") DreamLLM:多功能多模態(tài)大型語言模型,你的DreamLLM~
DreamLLM:多功能多模態(tài)大型語言模型,你的DreamLLM~
今天為大家介紹西安交大,清華大學(xué)、華中科大聯(lián)合MEGVII Technology的一篇關(guān)于多模態(tài)LLM學(xué)習(xí)框架的論文,名為DREAMLLM。
- 論文:DreamLLM: Synergistic Multimodal Comprehension and Creation
- 論文鏈接:https://arxiv.org/abs/2309.11499
- GitHub:https://github.com/RunpeiDong/DreamLLM
摘要
DREAMLLM是一個(gè)學(xué)習(xí)框架,實(shí)現(xiàn)了通用的多模態(tài)大型語言模型(Multimodal Large Language Models,MLLMs),該模型利用了多模態(tài)理解和創(chuàng)造之間經(jīng)常被忽視的協(xié)同作用。DREAMLLM的運(yùn)作遵循兩個(gè)基本原則:一是在原始多模態(tài)空間中通過直接采樣對(duì)語言和圖像后驗(yàn)進(jìn)行生成建模有助于獲取更徹底的多模態(tài)理解。二是促進(jìn)了原始、交錯(cuò)文檔的生成,對(duì)文本和圖像內(nèi)容以及非結(jié)構(gòu)化布局進(jìn)行建模,使得模型能夠有效地學(xué)習(xí)所有條件、邊際和聯(lián)合多模式分布。
簡(jiǎn)介
在多模態(tài)任務(wù)中,內(nèi)容理解和創(chuàng)作是機(jī)器智能的終極目標(biāo)之一。為此,多模式大語言模型成功進(jìn)入視覺領(lǐng)域。MLLMs在多模態(tài)理解能力方面取得了前所未有的進(jìn)展。通常通過將圖像作為多模式輸入來增強(qiáng)LLM,以促進(jìn)語言輸出的多模式理解。其目的是通過語言后驗(yàn)來捕捉多模式的條件分布或邊際分布。然而,涉及生成圖像、文本或兩者的多模式創(chuàng)作,需要一個(gè)通用的生成模型來同時(shí)學(xué)習(xí)語言和圖像后驗(yàn),而這一點(diǎn)目前尚未得到充分的探索。最近,一些工作顯示出使用MLLMs的條件圖像生成的成功。如下圖所示,
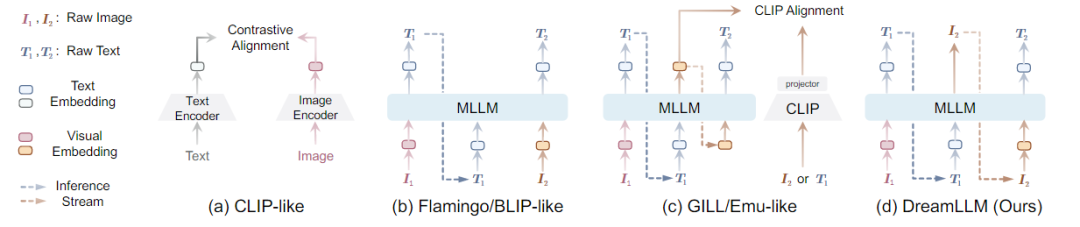
由于固有的模態(tài)缺口,如CLIP語義主要關(guān)注模態(tài)共享信息,往往忽略了可以增強(qiáng)多模態(tài)理解的模態(tài)特定知識(shí)。因此,這些研究并沒有充分認(rèn)識(shí)到多模式創(chuàng)造和理解之間潛在的學(xué)習(xí)協(xié)同作用,只顯示出創(chuàng)造力的微小提高,并且在多模式理解方面仍然存在不足。
