 Innodb中的Btree實現(一)·引言&insert篇
Innodb中的Btree實現(一)·引言&insert篇
1 背景
Btree 自 1970 年 Bayer 教授提出后,一直是關系型數據庫中核心數據結構,基于多路的分叉樹,將數據范圍自上而下不斷縮小,直到需要的記錄,通常在數據庫中一個 Btree 結點能展開幾百上千個分叉,數據的搜索范圍呈指數級下降,極大地減少了數據訪存次數,提升搜索效率。對于 B-tree 的基礎操作,如插入、刪除、更新,以及分裂/合并等操作已有大量的文獻介紹,如果需要了解或有所疑問,可以參考文章末尾的參考文獻 [3]。在伴隨著高并發和需要考慮事務處理的數據庫系統下,Btree 索引往往需要考慮更為復雜的場景。本文深入 MySQL Innodb 引擎,介紹 Innodb 中 Btree 的組織形式以及操作數據的具體實現,著重考慮其在高并發訪問時,如何保證數據、Btree 結構的一致性,以及如何考慮事務的 ACID 特性。
2 索引組織表 (IOT)
Innodb 是一種行存的存儲引擎,一條記錄(record)對應于數據表中的一行,包含多個列(field),除了用戶自定義的 field 之外,Innodb 還會給每個 record 增加幾個隱藏 field:最新修改的事務 ID、用于回滾和 MVCC 構建舊版本的回滾指針、以及未定義主鍵時的 row ID。這里我們將能唯一識別一條記錄的前若干個 field 組合稱為 key fields,其余的 field 組合為 value fields。
數據庫的核心是高效組織和訪問數據,便于用戶快速檢索和修改數據,MySQL 目前的主流 Innodb 引擎,采用的是索引組織表的形式,顧名思義,將表的數據組織為 B-tree 的形式,如圖 1 所示,整個 btree 結構由多個結點組成,每個結點對應于真實物理文件的劃分的固定大小的 page,Innodb 中默認是 16 KB。表中所有數據記錄(data record,包含 key 和 value)有序存放在 b-tree 的葉子結點中,形成一個遞增的 record 列表,非葉子結點存有 child 結點 key 的最小值以及 child 節點的 page 號 (index record,包含 key 和 page no),通過 page 號能從數據庫緩存系統(buffer pool)中快速定位到 child 節點,這個包含所有數據的 Btree 也被稱為主鍵索引(或者聚集索引),數據庫每創建一張表,默認就是生成了一顆主鍵索引 btree。
對于二級索引,會生成一顆新的 btree,使用主鍵索引 value 中的某些 field 作為新的 btree 的 key,主鍵索引的 key 作為新的 btree 的 value,先從二級索引定位到主鍵索引的 key,再回主鍵索引拿到完整的記錄,避免當以主鍵索引的 value 作為搜索條件時進行全表掃描的開銷,提高搜索效率。
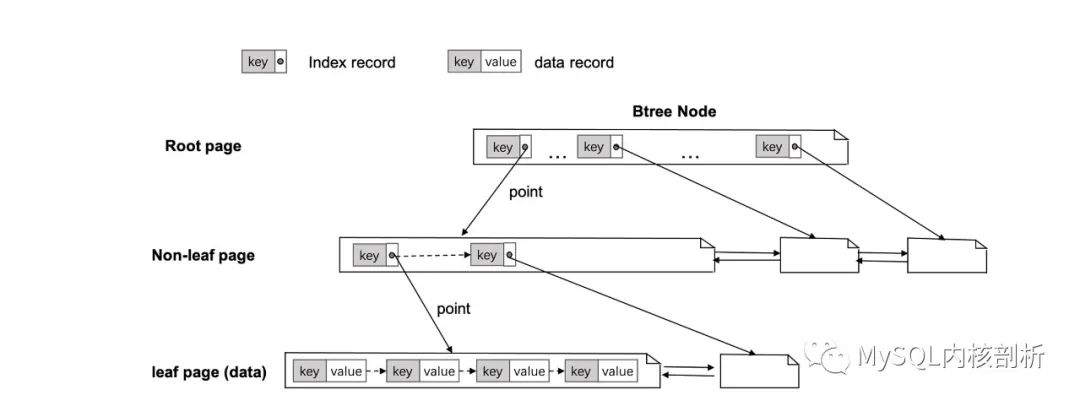
圖 1: Innodb 的索引組織表形式
3 索引頁和行結構
