 mysql經典面試題及答案
mysql經典面試題及答案
問題1:char、varchar的區別是什么?
varchar是變長而char的長度是固定的。如果你的內容是固定大小的,你會得到更好的性能。
問題2: TRUNCATE和DELETE的區別是什么?
DELETE命令從一個表中刪除某一行,或多行,TRUNCATE命令永久地從表中刪除每一行。
問題3:什么是觸發器,MySQL中都有哪些觸發器?
觸發器是指一段代碼,當觸發某個事件時,自動執行這些代碼。在MySQL數據庫中有如下六種觸發器:
1、Before Insert
2、After Insert
3、Before Update
4、After Update
5、Before Delete
6、After Delete
問題4:FLOAT和DOUBLE的區別是什么?
FLOAT類型數據可以存儲至多8位十進制數,并在內存中占4字節。
DOUBLE類型數據可以存儲至多18位十進制數,并在內存中占8字節。
問題5:如何在MySQL種獲取當前日期?
SELECTCURRENT_DATE();
問題6:如何查詢第n高的工資?
SELECTDISTINCT(salary)fromemployeeORDERBYsalaryDESCLIMITn-1,1
問題7:請寫出下面MySQL數據類型表達的意義(int(0)、char(16)、varchar(16)、datetime、text)
知識點分析
此題考察的是MySQL數據類型。MySQL數據類型屬于MySQL數據庫基礎,由此延伸出的知識點還包括如下內容:
MySQL基礎操作
MySQL存儲引擎
MySQL鎖機制
MySQL事務處理、存儲過程、觸發器
數據類型考點:
1、整數類型,包括TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT,分別表示1字節、2字節、3字節、4字節、8字節整數。任何整數類型都可以加上UNSIGNED屬性,表示數據是無符號的,即非負整數。
長度:整數類型可以被指定長度,例如:INT(11)表示長度為11的INT類型。長度在大多數場景是沒有意義的,它不會限制值的合法范圍,只會影響顯示字符的個數,而且需要和UNSIGNED ZEROFILL屬性配合使用才有意義。
例子,假定類型設定為INT(5),屬性為UNSIGNED ZEROFILL,如果用戶插入的數據為12的話,那么數據庫實際存儲數據為00012。
2、實數類型,包括FLOAT、DOUBLE、DECIMAL。
DECIMAL可以用于存儲比BIGINT還大的整型,能存儲精確的小數。
而FLOAT和DOUBLE是有取值范圍的,并支持使用標準的浮點進行近似計算。
計算時FLOAT和DOUBLE相比DECIMAL效率更高一些,DECIMAL你可以理解成是用字符串進行處理。
3、字符串類型,包括VARCHAR、CHAR、TEXT、BLOB
VARCHAR用于存儲可變長字符串,它比定長類型更節省空間。
VARCHAR使用額外1或2個字節存儲字符串長度。列長度小于255字節時,使用1字節表示,否則使用2字節表示。
VARCHAR存儲的內容超出設置的長度時,內容會被截斷。
CHAR是定長的,根據定義的字符串長度分配足夠的空間。
CHAR會根據需要使用空格進行填充方便比較。
CHAR適合存儲很短的字符串,或者所有值都接近同一個長度。
CHAR存儲的內容超出設置的長度時,內容同樣會被截斷。
使用策略:
對于經常變更的數據來說,CHAR比VARCHAR更好,因為CHAR不容易產生碎片。
對于非常短的列,CHAR比VARCHAR在存儲空間上更有效率。
使用時要注意只分配需要的空間,更長的列排序時會消耗更多內存。
盡量避免使用TEXT/BLOB類型,查詢時會使用臨時表,導致嚴重的性能開銷。
4、枚舉類型(ENUM),把不重復的數據存儲為一個預定義的集合。
有時可以使用ENUM代替常用的字符串類型。
ENUM存儲非常緊湊,會把列表值壓縮到一個或兩個字節。
ENUM在內部存儲時,其實存的是整數。
盡量避免使用數字作為ENUM枚舉的常量,因為容易混亂。
排序是按照內部存儲的整數
5、日期和時間類型,盡量使用timestamp,空間效率高于datetime,
用整數保存時間戳通常不方便處理。
如果需要存儲微妙,可以使用bigint存儲。
看到這里,這道真題是不是就比較容易回答了。
答:int(0)表示數據是INT類型,長度是0、char(16)表示固定長度字符串,長度為16、varchar(16)表示可變長度字符串,長度為16、datetime表示時間類型、text表示字符串類型,能存儲大字符串,最多存儲65535字節數據)
MySQL基礎操作:
常見操作
