 了解亞馬遜云科技搭建智能搜索大語言模型增強方案的快速部署流程
了解亞馬遜云科技搭建智能搜索大語言模型增強方案的快速部署流程
背景
知識庫需求在各行各業中普遍存在,例如制造業中歷史故障知識庫、游戲社區平臺的內容知識庫、電商的商品推薦知識庫和醫療健康領域的掛號推薦知識庫系統等。為保證推薦系統的實效性和準確性,需要大量的數據/算法/軟件工程師的人力投入和包括硬件在內的物力投入。那么在自己的環境中搭建智能搜索大語言模型增強方案是必不可少的。因此,本篇內容主要為大語言模型方案的快速部署。該方案部署流程并不復雜,只需要您對于亞馬遜云科技相關服務有一個基本的了解即可。
方案架構圖與功能原理
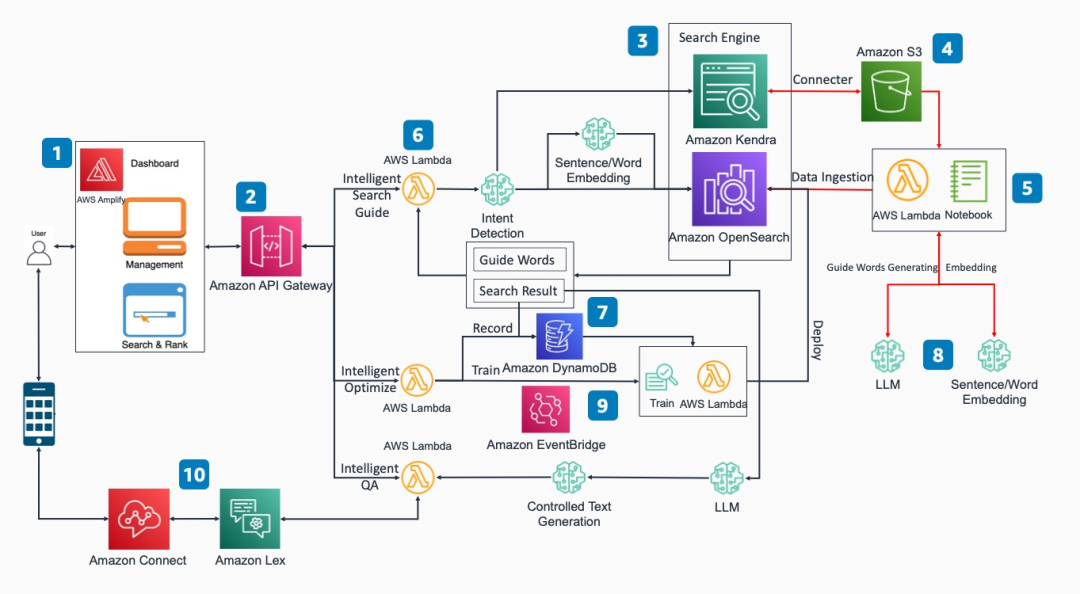
該方案分為以下幾個核心功能模塊:
前端訪問界面:該方案提供了基于React的前端訪問界面。用戶可以通過網頁以REST API的形式進行智能文檔搜索等功能的操作。
REST API:通過集成了相應Amazon API Gateway和Amazon Lambda函數的實現和后端搜索引擎,數據庫和模型推理端點交互。
企業搜索引擎:基于Amazon OpenSearch或Amazon Kendra。可以基于雙向反饋的學習機制,自動持續迭代提高輸出匹配精準度。同時采用引導式搜索機制,提高搜索輸入描述的精準度。
數據源存儲:可選用多種存儲方式如數據庫,對象存儲等,在這里Amazon Kendra通過連接器獲取Amazon S3上的對象。
向量化數據注入:采用Amazon SageMaker的Notebook模塊或者Amazon Lambda程序將原始數據向量化后的數據注入Amazon OpenSearch。
智能搜索/引導/問答等功能模塊:采用Amazon Lambda函數實現和后端搜索引擎,數據庫和模型推理端點交互。
記錄數據庫:用戶反饋記錄存儲在數據庫Amazon DynamoDB。