在 Innodb 中,對于任何數據的查詢和修改,最終都是落在磁盤物理文件的訪問操作中。簡單來說,是通過 btree 定位到具體的物理 page,對 page 內部的 record 進行增刪改查。Btree Page 內部本身可以看作一個有序的 record 單向鏈表,通過一些元信息對 16 KB 的物理空間進行高效管理和組織。每個 Page 中存在兩個特殊的 record:infimum record 和 supremum record,分別代表 page 中 record 的無窮小和無窮大,位于 record 鏈表的頭和尾。如圖 2 所示,在 record 鏈表上,每間隔幾個 record 會選取一個 record 作為 directory slot,這樣查找時先二分搜索定位到具體的 slot,在 slot 進一步線性搜索定位到具體的 record。默認初始時,存在兩個 directory slot,分別指向 infimum 和 supremum,隨著 page 中 record 不斷插入和刪除,directory slot 的數目也會動態變化。

圖 2: direction slot
Innodb Btree 中無論是葉子結點,還是非葉子結點,都有著相同 page 和 record 格式,圖 3 給出了 Innodb 中索引 page 和 record 的物理格式(page_t 和 rec_t),對于 page 可以分為四個部分:page 本身的元信息、用于 btree 和 record 組織的索引元信息、record 空間和 directory slot 空間。
Page Header 和 Page Tail:包含 page 的元信息,如最新修改全局的日志序號(LSN)信息、維護同一層 Btree 的 page 的相鄰 page 號,以及 page 的校驗 checksum 信息等。
Index Header:這塊是索引 page 的元信息,包含 page 內 directory slot 的數目,目前還未分配給 record 使用的空間偏移(Heap top),目前已經分配的 rec 數目(包含有效或者被回收的 rec),用于復用的 Free record List (最后被刪除的 record 的偏移),page 內部有效的 record 數目(n_recs),以及當前 page 在 Btree 中的層級 (level,Btree 的葉子結點是第 0 層)。
record 空間:從 94 byte 往后就是 innodb page 存放 record 的區域,依此存放 infimum、supremum,用戶 record 集合,以及還未分配的空間。
directory 空間:存放 directory slot 數組以及其指向的 record,所有 directory slot 是逆序存放的。
record 空間中存的就是上層用戶寫入的一行行記錄 (rec_t),Innodb 中有兩種行格式,Compact 和 Redundant 格式,MySQL 5.1 之后默認提供 Compact 格式了,本文也主要介紹 Compact 格式的 record。Record 主要分為兩部分:Header 部分和 data 數據部分。
Header 元信息,在代碼中以 Extra data 形容:首先是變長列的長度數組,這是按列的順序存儲的。第二部分存了行中為 NULL 的記錄的 bitmap,這個 bitmap 的大小由索引元信息中最多允許多少個 NULL 的記錄決定。后面多個字段決定當前 record 的狀態,delete mark 標記當前 record 是否被刪除(Innodb 中用戶刪除 record 都是標記刪除,真正物理刪除是由后臺 purge 線程觸發,保證沒有其他用戶并發訪問時執行)。Min rec flag 標記當前 record 是否是非葉子層的最小值,使得搜索小于 btree 所有行時,能夠定位在最小的葉子結點上。