MySQL的連接和關閉:mysql -u -p -h -P
-u:指定用戶名
-p:指定密碼
-h:主機
-P:端口
進入MySQL命令行后:G、c、q、s、h、d
G:打印結果垂直顯示
c:取消當前MySQL命令
q:退出MySQL連接
s:顯示服務器狀態
h:幫助信息
d:改變執行符
MySQL存儲引擎:
1、InnoDB存儲引擎,
默認事務型引擎,最重要最廣泛的存儲引擎,性能非常優秀。
數據存儲在共享表空間,可以通過配置分開。也就是多個表和索引都存儲在一個表空間中,可以通過配置文件改變此配置。
對主鍵查詢的性能高于其他類型的存儲引擎。
內部做了很多優化,從磁盤讀取數據時會自動構建hash索引,插入數據時自動構建插入緩沖區。
通過一些機制和工具支持真正的熱備份。
支持崩潰后的安全恢復。
支持行級鎖。
支持外鍵。
2、MyISAM存儲引擎,
擁有全文索引、壓縮、空間函數。
不支持事務和行級鎖、不支持崩潰后的安全恢復。
表存儲在兩個文件,MYD和MYI。
設計簡單,某些場景下性能很好,例如獲取整個表有多少條數據,性能很高。
全文索引不是很常用,不如使用外部的ElasticSearch或Lucene。
3、其他表引擎,
Archive、Blackhole、CSV、Memory
使用策略
在大多數場景下建議使用InnoDB存儲引擎。
MySQL鎖機制
表鎖是日常開發中的常見問題,因此也是面試當中最常見的考察點,當多個查詢同一時刻進行數據修改時,就會產生并發控制的問題。共享鎖和排他鎖,就是讀鎖和寫鎖。
共享鎖,不堵塞,多個用戶可以同時讀一個資源,互不干擾。
排他鎖,一個寫鎖會阻塞其他的讀鎖和寫鎖,這樣可以只允許一個用戶進行寫入,防止其他用戶讀取正在寫入的資源。
鎖的粒度
表鎖,系統開銷最小,會鎖定整張表,MyIsam使用表鎖。
行鎖,最大程度的支持并發處理,但是也帶來了最大的鎖開銷,InnoDB使用行鎖。
MySQL事務處理
MySQL提供事務處理的表引擎,也就是InnoDB。
服務器層不管理事務,由下層的引擎實現,所以同一個事務中,使用多種引擎是不靠譜的。
需要注意,在非事務表上執行事務操作,MySQL不會發出提醒,也不會報錯。
存儲過程
為以后的使用保存的一條或多條MySQL語句的集合,因此也可以在存儲過程中加入業務邏輯和流程。
可以在存儲過程中創建表,更新數據,刪除數據等等。
使用策略
可以通過把SQL語句封裝在容易使用的單元中,簡化復雜的操作
可以保證數據的一致性
可以簡化對變動的管理
觸發器
提供給程序員和數據分析員來保證數據完整性的一種方法,它是與表事件相關的特殊的存儲過程。
使用場景
可以通過數據庫中的相關表實現級聯更改。
實時監控某張表中的某個字段的更改而需要做出相應的處理。
例如可以生成某些業務的編號。
注意不要濫用,否則會造成數據庫及應用程序的維護困難。
大家需要牢記以上基礎知識點,重點是理解數據類型CHAR和VARCHAR的差異,表存儲引擎InnoDB和MyISAM的區別。
問題8:請說明InnoDB和MyISAM的區別
InnoDB支持事務,MyISAM不支持;
InnoDB數據存儲在共享表空間,MyISAM數據存儲在文件中;
InnoDB支持行級鎖,MyISAM只支持表鎖;
InnoDB支持崩潰后的恢復,MyISAM不支持;
InnoDB支持外鍵,MyISAM不支持;
InnoDB不支持全文索引,MyISAM支持全文索引;
問題9:innodb引擎的特性
插入緩沖(insert buffer)
二次寫(double write)
自適應哈希索引(ahi)
預讀(read ahead)
問題10:請列舉3個以上表引擎
InnoDB、MyISAM、Memory
問題11:請說明varchar和text的區別
varchar可指定字符數,text不能指定,內部存儲varchar是存入的實際字符數+1個字節(n<=255)或2個字節(n>255),text是實際字符數+2個字節。
text類型不能有默認值。
varchar可直接創建索引,text創建索引要指定前多少個字符。varchar查詢速度快于text,在都創建索引的情況下,text的索引幾乎不起作用。
查詢text需要創建臨時表。
問題11:varchar(50)中50的含義
最多存放50個字符,varchar(50)和(200)存儲hello所占空間一樣,但后者在排序時會消耗更多內存,因為order by col采用fixed_length計算col長度(memory引擎也一樣)。
問題12:int(20)中20的含義
是指顯示字符的長度,不影響內部存儲,只是當定義了ZEROFILL時,前面補多少個 0
問題13:簡單描述MySQL中,索引,主鍵,唯一索引,聯合索引的區別,對數據庫的性能有什么影響?
