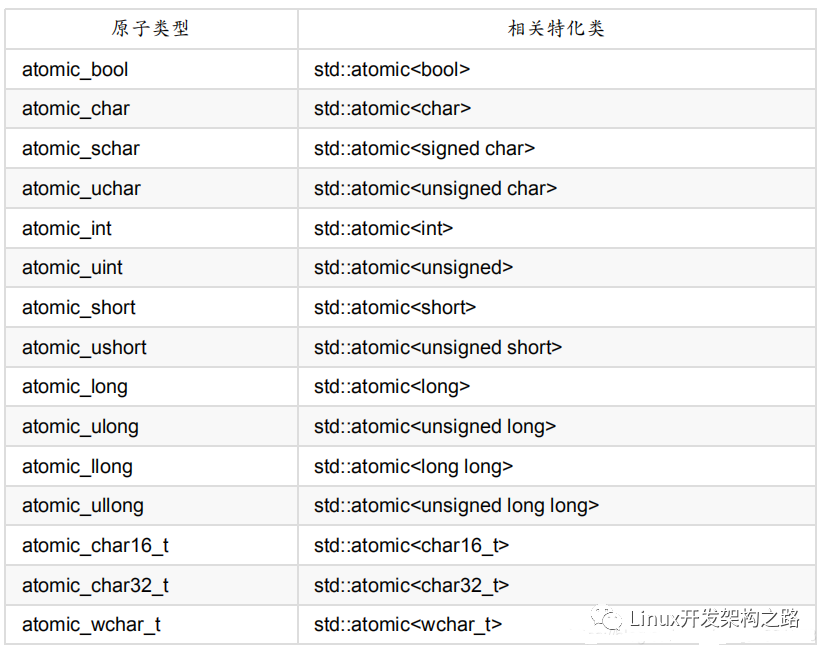
對(duì)原子類型的訪問,最主要的就是讀和寫,但原子庫(kù)提供的對(duì)應(yīng)原子操作是load()與store(val)。原子類型支持的原子操作如下:

2.2 原子操作中的內(nèi)存訪問模型
原子操作保證了對(duì)數(shù)據(jù)的訪問只有未開始和已完成兩種狀態(tài),不會(huì)訪問到中間狀態(tài),但我們?cè)L問數(shù)據(jù)一般是需要特定順序的,比如想讀取寫入后的最新數(shù)據(jù),原子操作函數(shù)是支持控制讀寫順序的,即帶有一個(gè)數(shù)據(jù)同步內(nèi)存模型參數(shù)std::memory_order,用于對(duì)同一時(shí)間的讀寫操作進(jìn)行排序。C++11定義的6種類型如下:
- memory_order_relaxed: 寬松操作,沒有同步或順序制約,僅對(duì)此操作要求原子性;
- memory_order_release & memory_order_acquire: 兩個(gè)線程A&B,A線程Release后,B線程Acquire能保證一定讀到的是最新被修改過的值;這種模型更強(qiáng)大的地方在于它能保證發(fā)生在A-Release前的所有寫操作,在B-Acquire后都能讀到最新值;
- memory_order_release & memory_order_consume: 上一個(gè)模型的同步是針對(duì)所有對(duì)象的,這種模型只針對(duì)依賴于該操作涉及的對(duì)象:比如這個(gè)操作發(fā)生在變量a上,而s = a + b; 那s依賴于a,但b不依賴于a; 當(dāng)然這里也有循環(huán)依賴的問題,例如:t = s + 1,因?yàn)閟依賴于a,那t其實(shí)也是依賴于a的;
- memory_order_seq_cst: 順序一致性模型,這是C++11原子操作的默認(rèn)模型;大概行為為對(duì)每一個(gè)變量都進(jìn)行Release-Acquire操作,當(dāng)然這也是一個(gè)最慢的同步模型;
內(nèi)存訪問模型屬于比較底層的控制接口,如果對(duì)編譯原理和CPU指令執(zhí)行過程不了解的話,容易引入bug。內(nèi)存模型不是本章重點(diǎn),這里不再展開介紹,后續(xù)的代碼都使用默認(rèn)的順序一致性模型或比較穩(wěn)妥的Release-Acquire模型。
2.3 使用原子類型替代互斥鎖編程
為便于比較,直接基于前篇文章:線程同步之互斥鎖中的示例程序進(jìn)行修改,用原子庫(kù)取代互斥庫(kù)的代碼如下:
//atomic1.cpp 使用原子庫(kù)取代互斥庫(kù)實(shí)現(xiàn)線程同步
#include < chrono >
#include < atomic >
#include < thread >
#include < iostream >
std::chrono::milliseconds interval(100);
std::atomic< bool > readyFlag(false); //原子布爾類型,取代互斥量
std::atomic< int > job_shared(0); //兩個(gè)線程都能修改'job_shared',將該變量特化為原子類型
int job_exclusive = 0; //只有一個(gè)線程能修改'job_exclusive',不需要保護(hù)
//此線程只能修改 'job_shared'
void job_1()
{
std::this_thread::sleep_for(5 * interval);
job_shared.fetch_add(1);
std::cout < < "job_1 shared (" < < job_shared.load() < < ")n";
readyFlag.store(true); //改變布爾標(biāo)記狀態(tài)為真
}
// 此線程能修改'job_shared'和'job_exclusive'
void job_2()
{
while (true) { //無限循環(huán),直到可訪問并修改'job_shared'
if (readyFlag.load()) { //判斷布爾標(biāo)記狀態(tài)是否為真,為真則修改‘job_shared’
job_shared.fetch_add(1);
std::cout < < "job_2 shared (" < < job_shared.load() < < ")n";
return;
} else { //布爾標(biāo)記為假,則修改'job_exclusive'