創(chuàng)新點(diǎn):DREAMLLM以統(tǒng)一的自回歸方式生成原始語言和圖像輸入,本質(zhì)上實(shí)現(xiàn)了交錯(cuò)生成。
知識(shí)背景
- Autoregressive Generative Modeling:自回歸生成建模
- Diffusion Model:擴(kuò)散模型
MLLMs具體做法:現(xiàn)有策略會(huì)導(dǎo)致MLLMs出現(xiàn)語義減少的問題,偏離其原始輸出空間,為了避免,提出了替代學(xué)習(xí)方法如下圖所示,即DREAMLLM模型框架。
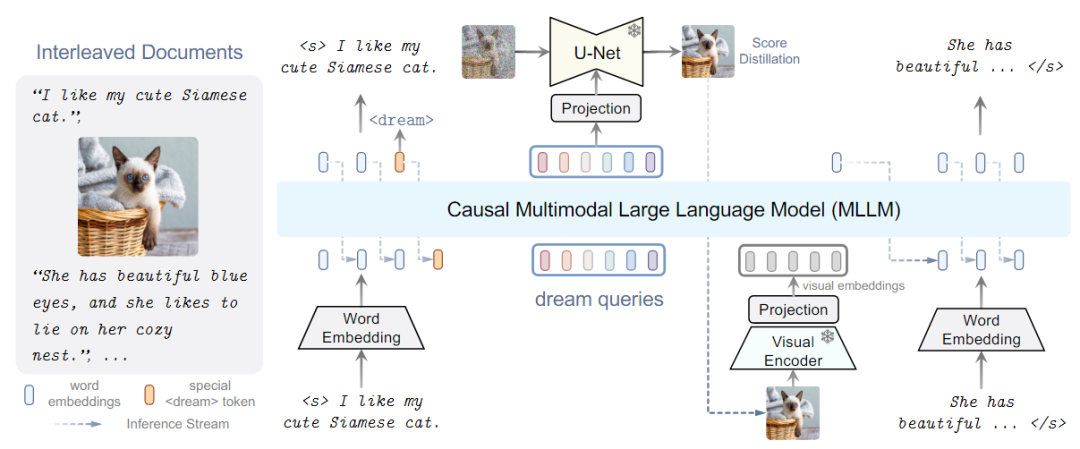
DREAMLLM架構(gòu)
DREAMLLM框架如上圖所示,使用交錯(cuò)的文檔用作輸入,解碼以產(chǎn)生輸出。文本和圖像都被編碼成用于MLLM輸入的順序的、離散的token嵌入。特殊的<dream>標(biāo)記可以預(yù)測(cè)在哪里生成圖像。隨后,一系列dream查詢被輸入到MLLM中,捕獲整體歷史語義。圖像由stable diffusion圖像解碼器以查詢的語義為條件進(jìn)行合成。然后將合成的圖像反饋到MLLM中用于隨后的理解。
其中MLLM是基于在shareGPT上訓(xùn)練的LLama的Vicuna,采用CLIP-Large作為圖像編碼器,為了合成圖像使用Stable Diffusion作為圖像解碼器。
模型訓(xùn)練
模型訓(xùn)練分為對(duì)齊訓(xùn)練、I-GPT預(yù)訓(xùn)練和監(jiān)督微調(diào)。
實(shí)驗(yàn)結(jié)果
-
多模態(tài)理解:多模式理解使人類能夠與以單詞和視覺內(nèi)容為條件的主體進(jìn)行互動(dòng)。本文評(píng)估了DREAMLLM在幾個(gè)基準(zhǔn)上的多模式視覺和語言能力。此外,對(duì)最近開發(fā)的MMBench和MM-Vet基準(zhǔn)進(jìn)行了零樣本評(píng)估,以評(píng)估模型在復(fù)雜多模式任務(wù)中的性能。
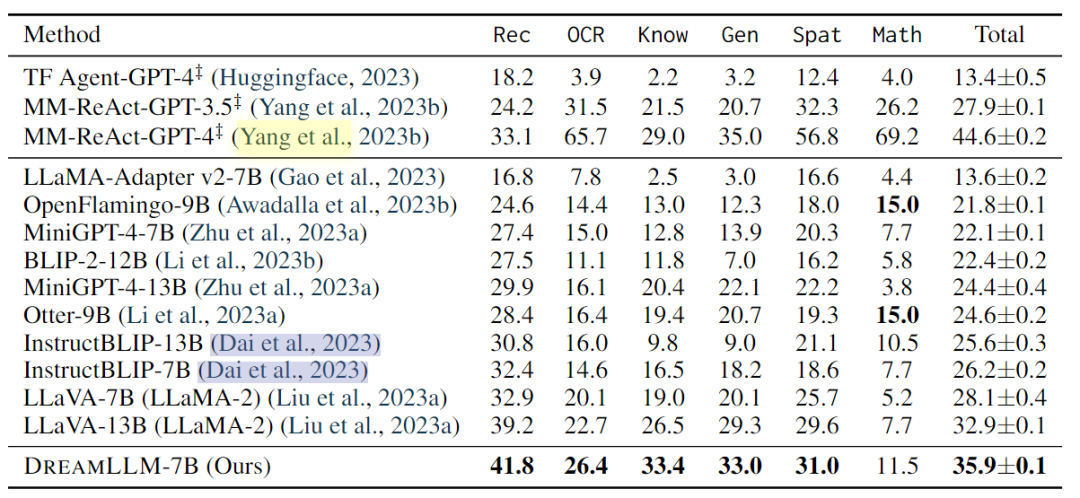
-
發(fā)現(xiàn),DREAMLLM在所有基準(zhǔn)測(cè)試中都優(yōu)于其他MLLM。值得注意的是,DREAMLLM-7B在圖像合成能力方面大大超過了并發(fā)MLLMs,與Emu-13B相比,VQAv2的精度提高了16.6。在MMBench和MMVet等綜合基準(zhǔn)測(cè)試中,DREAMLLM與所有7B同行相比都取得了最先進(jìn)的性能。
-
條件文本圖像合成:條件文本圖像合成是創(chuàng)造性內(nèi)容生成最常用的技術(shù)之一,它通過自由形式的語言生成遵循人類描述的圖像。
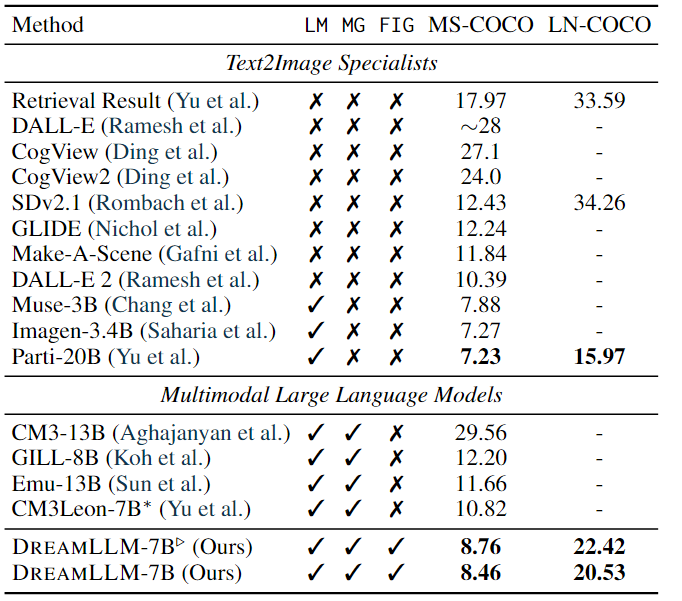
-