知識點分析
此真題主要考察的是MySQL索引的基礎和類型,由此延伸出的知識點還包括如下內容:
MySQL索引的創建原則
MySQL索引的注意事項
MySQL索引的原理
下面我們就來將這些知識一網打盡
索引的基礎
索引類似于書籍的目錄,要想找到一本數的某個特定主題,需要先查找書的目錄,定位對應的頁碼
存儲引擎使用類似的方式進行數據查詢,先去索引當中找到對應的值,然后根據匹配的索引找到對應的數據行。
創建索引的語法:
首先創建一個表:create table t1 (id int primary key,username varchar(20),password varchar(20));
創建單個索引的語法:CREATE INDEX 索引名 on 表名(字段名)
索引名一般是:表名_字段名
給id創建索引:CREATE INDEX t1_id on t1(id);
創建聯合索引的語法:CREATE INDEX 索引名 on 表名(字段名1,字段名2)
給username和password創建聯合索引:CREATE index t1_username_password ON t1(username,password)
其中index還可以替換成unique,primary key,分別代表唯一索引和主鍵索引
刪除索引:DROP INDEX t1_username_password ON t1
索引對性能的影響:
大大減少服務器需要掃描的數據量。
幫助服務器避免排序和臨時表。
將隨機I/O變順序I/O。
大大提高查詢速度。
降低寫的速度(不良影響)。
磁盤占用(不良影響)。
索引的使用場景:
對于非常小的表,大部分情況下全表掃描效率更高。
中到大型表,索引非常有效。
特大型的表,建立和使用索引的代價會隨之增大,可以使用分區技術來解決。
索引的類型:
索引很多種類型,是在MySQL的存儲引擎實現的。
普通索引:最基本的索引,沒有任何約束限制。
唯一索引:和普通索引類似,但是具有唯一性約束。
主鍵索引:特殊的唯一索引,不允許有空值。
索引的區別:
-一個表只能有一個主鍵索引,但是可以有多個唯一索引。
主鍵索引一定是唯一索引,唯一索引不是主鍵索引。
主鍵可以與外鍵構成參照完整性約束,防止數據不一致。
聯合索引:將多個列組合在一起創建索引,可以覆蓋多個列。(也叫復合索引,組合索引)
外鍵索引:只有InnoDB類型的表才可以使用外鍵索引,保證數據的一致性、完整性、和實現級聯操作(基本不用)。
全文索引:MySQL自帶的全文索引只能用于MyISAM,并且只能對英文進行全文檢索 (基本不用)
MySQL索引的創建原則
最適合創建索引的列是出現在WHERE或ON子句中的列,或連接子句中的列而不是出現在SELECT關鍵字后的列。
索引列的基數越大,數據區分度越高,索引的效果越好。
對于字符串進行索引,應該制定一個前綴長度,可以節省大量的索引空間。
根據情況創建聯合索引,聯合索引可以提高查詢效率。
避免創建過多的索引,索引會額外占用磁盤空間,降低寫操作效率。
主鍵盡可能選擇較短的數據類型,可以有效減少索引的磁盤占用提高查詢效率。
MySQL索引的注意事項
1、聯合索引遵循前綴原則
KEY(a,b,c) WHEREa=1ANDb=2ANDc=3 WHEREa=1ANDb=2 WHEREa=1 #以上SQL語句可以用到索引 WHEREb=2ANDc=3 WHEREa=1ANDc=3 #以上SQL語句用不到索引
2、LIKE查詢,%不能在前
WHEREnameLIKE"%wang%"
#以上語句用不到索引,可以用外部的ElasticSearch、Lucene等全文搜索引擎替代。
3、列值為空(NULL)時是可以使用索引的,但MySQL難以優化引用了可空列的查詢,它會使索引、索引統計和值更加復雜。可空列需要更多的儲存空間,還需要在MySQL內部進行特殊處理。
4、如果MySQL估計使用索引比全表掃描更慢,會放棄使用索引,例如:
表中只有100條數據左右。對于SQL語句WHERE id > 1 AND id < 100,MySQL會優先考慮全表掃描。
5、如果關鍵詞or前面的條件中的列有索引,后面的沒有,所有列的索引都不會被用到。
6、列類型是字符串,查詢時一定要給值加引號,否則索引失效,例如:
列name varchar(16),存儲了字符串"100"
WHERE name = 100;
以上SQL語句能搜到,但無法用到索引。
MySQL索引的原理
MySQL索引是用一種叫做聚簇索引的數據結構實現的,下面我們就來看一下什么是聚簇索引。
聚簇索引是一種數據存儲方式,它實際上是在同一個結構中保存了B+樹索引和數據行,InnoDB表是按照聚簇索引組織的(類似于Oracle的索引組織表)。
注: B+樹是一種樹數據結構,是一個n叉排序樹,每個節點通常有多個孩子,一棵B+樹包含根節點、內部節點和葉子節點。根節點可能是一個葉子節點,也可能是一個包含兩個或兩個以上孩子節點的節點。 B+樹通常用于數據庫和操作系統的文件系統中。NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系統都在使用B+樹作為元數據索引。B+樹的特點是能夠保持數據穩定有序,其插入與修改擁有較穩定的對數時間復雜度。B+樹元素自底向上插入。
InnoDB通過主鍵聚簇數據,如果沒有定義主鍵,會選擇一個唯一的非空索引代替,如果沒有這樣的索引,會隱式定義個主鍵作為聚簇索引。
下圖形象說明了聚簇索引表(InnoDB)和普通的堆組織表(MyISAM)的區別:
