 瘋狂的H100:現代GPU體系結構淺析,從算力焦慮開始聊起
瘋狂的H100:現代GPU體系結構淺析,從算力焦慮開始聊起
得益于 ChatGPT 引發的新一波 AI 浪潮,2023 年各大科技公司大量采購 NVIDIA 生產的 H100 等系列 GPU。據 NVIDIA 2024 財年第二季度財報[1],NVIDIA 收入創下紀錄新高,達到 135.07 億美元,遠超分析師給出 110.4 億美元預期。目前市場上對 H100 的需求在 43.2 萬張左右,每張售價約 3.5 萬美元,受限于臺積電的產能,2023 年 NVIDIA H100 的產量早已銷售一空,目前 GPU 的短缺或將持續到 2024 年[2]。
在 eBay 上,一張 NVIDIA H100 SXM 80GB 的 GPU 售價目前 (2023.10) 已經被炒到了 4.5 萬美元[3]。于此同時,估值僅 20 億美元的 CoreWeave 以 NVIDIA H100 為抵押,卻拿到了 23 億美元的債務融資[4]。要知道,CoreWeave 手上目前并沒有這么多的等價 NVIDIA H100,它有的僅僅只是 NVIDIA 的 H100 供貨承諾。仿佛過去二十年國內狂飆的土地財政一般,房地產商通過土地拍賣拿到的土地,又可以快速抵押拿到銀行的貸款,NVIDIA H100 在當下也成為了如土地一般的硬通貨。 本文嘗試深入到硬件,從英偉達 H100 系列 GPU 入手,解析現代 GPU 體系結構,試圖去理解在大模型繼續狂飆的當下,為何賣的如此之貴的 H100 還能夠賣的這么好。
01.TLDR
本文所有的資料來自于互聯網公開信息,更多是從程序員的角度去理解現代 GPU 的體系結構,強烈推薦大家閱讀本文附錄的原始資料,文中的觀點與本人雇主無關。
除了以 H100 為代表的英偉達 GPU,市場上同場競爭的還有很多其他類型的 GPU:比如來自 AMD、Intel 的 GPU,以華為昇騰 910 AI 加速芯片,Google 的 TPU,AWS 自研 Tranium 和 Inferentia,乃至來自壁仞等創業公司的 GPU 等。因為工作中主要使用的是英偉達的 GPU,本文目光也主要集中在英偉達的 H100。
隨著時代的發展,最早源于圖形渲染領域的 GPU,不斷在 HPC、圖形學和深度學習這三個領域游走,前幾年還在加密貨幣中發揮了重要作用。本文不太會詳細介紹其圖形渲染方向的能力,更多側重于像計算側能力的演進與發展。受限于篇幅,本文暫時不會涉及 MIG 和機密計算等新特性,也不太介紹 NVLink 等通信能力。
作為一名軟件工程師,本文作者對于硬件的理解也并不算深刻與全面,甚至可能會存在偏差與錯誤,在介紹相關方向的時候也肯定會存在遺漏,歡迎大家交流與指正。
本文相對較長,全文超過 10000 字,閱讀預計需要 20 分鐘左右。
在真正開始之前,這里先簡單介紹下本文可能會碰到的技術縮略語,現在不需要深刻理解其含義,只需要有初步印象即可。
| FLOPS | Floating point Operations per Second | FLOPS 為每秒浮點數運算次數,FLOPs 則表示浮點運算次數 |
| DGX | Deep-learning GPU Accelerator | NVIDIA 推出的一系列專門用于加速深度學習工作負載的高性能計算平臺 |
| HGX | High-Performance GPU Accelerator | NVIDIA 推出的服務器參照平臺。OEM 廠商用于構建 4 GPU 或 8 GPU 服務器,由 Supermicro 等第三方 OEM 制造 |
| SXM[6] | Server PCI Express Module | NVIDIA 用于連接 GPU 的高帶寬 socket 接口,相比 PCIe 具有高帶寬、低延遲、高拓展性、直接互聯等特點 |
| HBM | High Bandwidth Memory | 一種先進的內存技術,相對于 GDDR 等具有高帶寬、低功耗、封裝緊湊等特點 |
| CoWoS[7] | Chip on wafer on Substrate | 三維堆疊,相對于 GDDR 等具有高帶寬、低功耗、封裝緊湊等特點 |
| GPC | Graphics Processor Cluster | 圖形處理集群,每個 GPC 包含若干個 TPC |
| TPC | Texture Processor Cluster | 紋理處理集群,每個 TPC 包含若干個 SM |
| SM | Streaming MultiProcessor | NVIDIA GPU 架構中的核心計算單元,負責執行并行計算任務 |
| SIMT | Single Instruction Multiple Thread | 單指令多線程,NVIDIA GPU 中的一種并行計算模型,將 SIMD 和多線程結合起來,使得多個線程可以同時執行相同的指令,但是處理不同的數據 |
| GEMM | General Matrix Multiplication | 通用矩陣乘,是一種廣泛用于深度學習神經網絡模型的計算操作 |
| MMA | Matrix Multiply-Accumulate | 矩陣乘加 |
| FMA | Fused Multiply-Accumulate | 融合矩陣乘加,通過單個指令實現矩陣乘加 |
| TMA | Tensor Memory Accelerator | 張量內存加速器 |
| MIG | Multi-Instance GPU | 多實例 GPU |
| TEE | Trusted Execution Environments | 可信執行環境 |
| SHARP | Scalable Hierarchical Aggregation and Reduction Protocol | 可擴展分層次聚合和歸約協議,NVIDIA 推出的一種高性能集合通信協議,將聚合操作卸載到交換機,消除多次傳輸數據的需要 |
| DSA | Domain Specific Architecture | 領域專用架構,是一種針對特定應用場景進行優化的芯片架構,旨在提高芯片的性能和效率 |
| 英文 | 縮寫 | 中文釋義 |
03.算力需求膨脹,大模型訓練需要多少卡
昂貴 H100 的一時洛陽紙貴,供不應求,大模型訓練究竟需要多少張卡呢?GPT-4 很有可能是在 10000 到 20000 張 A100 的基礎上訓練完成的[8]。按照 Elon Musk 的說法,GPT-5 的訓練可能需要 3 萬到 5 萬張 H100,盡管之后被 Sam Altman 否認,也可窺見大模型訓練對于算力的巨大需求。 Inflection 公司宣布他們正在構建世界上最大的 AI 集群,包含 22000 張 NVIDIA H100,FP16 算力可以達到 22 exaFLOPS,如果更低精度的算力(也就是 FP8)得到使用,則可以獲得更高算力 [9]。這是一個非常驚人的數字,要知道 Frontier 超級計算機是目前唯一達到 ExaFLOPS 算力量級的超級計算機。對比目前排名第七的神威太湖之光超級計算機,最大算力也只有 94.64 PetaFlOPS。Inflection 自豪地宣稱,如果參與超級計算機 Top 500 排行[10],他們可以很輕松地排到第二名,并且逼近排名第一的 Frontier 超級計算機。