N_owned 是用于作為 directory slot 指向的 record 使用,說明了當前 directory slot 包含的 record 數目,用于判斷是否需要分裂或者收縮 directory slot。Page 中整個 record 空間是一個堆,每分配一個新的 Record,都會分配一個 heap no,這個 heap no 在事務系統中也用于唯一確定 page 內部 一個行鎖對象。Status 標識了當前 record 狀態:data record(ORDINARY)/ index record(NODE_PTR)/ INFIMUM / SUPREMUM。Next 指向 record 鏈中下一 record 在 page 內部的偏移。
data 數據部分:這是用戶數據真正存儲的位置,首先是 key fields,用于 record 的比較,唯一確定一個 record 在 Btree 的位置。Trx ID 和 Roll ptr 分別是最新修改的事務 ID 以及用于回滾和 MVCC 構建版本的回滾指針。后面的 Value fields 則是非 key 的列數據。
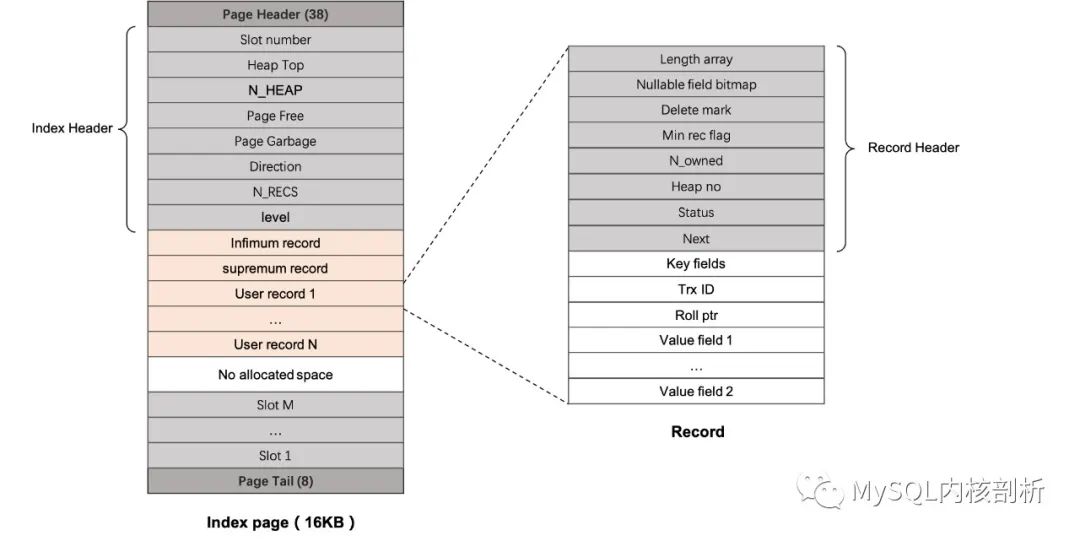
圖 3: Innodb 的索引頁和行結構
4 cursor 搜索
用戶通過 SQL 下發操作的指令和要操縱的數據,通過 MySQL server 層的解析,在傳入 innodb 引擎層時,會將需要操作的記錄轉換成 InnoDB 內存的記錄格式(dtuple),以及表中具體行的增、刪、改、查操作。dtuple 格式的內容比較直接,和 rec_t 中的數據部分是一致的,在操作時臨時分配創建的。要操作一個表的數據,首先要通過 dtuple 中的 key fields 和邏輯上 btree 定位到數據存儲的物理位置 (rec_t),這在 innodb 通過 cursor 搜索來實現的,每次 open 一個 cursor 都會開啟一個從 btree root 結點搜索到指定層級的 record 的搜索過程。
在搜索時指定搜索模式(search_mode),并發控制的加鎖模式(latch_mode) 以及 搜索過程的行為(flag)。Innodb 中 search mode 是考慮到在 page 內部進行二分查找時定位在哪個 record,考慮到不同 record 的查找需求,有以下 4 種。:
PAGE_CUR_G: > 查詢,查詢第一個大于 dtuple 的 rec_t
PAGE_CUR_GE: >=,> 查詢,查詢第一個大于等于 dtuple 的 rec_t
PAGE_CUR_L: < 查詢,查詢最后一個小于 dtuple 的 rec_t
PAGE_CUR_LE: <= 查詢,查詢最后一個小于等于 dtuple 的 rec_t
插入操作的 search_mode 默認是 PAGE_CUR_LE,即插在最后一個小于等于該 dtuple 的 rec_t 后。
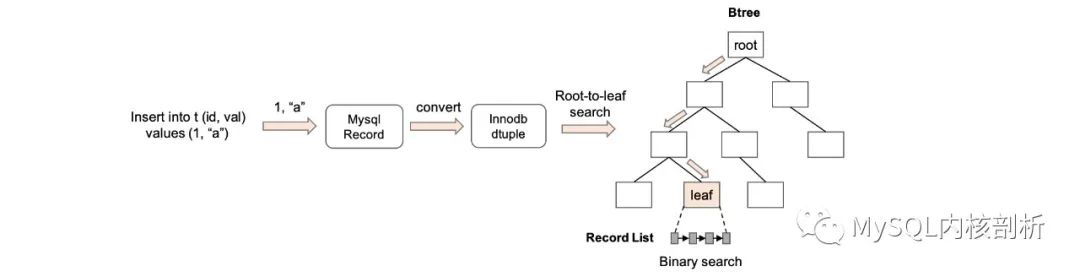
圖 4: Cursor 定位流程
cursor 搜索整個核心操作在 btr_cur_search_to_nth_level 中。這個函數較為復雜,省去 AHI 和 spatial index 以及下一節介紹的并發控制邏輯,主要流程是:
從 dict_index_t 元信息中拿到 root page 在物理文件的 page no(默認是 4)。
從 buffer_pool 中根據 page no 拿 page(buf_page_get_gen),buffer pool 模塊會根據 page 是否被緩存來決定是從內存中還是磁盤中讀取,并根據加鎖策略對 page 加鎖。