最常問的MySQL面試題三——每個開發人員都應該知道
對于普通的堆組織表來說(右圖),表數據和索引是分別存儲的,主鍵索引和二級索引存儲上沒有任何區別。
而對于聚簇索引表來說(左圖),表數據是和主鍵一起存儲的,主鍵索引的葉結點存儲行數據,二級索引的葉結點存儲行的主鍵值。
聚簇索引表最大限度地提高了I/O密集型應用的性能,但它也有以下幾個限制:
1)插入速度嚴重依賴于插入順序,按照主鍵的順序插入是最快的方式,否則將會出現頁分裂,嚴重影響性能。因此,對于InnoDB表,我們一般都會定義一個自增的ID列為主鍵。
2)更新主鍵的代價很高,因為將會導致被更新的行移動。因此,對于InnoDB表,我們一般定義主鍵為不可更新。
3)二級索引訪問需要兩次索引查找,第一次找到主鍵值,第二次根據主鍵值找到行數據。
二級索引的葉節點存儲的是主鍵值,而不是行指針,這是為了減少當出現行移動或數據頁分裂時二級索引的維護工作,但會讓二級索引占用更多的空間。
解題方法
在一些MySQL索引基礎考題中,我們可以輕松的通過索引基礎和類型來解決此類問題,對于一些索引創建注意事項方面的考點,我們可以通過索引創建原則和注意事項來解決。
問題14:創建MySQL聯合索引應該注意什么?
需遵循前綴原則
問題15:列值為NULL時,查詢是否會用到索引?
在MySQL里NULL值的列也是走索引的。當然,如果計劃對列進行索引,就要盡量避免把它設置為可空,MySQL難以優化引用了可空列的查詢,它會使索引、索引統計和值更加復雜。
問題16:以下語句是否會應用索引:SELECTFROM users WHERE YEAR(adddate) < 2007;*
不會,因為只要列涉及到運算,MySQL就不會使用索引。
問題17:MyISAM索引實現?
MyISAM存儲引擎使用B+Tree作為索引結構,葉節點的data域存放的是數據記錄的地址。MyISAM的索引方式也叫做非聚簇索引的,之所以這么稱呼是為了與InnoDB的聚簇索引區分。
問題17:MyISAM索引與InnoDB索引的區別?
InnoDB索引是聚簇索引,MyISAM索引是非聚簇索引。
InnoDB的主鍵索引的葉子節點存儲著行數據,因此主鍵索引非常高效。
MyISAM索引的葉子節點存儲的是行數據地址,需要再尋址一次才能得到數據。
InnoDB非主鍵索引的葉子節點存儲的是主鍵和其他帶索引的列數據,因此查詢時做到覆蓋索引會非常高效。
問題18:以下三條sql 如何建索引,只建一條怎么建?
WHEREa=1ANDb=1 WHEREb=1 WHEREb=1ORDERBYtimeDESC
以順序b,a,time建立聯合索引,CREATE INDEX table1_b_a_time ON index_test01(b,a,time)。因為最新MySQL版本會優化WHERE子句后面的列順序,以匹配聯合索引順序。
問題19:有A(id,sex,par,c1,c2),B(id,age,c1,c2)兩張表,其中A.id與B.id關聯,現在要求寫出一條SQL語句,將B中age>50的記錄的c1,c2更新到A表中同一記錄中的c1,c2字段中
考點分析
這道題主要考察的是MySQL的關聯UPDATE語句
延伸考點:
MySQL的關聯查詢語句
MySQL的關聯UPDATE語句
針對剛才這道題,答案可以是如下兩種形式的寫法:
UPDATEA,BSETA.c1=B.c1,A.c2=B.c2WHEREA.id=B.id UPDATEAINNERJOINBONA.id=B.idSETA.c1=B.c1,A.c2=B.c2 再加上B中age>50的條件: UPDATEA,BsetA.c1=B.c1,A.c2=B.c2WHEREA.id=B.idandB.age>50; UPDATEAINNERJOINBONA.id=B.idsetA.c1=B.c1,A.c2=B.c2WHEREB.age>50
MySQL的關聯查詢語句
六種關聯查詢
交叉連接(CROSS JOIN)
內連接(INNER JOIN)
外連接(LEFT JOIN/RIGHT JOIN)
聯合查詢(UNION與UNION ALL)
全連接(FULL JOIN)
交叉連接(CROSS JOIN)
SELECT*FROMA,B(,C)或者 SELECT*FROMACROSSJOINB(CROSSJOINC) #沒有任何關聯條件,結果是笛卡爾積,結果集會很大,沒有意義,很少使用 內連接(INNERJOIN) SELECT*FROMA,BWHEREA.id=B.id或者 SELECT*FROMAINNERJOINBONA.id=B.id 多表中同時符合某種條件的數據記錄的集合,INNERJOIN可以縮寫為JOIN
內連接分為三類
等值連接:ON A.id=B.id
不等值連接:ON A.id > B.id
自連接:SELECT * FROM A T1 INNER JOIN A T2 ON T1.id=T2.pid
外連接(LEFT JOIN/RIGHT JOIN)
左外連接:LEFT OUTER JOIN, 以左表為主,先查詢出左表,按照ON后的關聯條件匹配右表,沒有匹配到的用NULL填充,可以簡寫成LEFT JOIN
右外連接:RIGHT OUTER JOIN, 以右表為主,先查詢出右表,按照ON后的關聯條件匹配左表,沒有匹配到的用NULL填充,可以簡寫成RIGHT JOIN
聯合查詢(UNION與UNION ALL)
SELECT*FROMAUNIONSELECT*FROMBUNION...