The deployment of 22,000 NVIDIA H100 GPUs in one cluster is truly unprecedented, and will support training and deployment of a new generation of large-scale AI models. Combined, the cluster develops a staggering 22 exaFLOPS in the 16-bit precision mode, and even more if lower precision is utilized. [9]
Inflection 基于超過 3500 張 NVIDIA H100 實現了在 C4 數據集下僅用了不到 11 分鐘,即訓練完 GPT-3 的模型[11]。對比 OpenAI 在 2020 年時使用數千張 NVIDIA V100 訓練 GPT-3,花了一個月左右的時間,對比 V100,H100 算力顯著增長。這里截圖不全,只大致反映當前參與 Benchmark 的廠商與系統[12]。
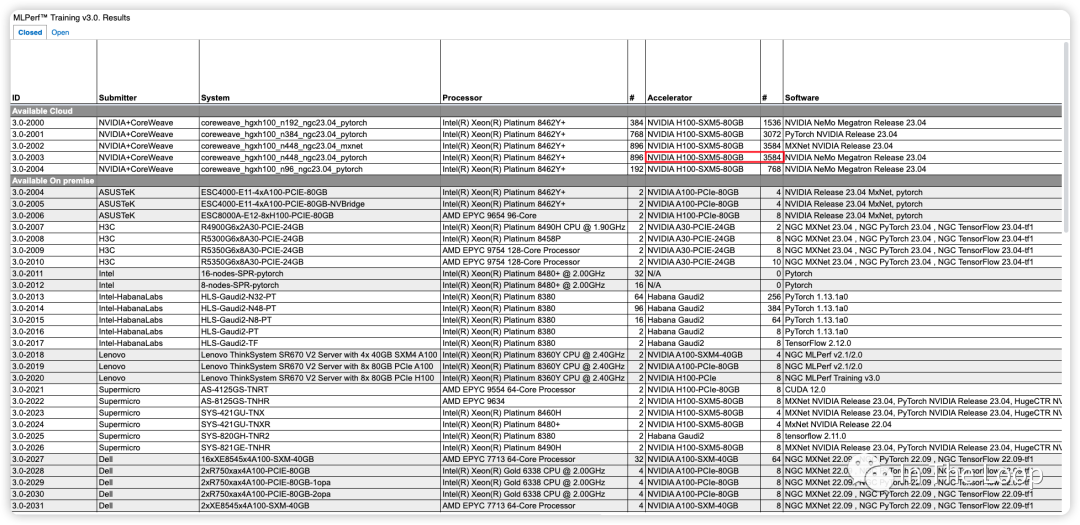
22000 張 NVIDIA H100 構成的 AI 集群,微軟和英偉達投資給 Inflection 的 13 億美元也許就要花去大半了。這一幕令人驚奇,也許存在泡沫,但真金白銀不會騙人,我們也好好算算為什么需要這么多卡。OpenAI 早在 2020 年的 Scaling Laws[13] 論文中給我們提出了一個經驗公式:
這里面:
C是訓練一個 Transformer 模型所需要的算力,單位是 FLOPs
P是一個 Transformer 模型中參數的數量
D是訓練數據集的大小,也就是用多少 tokens 來訓練
π是指訓練集群中所有硬件總的算力吞吐,單位是 FLOPs,計算方法為
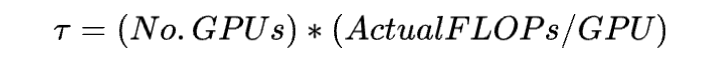
T是指訓練這個模型需要的時間,單位是 seconds
Scaling Law 論文 Section 2.1 對于這個公式的做了簡單的推導,在 forward pass需要的 FLOPs 數為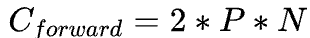 ,在 backward pass 需要的 FLOPs 數大致是 forward pass 的 2 倍,因此
,在 backward pass 需要的 FLOPs 數大致是 forward pass 的 2 倍,因此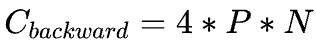 ,這即是系數 6 的來源。 ? 之所以有這樣簡潔的公式,是因為無論是 bias vector addition,layer normalization,residual connections, non-linearities,還是 softmax,甚至是 attention 的計算都不是占算力的主要因素,最關鍵的還是 Transformer 中的矩陣運算。
,這即是系數 6 的來源。 ? 之所以有這樣簡潔的公式,是因為無論是 bias vector addition,layer normalization,residual connections, non-linearities,還是 softmax,甚至是 attention 的計算都不是占算力的主要因素,最關鍵的還是 Transformer 中的矩陣運算。
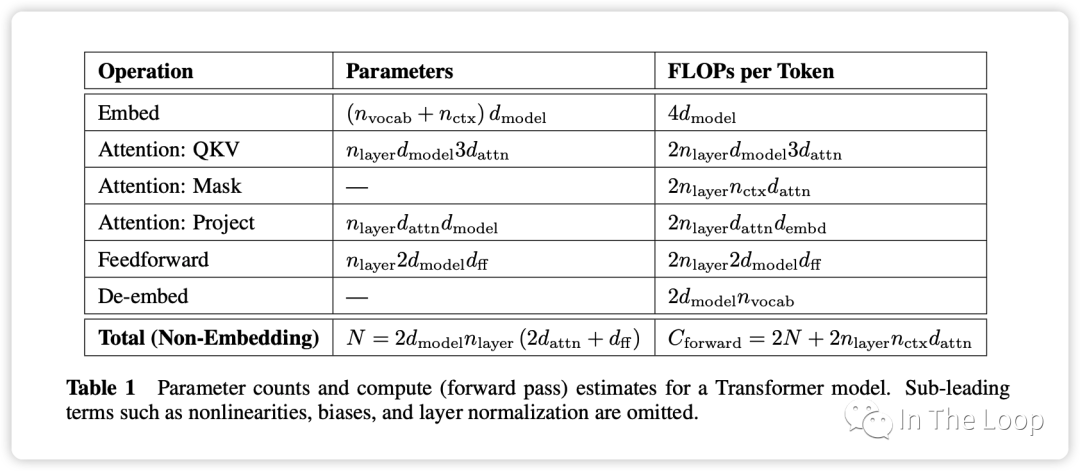
Parameter counts and compute (forward pass) for a transformer model, Source: Scaling Law Paper 記住上面的假設之后,我們就可以簡單地算出這里的系數 6 了,前向 2 次,反向 4 次,如下圖所示。
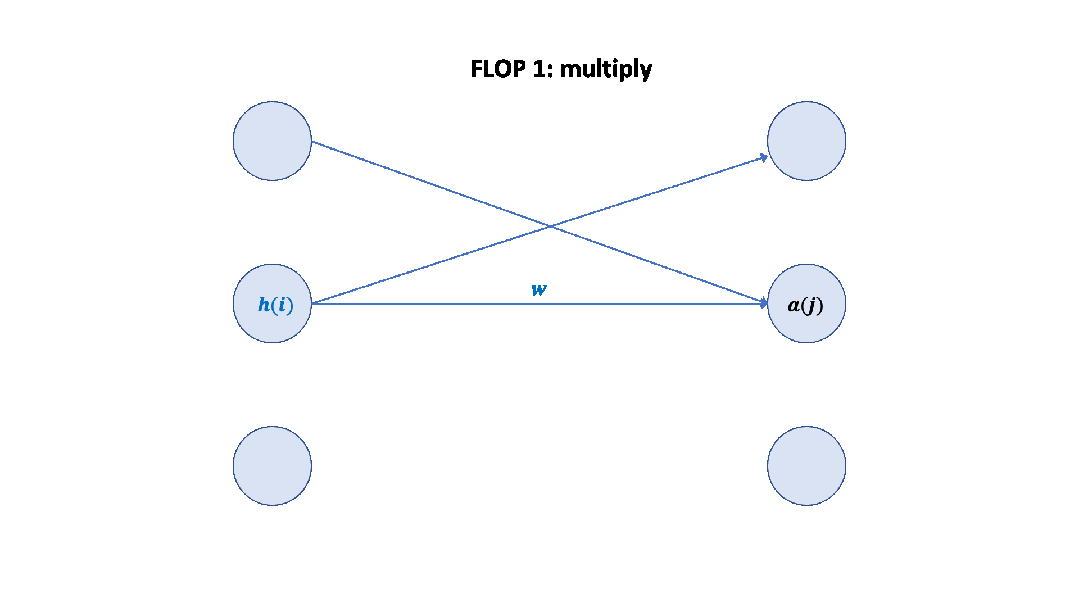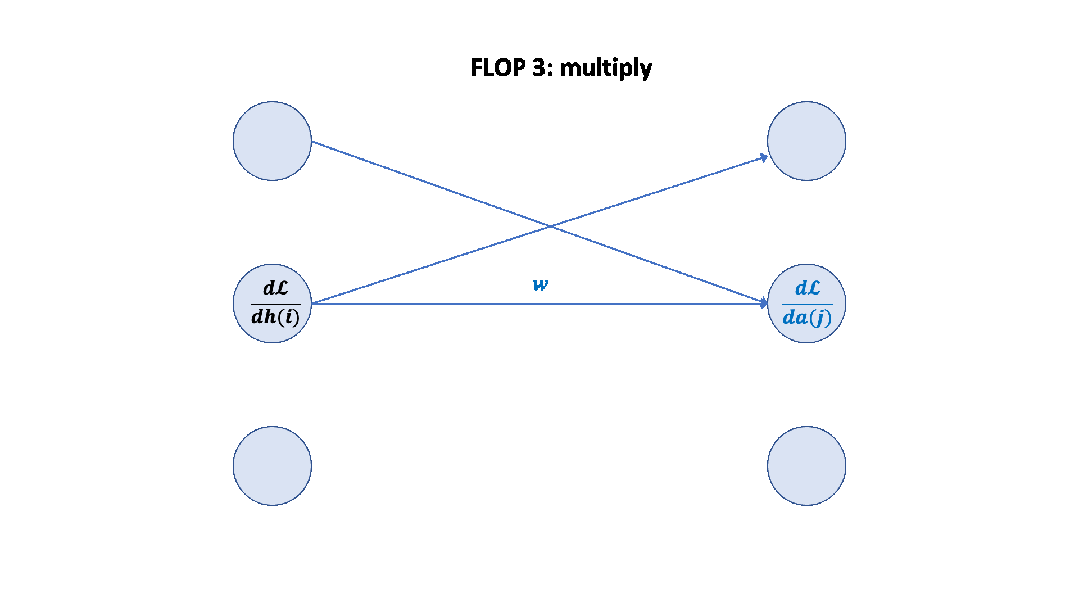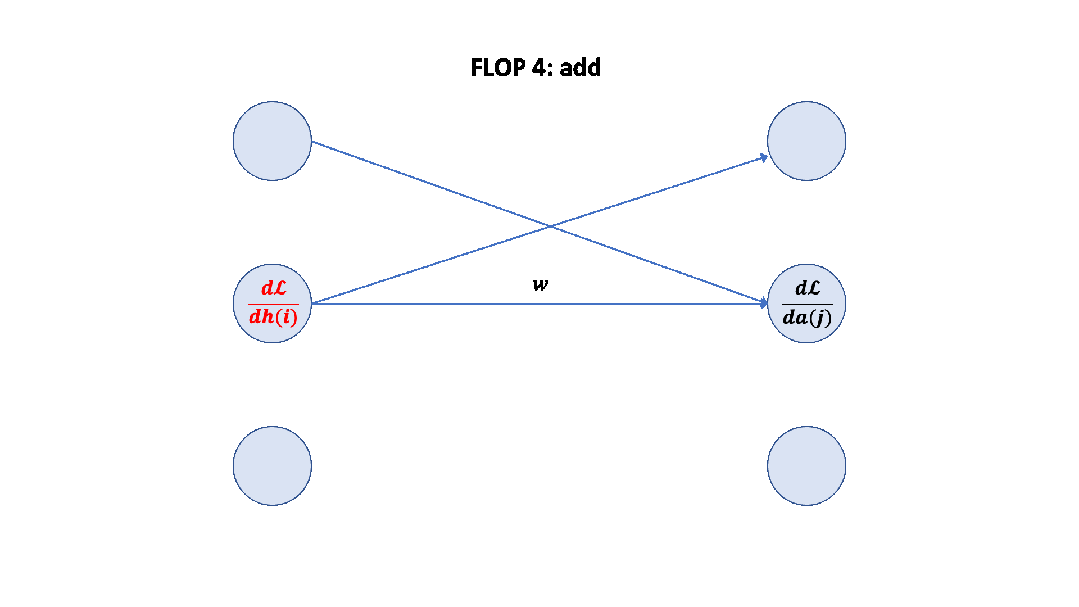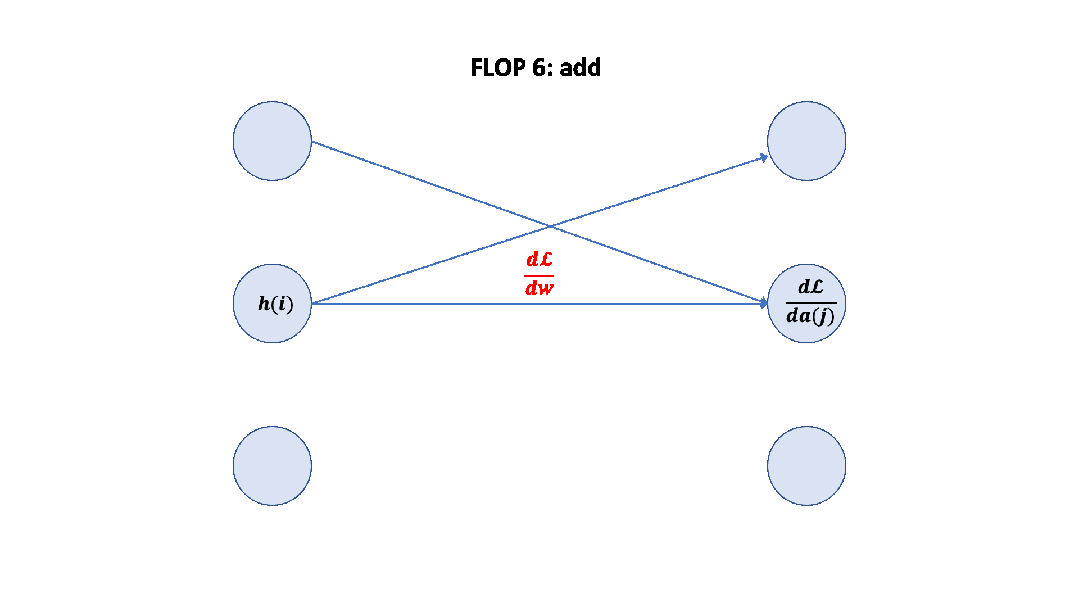
至此,基于上面的假設,我們已經推導出了經驗經驗公式中 6 的來源,至于為什么這個假設是正確的,可以參考 Scaling Law 的論文或者這篇文章[14]。
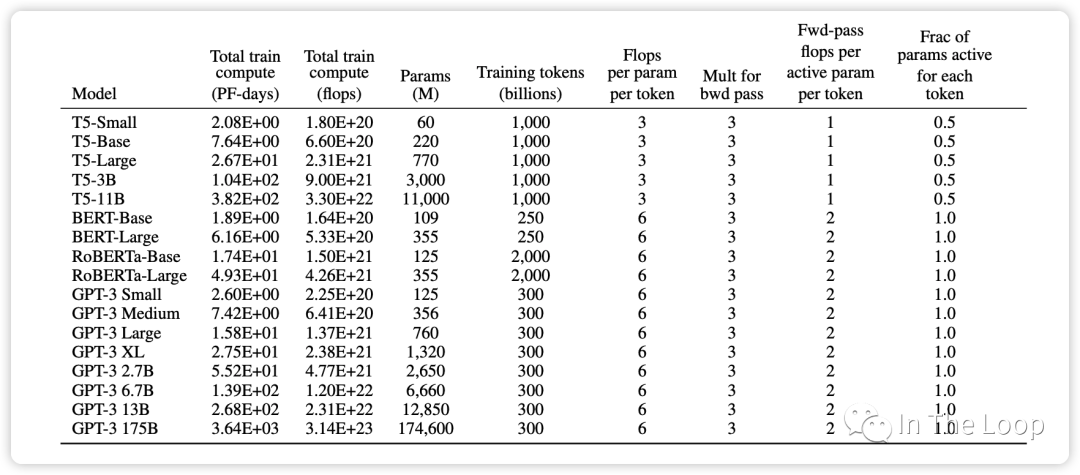
這個經驗公式在 GPT-3 的論文中也再次得到了驗證,可以看到對于 GPT-3 這種 decoder-only 結構的 transformer 模型,每個參數每個 token 所需要的 FLOPs 即為 6。而對于 T5 這種 encoder-decoder 結構的 transformer 模型,在 forward pass 和 backward pass,因為對每個 token 只有一半的參數是 active 的,因此這個經驗公式里面的系數為 3。
在計算所需算力的時候,我們剛才都是使用 FLOPS 這個單位,也就是 FLOP-seconds,Scaling Laws 論文中傾向于使用 PetaFLOP-days 的單位,這樣能夠更加直觀的感受出訓練一個模型需要多長時間。以 Meta 年初開源的 LLaMA-1 為例,65B 的模型基于 1.4T 的 tokens 訓練,使用了 2048 塊 NVIDIA A100 GPU,那么需要訓練多久呢?
所需算力
NVIDIA A100 WhitePaper 中給出 BF16 Tensor Core 的算力為 312 TFLOPS[15],但是實際上算力一般在 130 到 180 TFLOPS 中間,這里我們取中間值 150 TFLOPS[16]
根據實際算力計算集群算力吞吐為
訓練 LLaMA-1 所需耗時為
這一計算和 LLaMA-1 在論文中實際訓練時間基本一致:
When training a 65B-parameter model, our code processes around 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM. This means that training over our dataset containing 1.4T tokens takes approximately 21 days.
