 如何快速部署邊緣就緒的機器學習應用
如何快速部署邊緣就緒的機器學習應用
作者:Stephen Evanczuk
機器學習 (ML) 為創造智能產品提供了巨大的潛力,但神經網絡 (NN) 建模和為邊緣創建 ML應用非常復雜且困難,限制了開發人員快速交付有用解決方案的能力。雖然現成的工具使 ML 模型的創建在總體上更加容易,但傳統的 ML 開發實踐并不是為了滿足物聯網(IoT)、汽車、工業系統和其他嵌入式應用解決方案的獨特要求而設計的。
本文首先對 NN 建模進行簡要介紹,然后介紹并描述如何使用 NXP Semiconductors 的綜合 ML 平臺讓開發人員更有效地交付邊緣就緒的 ML應用。
NN 建模快速回顧
ML算法為開發人員提供了截然不同的應用開發選擇。開發人員不是編寫軟件代碼來明確解決諸如圖像分類等問題,而是提供一組數據——例如標注了所含實體的真實名稱(或類別)的圖像——來訓練NN 模型。訓練過程使用各種方法來計算模型的參數,即每個神經元和每層的權重和偏置值,使模型能夠對輸入圖像的正確類別提供相當準確的預測(圖 1)。
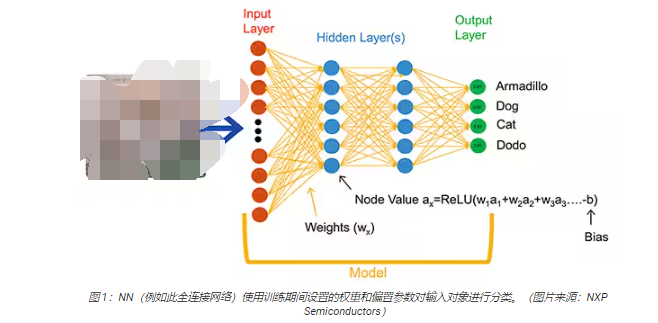
除圖 1 所示的通用全連接 NN 外,ML 研究人員還發展了范圍廣泛的 NN 架構。例如,圖像分類應用通常利用一種專門的架構——卷積神經網絡(CNN),它將圖像識別分成兩個階段:初始階段查找圖像的關鍵特征,分類階段預測它可能屬于訓練期間確定的多個類別中的哪一類(圖 2)。

盡管只有 ML
專家能夠選擇適當的模型架構和訓練方案,但多種開源和商用工具的出現極大地簡化了大規模部署的模型開發。如今,開發人員使用幾行代碼便可定義模型(清單1),然后利用開源 Netron 模型查看器等工具生成模型的圖形表示(圖 3),以檢查每一層的定義和連接。
def model_create(shape_in, shape_out):
from keras.regularizers import l2
tf.random.set_seed(RANDOM_SEED)
model = tf.keras.Sequential()
model.add(tf.keras.Input(shape=shape_in, name=‘acceleration’))
model.add(tf.keras.layers.Conv2D(8, (4, 1), activation=‘relu’))
model.add(tf.keras.layers.Conv2D(8, (4, 1), activation=‘relu’))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.MaxPool2D((8, 1), padding=‘valid’))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(64, kernel_regularizer=l2(1e-4),
bias_regularizer=l2(1e-4), activation=‘relu’))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(32, kernel_regularizer=l2(1e-4),
bias_regularizer=l2(1e-4), activation=‘relu’))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(shape_out, activation=‘softmax’))
model.compile(optimizer=‘adam’, loss=‘categorical_crossentropy’,
metrics=[‘acc’])
return model
清單 1:開發人員只需使用幾行代碼便可定義 NN 模型。(代碼來源:NXP Semiconductors)

對于最終部署,其他工具會剝離僅訓練期間需要的模型結構,并執行其他優化以創建高效的推理模型。
為智能產品開發基于 ML 的應用為什么如此困難
為物聯網或其他智能產品定義和訓練模型,與為企業級機器學習應用創建模型的工作流程相似。然而,盡管相似,但為邊緣開發 ML應用存在多種額外的挑戰。除模型開發外,設計人員還面臨一些常見的挑戰,即開發所需的主應用以運行其基于微控制器 (MCU) 的產品。因此,將 ML引入邊緣需要管理兩個相互關聯的工作流程(圖 4)。

