

今天,由李開復(fù)打造的 AI 大模型創(chuàng)業(yè)公司“零一萬物”發(fā)布了一系列開源大模型:Yi-34B 和 Yi-6B。
Yi-34B 是一個雙語(英語和中文)基礎(chǔ)模型,經(jīng)過 340 億個參數(shù)訓(xùn)練,明顯小于 Falcon-180B 和 Meta LlaMa2-70B 等其他開放模型。在發(fā)布會中,李開復(fù)稱其數(shù)據(jù)采集、算法研究、團(tuán)隊配置均為世界第一梯隊,對標(biāo) OpenAI、谷歌一線大廠,并抱有成為世界第一的初衷和決心。同時,他表示 Yi-34B 是“全球最強(qiáng)開源模型”,其通用能力、知識推理、閱讀理解等多指標(biāo)均處于全球榜單首位。
零一萬物團(tuán)隊也進(jìn)行了一系列打榜測試,具體成績包括:
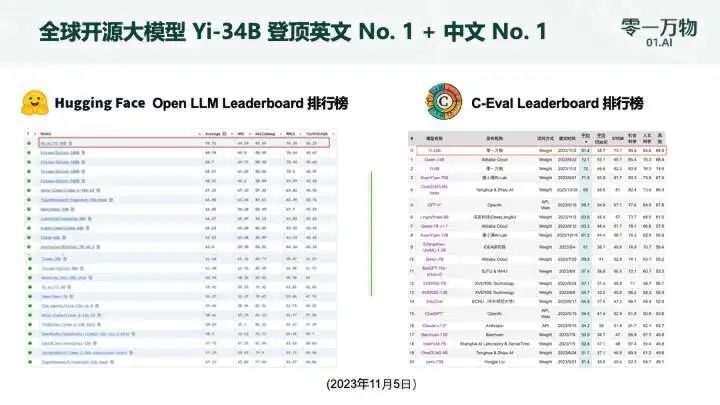
Hugging Face 英文測試榜單,以 70.72 分?jǐn)?shù)位列全球第一;
以小博大,作為國產(chǎn)大模型碾壓 Llama-2 70B 和 Falcon-180B 等一眾大模型(參數(shù)量僅為后兩者的 1/2、1/5);
C-Eval 中文能力排行榜位居第一,超越了全球所有開源模型;
MMLU、BBH 等八大綜合能力表現(xiàn)全部勝出,Yi-34B 在通用能力、知識推理、閱讀理解等多項指標(biāo)評比中“擊敗全球玩家”;
......
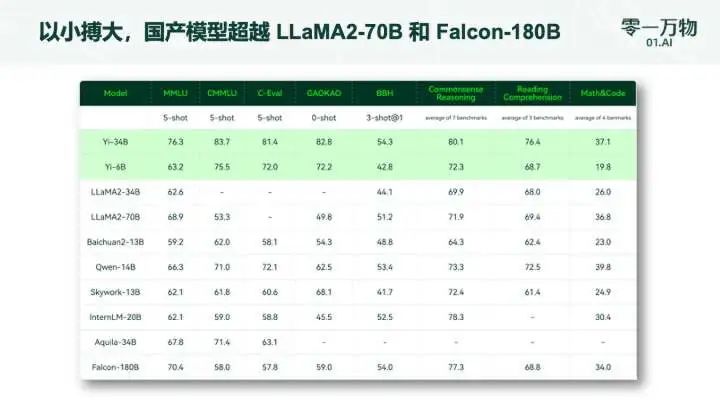
然而,在發(fā)布中,也有一點(diǎn)需要指出,那就是 Yi 系列模型在 GSM8k 和 MBPP 的數(shù)學(xué)以及代碼測評方面表現(xiàn)不如 GPT 模型出色。這是因?yàn)閳F(tuán)隊希望在預(yù)訓(xùn)練階段希望先盡可能保留模型的通用能力,所以訓(xùn)練數(shù)據(jù)中沒有加入過多數(shù)學(xué)和代碼數(shù)據(jù)。后續(xù)他們計劃在開源系列中推出專注于代碼和數(shù)學(xué)領(lǐng)域的繼續(xù)訓(xùn)練模型。
200K 上下文窗口, 能處理 40 萬字文本
值得注意的是,此次開源的 Yi-34B 模型,將發(fā)布全球最長、可支持 200K 超長上下文窗口(context window)版本,可以處理約 40 萬漢字超長文本輸入。這意味著 Yi-34B 不僅能提供更豐富的語義信息,理解超過 1000 頁的 PDF 文檔,還讓很多依賴于向量數(shù)據(jù)庫構(gòu)建外部知識庫的場景,都可以用上下文窗口來進(jìn)行替代。
相比之下,OpenAI 的 GPT-4 上下文窗口只有 32K,文字處理量約 2.5 萬字。今年三月,硅谷知名 AI 2.0 創(chuàng)業(yè)公司 Anthropic 的 Claude2-100K 將上下文窗口擴(kuò)展到了 100K 規(guī)模,零一萬物直接加倍,并且是第一家將超長上下文窗口在開源社區(qū)開放的大模型公司。
在語言模型中,上下文窗口是大模型綜合運(yùn)算能力的金指標(biāo)之一,對于理解和生成與特定上下文相關(guān)的文本至關(guān)重要,擁有更長窗口的語言模型可以處理更豐富的知識庫信息,生成更連貫、準(zhǔn)確的文本。