對 page 內部的 record list 進行二分搜索 (page_cur_search_with_match),Innodb 的二分搜索是在圖 2 中 directory slot 指向 record 進行的,先定位到相鄰的兩個 slot,在兩個 slot 范圍內進行線性搜索將 dtuple 與 rec_t 逐個進行比較,確定小于和大于等于 dtuple 的相鄰 rec_t(low_rec 和 up_rec),并將 low_rec 和 up_rec 匹配的 fields 數記錄下來(low_match 和 up_match),最后根據 search_mode 進行選取 rec_t。
如果沒有到達指定 level,當前一定會是非葉子結點,會從 rec_t 提取 child page 所在的 page_no,重走步驟 2,直到到達指定 level.
在 cursor 搜索過程中,會根據上層指定的 flag,觸發 cursor 搜索過程的行為,主要分為幾種類型:
insert buf 相關,包括 BTR_INSERT、BTR_DELETE_MARK、BTR_DELETE 等,在二級索引回表時指定,如果主鍵索引葉子結點不在內存中,緩存相應操作,按一定頻率合并寫入主鍵索引的 page 中,避免頻繁的隨機 IO 開銷。
lock intention 相關,包括 BTR_LATCH_FOR_INSERT、BTR_LATCH_FOR_DELETE,正常 innodb 在搜索到 leaf page 時,會把上層的鎖都放了,而這兩種類型在某些場景需要保留上層鎖,如對于 insert,如果因當前 page 滿了要插入到右 page 的第一個 record,會觸發上層的 delete。對于 delete,如果刪除 page 第一個 record,會觸發上層 page 的 insert。
BTR_ESTIMATE:在 range scan 時會估計 range 范圍內的 record,此時會保留 cursor 搜索路徑的所有 page 信息,用于估計計算。
BTR_MODIFY_EXTERNAL:當處理 Blob 字段類型涉及到外部 page 時需要特殊處理[5],對整個 index 會加 sx 鎖。
cursor 搜索的結果在 Innodb 是可以復用,持久化為 persist cursor(pcur),避免未修改時的重復搜索開銷,這塊內容我們將在 select 篇繼續介紹。
5 并發控制
對于一個需要支持大量并發業務的實時事務處理 OLTP 系統而言,并發控制策略成了數據庫 btree 實現的關鍵,在多線程并發搜索、查詢、修改過程中,保持 Btree 結構的一致性。Innodb 中對于 btree page 的操作都被包含在一個 mini-transaction(mtr)中,用戶線程操作 btree 前開啟一個 mtr,在操作 btree 過程中,將訪問的 page 指針、請求的鎖 latch、以及產生的 redo log 分別掛在 mtr 上,當操作流程結束提交 mtr 時,將 redo log 同步到全局 log buffer 中,將臟頁加入 flush list 上,最后釋放所有持有的 latch。真正修改只有在 mtr commit 提交,redo 落盤才生效,因此 mtr 的實現將上層對記錄的操作可以看作一個對 btree 的原子操作,也是 cursor 搜索并發控制的基本單位。

圖 5: lifecycle of mini-transaction (mtr)