LLM Training Cost, Source: https://karpathy.ai/stateofgpt.pdf
進一步計算,NVIDIA H100 WhitePaper 上給出 BF16 1979 TFLOPS,因為這個指標包含了 sparsity,實際稠密算力大約在 1000 TFLOPS[17]。對比 A100,差不多有 3 倍的增長,那么同樣數目的 GPU,不考慮其他因素做最粗糙的計算,LLaMA-1 65B 的訓練時長差不多可以減少到 10 天以下[18]。考慮到 H100 新推出的 FP8 Tensor Core 3,958 TFLOPS 的算力,以及新一代 NVLink Network 的通信帶寬,訓練速度可以進一步加快,GPT-3 175B 訓練可以相比 A100 可以快 6 倍多。
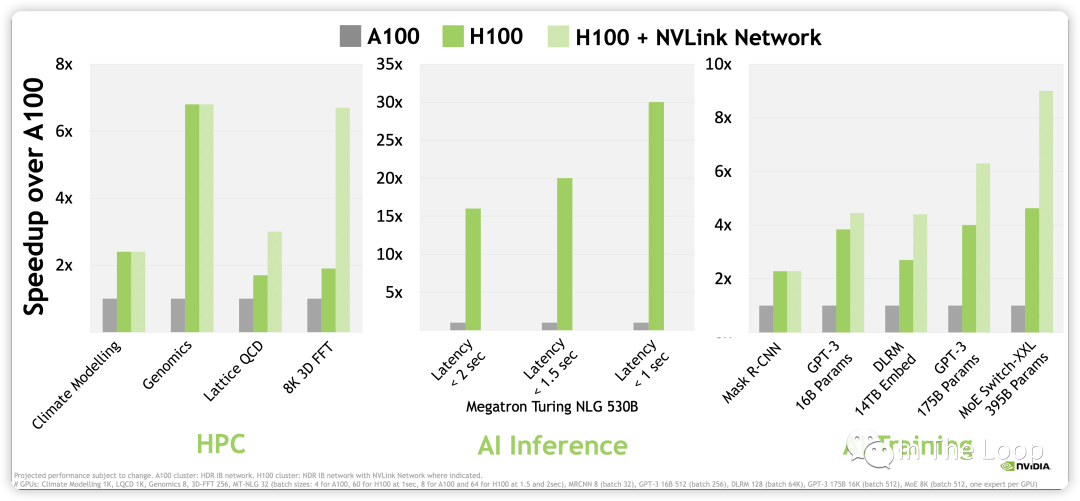
NVIDIA H100 vs A100 Performance, Source: NVIDIA WhitePaper
除了性能上相對于 A100 有明顯優勢,H100 在成本上也優于 A100。雖然 H100 在單位成本上是 A100 的 1.5 到 2 倍,但是效率上是 A100 的 3 倍,因此 H100 的每美元性能要比 A100 要更高。這就是老黃說的 「The More You Buy,The More You Save」,NVIDIA 贏麻了 。

Estimated times and cost for a 7B model on 8x NVIDIA H100 vs. 8x NVIDIA A100, Source: MosaicML
通過上面的計算,我們可以看到 LLM 訓練對于 GPU 提出的巨大需求,也看到了 H100 相對于 A100 的巨大優勢,這也是為何目前 H100 供不應求的原因之一。接下來,本文會嘗試深入到 H100 硬件,看看 H100 比 A100 到底好在哪里。
04.H100 系列產品線長什么模樣
NVIDIA 的產品線比較復雜,包括了數據中心,到專業工作站,以及消費級 GPU 和嵌入式等不同場景,其系列產品名稱也比較復雜,你可以在這里[19]看到。
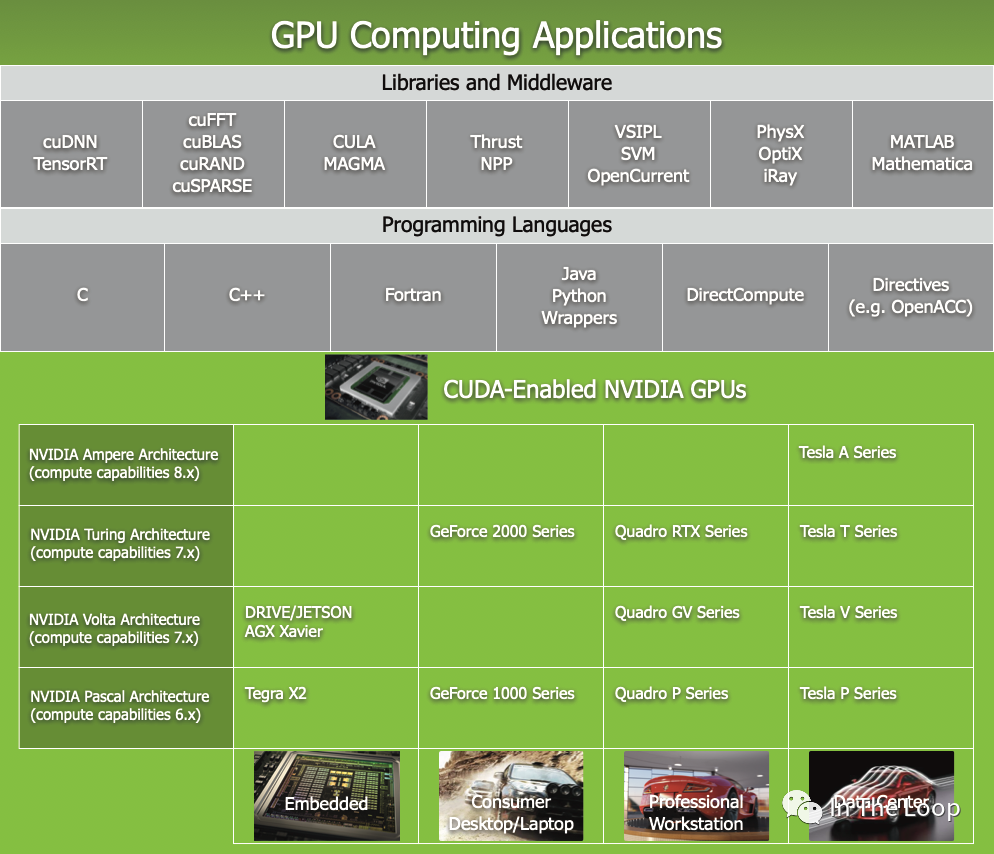
本文主要關注數據中心 H100 的系列產品線,在深入到具體硬件體系結構之前,我們先看看 NVIDIA 基于 H100 的系列產品線模樣,對 HGX 和 DGX 先有一個粗略的印象。
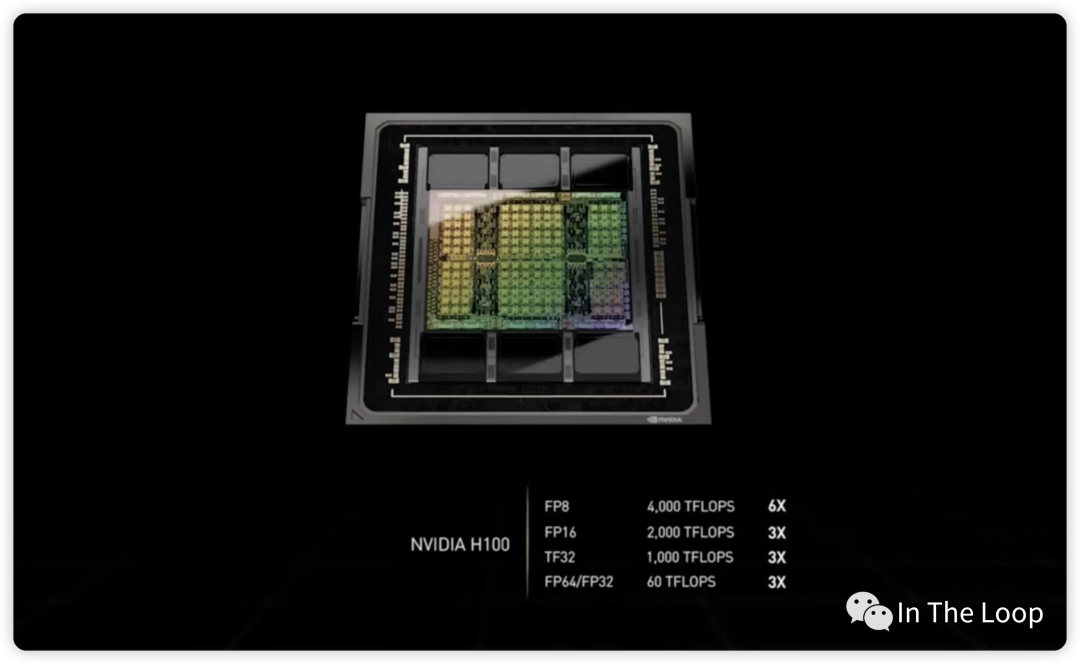
這個是 H100 GPU 芯片,包含 HBM3 高速顯存,通過臺積電的 CoWoS 技術封裝在一起
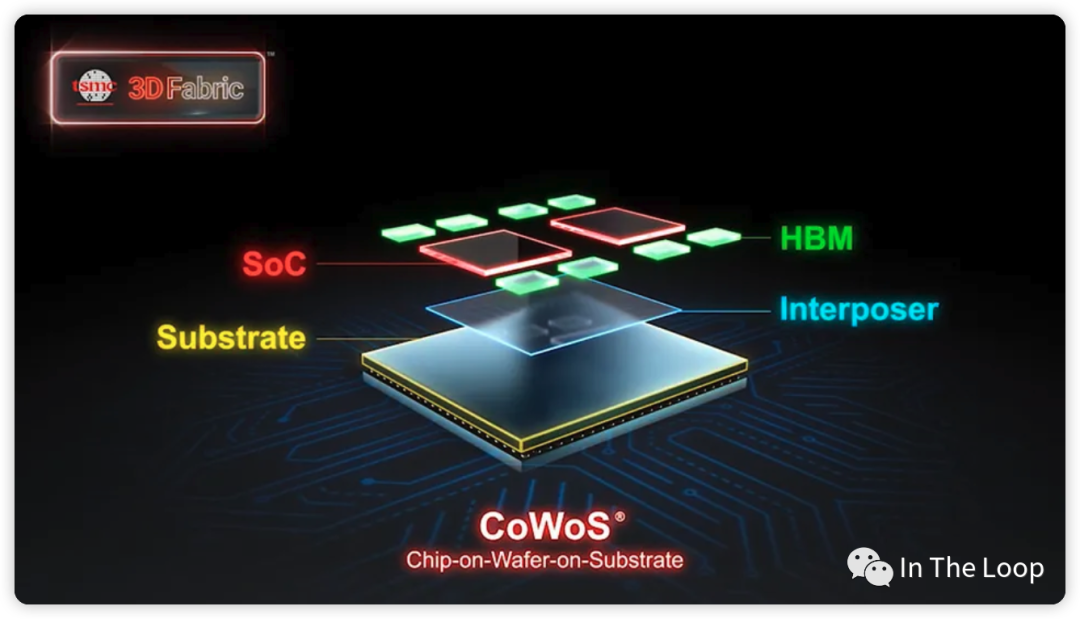
臺積電的 CoWoS 技術大概是這樣,Credit: TSMC

這是 H100 GPU 封裝在 SXM5 模塊中

NVIDIA HGX H100,由8個H100 SXM5 模塊加上4個NVSwitch Chip 在同一個 system board 上
值得注意的是,這 4 個 NVSwitch Gen3 芯片總共具有 3.6 TFLOPS 的 SHARP In-Network Computing 計算能力,此處暫時不表,后面再寫篇文章聊聊 SHARP。

DGX H100 在 HGX 100 的基礎上,進一步配置了 CPU、存儲與網卡

進一步 ScaleUp DXG H100,將32個 DGX 聚合到一起,形成 DGX H100 SuperPod

上個月 NVIDIA 又發布了 GH200,實際上就是 Grace CPU 加上 Hopper GPU
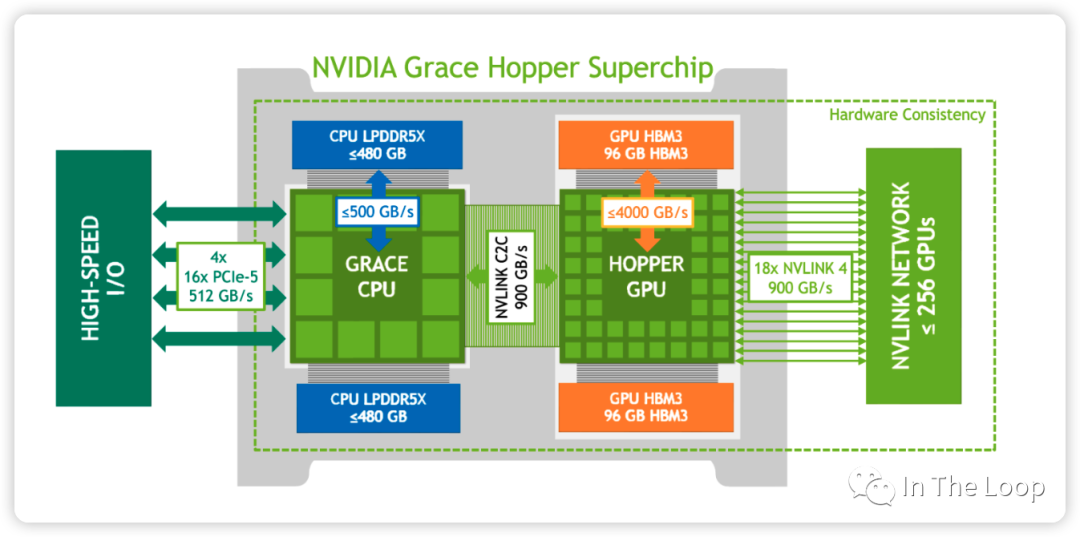
這是他們之間的邏輯鏈路
05.CUDA 編程模型與 H100 體系結構
本節將會結合 NVIDIA CUDA 的編程模型,對照分析 H100 GPU 體系結構。如下圖所示,滿配的 GH100 有 8 個 GPC,每個 GPC 有 9 個 TPC,每個 TPC 內有 2 個 SM,總共有 144 個 SM。基于 SXM5 的 H100 砍掉了 6 個 TPC,只有 66 個 TPC,總計 132 個 SM。
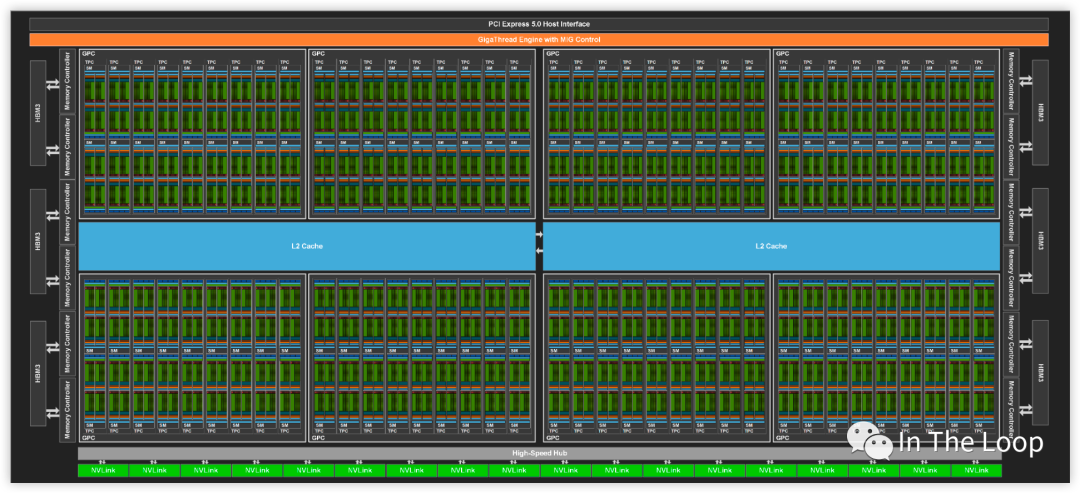
H100 支持第四代 NVLink 和 PCIe Gen5,支持 6 個 HBM3 Stacks,DRAM 帶寬達到 3TB/s,L2 Cache 到 50MB。