其結(jié)果如上表所示。結(jié)果顯示:DREAMLLM 在階段I對(duì)齊后顯示出比Stable Diffusion基線顯著提高FID,在 MS-COCO 和 LN-COCO 上分別將分?jǐn)?shù)分別降低了 3.67 和 11.83。此外,預(yù)訓(xùn)練和監(jiān)督微調(diào)后實(shí)現(xiàn)了 3.97 和 13.73 的 FID 改進(jìn)。LN-COCO 的實(shí)質(zhì)性改進(jìn)強(qiáng)調(diào)了 DREAMLLM 在處理長(zhǎng)上下文信息方面的卓越性能。與之前的專家模型相比,DREAMLLM 基于 SD 圖像解碼器提供了有競(jìng)爭(zhēng)力的結(jié)果。DREAMLLM 始終優(yōu)于基于并發(fā) MLLM 的圖像合成方法。
-
多模態(tài)聯(lián)合創(chuàng)建于比較:分別進(jìn)行了自由形式的交錯(cuò)文檔創(chuàng)建、圖片質(zhì)量和人工評(píng)估三個(gè)實(shí)驗(yàn)。實(shí)驗(yàn)結(jié)果表明:DREAMLLM可以根據(jù)給定的指令生成有意義的響應(yīng)。系統(tǒng)可以通過預(yù)測(cè)所提出的令牌在任何指定位置自主創(chuàng)建圖像,從而消除了對(duì)額外人工干預(yù)的需要。DREAMLLM生成的圖像準(zhǔn)確地對(duì)應(yīng)于相關(guān)文本。證明了所提方法的有效性。
總結(jié)
本文介紹了一個(gè)名為DREAMLLM的學(xué)習(xí)框架,它能夠同時(shí)實(shí)現(xiàn)多模態(tài)理解和創(chuàng)作。DREAMLLM具有兩個(gè)基本原則:第一個(gè)原則是通過在原始多模態(tài)空間中進(jìn)行直接采樣,生成語言和圖像后驗(yàn)概率的生成建模。第二個(gè)原則是促進(jìn)生成原始、交錯(cuò)文檔,模擬文本和圖像內(nèi)容以及無結(jié)構(gòu)的布局,使DREAMLLM能夠有效地學(xué)習(xí)所有條件、邊際和聯(lián)合多模態(tài)分布。實(shí)驗(yàn)結(jié)果表明,DREAMLLM是第一個(gè)能夠生成自由形式交錯(cuò)內(nèi)容的MLLM,并具有卓越的性能。
-
框架
+關(guān)注
關(guān)注
0文章
403瀏覽量
17509 -
語言模型
+關(guān)注
關(guān)注
0文章
527瀏覽量
10290 -
機(jī)器智能
+關(guān)注
關(guān)注
0文章
55瀏覽量
8612
原文標(biāo)題:DreamLLM:多功能多模態(tài)大型語言模型,你的DreamLLM~
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
一文理解多模態(tài)大語言模型——上