此外,在文檔摘要、基于文檔的問答等下游任務(wù)中,長上下文的能力發(fā)揮著關(guān)鍵作用,行業(yè)應(yīng)用場景廣闊。在法律、財務(wù)、傳媒、檔案整理等諸多垂直場景里,更準(zhǔn)確、更連貫、速度更快的長文本窗口功能,可以成為人們更可靠的 AI 助理,讓生產(chǎn)力得到大幅提升。然而,受限于計算復(fù)雜度、數(shù)據(jù)完備度等問題,上下文窗口規(guī)模擴(kuò)充從計算、內(nèi)存和通信的角度存在各種挑戰(zhàn),因此大多數(shù)發(fā)布的大型語言模型僅支持幾千 tokens 的上下文長度。為了解決這個限制,零一萬物技術(shù)團(tuán)隊實(shí)施了一系列優(yōu)化,包括:計算通信重疊、序列并行、通信壓縮等。通過這些能力增強(qiáng),實(shí)現(xiàn)了在大規(guī)模模型訓(xùn)練中近 100 倍的能力提升。
實(shí)現(xiàn) 40% 訓(xùn)練成本下降
AI Infra(AI Infrastructure 人工智能基礎(chǔ)架構(gòu)技術(shù))主要涵蓋大模型訓(xùn)練和部署提供各種底層技術(shù)設(shè)施,包括處理器、操作系統(tǒng)、存儲系統(tǒng)、網(wǎng)絡(luò)基礎(chǔ)設(shè)施、云計算平臺等等,是模型訓(xùn)練背后極其關(guān)鍵的“保障技術(shù)”,這是大模型行業(yè)至今較少受到關(guān)注的硬技術(shù)領(lǐng)域。
李開復(fù)曾經(jīng)表示,“做過大模型 Infra 的人比做算法的人才更稀缺”,而超強(qiáng)的 Infra 能力是大模型研發(fā)的核心護(hù)城河之一。在芯片、GPU 等算力資源緊缺的當(dāng)下,安全和穩(wěn)定成為大模型訓(xùn)練的生命線。零一萬物的 Infra 技術(shù)通過“高精度”系統(tǒng)、彈性訓(xùn)和接力訓(xùn)等全棧式解決方案,確保訓(xùn)練高效、安全地進(jìn)行。
憑借其強(qiáng)大的 AI Infra 支撐,零一萬物團(tuán)隊表示,Yi-34B 模型訓(xùn)練成本實(shí)測下降 40%,實(shí)際訓(xùn)練完成達(dá)標(biāo)時間與預(yù)測的時間誤差不到一小時,進(jìn)一步模擬上到千億規(guī)模訓(xùn)練成本可下降多達(dá) 50%。截至目前,零一萬物 Infra 能力實(shí)現(xiàn)故障預(yù)測準(zhǔn)確率超過 90%,故障提前發(fā)現(xiàn)率達(dá)到 99.9%,不需要人工參與的故障自愈率超過 95%,有力保障了模型訓(xùn)練的順暢進(jìn)行。
零一萬物背后
今年 7 月,李開復(fù)博士正式官宣并上線了其籌組的“AI 2.0”新公司:零一萬物。此前李開復(fù)曾表示,AI 大語言模型是中國不能錯過的歷史機(jī)遇,零一萬物就是在今年 3 月下旬,由他親自帶隊孵化的新品牌。
在接受外媒采訪時,他談到了創(chuàng)辦零一萬物的動機(jī):“我認(rèn)為需求是創(chuàng)新之母,中國顯然存在巨大的需求,”“與其他國際地區(qū)不同,中國無法訪問 OpenAI 和谷歌,因?yàn)檫@兩家公司沒有在中國提供他們的產(chǎn)品。因此,我認(rèn)為有很多人正在努力為市場創(chuàng)造解決方案。這是剛需。”