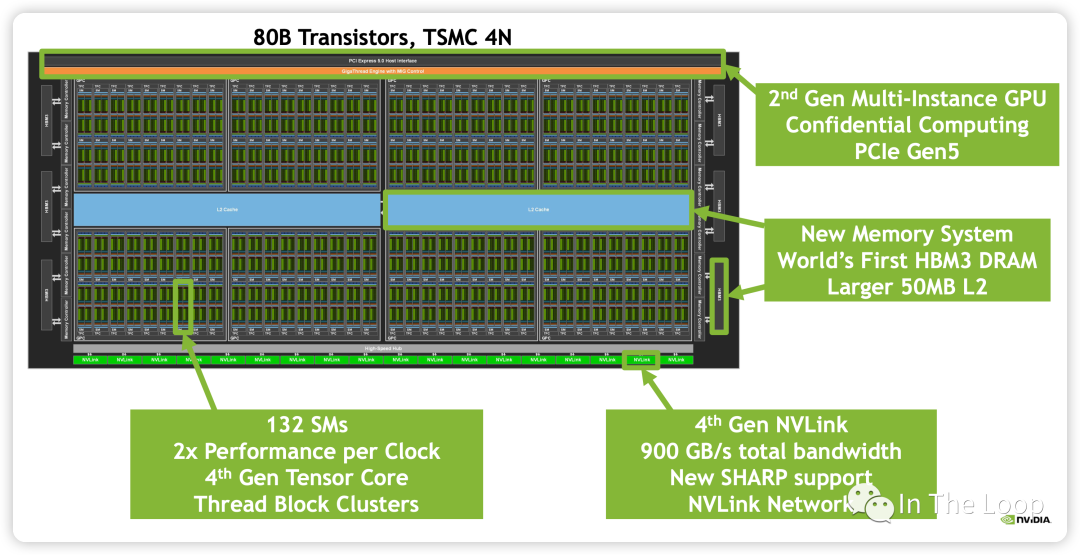
繼續放大每一個 SM,查看其中組成:
| Computing | CUDA Core FP32 Unit | 128,分成四組,每組 32 個 |
| Computing | CUDA Core FP64 Unit | 64,分成四組,每組 16 個 |
| Computing | CUDA Core INT32 Unit | 64,分成四組,每組 16 個 |
| Computing | TensorCore Gen4 | 4,分成四組,每組 1 個 |
| Computing | SFU | 4,分成四組,每組 1 個 |
| Computing | Tex | 4,分成四組,每組 1 個 |
| Scheduling | WARP Scheduler | 4,分成四組,每組 1 個,32 thread/clk |
| Scheduling | Dispatch Unit | 4,分成四組,每組 1 個,32 thread/clk |
| Storage | Register File | 256KB,分成四組,每組 64 KB |
| Storage | L0 Instruction Cache | -- |
| Storage | L1 Data Cache/Shared Memory | 256KB |
| Storage | L1 Instruction Cache | -- |
| Storage | LD/ST | 32,分成四組,每組 8 個 |
| Storage+Computing | Tensor Memory Accelerator | 1 |
| Functions in SM | Component Name | Unit per SM |
包含 128 個 CUDA Core,分為 4 組,每組包含 16 個 FP64 Unit,16 個 INT32 Unit 和 32 個 FP32 Unit,這些 CUDA Core 單元可以用于超算、圖形渲染等場景的計算。
包含第四代 Tensor Core,此處暫時略過,在 Tensor Core 那節會詳細介紹。
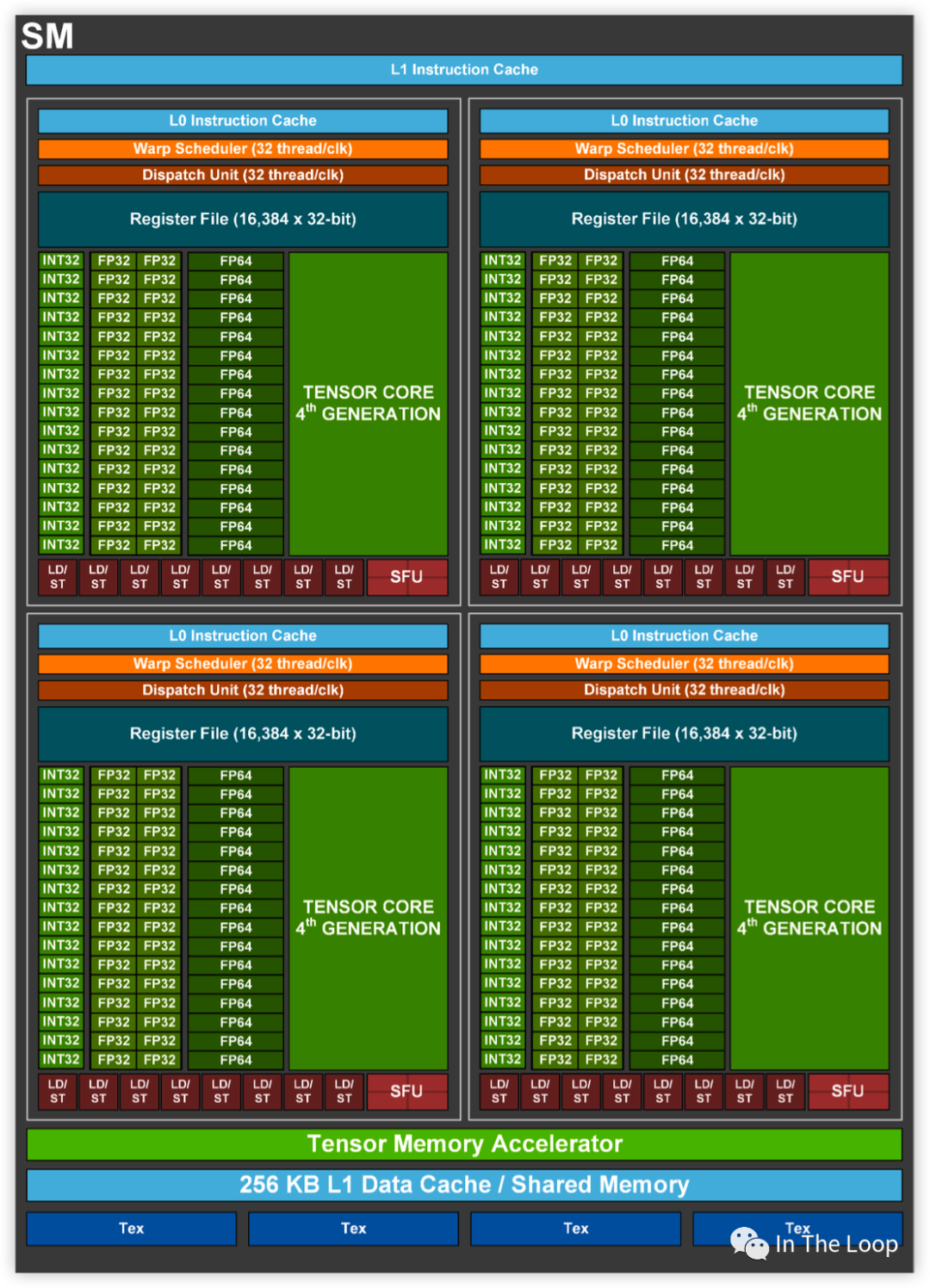
密集恐懼癥者看到 SM 這密密麻麻的計算核心或許會有點害怕,為了更好的理解 NVIDIA GPU 的結構,我們看可以看下面的簡化版本:
對于每一個 GPU,通過 GPC 和 TPC 的層級可以劃分為很多的 SM
SM 進一步可以劃分為 4 組,每組都有自己的 64KB Register File 和很多的計算核心,
同一個 SM 中所有運行的 thread 共享 256KB 的 Shared Memory 和 L1 Data Cache
同一個 GPU 內的所有 SM 共享 50MB L2 Cache 和 80GB HBM3 Memory
進一步向外看,同一個節點上的 GPU 通過 NVLink/NVSwitch 連接在一起
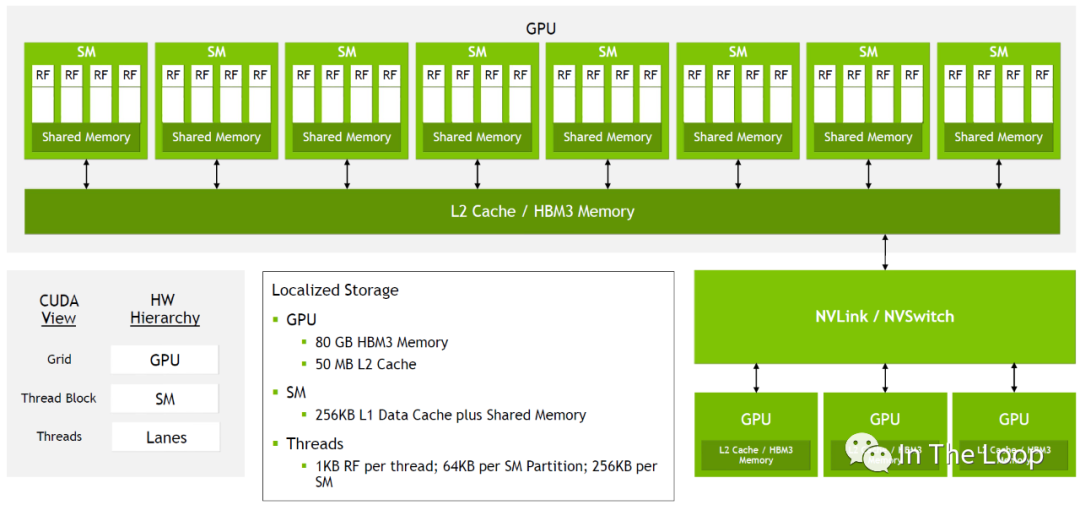
簡化的 H100 結構
這張圖里面我們已經看到了對應于硬件,從軟件層面 CUDA 編程模型中的視角,我們進一步介紹 CUDA 編程模型。在 CUDA 編程模型中,CPU 和主存被稱為 Host,GPU 和顯存被稱為 Device。CUDA 程序中既包含 Host 程序,又包含 Device 程序,它們分別在 CPU 和 GPU 上運行。
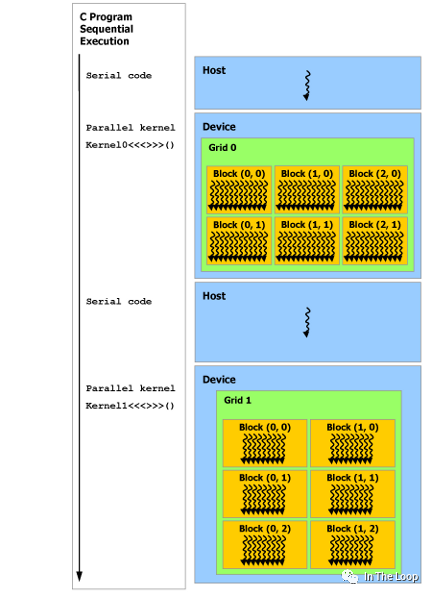
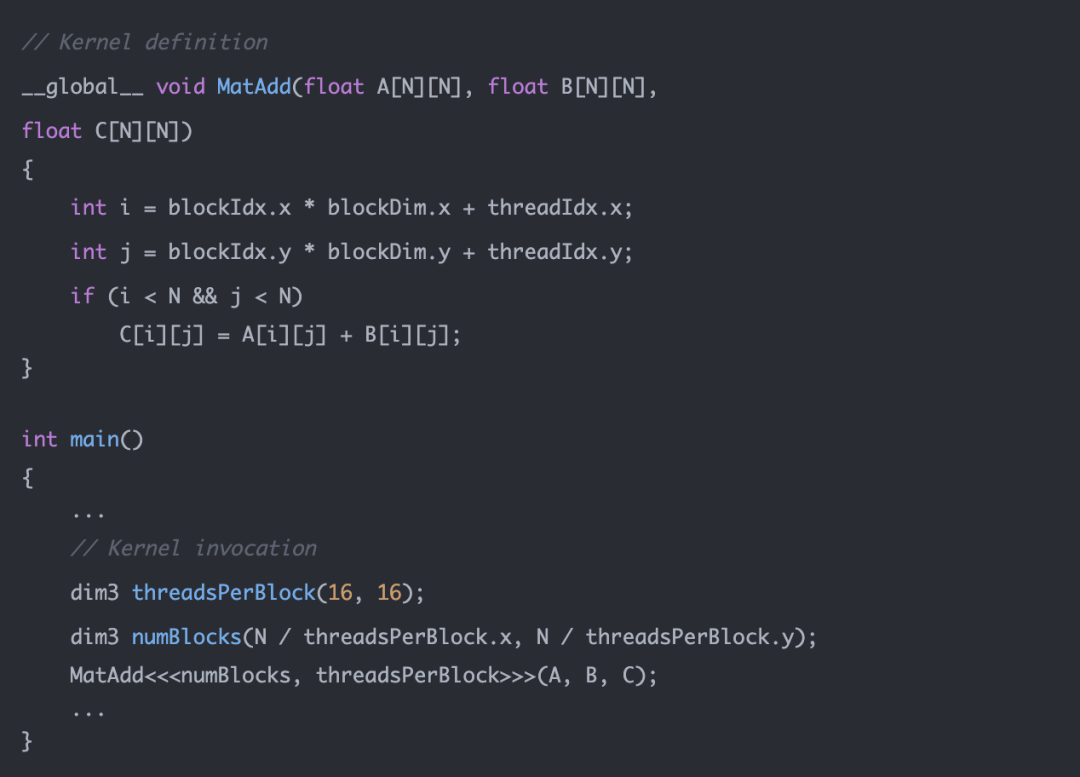
為了實現 GPU 并行加速計算,我們需要在 Host 上執行 kernel launch,讓核函數在 Device 上的多個線程并發執行。CUDA 將核函數所定義的運算稱為線程(Thread),多個線程組成一個塊(Block),多個塊組成網格(Grid)。具體的方式就是在調用核函數的時候通過 <<
為了進一步理解這里的 CUDA 編程模型概念與硬件結構,我們繼續聊聊剛才沒有提到的 WARP Scheduler。NVIDIA SM 采用 SIMT 架構[21],線程束 warp 是最基本的執行和調度單元,一個 warp 一般包含 32 threads,這些 threads 以不同的數據資源執行相同的指令。
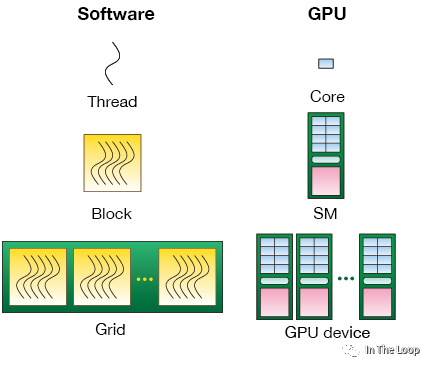