雖然嵌入式開發人員熟悉 MCU 項目的工作流程,但當開發人員努力創建一個優化的 ML 推理模型時,ML 項目會對基于 MCU的應用提出額外的要求。事實上,ML項目會極大地影響嵌入式設備的要求。模型執行通常涉及繁重的計算負載和存儲器需求,這可能超出了物聯網和智能產品中使用的微控制器資源的能力。為了減少資源需求,ML專家會運用各種技術,例如:模型網絡修剪、壓縮、量化到較低精度,甚至使用單比特參數和中間值,以及其他方法。
然而,即使采用這些優化方法,開發人員仍可能發現常規微控制器在處理與 ML 算法相關的大量數學運算方面性能不足。另一方面,使用高性能應用處理器可以處理 ML計算負載,但這種方法可能導致延遲增加和非確定性響應,影響其嵌入式設計的實時特性。
除了硬件選擇方面的挑戰,為邊緣提供優化的 ML 模型還存在嵌入式應用開發所特有的額外挑戰。為企業級 ML應用開發的大量工具和方法,可能無法很好地擴展到嵌入式應用開發人員的應用和工作環境中。即使經驗豐富的嵌入式應用開發人員,為了能夠快速部署基于 ML的設備,也可能需要在大量可用的 NN 模型架構、工具、框架和工作流程中竭力尋找有效的解決方案。
NXP 解決了邊緣 ML 開發的硬件性能和模型實現兩方面的問題。在硬件層面,NXP 的高性能 i.MX RT1170 跨界微控制器滿足了邊緣 ML的廣泛性能要求。為了充分利用這一硬件基礎,NXP 的 eIQ(邊緣智能)ML 軟件開發環境和應用軟件包提供了一種高效解決方案以創建邊緣就緒的 ML應用,它既適合沒有經驗的 ML 開發人員,也適合 ML 開發專家。
用于開發邊緣就緒 ML 應用的高效平臺
NXP 的 i.MX RT 跨界處理器兼具傳統嵌入式微控制器的實時、低延遲響應與高性能應用處理器的執行能力。NXP 的 i.MX RT1170跨界處理器系列集成了高能效 Arm?Cortex?-M4 和高性能 Arm Cortex-M7處理器,以及運行嚴苛應用所需的大量功能塊和外設,包括嵌入式設備中基于 ML 的解決方案(圖 5)。

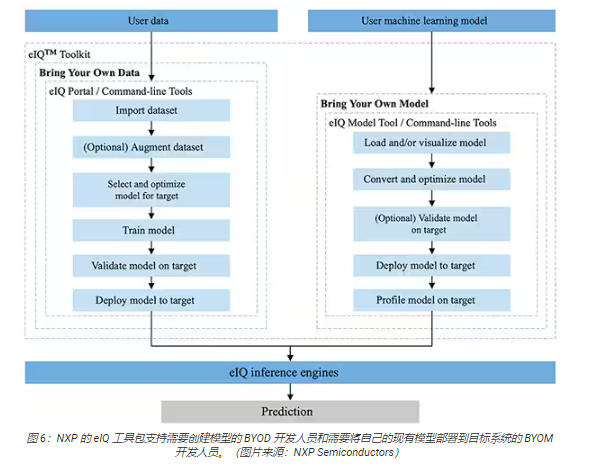
NXP 的 eIQ 環境完全集成到 NXP 的 MCUXpresso SDK 和 Yocto 開發環境中,專門用于促進在利用 NXP微處理器和微控制器構建的嵌入式系統上實現推理模型。eIQ 環境中包含 eIQ 工具包,后者通過多個工具支持“自帶數據”(BYOD) 和“自帶模型”(BYOM)工作流程,這些工具包括 eIQ Portal、eIQ Model Tool 和命令行工具(圖 6)。
eIQ Portal 旨在同時支持 ML 模型開發專家和新手開發人員的 BYOD 工作流程,它提供了一個圖形用戶界面(GUI),以幫助開發人員更輕松地完成模型開發工作流程的每個階段。
在開發的初始階段,eIQ Portal 的數據集管理工具幫助開發人員導入數據,從連接的相機中捕獲數據,或從遠程設備中捕獲數據(圖 7)。