就是把多個結果集集中在一起,UNION前的結果為基準,需要注意的是聯合查詢的列數要相等,相同的記錄行會合并
如果使用UNION ALL,不會合并重復的記錄行
效率 UNION 高于 UNION ALL
全連接(FULL JOIN)
MySQL不支持全連接
可以使用LEFT JOIN 和UNION和RIGHT JOIN聯合使用
SELECT*FROMALEFTJOINBONA.id=B.idUNION SELECT*FROMARIGHTJOINBONA.id=B.id
嵌套查詢
用一條SQL語句得結果作為另外一條SQL語句得條件,效率不好把握
SELECT * FROM A WHERE id IN (SELECT id FROM B)
解題方法
根據考題要搞清楚表的結果和多表之間的關系,根據想要的結果思考使用那種關聯方式,通常把要查詢的列先寫出來,然后分析這些列都屬于哪些表,才考慮使用關聯查詢
問題20:
為了記錄足球比賽的結果,設計表如下:
team:參賽隊伍表
match:賽程表
其中,match賽程表中的hostTeamID與guestTeamID都和team表中的teamID關聯,查詢2006-6-1到2006-7-1之間舉行的所有比賽,并且用以下形式列出:拜仁 2:0 不萊梅 2006-6-21
首先列出需要查詢的列:
表team
teamID teamName
表match
match ID
hostTeamID
guestTeamID
matchTime matchResult
其次列出結果列:
主隊 結果 客對 時間
初步寫一個基礎的SQL:
SELECThostTeamID,matchResult,matchTimeguestTeamIDfrommatchwherematchTimebetween"2006-6-1"and"2006-7-1";
通過外鍵聯表,完成最終SQL:
selectt1.teamName,m.matchResult,t2.teamName,m.matchTimefrommatchasmleftjointeamast1onm.hostTeamID=t1.teamID,leftjointeamt2onm.guestTeamID=t2.guestTeamIDwherem.matchTimebetween"2006-6-1"and"2006-7-1"
問題21:UNION與UNION ALL的區別?
如果使用UNION ALL,不會合并重復的記錄行
效率 UNION 高于 UNION ALL
問題22:一個6億的表a,一個3億的表b,通過外鍵tid關聯,你如何最快的查詢出滿足條件的第50000到第50200中的這200條數據記錄。
1、如果A表TID是自增長,并且是連續的,B表的ID為索引
select*froma,bwherea.tid=b.idanda.tid>50000limit200;
2、如果A表的TID不是連續的,那么就需要使用覆蓋索引.TID要么是主鍵,要么是輔助索引,B表ID也需要有索引。
select*fromb,(selecttidfromalimit50000,200)awhereb.id=a.tid;
問題23:拷貝表( 拷貝數據, 源表名:a 目標表名:b)
insertintob(a,b,c)selectd,e,ffroma;
問題24:Student(S#,Sname,Sage,Ssex) 學生表 Course(C#,Cname,T#) 課程表 SC(S#,C#,score) 成績表 Teacher(T#,Tname) 教師表 查詢沒學過“葉平”老師課的同學的學號、姓名
selectStudent.S#,Student.Sname fromStudent whereS#notin(selectdistinct(SC.S#)fromSC,Course,TeacherwhereSC.C#=Course.C#andTeacher.T#=Course.T#andTeacher.Tname=’葉平’);
問題25:隨機取出10條數據
SELECT*FROMusersWHEREid>=((SELECTMAX(id)FROMusers)-(SELECTMIN(id)FROMusers))*RAND()+(SELECTMIN(id)FROMusers)LIMIT10 #此方法效率比直接用SELECT*FROMusersorderbyrand()LIMIT10高很多
問題26:請簡述項目中優化SQL語句執行效率的方法,從哪些方面,SQL語句性能如何分析?