大型語言模型有哪些用途?
大型語言模型有哪些用途?大型語言模型如何運(yùn)作呢?
利用大語言模型做多模態(tài)任務(wù)
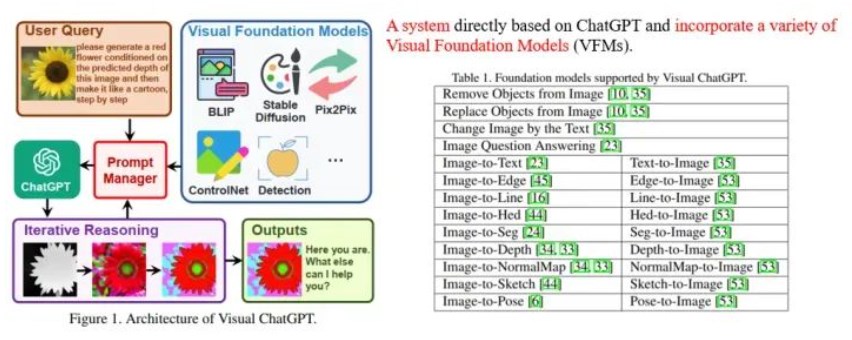
如何利用LLM做多模態(tài)任務(wù)?
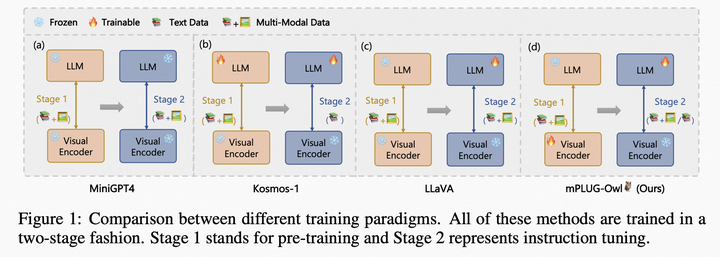
邱錫鵬團(tuán)隊(duì)提出具有內(nèi)生跨模態(tài)能力的SpeechGPT,為多模態(tài)LLM指明方向

VisCPM:邁向多語言多模態(tài)大模型時(shí)代

更強(qiáng)更通用:智源「悟道3.0」Emu多模態(tài)大模型開源,在多模態(tài)序列中「補(bǔ)全一切」

探究編輯多模態(tài)大語言模型的可行性
哈工大提出Myriad:利用視覺專家進(jìn)行工業(yè)異常檢測(cè)的大型多模態(tài)模型

自動(dòng)駕駛和多模態(tài)大語言模型的發(fā)展歷程

機(jī)器人基于開源的多模態(tài)語言視覺大模型

韓國(guó)Kakao宣布開發(fā)多模態(tài)大語言模型“蜜蜂”
智譜AI發(fā)布全新多模態(tài)開源模型GLM-4-9B
一文理解多模態(tài)大語言模型——下






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論