開發人員使用數據集管理工具給數據集中的每個項目添加注釋或標記,既可標記整幅圖像,也可只標記指定邊界框內包含的特定區域。擴展功能通過使圖像模糊、添加隨機噪聲、更改特征(如亮度或對比度)及其他方法,幫助開發人員為數據集提供所需的多樣性。
在下一階段,eIQ Portal幫助開發人員選擇最適合應用的模型類型。對于不確定模型類型的開發人員,模型選擇向導會根據應用類型和硬件基礎引導開發人員完成選擇過程。如果已經知道自己需要的模型類型,開發人員可以選擇eIQ 安裝時提供的自定義模型或其他自定義實現方法。
eIQ Portal 引導開發人員完成下一關鍵訓練步驟,并提供一個直觀的圖形用戶界面,以便用戶修改訓練參數和查看模型預測精度隨每個訓練步驟的變化(圖8)。

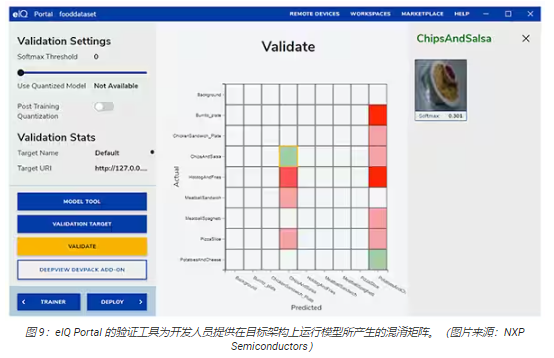
在下一步,eIQ Portal GUI幫助開發人員驗證模型。在此階段,模型轉換至目標架構上運行,以確定其實際性能。完成驗證后,驗證屏幕會顯示混淆矩陣——這是一個基本的 ML驗證工具,允許開發人員將輸入對象的實際類別與模型預測的類別進行比較(圖 9)。
對于最終部署,該環境允許開發人員根據處理器選擇目標推理引擎,包括:
Arm CMSIS-NN(通用微控制器軟件接口標準,神經網絡)— 為在 Arm Cortex-M處理器內核上實現神經網絡的性能最大化和內存占用最小化而開發的神經網絡內核
Arm NN SDK(神經網絡,軟件開發套件)— 一套工具和推理引擎,用于在現有神經網絡框架和 Arm Cortex-A 處理器之間搭建橋梁等
DeepViewRT — 用于 i.MX RT 跨界 MCU 的 NXP 專有推理引擎
Glow NN — 基于 Meta 的 Glow (graph lowering) 編譯器,由 NXP 針對 Arm Cortex-M 內核進行優化,使用CMSIS-NN 內核的函數調用或 Arm NN 庫(如有),或者從其自身的本地庫編譯代碼
ONXX Runtime — Microsoft Research 的工具,旨在針對 Arm Cortex-A 處理器優化性能
用于微控制器的 TensorFlow Lite — TensorFlow Lite 的較小版本,為在 i.MX RT 跨界 MCU上運行機器學習模型而優化
TensorFlow Lit — TensorFlow 的一個版本,為較小系統提供支持
對于 BYOM 工作流程,開發人員可以使用 eIQ Model Tool 直接進入模型分析和每層時間剖析。對于 BYOD 和 BYOM工作流程,開發人員可以使用 eIQ 命令行工具訪問工具功能以及非直接通過 GUI 提供的 eIQ 特性。