Innodb 對于 btree 修改的保證還是基于鎖 latch 實現的,訪問任何一個 page 內容都需要持有其 latch,讀加 S 鎖,寫加 X 鎖。除此之外,還有一種 SX 鎖類型,與 S 鎖兼容,與其他 SX 和 X 鎖互斥,獨占寫權限但允許讀。同時為了保證因 page 滿或者稀疏而分裂或合并引起 btree 結構發生變化時的正確性,Innodb 還有一把整個 index 的全局 latch,在 dict_index_t 元信息中。
Btree 是樹狀組織的數據結構,在訪問加 latch 需要滿足一定順序,才能防止死鎖。然而保證加鎖順序的同時,還需要盡可能減少 latch 持有的范圍,提高訪問并發度。Innodb 經過多年的發展,在 btree latch 上的也做了大量的優化。文章 [4] 對于 innodb btree latch 的發展做了全面的概述,本文不再展開敘述,主要介紹在 MySQL 8.0 版本 btree latch 的機制。整體上遵守自頂向下,自左向右的訪問策略,因此如果要訪問一個 page 的 上層 page 或者 左邊(prev)page,都需要從 root 結點開始重新遍歷搜索。
對于讀操作(BTR_SEARCH_LEAF),不會引起 btree 結構發生變化,對 index latch 加 S 鎖,一路順著 cursor 搜索路徑,沿路對 page 加 S 鎖,直到達 leaf page。
對于修改操作時,分為兩種情況,認為當前修改不影響 btree 結構的樂觀修改(BTR_MODIFY_LEAF)、以及認為當前修改會使得 btree 結構發生變化的悲觀修改(BTR_MODIFY_TREE),兩種搜索加鎖策略的粒度是不同的,如圖 6 所示。
樂觀修改和讀操作類似,會對 index latch 加 S 鎖,一路順著 cursor 搜索路徑,沿路對 page 加 S 鎖,到 leaf page 加 X 鎖進行修改即可。
悲觀修改加鎖更為復雜,首先對 index latch 加 SX 鎖,即此時僅允許一個悲觀修改訪問 btree,但允許并發的讀操作和樂觀修改。順著 cursor 搜索路徑,初始時不對沿路 page 加鎖(此時其他訪問不可能修改非葉子 page),當訪問到 leaf page 的 parent 時,會對進行兩層判斷,如果修改會及聯修改 parent 的父結點以上,這時到達 leaf page 時會將沿路的 page 重新加上 X 鎖,如果 btree 的修改僅限于 parent,這時僅將 parent 的鎖加上。當到達 leaf page 時,會將 leaf page 及其前后的 page 都加上 latch (需要修改前后 page 的指向)。
對于悲觀修改,會遞歸修改上層 page(BTR_CONT_MODIFY_TREE),因為第一次悲觀修改已經加好鎖,再次搜索是無需對 page 加鎖。
在 Innodb 中,某些場景需要獲取某個 dtuple 的前一個 page (BTR_SEARCH_PREV 和 BTR_MODIFY_PREV),例如向前 range scan 需要跨 page 到前一個 record 時。由于加鎖順序問題,無法在持有當前 page 的 latch 拿去 previous page 的 latch,因此需要從 btree root 重新遍歷,在持有 previous page 的 parent 的 latch 的情況下,釋放當前 page 的 latch,獲取 previous 的 page 的 latch。這里遍歷加鎖時候,還要特殊處理 previous page 和 當前 page 不在同一個 parent 的情況。