考點分析:
這道題主要考察的是查找分析SQL語句查詢速度慢的方法
延伸考點:
優化查詢過程中的數據訪問
優化長難的查詢語句
優化特定類型的查詢語句
如何查找查詢速度慢的原因
記錄慢查詢日志,分析查詢日志,不要直接打開慢查詢日志進行分析,這樣比較浪費時間和精力,可以使用pt-query-digest工具進行分析
使用show profile
setprofiling=1;開啟,服務器上所有執行語句會記錄執行時間,存到臨時表中 showprofiles showprofileforquery臨時表ID
使用show status
show status會返回一些計數器,show global status會查看所有服務器級別的所有計數
有時根據這些計數,可以推測出哪些操作代價較高或者消耗時間多
show processlist
觀察是否有大量線程處于不正常的狀態或特征

最常問的MySQL面試題五——每個開發人員都應該知道
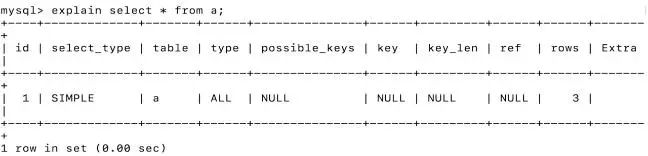
使用explain
分析單條SQL語句
優化查詢過程中的數據訪問
訪問數據太多導致查詢性能下降
確定應用程序是否在檢索大量超過需要的數據,可能是太多行或列
確認MySQL服務器是否在分析大量不必要的數據行
避免犯如下SQL語句錯誤
查詢不需要的數據。解決辦法:使用limit解決
多表關聯返回全部列。解決辦法:指定列名
總是返回全部列。解決辦法:避免使用SELECT *
重復查詢相同的數據。解決辦法:可以緩存數據,下次直接讀取緩存
是否在掃描額外的記錄。解決辦法:
使用explain進行分析,如果發現查詢需要掃描大量的數據,但只返回少數的行,可以通過如下技巧去優化:
使用索引覆蓋掃描,把所有的列都放到索引中,這樣存儲引擎不需要回表獲取對應行就可以返回結果。
改變數據庫和表的結構,修改數據表范式
重寫SQL語句,讓優化器可以以更優的方式執行查詢。
優化長難的查詢語句
一個復雜查詢還是多個簡單查詢
MySQL內部每秒能掃描內存中上百萬行數據,相比之下,響應數據給客戶端就要慢得多
使用盡可能小的查詢是好的,但是有時將一個大的查詢分解為多個小的查詢是很有必要的。
切分查詢
將一個大的查詢分為多個小的相同的查詢
一次性刪除1000萬的數據要比一次刪除1萬,暫停一會的方案更加損耗服務器開銷。
分解關聯查詢,讓緩存的效率更高。
執行單個查詢可以減少鎖的競爭。
在應用層做關聯更容易對數據庫進行拆分。
查詢效率會有大幅提升。
較少冗余記錄的查詢。
優化特定類型的查詢語句
count(*)會忽略所有的列,直接統計所有列數,不要使用count(列名)
MyISAM中,沒有任何where條件的count(*)非常快。
當有where條件時,MyISAM的count統計不一定比其它引擎快。
可以使用explain查詢近似值,用近似值替代count(*)
增加匯總表
使用緩存
優化關聯查詢
確定ON或者USING子句中是否有索引。
確保GROUP BY和ORDER BY只有一個表中的列,這樣MySQL才有可能使用索引。
優化子查詢
用關聯查詢替代
優化GROUP BY和DISTINCT
這兩種查詢據可以使用索引來優化,是最有效的優化方法
關聯查詢中,使用標識列分組的效率更高
如果不需要ORDER BY,進行GROUP BY時加ORDER BY NULL,MySQL不會再進行文件排序。
WITH ROLLUP超級聚合,可以挪到應用程序處理
優化LIMIT分頁
LIMIT偏移量大的時候,查詢效率較低
可以記錄上次查詢的最大ID,下次查詢時直接根據該ID來查詢
優化UNION查詢
UNION ALL的效率高于UNION
優化WHERE子句
解題方法
對于此類考題,先說明如何定位低效SQL語句,然后根據SQL語句可能低效的原因做排查,先從索引著手,如果索引沒有問題,考慮以上幾個方面,數據訪問的問題,長難查詢句的問題還是一些特定類型優化的問題,逐一回答。
SQL語句優化的一些方法?