| thread | 最小的計算單元,每個 thread 擁有自己的程序計數器和狀態寄存器 | 對應于 Core, or lanes |
| warp | 最小的執行和調度單元,一個 SM 的 CUDA Core 會分組成幾個 warp | Warp Scheduler 一次調度一個 warp |
| block | 一個 block 中的 warp 只能在同一個 SM 調度 | 對應于 SM,一個 warp 中的 threads 必然在同一個 block |
| grid | 一個 GPU | 對應于 GPU |
| CUDA 視角 | 功能 | 硬件視角 |
雖然 warp 中的線程執行同一程序地址,但可能具有不同的行為,比如分支結構,因為 GPU 規定 warp 中所有線程在同一周期執行相同的指令,warp 發散會導致性能下降。一個 SM 同時并發的 warp 是有限的,因為資源限制,SM 要為每個線程塊分配共享內存,而也要為每個線程束中的線程分配獨立的寄存器,所以 SM 的配置會影響其所支持的線程塊和 warp 并發數量。
同一個 block 的 warp 只能在同一個 SM 調度運行,但是同一個 SM 可以容納來自不同 block 的多個 warp。主流的架構中每個 SM 最大 2048 個 threads,也就是最多 64 個 warps。一個 SM 有 4 組 warp scheduler,哪個 warp ready 了就調度哪個。一般 warp 可能因為在等內存搬運、等計算 core 或者等 sync 之類的而沒有 ready。warp 調度上了之后,就可以走到 dispatch unit。
到現在為止,前面介紹的 CUDA 編程模型實際上都是在 Hopper 架構以前的抽象,也就是 grid/block 兩級調度,block 映射到 SM 上。隨著 Cooperative Groups 的引入和異步編程的支持,多個 Kernel 之間以生產者和消費者的方式通信,SM 到 SM 之間的通信帶寬也在增加。
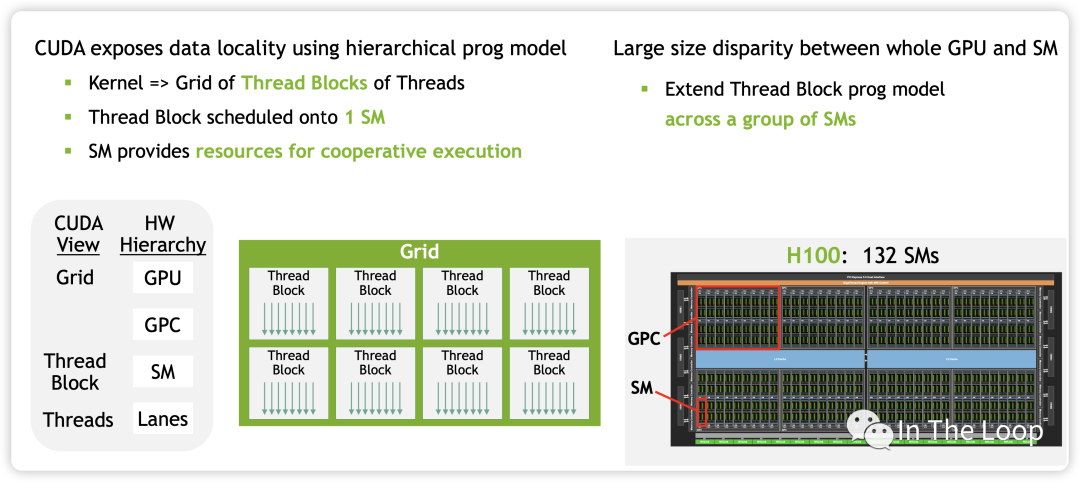
在 Hopper 架構中,新增了 Distributed Shared Memory (DSMEM) 的概念,在一個 GPC 內部的 SM 有了專用的通信帶寬,因此 CUDA 上新增了一層 Cluster 的調度層次。
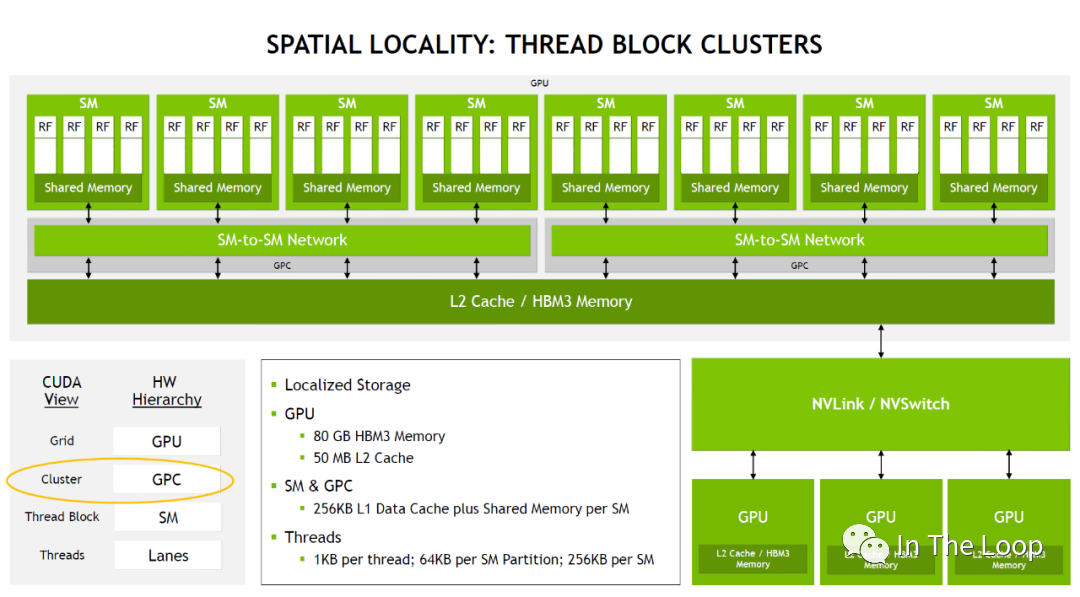
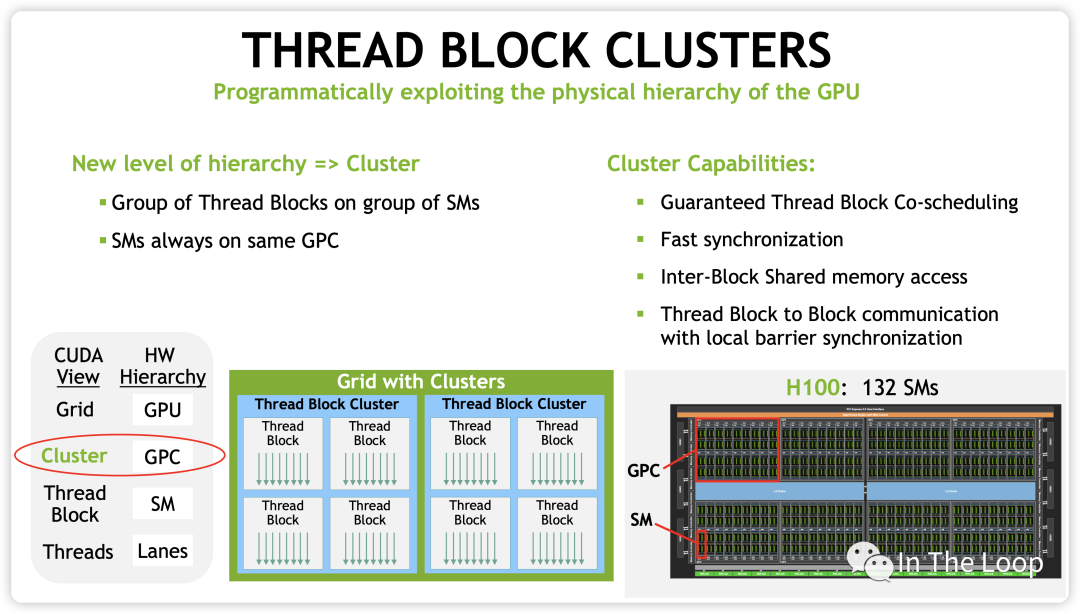
有了 cluster 這一層抽象之后,類似于同一個 block 的 threads 都會被調度到同一個 SM,同一個 cluster 的 thread blocks 都會被調度到同一個 GPC 中。
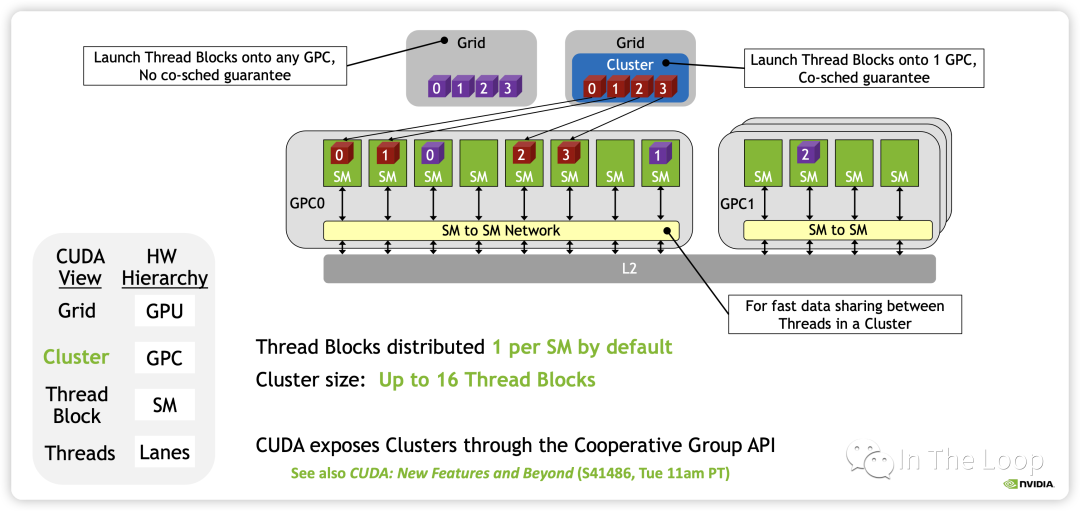
這樣同一個 cluster 中不同 block 的 threads 可以通過 SM to SM Network 訪問另一個 block 的 DSMEM。這樣在一個 GPC 內部實現多個 SM 的 LD/ST,Atomic,Reduce 和異步 DMA 操作都變得非常的簡潔。
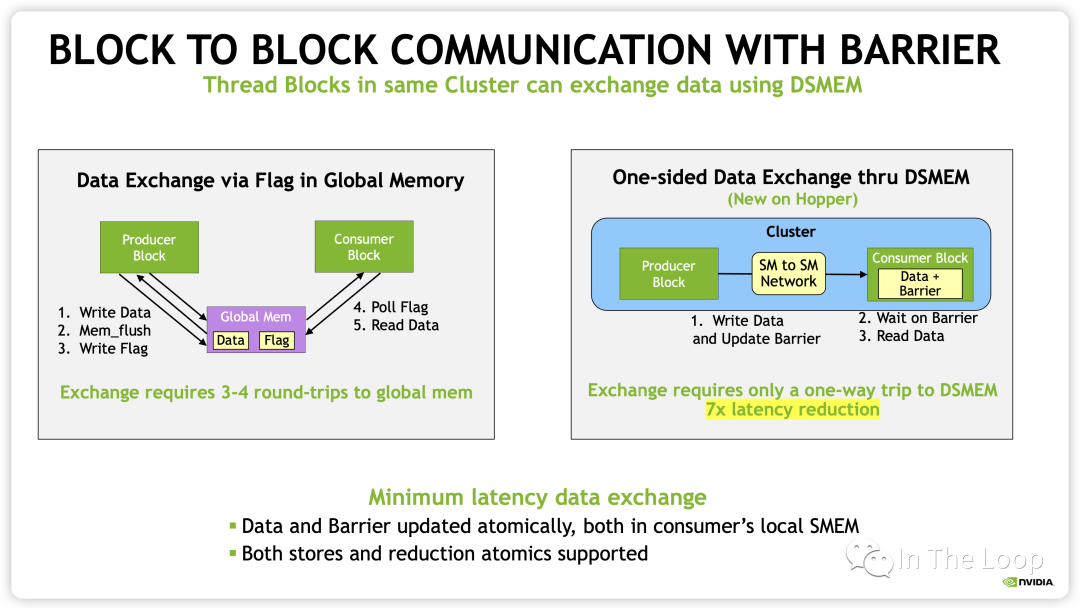
從 CUDA 編程模型的內存模型也就變成了下圖所示:
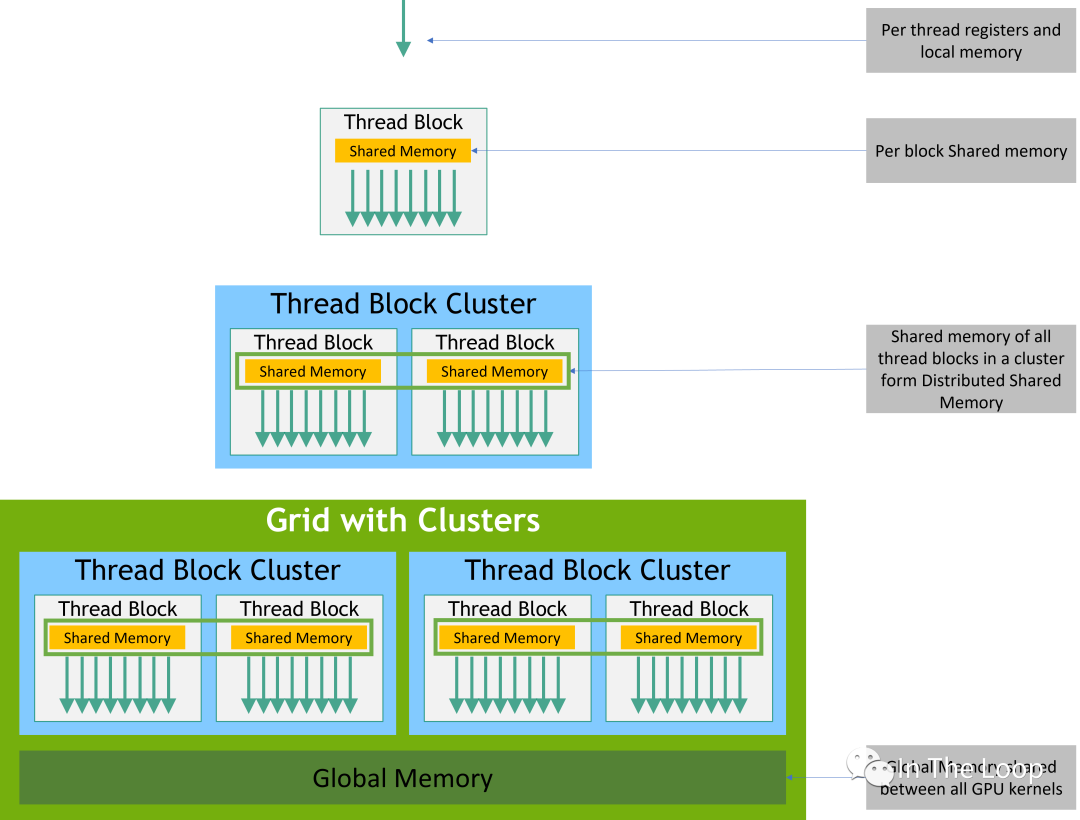
本質上看,CUDA 引入 block 和 cluster 的抽象,都是為了更好地利用空間局部性原理。Block 可以讓所有的 threads 調度到同一個 SM,讓 threads 可以通過 fast barriers 快速同步,并且通過 SM 的 Shared Memory 交換數據。隨著 GPU 的 SM 越來越多,僅僅使用 Block 這一層抽象已經不能夠更好地利用局部性原理,因此 Hopper 引入了 Cluster 這層抽象,讓所有的 threads 運行在同一個 GPC 內部。
總結:本小節簡單介紹了下 NVIDIA CUDA 編程模型與對應的 GPU 硬件體系結構。事實上,NVIDIA 的硬件體系結構是在不斷變化的,從最早 Telsa 架構的 SIMT 模型,到 Volta 架構為每個 Thread 引入獨立的程序計數器 PC,再到后面 Cooperative Groups 和異步編程 API 的引入,這些設計是經過了各種權衡和 tradeoff 做出的。關于 NVIDIA 系列 GPU 架構的演進,強烈推薦 zartbot 的系列文章[22]。