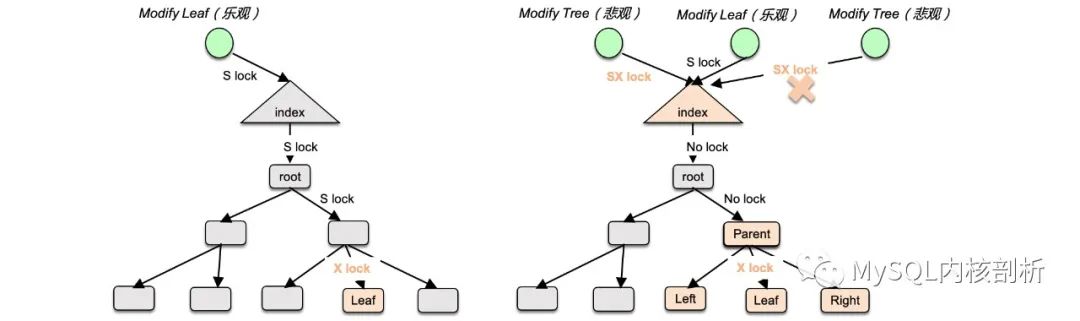
圖 6: 樂觀修改加鎖路徑(左)、悲觀修改加鎖路徑(右)
6 Insert 路徑解析
介紹完 Innodb 中 Btree 組織形式、搜索和并發控制策略,我們此時來看 Innodb 中 btree 是如何插入一條數據的。Innodb 在插入時需要對主鍵索引和二級索引分開考慮,先插入主鍵索引,再插入二級索引。
整個插入流程函數在 row_ins 中,插入前會先判斷主鍵索引是否 unique(即是否定義主鍵),不是則會先分配 row id 來唯一標識一條 record。
無論主鍵索引還是二級索引,都需要先構建插入的完整行記錄的內存版本(row,dtuple type),再基于 row 和各個索引(dict_index_t)的列信息構建真正需要插入索引中存儲的版本(entry,dtuple type),進行 cursor 搜索定位到最后一個小于等于該 dtuple 的 rec_t 后,從 page 內部申請空間插入 entry 的內容。
6.1 主鍵索引的 insert 路徑
主鍵索引的插入流程在 row_ins_clust_index_entry 函數中,先進行加鎖范圍更小的樂觀插入流程,如果插入失敗(page 空間不足),會進行悲觀插入流程,加鎖范圍更大,并觸發結點分裂流程,這也和 cursor 的樂觀悲觀搜索相對應。
控制樂觀和悲觀插入流程在 row_ins_clust_index_entry_low 中,根據 latch_mode 進行判斷,每次都開啟一個新的 mtr 流程,我們先看樂觀插入:
先進行樂觀 cursor 搜索(BTR_MODIFY_LEAF),定位到 leaf page 的 rec_t 中。
duplicate check: 檢查定位的 rec_t 是否和要插入的 entry 相等,存在重復,會將可能相等的 record 都加上事務鎖(普通 insert 加 S lock,insert on duplicate key update 則加 X lock,gap mode 取決于事務隔離級別),保證不被其他事務修改。如果 rec_t 不是 delete mark,向上層返回 duplicate key 錯誤,如果是 delete mark,將插入流程轉為 update-in-place 覆蓋寫入(row_ins_clust_index_entry_by_modify)。
否則進入樂觀插入(btr_cur_optimistic_insert),首先會計算插入 entry 空間,先判斷 page 中 free list 空間是否足夠,free list 空間不夠,再判斷 page 中未分配的堆的空間,如果還是不夠,會判斷 reorganize page 后的空間(整理 page 內部的空間碎片),如果存在空閑空間,將 entry 內容 copy 到申請的 rec_t 中,并更新 rec_t 和 page 的元信息,否則會進行悲觀插入。