機器學習模型:企業可以根據自身需要構建大語言模型和詞向量模型,將選取好的模型托管到Amazon SageMaker的endpoint節點。
反饋優化:用戶在前端頁面反饋最優搜索結果,通過手動或事件觸發器Amazon EventBridge觸發新的訓練任務并且重新部署到搜索引擎。
插件式應用:利用該方案核心能力可以與Amazon Lex集成以實現智能會話機器人功能,也可以與Amazon Connect集成實現智能語音客服功能。
實施步驟介紹
以smart-search v1版本為例,為大家講解方案的整個部署流程。
1、環境準備
首先您需要在您的開發環境中安裝好python 3、pip以及npm等通用工具,并保證您的環境中擁有16GB以上的存儲空間。根據您的使用習慣,您可以在自己的開發筆記本(Mac OS或Linux環境)上部署,也可以選擇EC2或者Cloud9進行部署。
2、CDK自動部署
2.1 獲取代碼安裝Amazon CDK包
獲取代碼后把代碼拷貝到指定目錄下。打開終端窗口,進入smart_search的軟件包,并切換到名為deployment文件夾下:

進入到deployment目錄后,相應的CDK部署操作均在該目錄下進行。然后安裝Amazon CDK包。
2.2 安裝CDK自動化部署腳本所需的所有依賴項和環境變量
在deployment目錄下運行以下命令安裝依賴庫:

然后將您的12位亞馬遜云科技賬號信息、Acess Key ID、Secret Access Key、以及需要部署的Region ID導入到環境變量中:
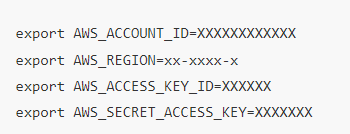
然后運行“cdk bootstrap”安裝賬戶和目標區域內的CDK工具包,例如:

2.3 在cdk.json可以進行自定義配置
該方案的默認配置文件在deployment目錄下的cdk.json文件中,如果想要自行配置需要部署哪些功能模塊,可以根據需要修改cdk.json的“context”部分。例如,如果需要修改部署哪些功能函數,可以對“selection”值進行修改。