除了本文描述的特性外,eIQ 工具包還支持一系列廣泛的功能,包括遠遠超出本文范圍的模型轉換和優化。然而,為了快速開發邊緣就緒 ML應用的原型,開發人員通常可以快速完成開發和部署,幾乎不需要使用 eIQ 環境中許多較復雜的功能。事實上,NXP 的專業應用軟件 (App SW)包提供了完整的應用,開發人員可以使用這些應用立即開展評估,或將其作為自己定制應用的基礎。
如何使用應用軟件包快速評估模型開發
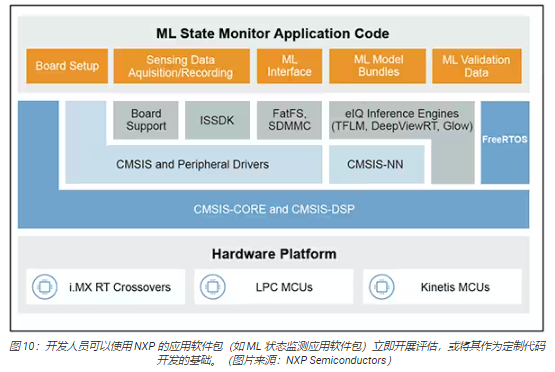
NXP 的應用軟件包集生產就緒的源代碼、驅動程序、中間件和工具于一體,提供完整的基于 ML 的應用。例如,NXP 的 ML狀態監測應用軟件包為基于傳感器輸入確定復雜系統的狀態這一常見問題提供了一個基于 ML 的快速解決方案(圖 10)。
ML 狀態監測應用軟件包實現了一個完整的應用解決方案,可檢測風扇工作在四種狀態中的哪一種狀態:
ON
OFF
CLOGGED,當風扇開啟但氣流被阻擋時
FRICTION,當風扇開啟,但一個或多個風扇葉片在運行過程中遇到過大摩擦時
對于模型開發人員,同樣重要的是,ML 狀態監測應用軟件包除包括 ML 模型外,還包括一個完整數據集,它代表了風扇在這四種狀態下運行的加速度計讀數。
開發人員可以研究 ML狀態監測應用軟件包提供的代碼、模型和數據,以了解如何使用傳感器數據訓練模型,創建推理模型,并針對驗證傳感器數據集驗證推理。事實上,NXP 的應用軟件包中包含的ML_State_Monitor.ipynb Jupyter Notebook 提供了一個開箱即用的工具,支持在任何硬件部署之前研究模型開發工作流程。
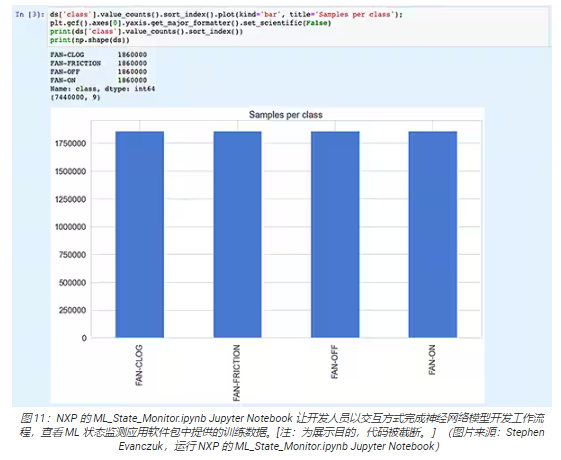
Jupyter Notebook 是一個基于瀏覽器的互動式 Python 執行平臺,允許開發人員立即查看 Python 代碼的執行結果。運行Jupyter Notebook 會生成一個 Python代碼塊,緊接著出現該代碼塊的運行結果。這些結果不是簡單的靜態展示,而是通過運行代碼得到的實際結果。例如,開發人員運行 NXP 的ML_State_Monitor.ipynb Jupyter Notebook 時,可以立即查看輸入數據集的摘要(圖 11)。
Notebook 中的下一部分代碼為用戶提供了輸入數據的圖形顯示,以時間序列和頻率的單獨圖形呈現(圖 12)。