真正插入 entry 前,會檢查事務鎖和記錄 undo(btr_cur_ins_lock_and_undo),檢查事務鎖 (lock_rec_insert_check_and_lock) 會判斷 cursor 定位的下一個 rec_t 上當前有沒有鎖,有的話加上帶有 gap 的插入意向的 X 鎖(LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION )的顯示鎖,來等待其他 gap 鎖釋放,確保要插入的區間沒有其他事務訪問。同時每一條 Insert 的 rec_t 上都默認有一個隱式鎖,它是通過 trx_id 和當前活躍事務數組的 id 來檢測的,這么做減少了 lock_sys 的操作,提升性能[6]。為了保證事務回滾,插入 entry 前會記錄一條 insert 類型的 undo(trx_undo_report_row_operation),將 entry 的 key fields 寫入 undo page 中,便于回滾時找到 record 的位置,并根據 undo page 的 id 和 offset 構建出回滾指針存入插入的 rec_t 中[7]。
在寫入 entry 之后,會向 mtr 的 log buf 記錄 redo log (page_cur_insert_rec_write_log),用于 WAL 故障恢復,通常一條 insert 的 redo log 會記錄 page 和 index 信息,以及和 cursor 定位的 rec_t 相比的差異部分(btree的有序特性,相鄰的 record 相同部分較多,減少存儲的 redo log 大小):
(Page ID, offset) + (len of each field) + (extra info) + (bytes which differs from cursor record)
6.2 結點分裂
如果 cursor 搜索到的 leaf page 剩余空間不足以容納待插入的 entry,會觸發悲觀插入流程,騰出插入的空間:
先進行悲觀的 cursor 搜索流程,將涉及的 page 的 latch 都加上。
檢查事務鎖和記錄 undo。
進行結點分裂,最后將 entry 插入到分裂后的 page 中,寫 redo。
整個結點分裂過程在 btr_page_split_and_insert 中,如圖 7 所示,主要是:
選擇原 page 的分裂點 (split_rec)。
生成新 page,將原 page 的部分 record list 批量 move 到新 page 中,這里會寫 move 相關的 redo(包括原 page 的 delete 和新 page 的 insert)。
修改前后 page 的指針指向、在 parent page 新增一個 index record 指向新 page(觸發新的插入流程)。
根據 entry 和 split_rec 的大小關系,將 entry 插入到原 page 或者新 page 中的一個。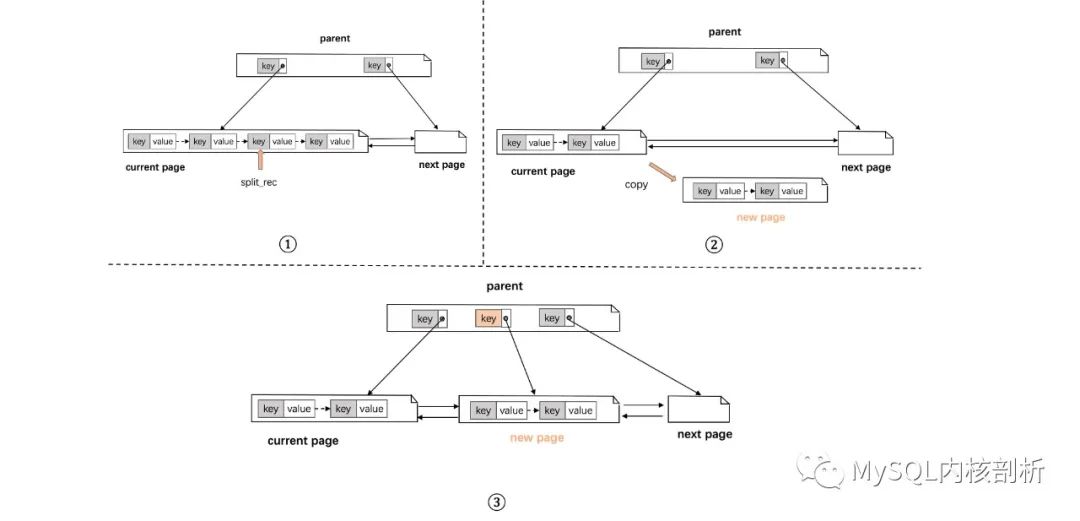
圖 7: 結點分裂流程
原 page 的分裂點的選擇,為了性能考慮,Innodb 采用了兩種策略[8]:
將原始頁面中 50% 數據移動到新頁面,這是最普通的分裂方法。
為了優化上述中間點分裂在順序插入場景的問題,InnoDB 實現了在插入點分裂的方法,在每個 page 上記錄上次插入位置 (PAGE_LAST_INSERT),以此判斷本次插入是否遞增或者遞減,如果判定為順序插入,就在當前插入點進行分裂。
6.3 二級索引的 insert 路徑
前面介紹二級索引由主鍵索引的部分 value fields 作為 sk(secondary key),主鍵索引的 pk (primary key) 作為 value。二級索引的插入流程整體和主鍵索引相差不大,可以參考主鍵索引流程,但存在以下幾個區別:
duplicate check:二級索引 unique 性質是由 sk 決定的,而和主鍵索引不同,二級索引覆蓋一個 delete mark 的 rec_t,需要滿足所有 fields 都相等(sk + pk),因此對于一個 unique 的二級索引,可能存在多個被 delete-mark 的相同 sk 不同 pk 的 rec_t,并且跨多個 page。在搜索時,為了保證 unique 性質,需要把所有被 delete-mark 的 rec_t 以及第一個 sk 不相同的 rec_t 都加上 next-key 鎖(gap 鎖加在下一個 rec),阻止其他事務插入相同的 sk 的 record 造成 unique 不一致。
由于插入都是以 PAGE_CUR_LE 模式插入,所以插入時候搜索會定位到最后一個相等 sk 的 rec_t 上,然而由于相等 rec_t 可能跨 page,為了符合加鎖順序,在 duplicate check 的時候,會把上一個 mtr 提交,開啟一個以 PAGE_CUR_GE 模式的 cursor 搜索過程來加 gap 鎖。
由于 gap 鎖加了第一個與 sk 不相同的 rec_t,當這中間的 gap 很大時,會造成即使在 RC 隔離級別下,也會很容易發生死鎖問題,也是官方遺留很多年的問題,這在文章 [9] 有很好的例子、解釋以及方案討論,感興趣的可以仔細閱讀。
二級索引不需要通過記錄 undo 來支持事務回滾和 MVCC 一致性讀。
7 總結
本文介紹了以下幾個方面:btree 的背景、Innodb 中 btree 的組織形式,包括索引組織表邏輯形式以及 btree 索引頁和記錄的物理格式。接下來介紹了從 Innodb 中定位 record 的方法和如何保證 btree 的一致性,包括了 cursor 搜索邏輯和并發控制流程。最后介紹了 Innodb 整個 insert 路徑,以及如何考慮其他模塊如 事務鎖、undo、redo、BP 等。btree 索引是數據庫的核心,是直接操縱數據的模塊,通過 btree 來看 Innodb,對整個數據庫都會有更深層次的理解。
審核編輯:劉清
-
MySQL
+關注
關注
1文章
817瀏覽量
26629 -
Cur
+關注
關注
0文章
3瀏覽量
7058 -
MVCC
+關注
關注
0文章
13瀏覽量
1481
原文標題:Innodb 中的 Btree 實現 (一) · 引言 & insert 篇
文章出處:【微信號:inf_storage,微信公眾號:數據庫和存儲】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Altera_FPGA_CPLD設計_基礎篇&高級篇
Linux命令 &與&&的作用
單片機STC15雙機通信&異步串行通信&Proteus

單片機STC15雙機通信&異步串行通信&Proteus
詳細總結下InnoDB存儲引擎中行鎖的加鎖規則
如何區分Java中的&amp;和&amp;&amp;
if(a==1 &amp;&amp; a==2 &amp;&amp; a==3),為true,你敢信?

HarmonyOS &amp;amp;amp;潤和HiSpark 實戰開發,“碼”上評選活動,邀您來賽!!!

你使用shell腳本中的2&gt;&amp;1了嗎?
攝像機&amp;amp;雷達對車輛駕駛的輔助
FS201資料(pcb &amp; DEMO &amp; 原理圖)
onsemi LV/MV MOSFET 產品介紹 &amp;amp; 行業應用

北美運營商AT&amp;amp;T認證中的VoLTE測試項






 工商網監
工商網監
評論