默認的參數如下所示:

如果僅需要使用“支持knn的文檔搜索功能”,可以僅保留“knn_doc”。除此之外,還可以選擇通過修改cdk.json的其他相應參數來自定義部署方式、部署哪些插件和名稱和路徑等配置。
2.4 CDK命令自動化署
運行下面的命令將驗證環境并生成Amaon CloudFormation的json模版:

如果沒有報錯,則運行以下命令部署全部堆棧。

CDK部署將提供相關Amazon CloudFormation堆棧以及相關資源,例如Amazon Lambda、Amazon API Gateway、Amazon OpenSearch實例和Amazon SageMaker的notebook實例等,預計安裝的部署時間大約為30分鐘左右。
3、利用Amazon SageMaker的Notebook實例部署模型與數據導入
3.1 部署模型
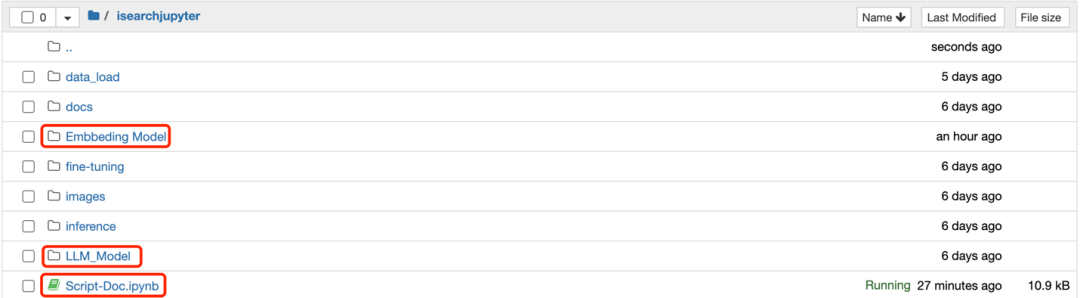
3.1.1進入Amazon SageMaker控制臺,進入NoteBook Instances,選擇SmartSearchNoteBook實例,點擊“Open Jupyter”,進入SmartSearch的代碼主目錄,點擊“isearchjupyter”目錄進入,能看到包括Embbeding Model、LLM_Model等目錄,這兩個目錄包含模型部署腳本,而Script-Doc.ipynb腳本則會用于后面的文檔上傳,目錄如下圖所示:
3.1.2首先安裝Embbeding Model,進入“/isearchjupyter/Embbeding Model”目錄,能看到對應的幾個腳本。其中“EmbbedingModel_shibing624_text2vec-base-chinese.ipynb”為中文的詞向量模型,其他兩個為英文,打開相應腳本依次運行單元格,開始部署embbeding model。等待script部署完畢,成功部署后會在Amazon SageMaker的endpoint中看到名為“huggingface-inference-eb”的endpoint,狀態為“InService”。