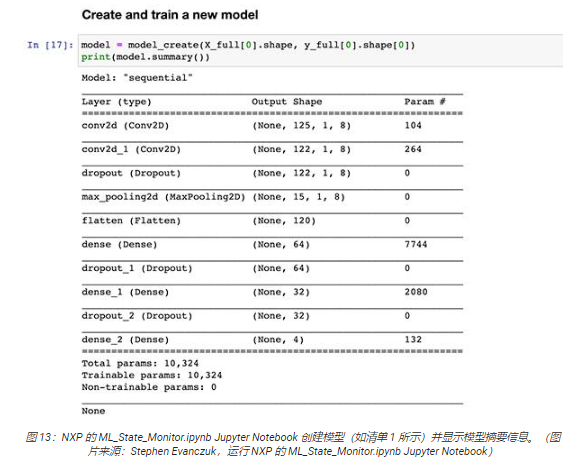
其他代碼部分提供了進一步的數據分析、規一化、整形和其他準備工作,直至代碼執行到清單 1 中顯示的模型創建函數定義 model_create()。接下來的代碼部分將執行此 model_create() 函數,并打印出摘要以供快速驗證(圖 13)。
在部分模型訓練和評估代碼之后,ML_State_Monitor.ipynb Jupyter Notebook顯示完整數據集、訓練數據集和驗證數據集(從訓練數據集中排除的數據集的子集)的每個混淆矩陣。在這種情況下,完整數據集的混淆矩陣展現出良好的精度和一定的誤差,其中最明顯的是模型將一小部分數據集混淆為處于ON 狀態,而根據原始數據集的注釋,它們實際上處于 CLOGGED 狀態(圖 14)。

在后面的代碼部分,模型被導出為幾種不同的模型類型和格式,由 eIQ 開發環境支持的各種推理引擎使用(圖 15)。

推理引擎的選擇對于滿足特定性能要求至關重要。對于該應用,NXP測量了以幾種不同推理引擎為目標的模型大小、代碼大小和推理時間(對單一輸入對象完成推理所需的時間),一個以 996 MHz 運行,一個以 156 MHz 運行(圖16 和 17)。

正如 NXP 指出的那樣,此樣例應用使用的是一個非常小的模型,所以這些數字的差異相當明顯,但對于復雜分類所用的大型模型,差異可能要小得多。
構建用于狀態監測的系統解決方案
除了用于交互式探索模型開發工作流程的 Jupyter Notebook,NXP 的 ML 狀態監測應用軟件包還提供完整的源代碼,用于在 NXP 的MIMXRT1170-EVK 評估板上實現設計。評估板圍繞 NXP 的 MIMXRT1176DVMAA 跨界 MCU構建,提供一個全面的硬件平臺,并配備了額外的存儲器和多個接口(圖 18)。