06.CUDA Core 與 Tensor Core 的演進
在深度學習中有大量的
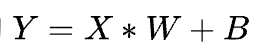
計算,然后通過激活函數傳遞到下一層神經網絡。這是一個典型的 GEMM 操作,對于 GEMM 的優化是一個非常有意思的話題,從數學角度 Strassen 等算法的優化,到計算機角度利用訪存局部性[23]等原理進行優化,乃至各種硬件層面的優化,都可以做的非常深。 2016 年 Google 發布 TPU[24],基于脈動陣列[25]這一古老技術從硬件上優化矩陣乘法,吹響了各類 DSA 的 AI 芯片挑戰 NVIDIA GPU 的號角。在 SIMT 道路上一路前行的 NVIDIA 積極應戰,在上一波深度學習喧囂的高潮也就是 2017 年發布了 Volta 架構,開始走上 DSA 的路子,引入了 Tensor Core。

Volta Tensor Core vs Pascal CUDA Core
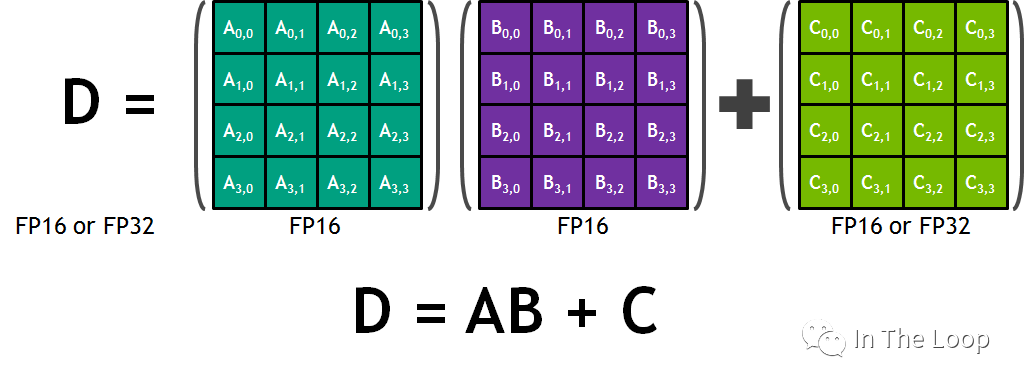
與 CUDA Core 在單位時鐘周期只能執行一次浮點乘法計算不同,Tensor Core 在單位時間可以執行一次矩陣乘法。以 Volta 架構為例,Tensor Core 可以支持每個時鐘周期 4 x 4 x 4 混合精度乘加,其中 A 矩陣和 B 矩陣都是 FP16 的精度,C 矩陣和 D 矩陣是 FP16 或者 FP32 的精度。
在深度學習中,相對于 HPC 領域標準 IEEE 浮點數計算,混合低精度計算更加常見。因此在 Volta 架構之后,NVIDIA 依次在之后的架構加入了更多低精度計算到 Tensor Core 中。
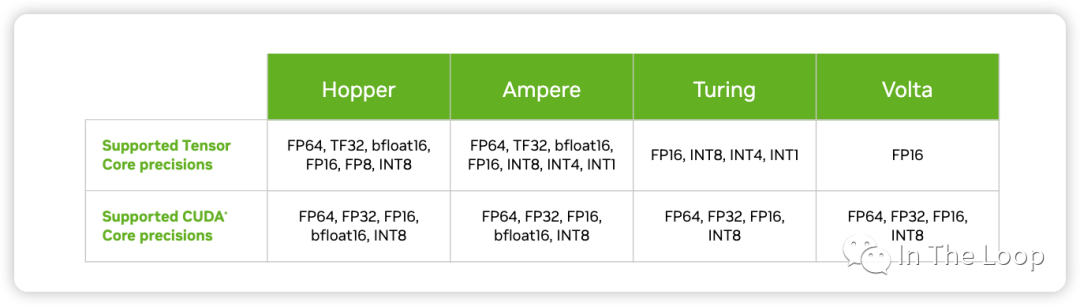
Turing 架構加入支持 INT8/INT4/INT1 的數據類型。Ampere 架構中加入新的 BF16 和 TF32 數據類型,并加入對于 Sparsity 的支持,并且每個 TensorCore 在每個時鐘周期支持的混合精度矩陣乘加從 Volta 的 4 x 4 x 4 進化到 8 x 4 x 8。
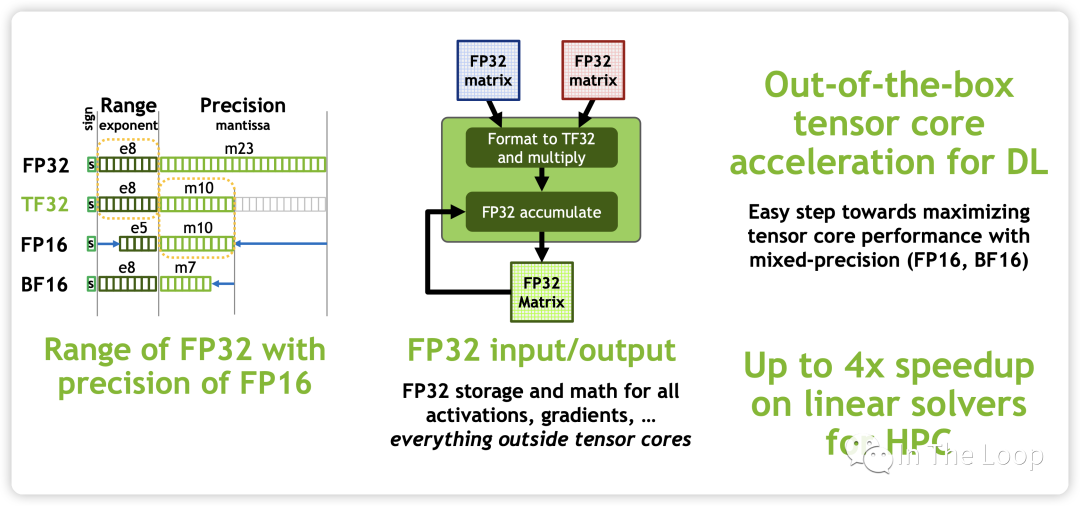
新增的 TF32 不會遇到 FP16 那樣溢出的問題,同時配合新的 BF16 和 FP32 可以實現階梯精度提升,而對于一個乘法器而言,又節省了芯片面積。BF16 數據格式是32位 IEEE 754單精度浮點格式(float32)的截斷(16位)版本。它保留了32位浮點數的近似動態范圍,保留了指數的8位,但只支持8位精度。Bfloat16用于降低存儲需求,提高機器學習算法的計算速度[26]。
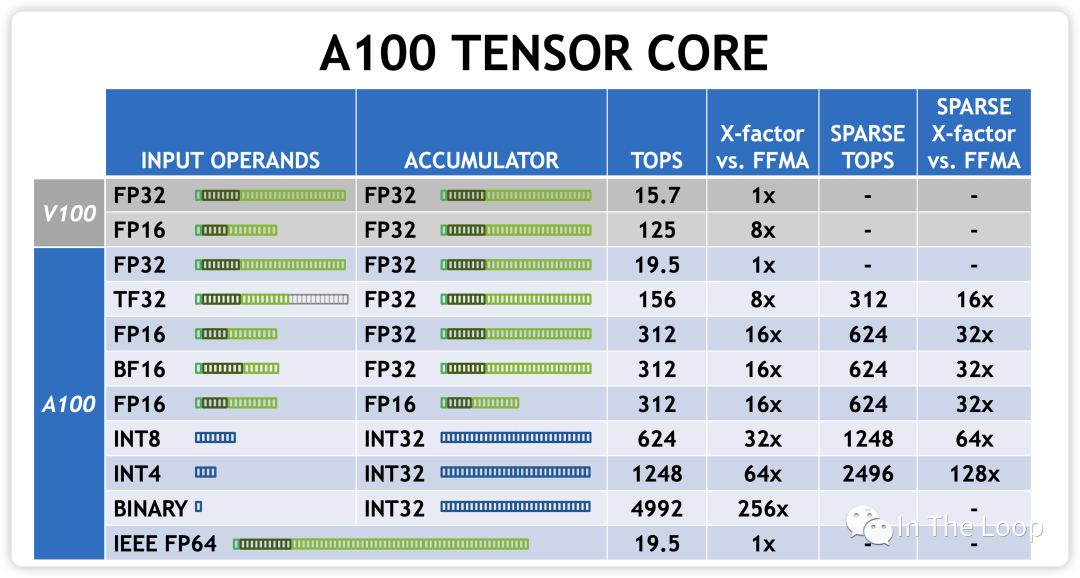
從而算力進一步增加:
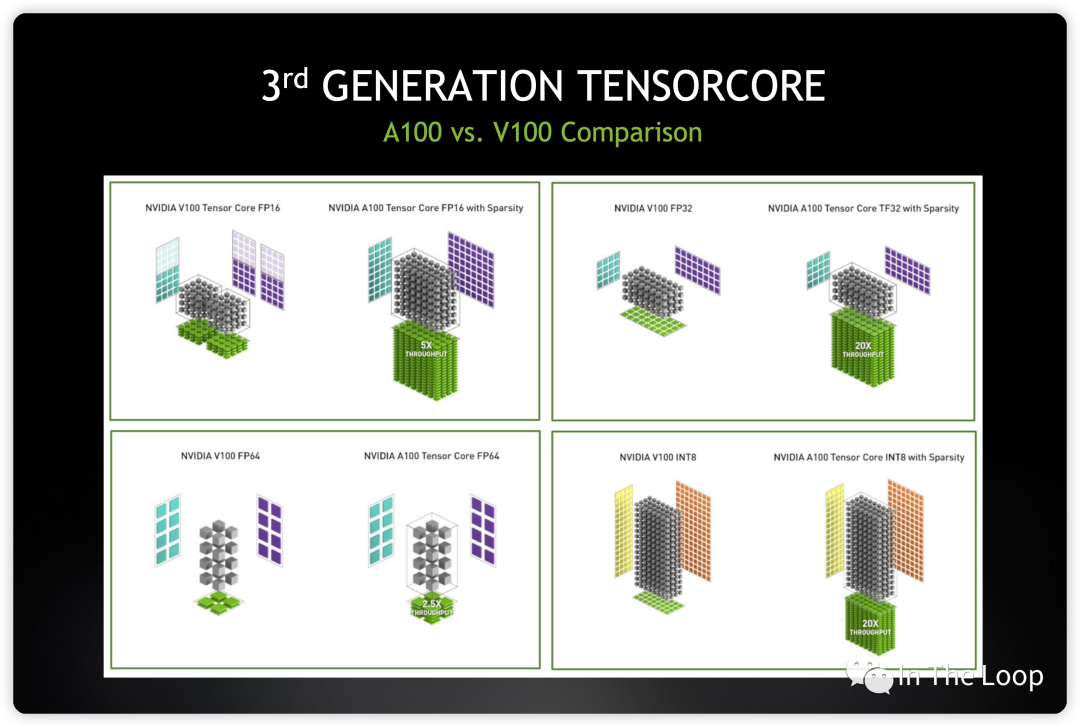
到了 Hopper 架構,每個 TensorCore 在每個時鐘周期支持的混合精度矩陣乘加進化到 4 x 8 x 16。TF32,FP64,INT8 Tensor Core 相對于 Ampere 有了 3 倍的性能提升。

同時,也加速了 Spare 張量計算:
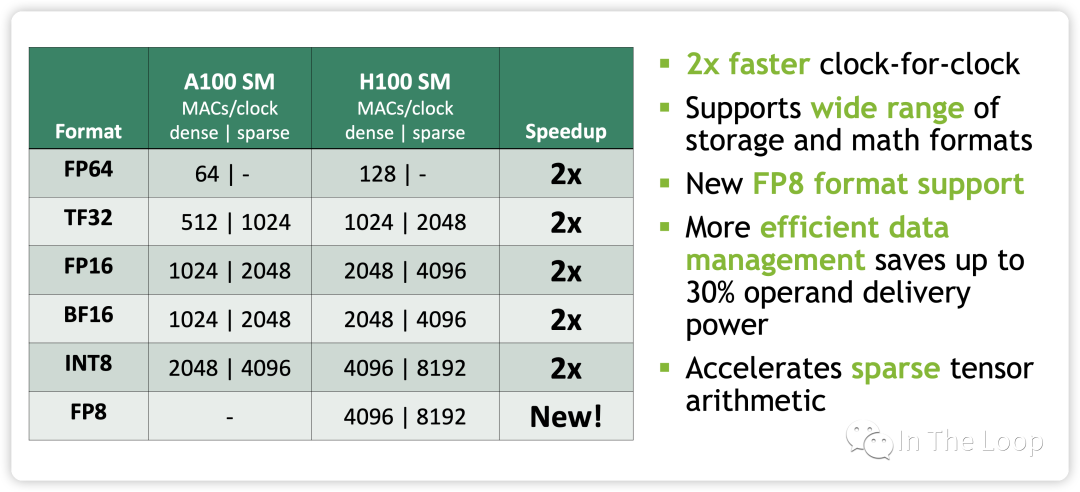
最重要的是,NVIDIA 在 Hopper 架構 TensorCore 引入了 FP8 的數據類型,并針對 Transformer 架構提出了 Transformer Engine 的技術,這個我們在下一小節會進一步闡述,此處暫時不表。
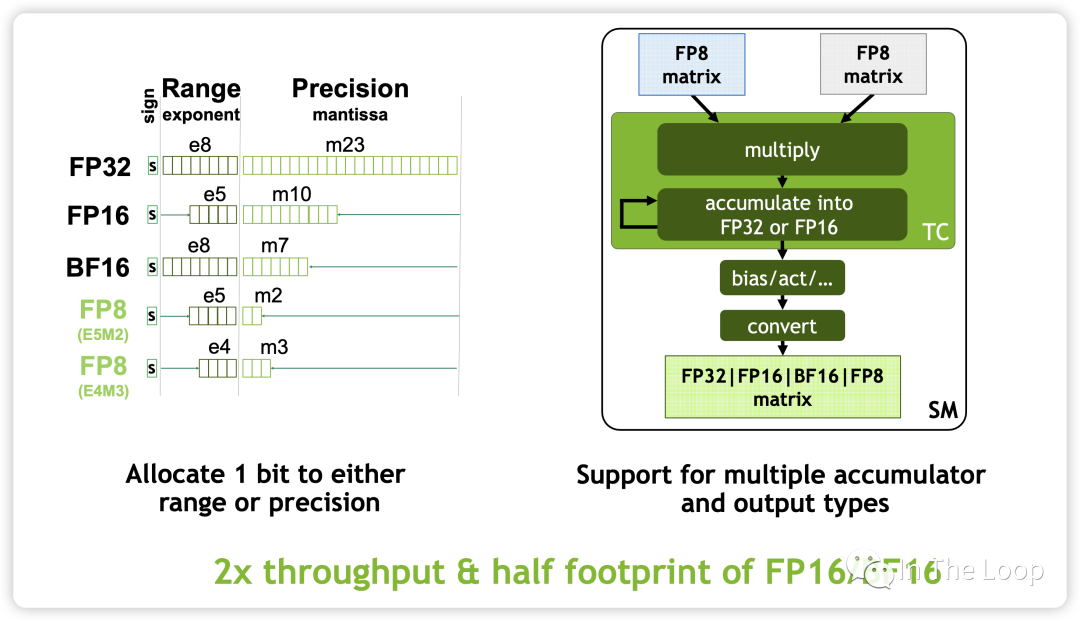
CUDA 提供了 WMMA (Warp MMA) 等底層 API 來利用 TensorCore 的硬件特性[27]。但是 TensorCore 編程并不容易,想要喂滿太難了,因此 CUDA 進一步提供了類似于 CUTLASS 和 CUBLAS,CUDNN 等更上層的庫來實現的,以后有機會可以進一步介紹其原理,此處暫時不表。
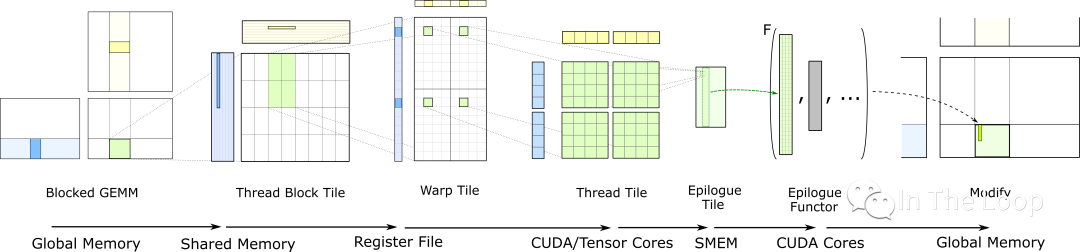
CUTLASS: GEMM Hierarchy with Epilogue
07.FP8 混合精度訓練與 Transformer Engine
如前所述,Hopper 架構的一個重要特點就是 TensorCore 引入了 FP8 的數據類型,這也是 H100 相對于 A100 的一個巨大優勢。
為什么要 FP8 的數據格式 ?