3.1.3然后部署大語言模型,LLM_Model目錄下當前包含了中文和英文的大語言模型庫。這里先為大家介紹中文的大語言模型的部署方法,找到isearchjupyter/LLM_Model/llm_chinese/code/inference.py,該文件定義了大語言模型的統一部署方法。大語言模型可以通過唯一的名稱進行部署,把該唯一名稱聲明為“LLM_NAME”的參數值,作為參數傳遞給部署腳本。可以根據大語言模型的文檔來確定“LLM_NAME”的值。打開網址后對照該文檔找到該模型部署的唯一名稱,然后粘貼到為“LLM_NAME”賦值的位置即可,可以參照該方法舉一反三,指定項目中需要使用的大語言模型。修改inference.py文件后進入“isearchjupyter/LLM_Model/llm_chinese/“目錄,運行該目錄的script。等待script 部署完畢,成功部署后會在Amazon SageMaker的endpoint中看到名為“pytorch-inference-llm-v1”的endpoint。
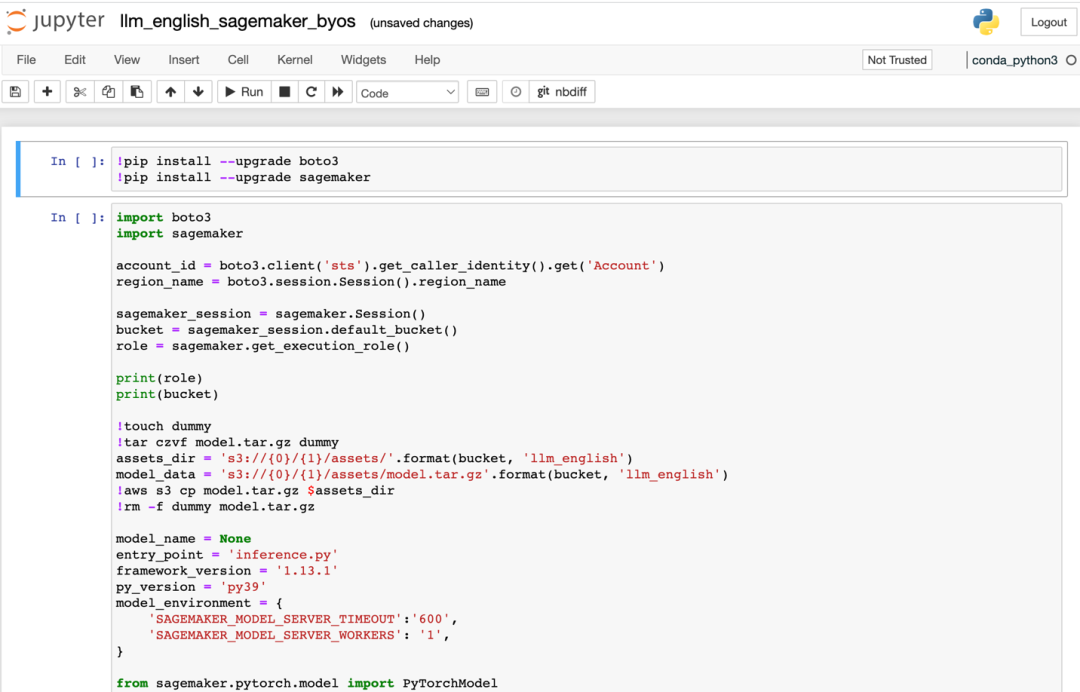
如果選擇部署英文大語言模型,部署方式類似,需要將英文大語言模型的參數填入LLM_Model/llm_english/code/inference.py文件的“LLM_NAME”參數中。找到該大語言模型項目名稱,則然后復制該名稱再粘貼到為“LLM_NAME”賦值的位置,可以用該方法進行舉一反三,指定任意一個滿足業務需求的大語言模型。進入“isearchjupyter/LLM_Model/llm_english/”的目錄下,依次運行該目錄下英文大語言模型的腳本的部署單元格。如下圖所示:
3.1.4安裝完成后,看到兩個endpoint已經在”InService”狀態,如下圖:
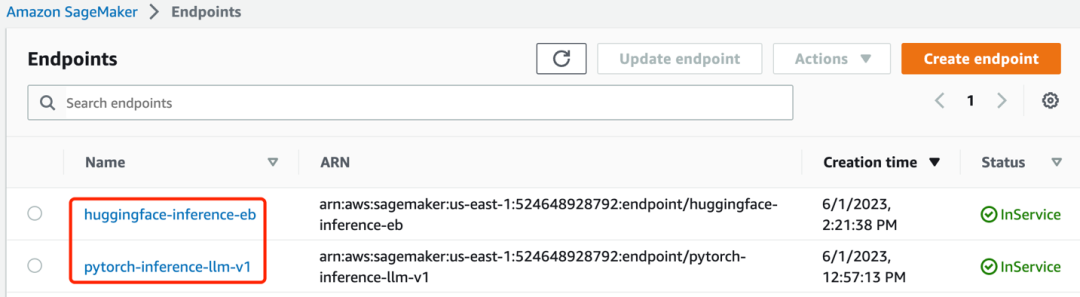
3.2 知識庫數據上傳
3.2.1數據準備。進入jupyter的目錄“/isearchjupyter”,在“docs”目錄,將上傳所需要的word、excel或pdf等格式的文檔進行上傳,該文件夾下已經提供了用于測試的樣例文件“sample.docx”。
3.2.2 進入Script-Doc.ipynb,修改單元格“Hyperparameter”的如下參數,folder_path為指定的docs目錄,index_name為Amazon OpenSearch的index名稱,如下圖:
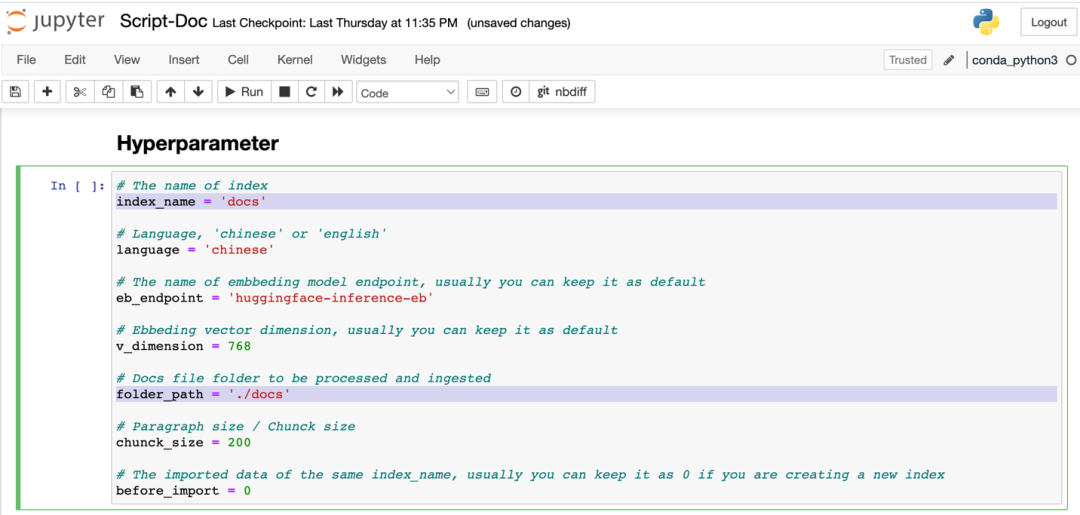
然后從頭運行這個script,完成數據導入。
4、配置Web UI
4.1 進入smart_search/ search-web-knn目錄,該目錄包含基于React的前端界面代碼。然后對/src/pages/common/constants.js文件進行編輯,如下圖所示:
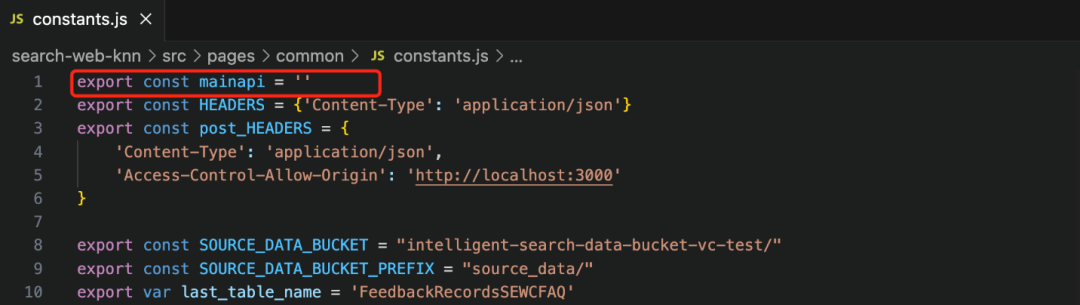
Mainapi常變量指定了前端調用的API入口。該值可以從網頁端進入API Gateway中獲取,進入“smartsearch-api”的Stages側邊欄,將prod stage的involke URL賦值給constants.js的mainapi常變量。
4.2 檢查主頁面參數配置。smart_search/search-web-knn/src/pages/MainSearchDoc.jsx為功能展示頁面,在該文件的last_index參數設置了頁面自動填充的默認index值,將上文Notebook實例部署的index name填入,如“docs”。
4.3 運行前端界面。進入目錄 search-web-knn,執行如下兩條命令:

然后運行以下命令啟動前端界面:

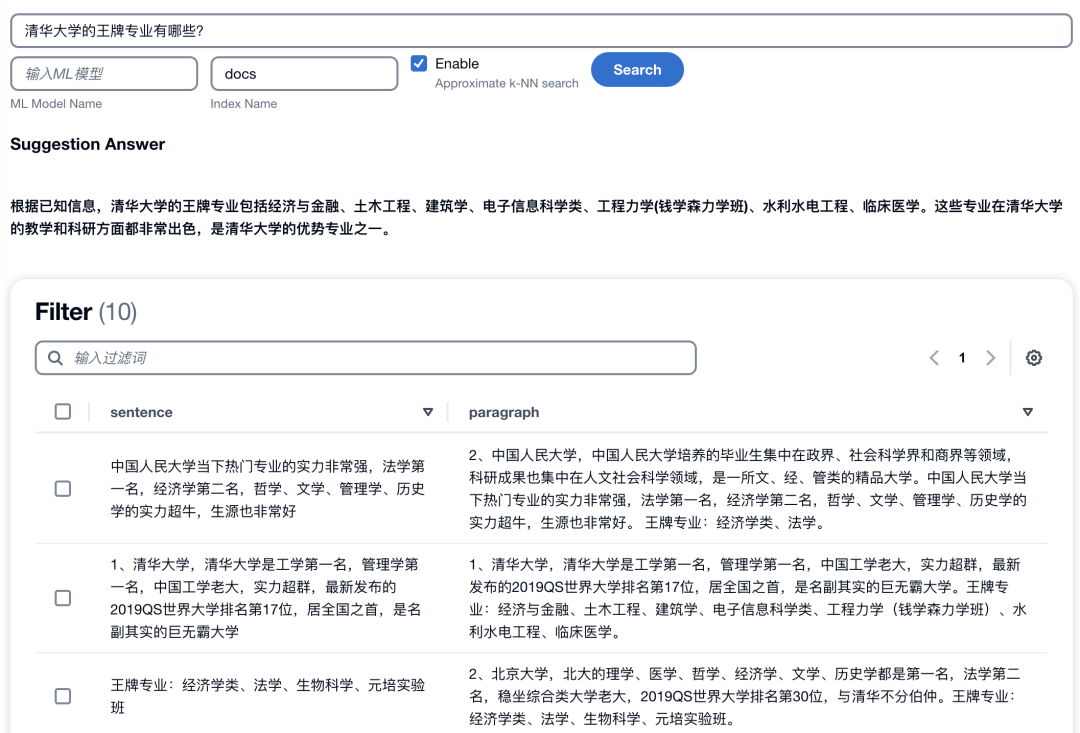
一切順利的話,將得到一個網頁版界面。在本地開發筆記本部署的默認訪問地址和端口號是localhost:3000,如果是EC2部署,需要啟用對應端口訪問的安全組策略,通過EC2的公網地址加端口號進行訪問。該前端頁面的使用方法為:將問題輸入搜索欄,配置index名稱和k-NN選項,點擊“Search”按鈕后您可以得到一個基于企業知識庫的大語言模型匯總回答。如下圖所示:
5、安裝擴展插件
5.1 與Amazon Lex集成實現智能聊天機器人
本方案已經集成了Amazon Lex的會話機器人功能,Amazon Lex當前在海外區可用。在cdk.json文件中,將“bot”加入extension鍵值處。
cdk部署成功后進入管理界面可以看到名為“llmbot”的對話機器人,如下圖:
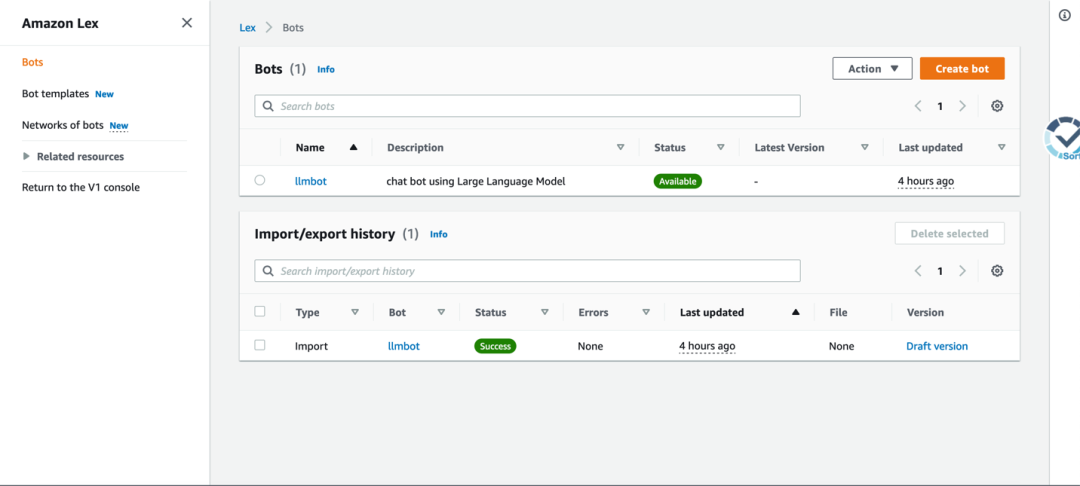
該機器人可以方便地進行前端頁面的集成。
5.2 與Amazon Connect集成實現智能語音客服
Amazon Connect為亞馬遜云科技的云呼叫中心服務,該服務當前在海外區可用。該方案可以通過Amazon Lex機器人將大語言模型能力集成到Amazon Connect云呼叫中心中,通過以下幾個步驟可以使您獲得一個支持語音呼叫功能的智能客服機器人。
5.2.1 將上一步生成的llmbot機器人集成到現有Amazon Connect實例中。
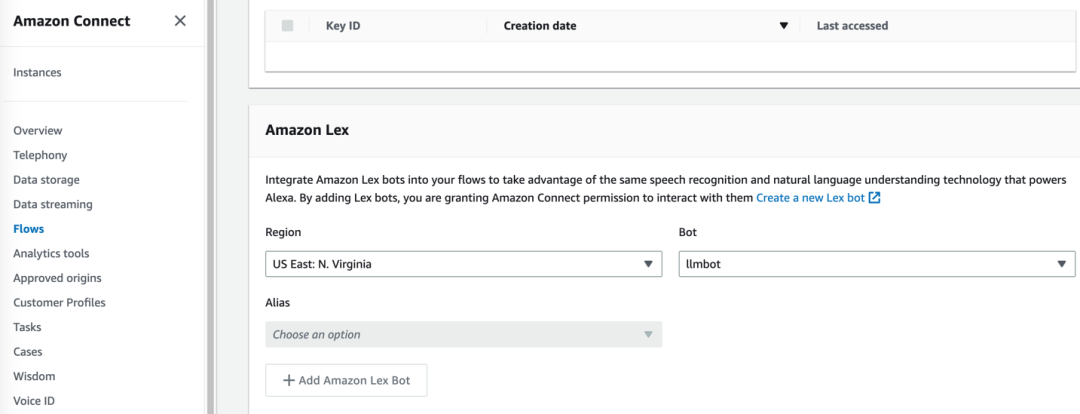
5.2.2 然后進入Amazon Connect實例中,將smart-search/extension/connect里面的文件導入到Contact Flow中,并保存和發布。