眾所周知,構(gòu)建大模型是一項耗資巨大的事業(yè)。為了維持現(xiàn)金密集型業(yè)務(wù),零一萬物從一開始就制定了商業(yè)化計劃。雖然該公司將繼續(xù)開源其一些模型,但其目標(biāo)是構(gòu)建最先進(jìn)的專有模型,作為各種商業(yè)產(chǎn)品的基礎(chǔ)。
李開復(fù)表示,他們非常清楚這些大型語言模型需要大量計算,花費(fèi)巨大。“我們籌集到了大量資金,其中大部分都花在了 GPU 上。”與中國其他 LLM 玩家一樣,零一萬物也需要積極儲備 GPU 以應(yīng)對美國制裁。在發(fā)布會中,李開復(fù)表示零一萬物現(xiàn)在的供應(yīng)至少足以滿足未來 12-18 個月的需求。
美國的制裁也讓中國企業(yè)注重優(yōu)化計算能力,李開復(fù)表示:“借助一支非常高質(zhì)量的基礎(chǔ)設(shè)施團(tuán)隊,每 1000 個 GPU,我們也許能夠從中擠出 2000 個 GPU 的工作負(fù)載。”
從一些報道中,我們可以了解到,零一萬物員工規(guī)模已超過 100 人,半數(shù)是來自國內(nèi)外大廠的 LLM 專家。其中,零一萬物技術(shù)副總裁及 AI Alignment 負(fù)責(zé)人是 Google Bard/Assistant 早期核心成員,主導(dǎo)或參與了從 Bert、LaMDA 到大模型在多輪對話、個人助理、AI Agent 等多個方向的研究和工程落地;首席架構(gòu)師曾在 Google Brain 與 Jeff Dean、Samy Bengio 等合作,為 TensorFlow 的核心創(chuàng)始成員之一。
零一萬物的商業(yè)化之路很大程度上取決于其為其昂貴的 AI 模型找到適合的產(chǎn)品市場的能力。“中國在大模型方面并不領(lǐng)先于美國,但毫無疑問,中國可以構(gòu)建比美國開發(fā)商更好的應(yīng)用程序,這主要是因?yàn)檫^去 12 年左右建立的非凡的移動互聯(lián)網(wǎng)生態(tài)系統(tǒng),”李開復(fù)說道。
李開復(fù)表示,這家初創(chuàng)公司的最終目標(biāo)是成為一個外部開發(fā)人員可以輕松構(gòu)建應(yīng)用程序的生態(tài)系統(tǒng)。“我們的職責(zé)不僅僅是推出好的研究模型,更重要的是讓應(yīng)用程序開發(fā)變得容易,這樣才能有優(yōu)秀的應(yīng)用程序,”他說。“歸根結(jié)底。這是一場生態(tài)系統(tǒng)游戲。”
-
語言模型
+關(guān)注
關(guān)注
0文章
557瀏覽量
10591 -
OpenAI
+關(guān)注
關(guān)注
9文章
1196瀏覽量
8227 -
大模型
+關(guān)注
關(guān)注
2文章
2941瀏覽量
3681
原文標(biāo)題:李開復(fù)4個多月后“放大招”:對標(biāo)OpenAI、谷歌,發(fā)布“全球最強(qiáng)”開源大模型
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
OpenAI發(fā)布o1大模型,數(shù)理化水平比肩人類博士,國產(chǎn)云端推理芯片的新藍(lán)海?
上新:小米首個推理大模型開源 馬斯克:下周推出Grok 3.5
低至¥2.27/h!就能使用全球最強(qiáng)開元模型——千問 QwQ-32B






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論