加速 math-intensive 操作:因為精度低,相對于 16-bits 的 TensorCore,FP8 快 2 倍。
加速 memory-intensive 操作:因為只占用一個字節,FP8 相對于 16-bits 能夠大幅減少訪問存儲 traffic,也可以減少模型的內存占用
更加方便推理:在推理中使用 FP8 已經是非常流行的選擇,當使用 FP8 格式訓練時可以更加方便推理部署,不再需要對模型進一步量化
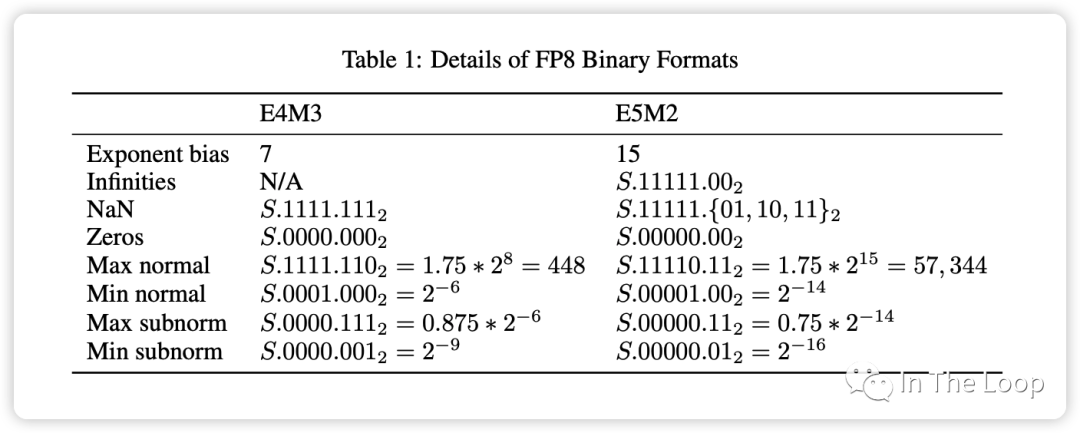
Source: FP8 Formats for Deep Learning Tensor Core 中 FP8 支持兩種數據格式:
E4M3
不遵循 IEEE 754 標準,支持 NaN 和 Zero 的編碼,但不支持 Inf
數據精度相對更高,可用于 fwd pass 和 inference
E5M2:
遵循 IEEE 754 標準,支持 Inf、NaN 和 Zero 的編碼
數據范圍更廣,可用于混合精度訓練的梯度表示

下圖展示了 FP8 GEMM 計算的主要過程示意圖:
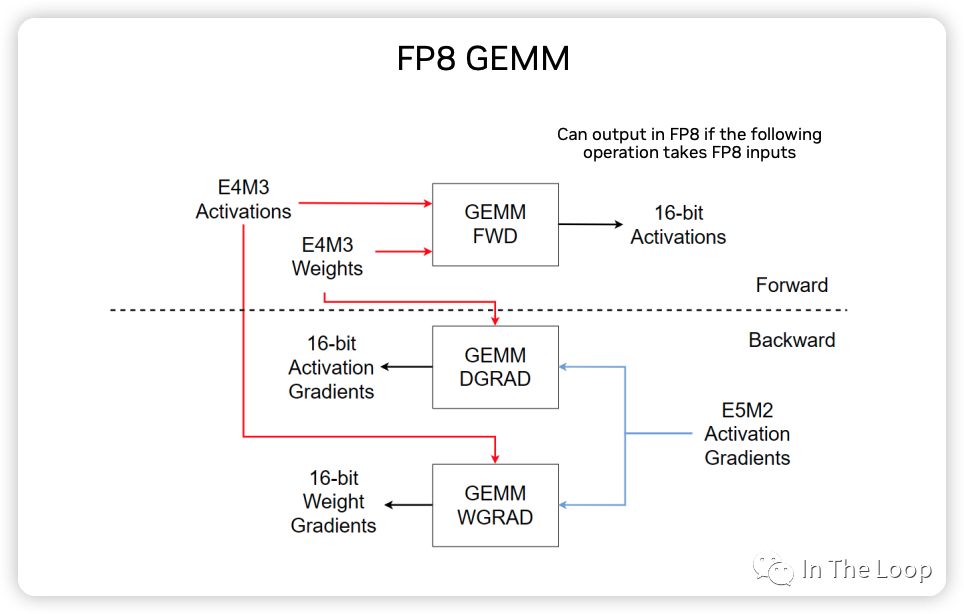
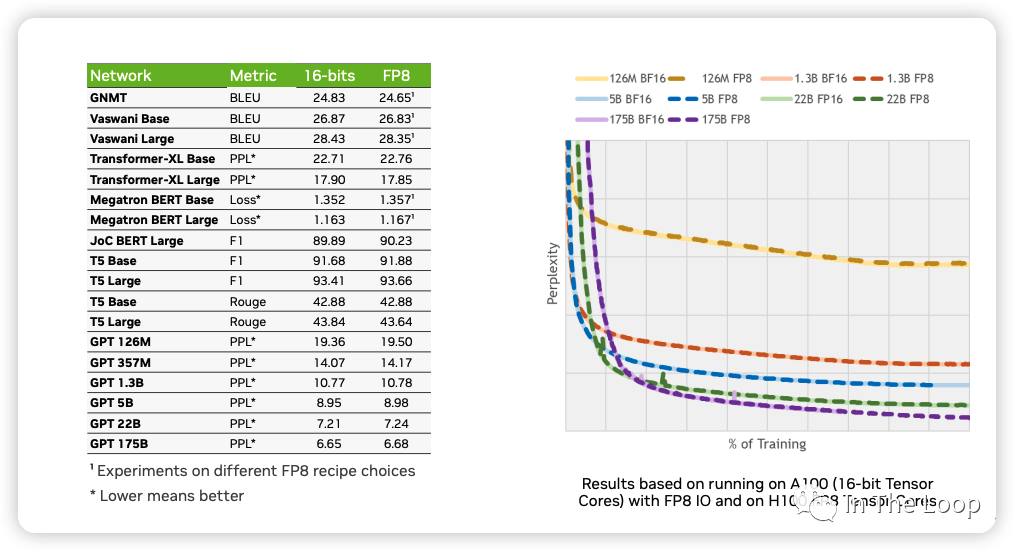
NVIDIA,ARM 和 Intel 在這篇論文[28] 中,利用 FP8 混合精度訓練,在基于 Transformer 的語言模型和基于 CNN 的視覺模型等不同網絡結構下進行驗證,證明了 FP8 可以達到與 BF16 基本一致的效果。
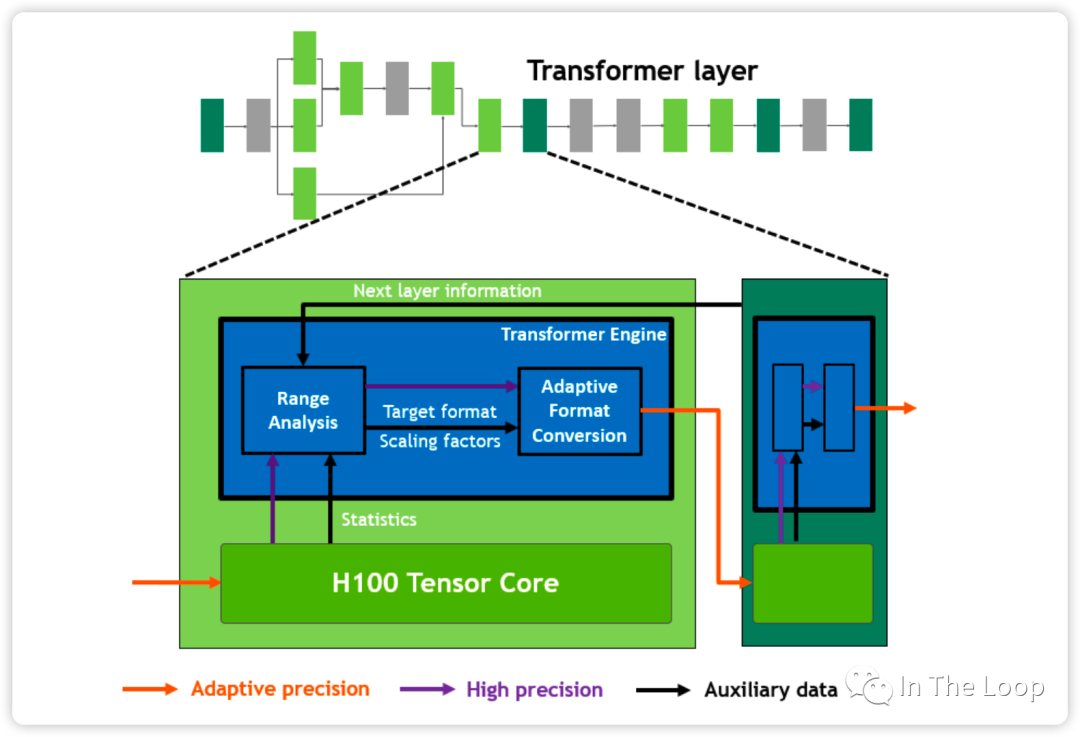
說了這么多的 FP8 混合精度訓練,那么 H100 白皮書里面的 Transformer Engine 又是什么呢?實際上,Transformer Engine 并不是涉及專用的硬件結構,而是一個軟件層面加速 Transformer 訓練的庫[29],其中提供了 FP8 混合精度訓練的加速方案。Transformer Engine 本質上可以通過 label 輸出的值域動態調整浮點精度,這里不再詳細論述,可以參考 Transformer Engine 的官方文檔[30]。
08.英偉達帝國大廈已成,頭上僅剩幾朵烏云
30 年前,NVIDIA 公司成立,30 年后 NVIDIA 公司市值超過萬億美元,構建了自己的龐大帝國。站在 2023 的今天回看過去三十年 GPU 市場的發展,令人感慨萬千:
1983 美國電子游戲的大蕭條[31] 和 80 年代個人電腦的推出,讓游戲從原來的家用游戲機轉移到 PC 平臺,從而引發了 PC 平臺下圖形卡的需求。1993 年成立初期的 NVIDIA 步履維艱,正是靠著日本街機游戲公司世嘉 Sega 的資助,以及押注微軟公司的 DirectX 接口,推出的 RIVA 迅速得到市場認可,并進一步推出世界第一款 GPU GeForce 256,徹底站穩市場。在那個群魔亂舞的 1990 到 2000 時代:
顯卡先驅 3DFX 最終被 NVIDIA 收購
S3 被 VIA 收購逐漸沉寂
Intel 最終放棄獨顯專攻集顯,這個劇情在 2000 年代再次重現,直到 2018 年 Intel 才真正意識到他們失去了什么,重新開始生產獨立顯卡
ATI 繼續和 NVIDIA 爭斗,最終被 AMD 收購,經過一番整合后 AMD 今日仍在競爭的一線
2000 到 2010 年代,NVIDIA 與 ATI 爭霸可編程 GPU。NVIDIA 在 2006 年推出極其靈活可編程的 CUDA 架構,并堅定地在這條路上走了下去,構建了其如今最大的護城河。
2010 年代,移動互聯網浪潮的到來,NVIDIA 推出 TEGRA 移動處理器嘗試染指這一市場卻最終平淡收場。所幸的是,2012 年之后深度學習開始崛起,NVIDIA 快速抓住了這波機會,CUDA 最終統治了這一市場,直到如今 AMD 的 ROCm 仍在苦苦維持。這十年 NVIDIA 繼續高歌猛進,抓住包括加密貨幣和自動駕駛等在內每一個市場機會,在數據中心、HPC、專業圖形等市場取得統治地位。
2020 年后,NVIDIA 收購了 Mellanox,強大的算力結合高速通信網絡,NVIDIA 又講起了 DPU 的故事,并繼續慢慢培育其 DOCA 平臺,試圖重演 CUDA 的故事。可惜的是,NVIDIA 收購 ARM 最終沒有被批準,ARM 獨立上市,不然手握 CPU、GPU 和 DPU 的英偉達真的可以完全定義下一個世代的計算平臺。
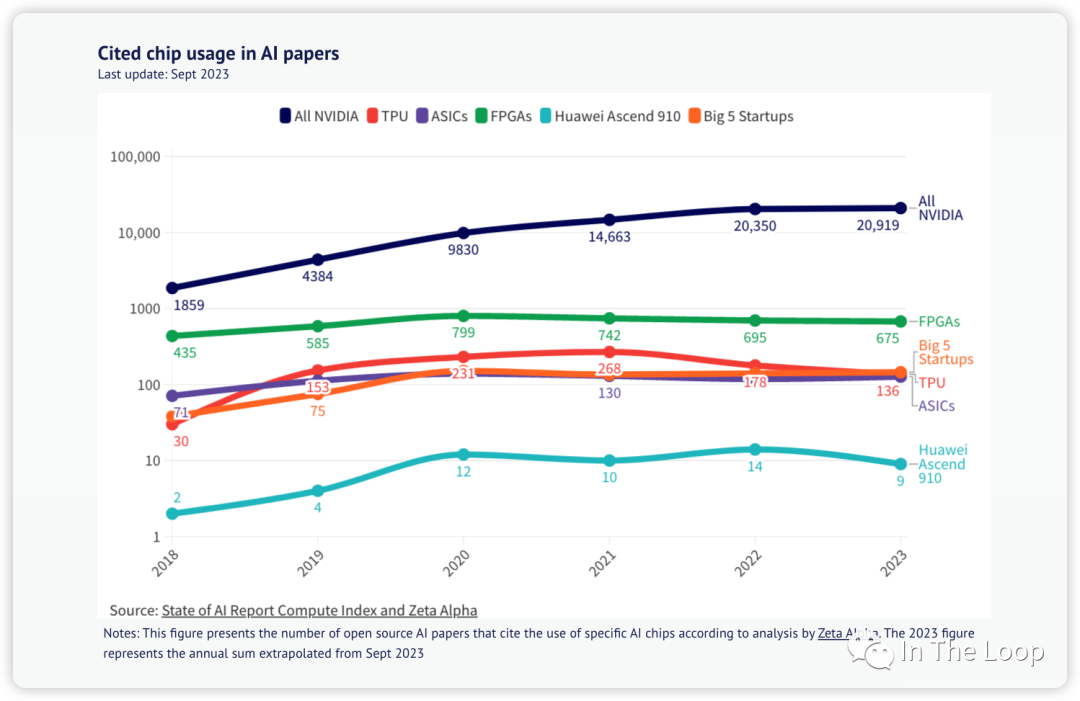
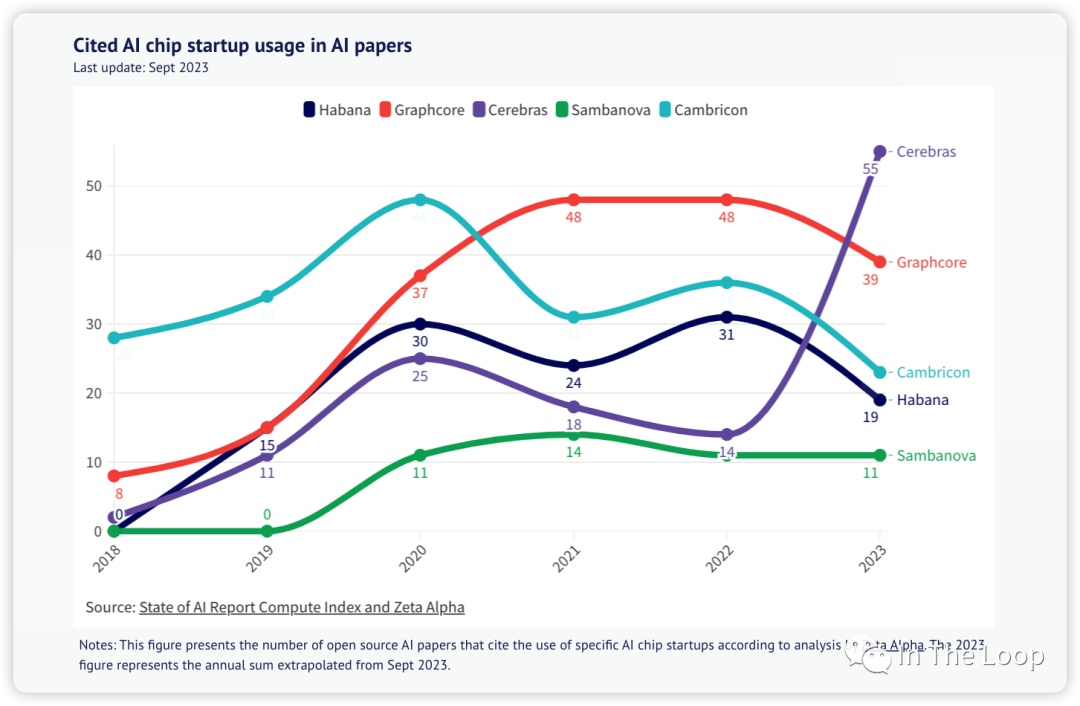
Cited chip usage in AI papers, Source: State of AI Report Compute Index 老黃的刀法讓大家又愛又恨,曾經的屠龍者成為了新的巨龍。H100 如今這么貴卻又賣的如此好,華為鯤鵬的夏晶老師分析了 H100 的成本[32],售價超過 3 萬美元的 H100 實際物理成本可能才不到 3000 美元,這也與海外投研機構 Raymond James 分析的 3,320 美元基本一致[33],純從物理成本上看 H100 利潤率接近 1000%。雖然這樣拋開研發成本看利潤率不太公允,但是也可以看出 NVIDIA 的底氣了。這真的是做 Infra 的最牛存在了,我可以賣的貴,我可以自己定義平臺,而你還不得不搶著來用我的。惡龍仍在,天下苦英偉達久矣,仍有新的少年想要戰勝惡龍。 今年 6 月,AMD 發布了 Instinct MI300 系列,其中 MI300X 直接對標 NVIDIA H100,蘇媽在接受采訪時,面對 CUDA 這一難以逾越的護城河問題的回答[34]反映了業界對于 LLM 領域強依賴于 NVIDIA 的問題的急切。
Q: If you look at what Wall Street thinks Nvidia’s mode is, it’s CUDA... You have ROCm, which is a little different. Do you think that that’s a moat that you can overcome with better products or with a more open approach? Lisa Su: I’m not a believer in moats when the market is moving as fast as it is... When you look at going forward, actually what you find is everyone’s looking for the ability to build hardware-agnostic software because people want choice. Frankly, people want choice... Things like PyTorch, for example, which tends to be that hardware-agnostic capability.