++job_exclusive;
std::cout < < "job_2 exclusive (" < < job_exclusive < < ")n";
std::this_thread::sleep_for(interval);
}
}
}
int main()
{
std::thread thread_1(job_1);
std::thread thread_2(job_2);
thread_1.join();
thread_2.join();
getchar();
return 0;
}
由示例程序可以看出,原子布爾類型可以實(shí)現(xiàn)互斥鎖的部分功能,但在使用條件變量condition variable時(shí),仍然需要mutex保護(hù)對(duì)condition variable的消費(fèi),即使condition variable是一個(gè)atomic object。
2.4 使用原子類型實(shí)現(xiàn)自旋鎖
自旋鎖(spinlock)與互斥鎖(mutex)類似,在任一時(shí)刻最多只能有一個(gè)持有者,但如果資源已被占用,互斥鎖會(huì)讓資源申請(qǐng)者進(jìn)入睡眠狀態(tài),而自旋鎖不會(huì)引起調(diào)用者睡眠,會(huì)一直循環(huán)判斷該鎖是否成功獲取。自旋鎖是專為防止多處理器并發(fā)而引入的一種鎖,它在內(nèi)核中大量應(yīng)用于中斷處理等部分(對(duì)于單處理器來說,防止中斷處理中的并發(fā)可簡(jiǎn)單采用關(guān)閉中斷的方式,即在標(biāo)志寄存器中關(guān)閉/打開中斷標(biāo)志位,不需要自旋鎖)。
對(duì)于多核處理器來說,檢測(cè)到鎖可用與設(shè)置鎖狀態(tài)兩個(gè)動(dòng)作需要實(shí)現(xiàn)為一個(gè)原子操作,如果分為兩個(gè)原子操作,則可能一個(gè)線程在獲得鎖后設(shè)置鎖前被其余線程搶到該鎖,導(dǎo)致執(zhí)行錯(cuò)誤。這就需要原子庫(kù)提供對(duì)原子變量“讀-修改-寫(Read-Modify-Write)”的原子操作,上文原子類型支持的操作中就提供了RMW(Read-Modify-Write)原子操作,比如a.exchange(val)與a.compare_exchange(expected,desired)。
標(biāo)準(zhǔn)庫(kù)還專門提供了一個(gè)原子布爾類型std::atomic_flag,不同于所有 std::atomic 的特化,它保證是免鎖的,不提供load()與store(val)操作,但提供了test_and_set()與clear()操作,其中test_and_set()就是支持RMW的原子操作,可用std::atomic_flag實(shí)現(xiàn)自旋鎖的功能,代碼如下:
//atomic2.cpp 使用原子布爾類型實(shí)現(xiàn)自旋鎖的功能
#include < thread >
#include < vector >
#include < iostream >
#include < atomic >
std::atomic_flag lock = ATOMIC_FLAG_INIT; //初始化原子布爾類型
void f(int n)
{
for (int cnt = 0; cnt < 100; ++cnt) {
while (lock.test_and_set(std::memory_order_acquire)) // 獲得鎖
; // 自旋
std::cout < < n < < " thread Output: " < < cnt < < 'n';
lock.clear(std::memory_order_release); // 釋放鎖
}
}
int main()
{
std::vector< std::thread > v; //實(shí)例化一個(gè)元素類型為std::thread的向量
for (int n = 0; n < 10; ++n) {
v.emplace_back(f, n); //以參數(shù)(f,n)為初值的元素放到向量末尾,相當(dāng)于啟動(dòng)新線程f(n)
}
for (auto& t : v) { //遍歷向量v中的元素,基于范圍的for循環(huán),auto&自動(dòng)推導(dǎo)變量類型并引用指針指向的內(nèi)容
t.join(); //阻塞主線程直至子線程執(zhí)行完畢
}
getchar();
return 0;
}