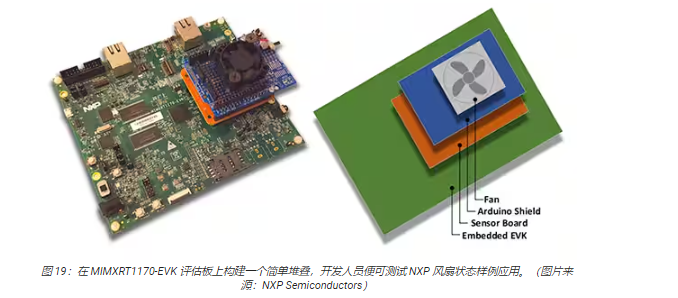
將 MIMXRT1170-EVK 評估板與可選的 NXP FRDM-STBC-AGM01 傳感器板、Arduino 擴展板和合適的 5 V無刷直流風扇(如 Adafruit 的 4468)堆疊起來,開發人員便可使用 NXP 的風扇狀態應用來預測風扇的狀態(圖 19)。
借助 MCUXpresso 集成開發環境 (IDE),開發人員可以配置應用以簡單地獲取和存儲風扇狀態數據,或立即使用 TensorFlow推理引擎、DeepViewRT 推理引擎或 Glow 推理引擎對獲取的數據運行推理(清單 2)。
#define SENSOR_COLLECT_LOG_EXT 1 // Collect and log data externally
#define SENSOR_COLLECT_RUN_INFERENCE 2 // Collect data and run inference
/* Inference engine to be used */
#define SENSOR_COLLECT_INFENG_TENSORFLOW 1 // TensorFlow
#define SENSOR_COLLECT_INFENG_DEEPVIEWRT 2 // DeepViewRT
#define SENSOR_COLLECT_INFENG_GLOW 3 // Glow
/* Data format to be used to feed the model */
#define SENSOR_COLLECT_DATA_FORMAT_BLOCKS 1 // Blocks of samples
#define SENSOR_COLLECT_DATA_FORMAT_INTERLEAVED 2 // Interleaved samples
/* Parameters to be configured by the user: */
/* Configure the action to be performed */
#define SENSOR_COLLECT_ACTION SENSOR_COLLECT_RUN_INFERENCE
#if SENSOR_COLLECT_ACTION == SENSOR_COLLECT_LOG_EXT
/* If the SD card log is not enabled the sensor data will be streamed to the
terminal */
#define SENSOR_COLLECT_LOG_EXT_SDCARD 1 // Redirect the log to SD card,
otherwise print to console
清單 2:開發人員可以通過修改 sensor_collect.h 頭文件中包含的定義,輕松配置 NXP 的 ML 狀態監測樣例應用。(代碼來源:NXPSemiconductors)
該應用的工作流程簡單明了。main.c 中的主例程創建一個名為 MainTask 的任務,后者是位于sensor_collect.c模塊中的一個例程。
void MainTask(void *pvParameters)
{
status_t status = kStatus_Success;
printf(“MainTask startedrn”);
#if !SENSOR_FEED_VALIDATION_DATA
status = SENSOR_Init();
if (status != kStatus_Success)
{
goto main_task_exit;
}
#endif
g_sensorCollectQueue = xQueueCreate(SENSOR_COLLECT_QUEUE_ITEMS,
sizeof(sensor_data_t));
if (NULL == g_sensorCollectQueue)
{
printf(“collect queue create failed!rn”);
status = kStatus_Fail;
goto main_task_exit;
}
#if SENSOR_COLLECT_ACTION == SENSOR_COLLECT_LOG_EXT
uint8_t captClassLabelIdx;
CAPT_Init(&captClassLabelIdx, &g_SensorCollectDuration_us,
&g_SensorCollectDuration_samples);
g_SensorCollectLabel = labels[captClassLabelIdx];
if (xTaskCreate(SENSOR_Collect_LogExt_Task, “SENSOR_Collect_LogExt_Task”,
4096, NULL, configMAX_PRIORITIES - 1, NULL) != pdPASS)
{
printf(“SENSOR_Collect_LogExt_Task creation failed!rn”);
status = kStatus_Fail;
goto main_task_exit;
}
#elif SENSOR_COLLECT_ACTION == SENSOR_COLLECT_RUN_INFERENCE
if (xTaskCreate(SENSOR_Collect_RunInf_Task, “SENSOR_Collect_RunInf_Task”,
4096, NULL, configMAX_PRIORITIES - 1, NULL) != pdPASS)
{
printf(“SENSOR_Collect_RunInf_Task creation failed!rn”);
status = kStatus_Fail;
goto main_task_exit;
}
#endif
清單 3:在 NXP 的 ML 狀態監測樣例應用中,MainTask 調用一個子任務來獲取數據或運行推理。(代碼來源:NXPSemiconductors)
MainTask 先執行各種初始化任務,再啟動兩個子任務中的一個,具體哪一個取決于用戶在 sensor_collect.h 中的設置:
如果 SENSOR_COLLECT_ACTION 被設置為 SENSOR_COLLECT_LOG_EXT,則 MainTask 啟動子任務
SENSOR_Collect_LogExt_Task(),收集數據并將其存儲在 SD 卡上(如已配置)