1.對查詢進行優化,應盡量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。
2.應盡量避免在 where 子句中對字段進行 null 值判斷,否則將導致引擎放棄使用索引而進行全表掃描,如:
selectidfromtwherenumisnull可以在num上設置默認值0,確保表中num列沒有null值,然后這樣查詢:selectidfromtwherenum=
3.應盡量避免在 where 子句中使用!=或<>操作符,否則引擎將放棄使用索引而進行全表掃描。
4.應盡量避免在 where 子句中使用or 來連接條件,否則將導致引擎放棄使用索引而進行全表掃描,如:
selectidfromtwherenum=10ornum=20可以這樣查詢:selectidfromtwherenum=10unionallselectidfromtwherenum=20
5.in 和 not in 也要慎用,否則會導致全表掃描,如:
selectidfromtwherenumin(1,2,3)對于連續的數值,能用between就不要用in了:selectidfromtwherenumbetween1and3
6.下面的查詢也將導致全表掃描:select id from t where name like ‘%李%’若要提高效率,可以考慮全文檢索。
7. 如果在 where 子句中使用參數,也會導致全表掃描。因為SQL只有在運行時才會解析局部變量,但優化程序不能將訪問計劃的選擇推遲到運行時;它必須在編譯時進行選擇。然 而,如果在編譯時建立訪問計劃,變量的值還是未知的,因而無法作為索引選擇的輸入項。如下面語句將進行全表掃描:
selectidfromtwherenum=@num可以改為強制查詢使用索引:selectidfromtwith(index(索引名))wherenum=@num
8.應盡量避免在 where 子句中對字段進行表達式操作,這將導致引擎放棄使用索引而進行全表掃描。如:
selectidfromtwherenum/2=100應改為:selectidfromtwherenum=100*2
9.應盡量避免在where子句中對字段進行函數操作,這將導致引擎放棄使用索引而進行全表掃描。如:
selectidfromtwheresubstring(name,1,3)=’abc’,name以abc開頭的id應改為: selectidfromtwherenamelike‘abc%’
10.不要在 where 子句中的“=”左邊進行函數、算術運算或其他表達式運算,否則系統將可能無法正確使用索引。
問題27:簡述MySQL分表操作和分區操作的工作原理,分別說說分區和分表的使用場景和各自優缺點。
考點分析
分區表的原理
分庫分表的原理
延伸:
MySQL的復制原理及負載均衡
分區表的工作原理
對用戶而言,分區表是一個獨立的邏輯表,但是底層MySQL將其分成了多個物理子表,這對用戶來說是透明的,每一個分區表都會使用一個獨立的表文件。
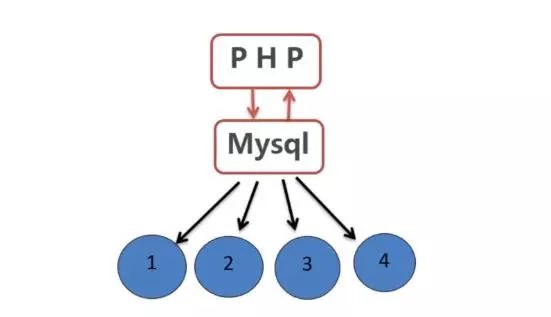
如圖所示:MySQL將表分成多個物理字表,但PHP客戶端并無感知,仍然認為操作的是一個表。
創建表時使用partition by子句定義每個分區存放的數據,執行查詢時,優化器會根據分區定義過濾那些沒有需要的數據的分區,這樣只需要查詢數據所在分區即可。
這樣子表相對于未分區的表來說占用空間小,數據量更小,因此操作速度更快。
分區的主要目的是將數據按照一個較粗的粒度分在不同的表中,這樣可以將相關的數據存放在一起,而且如果想一次性的刪除整個分區的數據也和方便。
適用場景
1、表非常大,無法全部存在內存,或者只在表的最后有熱點數據,其他都是歷史數據。
2、分區表的數據更易維護,可以對獨立的分區進行獨立的操作。
3、分區表的數據可以分布在不同的機器上,從而高效適用資源。
4、可以使用分區表來避免某些特殊的瓶頸
5、可以備份和恢復獨立的分區
限制
1、一個表最多只能有1024個分區
2、5.1版本中,分區表表達式必須是整數,5.5可以使用列分區
3、分區表字段如果有主鍵和唯一索引列,那么主鍵列和唯一索引列都必須包含進來
4、分區表中無法使用外鍵約束
5、需要對現有表的結構進行修改
6、所有分區都必須使用相同的存儲引擎
7、分區函數中可以使用的函數和表達式會有一些限制
8、某些存儲引擎不支持分區
9、對于MyISAM的分區表,不能使用load index into cache
10、對于MyISAM表,使用分區表時需要打開更多的文件描述符