自旋鎖除了使用atomic_flag的TAS(Test And Set)原子操作實(shí)現(xiàn)外,還可以使用普通的原子類型std::atomic實(shí)現(xiàn):其中a.exchange(val)是支持TAS原子操作的,a.compare_exchange(expected,desired)是支持CAS(Compare And Swap)原子操作的,感興趣可以自己實(shí)現(xiàn)出來。其中CAS原子操作是無鎖編程的主要實(shí)現(xiàn)手段,我們接著往下介紹無鎖編程。
三、如何進(jìn)行無鎖編程
3.1 什么是無鎖編程
在原子操作出現(xiàn)之前,對(duì)共享數(shù)據(jù)的讀寫可能得到不確定的結(jié)果,所以多線程并發(fā)編程時(shí)要對(duì)使用鎖機(jī)制對(duì)共享數(shù)據(jù)的訪問過程進(jìn)行保護(hù)。但鎖的申請(qǐng)釋放增加了訪問共享資源的消耗,且可能引起線程阻塞、鎖競(jìng)爭(zhēng)、死鎖、優(yōu)先級(jí)反轉(zhuǎn)、難以調(diào)試等問題。
現(xiàn)在有了原子操作的支持,對(duì)單個(gè)基礎(chǔ)數(shù)據(jù)類型的讀、寫訪問可以不用鎖保護(hù)了,但對(duì)于復(fù)雜數(shù)據(jù)類型比如鏈表,有可能出現(xiàn)多個(gè)核心在鏈表同一位置同時(shí)增刪節(jié)點(diǎn)的情況,這將會(huì)導(dǎo)致操作失敗或錯(cuò)序。所以我們?cè)趯?duì)某節(jié)點(diǎn)操作前,需要先判斷該節(jié)點(diǎn)的值是否跟預(yù)期的一致,如果一致則進(jìn)行操作,不一致則更新期望值,這幾步操作依然需要實(shí)現(xiàn)為一個(gè)RMW(Read-Modify-Write)原子操作,這就是前面提到的CAS(Compare And Swap)原子操作,它是無鎖編程中最常用的操作。
既然無鎖編程是為了解決鎖機(jī)制帶來的一些問題而出現(xiàn)的,那么無鎖編程就可以理解為不使用鎖機(jī)制就可保證多線程間原子變量同步的編程。無鎖(lock-free)的實(shí)現(xiàn)只是將多條指令合并成了一條指令形成一個(gè)邏輯完備的最小單元,通過兼容CPU指令執(zhí)行邏輯形成的一種多線程編程模型。
無鎖編程是基于原子操作的,對(duì)基本原子類型的共享訪問由load()與store(val)即可保證其并發(fā)同步,對(duì)抽象復(fù)雜類型的共享訪問則需要更復(fù)雜的CAS來保證其并發(fā)同步,并發(fā)訪問過程只是不使用鎖機(jī)制了,但還是可以理解為有鎖止行為的,其粒度很小,性能更高。對(duì)于某個(gè)無法實(shí)現(xiàn)為一個(gè)原子操作的并發(fā)訪問過程還是需要借助鎖機(jī)制來實(shí)現(xiàn)。
3.1 CAS原子操作實(shí)現(xiàn)無鎖編程
CAS原子操作主要是通過函數(shù)a.compare_exchange(expected,desired)實(shí)現(xiàn)的,其語義為“我認(rèn)為V的值應(yīng)該為A,如果是,那么將V的值更新為B,否則不修改并告訴V的值實(shí)際為多少”,CAS算法的實(shí)現(xiàn)偽碼如下:
bool compare_exchange_strong(T& expected, T desired)
{
if( this- >load() == expected ) {
this- >store(desired);
return true;
} else {
expected = this- >load();
return false;
}
}
下面嘗試實(shí)現(xiàn)一個(gè)無鎖棧,代碼如下:
//atomic3.cpp 使用CAS操作實(shí)現(xiàn)一個(gè)無鎖棧
#include < atomic >
#include < iostream >
template< typename T >
class lock_free_stack
{
private:
struct node
{
T data;
node* next;
node(const T& data) : data(data), next(nullptr) {}
};
std::atomic< node* > head;
public:
lock_free_stack(): head(nullptr) {}
void push(const T& data)
{
node* new_node = new node(data);
do{
new_node- >next = head.load(); //將 head 的當(dāng)前值放入new_node- >next