5.2.3 最后在Amazon Connect中將呼入號碼與上一步配置的Contact Flow進行關聯。則所有呼入該號碼的語音通話將會連接到智能客服的呼叫服務流程。
正常情況下,智能客服將會識別呼入人的語音輸入,隨后集成到Amazon Connect的智能客服機器人會基于企業知識庫信息和大語言模型的能力進行以接近人類的邏輯方式進行語音回答。
6、資源清理
想要將資源進行清理時,請使用以下命令將所有堆棧進行刪除:
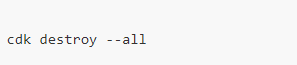
注意:通過Amazon SageMaker的Notebook實例創建的推理模型資源需要進行手動刪除,在Amazon SageMaker的“inference”邊欄進入“endpoint”,點擊“delete”,將所有endpoint進行刪除。
當堆棧創建的Amazon S3桶中已經有了數據或者存在其他手動創建或修改的資源時,則也需要手動刪除。
總結
通過此次部署,已經成功掌握了該方案的部署方法,也對該方案有了更深的了解。亞馬遜云科技將會對該方案進行持續的迭代與優化以支持更多的數據類型、模型庫與擴展功能,進而將方案的能力延伸到更多的業務場景中去。該方案可以解決許多行業和領域的專業或通用場景,通過使用該方案可以使用人工智能的最新進展和亞馬遜云科技的產品來為行業發展注入新的活力。
審核編輯 黃宇
-
語言模型
+關注
關注
0文章
538瀏覽量
10340 -
亞馬遜
+關注
關注
8文章
2680瀏覽量
83604
發布評論請先 登錄
相關推薦
亞馬遜云科技發布Amazon Trainium2實例
亞馬遜云科技與SAP推出GROW with SAP解決方案
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
基于亞馬遜云科技的GROW with SAP解決方案 助力企業簡化云端ERP部署
飛利浦與亞馬遜云科技擴展戰略合作,增強HealthSuite云服務能力并賦能生成式AI工作流





 工商網監
工商網監
評論