如果 SENSOR_COLLECT_ACTION 被設置為 SENSOR_COLLECT_RUN_INFERENCE,則 MainTask 啟動子任務SENSOR_Collect_RunInf_Task(),針對所收集的數據運行 Sensor_collect.h中定義的推理引擎(Glow、DeepViewRT 或 TensorFlow);如果定義了SENSOR_EVALUATE_MODEL,則還會顯示相應的性能和分類預測
if SENSOR_COLLECT_ACTION == SENSOR_COLLECT_LOG_EXT
void SENSOR_Collect_LogExt_Task(void *pvParameters)
{
[code deleted for simplicity]
while (1)
{
[code deleted for simplicity]
bufSizeLog = snprintf(buf, bufSize, “%s,%ld,%d,%d,%d,%d,%d,%d,%drn”,
g_SensorCollectLabel, (uint32_t)(sensorData.ts_us/1000),
sensorData.rawDataSensor.accel[0], sensorData.rawDataSensor.accel[1],
sensorData.rawDataSensor.accel[2],
sensorData.rawDataSensor.mag[0], sensorData.rawDataSensor.mag[1],
sensorData.rawDataSensor.mag[2],
sensorData.temperature);
#if SENSOR_COLLECT_LOG_EXT_SDCARD
SDCARD_CaptureData(sensorData.ts_us, sensorData.sampleNum,
g_SensorCollectDuration_samples, buf, bufSizeLog);
#else
printf(“%.*s”, bufSizeLog, buf);
[code deleted for simplicity]
}
vTaskDelete(NULL);
}
#elif SENSOR_COLLECT_ACTION == SENSOR_COLLECT_RUN_INFERENCE
[code deleted for simplicity]
void SENSOR_Collect_RunInf_Task(void *pvParameters)
{
[code deleted for simplicity]
while (1)
{
[code deleted for simplicity]
/* Run Inference */
tinf_us = 0;
SNS_MODEL_RunInference((void*)g_clsfInputData, sizeof(g_clsfInputData),
(int8_t*)&predClass, &tinf_us, SENSOR_COLLECT_INFENG_VERBOSE_EN);
[code deleted for simplicity]
#if SENSOR_EVALUATE_MODEL
/* Evaluate performance */
validation.predCount++;
if (validation.classTarget == predClass)
{
validation.predCountOk++;
}
PRINTF(“rInference %d?%d | t %ld us | count: %d/%d/%d | %s ”,
validation.classTarget, predClass, tinf_us, validation.predCountOk,
validation.predCount, validation.predSize, labels[predClass]);
tinfTotal_us += tinf_us;
if (validation.predCount 》= validation.predSize)
{
printf(“rnPrediction Accuracy for class %s %.2f%%rn”,
labels[validation.classTarget],
(float)(validation.predCountOk * 100)/validation.predCount);
printf(“Average Inference Time %.1f (us)rn”,
(float)tinfTotal_us/validation.predCount);
tinfTotal_us = 0;
}
#endif
}
exit_task:
vTaskDelete(NULL);
}
#endif /* SENSOR_COLLECT_ACTION */
清單 4:NXP 的 ML 狀態監測樣例應用演示了獲取傳感器數據和對獲取的數據運行所選推理引擎的基本設計模式。(代碼來源:NXPSemiconductors)
由于 NXP 的 ML狀態監測應用軟件包提供了完整的源代碼以及全套必需的驅動程序和中間件,因此開發人員可以輕松擴展該應用以增加特性,或將其作為起點來開發自己的定制應用。
總結
在物聯網和其他應用中的智能產品的邊緣實施 ML 可以提供一系列強大的功能,但現有 ML 工具和方法大多是為企業級應用而開發的,邊緣 ML開發人員使用起來往往很吃力。有了由跨界處理器和專門的模型開發軟件組成的 NXP 開發平臺,無論 ML 專家還是幾乎沒有 ML經驗的開發人員都能更有效地創建專門設計的 ML 應用,以滿足對高效邊緣性能的要求。
-
神經網絡
+關注
關注
42文章
4774瀏覽量
100898 -
物聯網
+關注
關注
2910文章
44752瀏覽量
374593 -
開源
+關注
關注
3文章
3370瀏覽量
42577 -
ML
+關注
關注
0文章
149瀏覽量
34670 -
機器學習
+關注
關注
66文章
8425瀏覽量
132771
發布評論請先 登錄
相關推薦
如何通過生產就緒平臺快速構建和部署自適應邊緣視覺應用
快速高效地實施網絡邊緣機器學習
超低功耗FPGA解決方案助力機器學習
高性能的機器學習讓邊緣計算更給力-iMX8M Plus為邊緣計算賦能
微型機器學習
高性能的機器學習讓邊緣計算更給力
創建一個邊緣機器學習系統

邊緣機器學習成功的關鍵因素

TDK機器學習解決方案促進邊緣人工智能前景大幅擴展
如何快速設計和部署 IIoT 就緒型機器






 工商網監
工商網監
評論