}while(!head.compare_exchange_strong(new_node- >next, new_node));
// 如果新元素new_node的next和棧頂head一樣,證明在你之前沒人操作它,使用新元素替換棧頂退出即可;
// 如果不一樣,證明在你之前已經(jīng)有人操作它,棧頂已發(fā)生改變,該函數(shù)會(huì)自動(dòng)更新新元素的next值為改變后的棧頂;
// 然后繼續(xù)循環(huán)檢測(cè)直到狀態(tài)1成立退出;
}
T pop()
{
node* node;
do{
node = head.load();
}while (node && !head.compare_exchange_strong(node, node- >next));
if(node)
return node- >data;
}
};
int main()
{
lock_free_stack< int > s;
s.push(1);
s.push(2);
s.push(3);
std::cout < < s.pop() < < std::endl;
std::cout < < s.pop() < < std::endl;
getchar();
return 0;
}
程序注釋中已經(jīng)解釋的很清楚了,在將數(shù)據(jù)壓棧前,先通過比較原子類型head與新元素的next指向?qū)ο笫欠裣嗟葋砼袛鄅ead是否已被其他線程修改,根據(jù)判斷結(jié)果選擇是繼續(xù)操作還是更新期望,而這一切都是在一個(gè)原子操作中完成的,保證了在不使用鎖的情況下實(shí)現(xiàn)共享數(shù)據(jù)的并發(fā)同步。
CAS 看起來很厲害,但也有缺點(diǎn),最著名的就是 ABA 問題,假設(shè)一個(gè)變量 A ,修改為 B之后又修改為 A,CAS 的機(jī)制是無法察覺的,但實(shí)際上已經(jīng)被修改過了。如果在基本類型上是沒有問題的,但是如果是引用類型呢?這個(gè)對(duì)象中有多個(gè)變量,我怎么知道有沒有被改過?聰明的你一定想到了,加個(gè)版本號(hào)啊。每次修改就檢查版本號(hào),如果版本號(hào)變了,說明改過,就算你還是 A,也不行。
上面的例子節(jié)點(diǎn)指針也屬于引用類型,自然也存在ABA問題,比如在線程2執(zhí)行pop操作,將A,B都刪掉,然后創(chuàng)建一個(gè)新元素push進(jìn)去,因?yàn)?a href="http://m.1cnz.cn/v/tag/527/" target="_blank">操作系統(tǒng)的內(nèi)存分配機(jī)制會(huì)重復(fù)使用之前釋放的內(nèi)存,恰好push進(jìn)去的內(nèi)存地址和A一樣,我們記為A’,這時(shí)候切換到線程1,CAS操作檢查到A沒變化成功將B設(shè)為棧頂,但B是一個(gè)已經(jīng)被釋放的內(nèi)存塊。該問題的解決方案就是上面說的通過打標(biāo)簽標(biāo)識(shí)A和A’為不同的指針,具體實(shí)現(xiàn)代碼讀者可以嘗試實(shí)現(xiàn)。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7081瀏覽量
89196 -
編程
+關(guān)注
關(guān)注
88文章
3628瀏覽量
93812 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4338瀏覽量
62749 -
C++
+關(guān)注
關(guān)注
22文章
2112瀏覽量
73707 -
原子
+關(guān)注
關(guān)注
0文章
88瀏覽量
20316
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
三種最常見的接線端子類型:PCB安裝,隔離帶和饋通

請(qǐng)問三級(jí)管開關(guān)如果控制負(fù)電壓對(duì)管子類型有要求嗎
芯靈思SinlinxA33開發(fā)板Linux內(nèi)核原子操作(附實(shí)測(cè)代碼)
請(qǐng)教大神我可以在OTA分區(qū)運(yùn)行時(shí)更改分區(qū)子類型嗎?
如何在運(yùn)行時(shí)更改分區(qū)子類型?
等離子類型
pcb接線端子類型有哪些
Rust原子類型和內(nèi)存排序
接線端子類型介紹
常見的接線端子類型有哪些?
鋰離子電池離子液體電解質(zhì)體系的MD模擬





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論