Q:PyTorch is a big deal, right? This is the language that all these models are actually coded in. I talk to a bunch of cloud CEOs. They don’t love their dependency on Nvidia as much as anybody doesn’t love being dependent on any one vendor. Is this a place where you can go work with those cloud providers and say, “We’re going to optimize our chips for PyTorch and not CUDA,” and developers can just run on PyTorch and pick whichever is best optimized? Lisa Su: That’s exactly it. PyTorch really is trying to be that sort of hardware-agnostic layer — one of the major milestones that we’ve come up with is on PyTorch 2.0. But our goal is “may the best chip win.” And the way you do that is to make the software much more seamless. And it’s PyTorch, but it’s also Jax. It’s also some of the tools that OpenAI is bringing in with Triton.
CUDA 確實非常優秀,但它是不是優秀到你要為它支付過多的成本,包括實際的金錢成本和各種隱形成本。基于 PyTorch 或者 Jax 這些新一代的中間層,新的解決方案正在形成。「AMD AI Software Solved – MI300X Pricing, Performance, PyTorch 2.0, FlashAttention, OpenAI Triton」 這篇文章[35] 展示了基于 PyTorch 2.0 和 OpenAI Triton, MosaicML 能夠基本不做代碼修改,在 AMD 硬件平臺上實現與 NVIDIA A100 基本一致的性能。
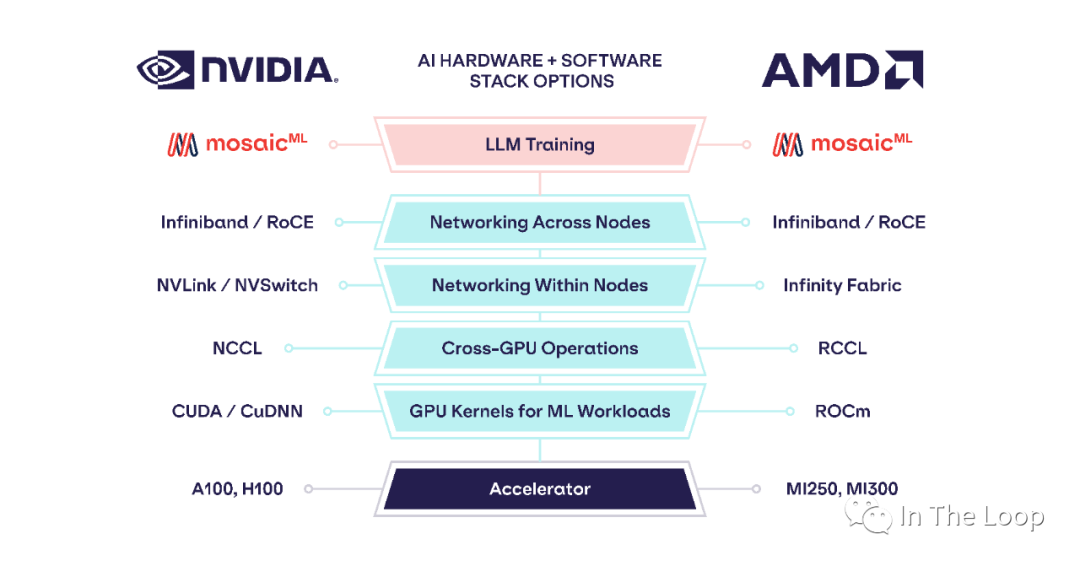
We profiled training throughput of MPT models from 1B to 13B parameters and found that the per-GPU-throughput ofMI250 was within 80% of the A100-40GB and within 73% of the A100-80GB. Abhi Venigalla, MosaicML[36]
今年 7 月,Intel 在國內發布 Habana Gaudi 2 AI 芯片,期望在國內禁售英偉達 H100/A100 的當下,分到這一波生成式人工智能浪潮的蛋糕。Habana Gaudi 2,正是 Intel 在 2019 年收購 Habana Labs 之后的作品,也是 Intel 在收購 Nervana 浪費 3 年時間后的再次嘗試。 除了 NVIDIA,AMD,Intel 這三個在 CPU/GPU/DPU 等各個領域打成一片的老冤家,還有 GraphCore、Cerebras 這樣的 AI Chip 創業公司仍在繼續。
與此同時,云服務巨頭家大業大,自然不甘心受制于人,紛紛投入自研 AI 芯片。前不久,AWS 投資 40 億美元到 Anthropic[37],目標之一就是讓 AWS 自研 Trainium 和 Inferentia 得到大量應用[38]。8 月底,Google Cloud 的 H100 實例 A3 終于姍姍來遲,但是也許這并不是他們的重點,重點是他們發布了 TPUv5e[39]。作為 AI 芯片的先行者,Google 的 TPU 相對于 AWS 的 Trainium/Inferentia 要成熟的多,TPU 也是應對 NVIDIA H100 的有力競爭對手[40]。 英偉達帝國大廈已經建立,只是頭上還有幾朵烏云。在美國禁售 A100/H100 的當下,如華為昇騰 910 這樣的國產 AI芯片也開始慢慢得到應用。30 年前,面對個人電腦這個新計算平臺的范式轉移,誕生了像 Intel,Microsoft 和 NVIDIA 這樣的巨頭。30 年后的今天,新一波生成式人工智能或將迎來新的計算范式轉移,這一次面對巨龍,又將會是怎樣的故事呢。
-
gpu
+關注
關注
28文章
4753瀏覽量
129064 -
AI芯片
+關注
關注
17文章
1893瀏覽量
35102 -
算力
+關注
關注
1文章
994瀏覽量
14863
原文標題:瘋狂的 H100:現代 GPU 體系結構淺析,從算力焦慮開始聊起
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英偉達a100和h100哪個強?英偉達A100和H100的區別
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
淺析PCI體系結構
LTE體系結構
NVIDIA發布新一代產品—NVIDIA H100

NVIDIA發布最新Hopper架構的H100系列GPU和Grace CPU超級芯片
藍海大腦服務器全力支持NVIDIA H100 GPU
利用NVIDIA HGX H100加速計算數據中心平臺應用
關于NVIDIA H100 GPU的問題解答

傳英偉達新AI芯片H20綜合算力比H100降80%
英偉達H100,沒那么缺貨了 !RTX 4090 ,大漲
一文梳理:如何構建并優化GPU云算力中心?





 工商網監
工商網監
評論