分庫分表的工作原理
通過一些HASH算法或者工具實現將一張數據表垂直或者水平進行物理切分
適用場景
1、單表記錄條數達到百萬或千萬級別時
2、解決表鎖的問題
分表方式
水平分表:
表很大,分割后可以降低在查詢時需要讀的數據和索引的頁數,同時也降低了索引的層數,提高查詢次數
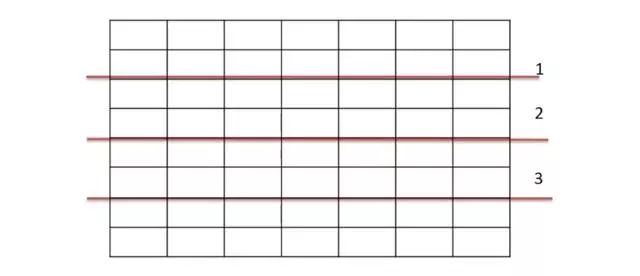
適用場景
1、表中的數據本身就有獨立性,例如表中分表記錄各個地區的數據或者不同時期的數據,特別是有些數據常用,有些不常用。
2、需要把數據存放在多個介質上。
水平切分的缺點
1、給應用增加復雜度,通常查詢時需要多個表名,查詢所有數據都需UNION操作
2、在許多數據庫應用中,這種復雜度會超過它帶來的優點,查詢時會增加讀一個索引層的磁盤次數
垂直分表
把主鍵和一些列放在一個表,然后把主鍵和另外的列放在另一個表中
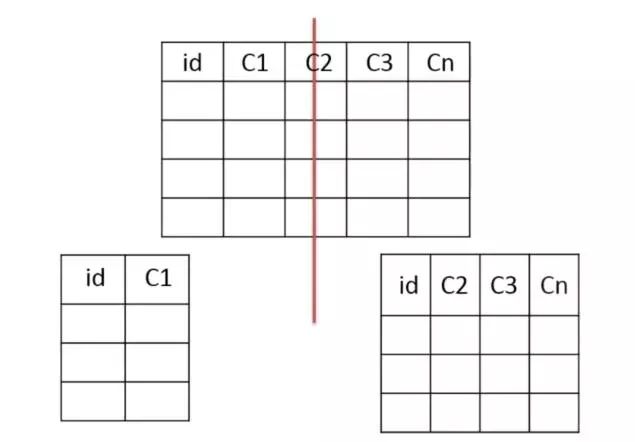
適用場景
1、如果一個表中某些列常用,另外一些列不常用
2、可以使數據行變小,一個數據頁能存儲更多數據,查詢時減少I/O次數
缺點
管理冗余列,查詢所有數據需要join操作
分表缺點
有些分表的策略基于應用層的邏輯算法,一旦邏輯算法改變,整個分表邏輯都會改變,擴展性較差
對于應用層來說,邏輯算法增加開發成本
MySQL的復制原理及負載均衡
MySQL主從復制工作原理
在主庫上把數據更高記錄到二進制日志
從庫將主庫的日志復制到自己的中繼日志
從庫讀取中繼日志的事件,將其重放到從庫數據中
MySQL主從復制解決的問題
數據分布:隨意開始或停止復制,并在不同地理位置分布數據備份
負載均衡:降低單個服務器的壓力
高可用和故障切換:幫助應用程序避免單點失敗
升級測試:可以用更高版本的MySQL作為從庫
解題方法
充分掌握分區分表的工作原理和適用場景,在面試中,此類題通常比較靈活,會給一些現有公司遇到問題的場景,大家可以根據分區分表,MySQL復制、負載均衡的適用場景來根據情況進行回答
問:28:設定網站用戶數量在千萬級,但是活躍用戶數量只有1%,如何通過優化數據庫提高活躍用戶訪問速度?
可以使用MySQL的分區,把活躍用戶分在一個區,不活躍用戶分在另外一個區,本身活躍用戶區數據量比較少,因此可以提高活躍用戶訪問速度。
還可以水平分表,把活躍用戶分在一張表,不活躍用戶分在另一張表,可以提高活躍用戶訪問速度。
問題29:SQL語句應該考慮哪些安全性?
考點分析
SQL查詢的安全方案
延伸:
MySQL的其它安全設置
SQL查詢的安全方案
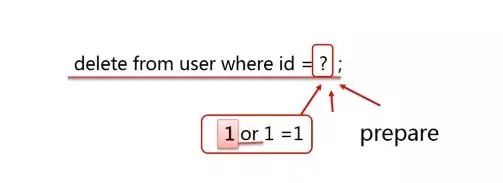
1、使用預處理語句防止SQL注入
deleteuserwhereid=?
2、寫入數據庫的數據一定要進行特殊字符轉義
3、查詢錯誤信息不要返回給用戶,將錯誤記錄到日志
注意:
PHP端盡量使用PDO對數據庫進行操作,PDO擁有對預處理語句很好的支持的方法,MySQLi也有,但是可擴展性不如PDO,MySQL函數在新版中已經趨向于淘汰,所以不建議使用,而且它沒有很好的支持預處理方法。
1、定期做數據備份
2、不給查詢用戶root權限,合理分配權限
3、關閉遠程訪問數據庫權限
4、修改root口令,不用默認口令,使用較復雜的口令
5、刪除多余的用戶
6、改變root用戶的名稱
7、限制一般用戶瀏覽其它庫
8、限制用戶對數據文件的訪問權限
解題方法
通常情況下,SQL安全的考點都在防SQL注入的問題,因此只要遇到此類考點,優先考慮SQL注入的防護手段。
問題30:為什么使用mysqli和PDO連接數據庫會比mysql連接數據庫更安全? mysqli和PDO支持預處理,可以防止SQL注入,mysql不支持預處理。
編輯:黃飛
-
數據庫
+關注
關注
7文章
3826瀏覽量
64507 -
觸發器
+關注
關注
14文章
2000瀏覽量
61221 -
字符串
+關注
關注
1文章
584瀏覽量
20553 -
MySQL
+關注
關注
1文章
817瀏覽量
26626 -
Doubler
+關注
關注
0文章
7瀏覽量
7201
原文標題:針對運維崗的mysql突擊面試題,可以怒刷這份總結~
文章出處:【微信號:浩道linux,微信公眾號:浩道linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
免費視頻教程:java經典面試題深度解析
java經典面試題深度解析


Java的經典面試題和答案詳細說明










 工商網監
工商網監
評論