 RabbitMQ通信模型中的work模型
RabbitMQ通信模型中的work模型
上一篇文章中,簡單的介紹了一下RabbitMQ,以及安裝和hello world。
有的小伙伴留言說看不懂其中的方法參數,這里先解釋一下幾個基本的方法參數。
// 聲明隊列方法
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
/**
* param1:queue 隊列的名字
* param2:durable 是否持久化;比如現在發送到隊列里面的消息,如果沒有持久化,重啟這個隊列后數 據會丟失(false) true:重啟之后數據依然在
* param3:exclusive 是否排外(是否是當前連接的專屬隊列),排外的意思是:
* 1:連接關閉之后 這個隊列是否自動刪除(false:不自動刪除)
* 2:是否允許其他通道來進行訪問這個數據(false:不允許)
* param4:autoDelete 是否自動刪除
* 就是當最后一個連接斷開的時候,是否自動刪除這個隊列(false:不刪除)
* param5:arguments(map) 聲明隊列的時候,附帶的一些參數
*/
// 發送數據到隊列
channel.basicPublish("", QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN, "第一個隊列消息...".getBytes());
/**
* param1:exchange 交換機 沒有就設置為 "" 值就可以了
* param2:routingKey 路由的key 現在沒有設置key,直接使用隊列的名字
* param3:BasicProperties 發送數據到隊列的時候,是否要帶一些參數。
* MessageProperties.PERSISTENT_TEXT_PLAIN表示沒有帶任何參數
* param4:body 向隊列中發送的消息數據
*/
Work模型
work模型稱為工作隊列或者競爭消費者模式,多個消費者消費的數據之和才是原來隊列中的所有數據,適用于流量的削峰。
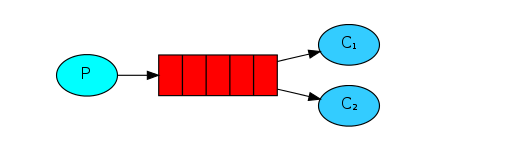
img
演示
寫個簡單的測試:
生產者
public class Producer { private static final String QUEUE_NAME = "queue_work_1"; public static void main(String[] args) throws IOException, TimeoutException { Connection connection = ConnectionUtils.getConnection(); Channel channel = connection.createChannel(); channel.queueDeclare(QUEUE_NAME, false, false, false, null); for (int i = 0; i < 100; i++) { channel.basicPublish("", QUEUE_NAME, null, ("work模型:" + i).getBytes()); } channel.close(); connection.close(); } }消費者
// 消費者1 public class Consumer { private static final String QUEUE_NAME = "queue_work_1"; public static void main(String[] args) throws IOException, TimeoutException { Connection connection = ConnectionUtils.getConnection(); Channel channel = connection.createChannel(); channel.queueDeclare(QUEUE_NAME, false, false, false, null); // channel.basicQos(0, 1, false); DefaultConsumer defaultConsumer = new DefaultConsumer(channel) { @Override public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException { System.out.println(System.currentTimeMillis() + "消費者1接收到信息:" + new String(body)); channel.basicAck(envelope.getDeliveryTag(), false); } }; channel.basicConsume(QUEUE_NAME, false, defaultConsumer); } }// 消費者2 public class Consumer2 { private static final String QUEUE_NAME = "queue_work_1"; public static void main(String[] args) throws IOException, TimeoutException { Connection connection = ConnectionUtils.getConnection(); Channel channel = connection.createChannel(); channel.queueDeclare(QUEUE_NAME, false, false, false, null); // channel.basicQos(0, 1, false); DefaultConsumer defaultConsumer = new DefaultConsumer(channel) { @Override public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException { System.out.println(System.currentTimeMillis() + "消費者2接收到信息:" + new String(body)); channel.basicAck(envelope.getDeliveryTag(), false); // 這里加了個延遲,表示處理業務時間 try { Thread.sleep(200); } catch (InterruptedException e) { e.printStackTrace(); } } }; channel.basicConsume(QUEUE_NAME, false, defaultConsumer); } }結果
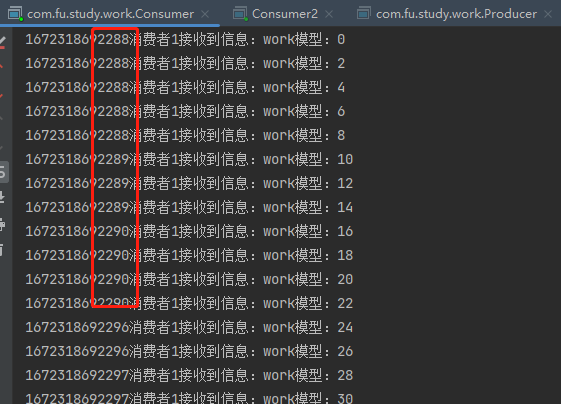
image-20221229210012145

image-20221229210046184
可以看出來:100條消息,消費者之間是平分的,消費者1 幾乎是瞬間完成,消費者2 則是慢慢吞吞的運行完畢,消費者1大量時間處于空閑狀態,消費者2則一直忙碌。這顯然是不適用于實際開發中。
我們需要遵從一個原則,就是 能者多勞 ,消費越快的人,消費的越多;
現在我們把消費者1和2的代碼中 // channel.basicQos(0, 1, false); 這行代碼取消注釋,再次運行;

image-20221229211317632

image-20221229211335782
現在的結果就比較符合能者多勞,雖然你干的多,但是工資是一樣的呀~
work模型的一個主要的方法是basicQos();這里也解釋一下其參數:
// 設置限流機制
channel.basicQos(0, 1, false);
/**
* param1: prefetchSize,消息本身的大小 如果設置為0 那么表示對消息本身的大小不限制
* param2: prefetchCount,告訴rabbitmq不要一次性給消費者推送大于N個消息
* param3:global,是否將上面的設置應用于整個通道,false表示只應用于當前消費者
*/
小結
本文到這里就結束了,主要介紹了RabbitMQ通信模型中的work模型,適用于限流、削峰等應用場景。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
數據
+關注
關注
8文章
7081瀏覽量
89177 -
通信
+關注
關注
18文章
6042瀏覽量
136138 -
模型
+關注
關注
1文章
3262瀏覽量
48916 -
Work
+關注
關注
0文章
9瀏覽量
9035 -
rabbitmq
+關注
關注
0文章
18瀏覽量
1035
發布評論請先 登錄
相關推薦
CAN總線通信協議模型概述 CAN總線通信模型作用
參照 ISO/OSI 標準模型,CAN 總線的通信參考模型如圖 9-1 所示。這 4 層結構的功能如下:? 物理層規定了節點的全部電氣特性,在一個網絡里,要實現不同節點間的數據傳輸,所有節點的物理層
發表于 12-14 14:17
MQTT的通信模型及消息
MQTT通信模型 MQTT協議是基于客戶端-服務器模型,在協議中主要有三種身份:發布者(Publisher)、服務器(Broker) 以及訂閱者(Subscriber)。 并且消息發布者可以
發表于 01-19 15:57
基于VxWorks實時操作系統的通信模型該怎樣去設計?
多任務實時操作系統VxWorks是什么?與傳統通信機制相比,模塊間通信模型有什么優勢?基于VxWorks實時操作系統的通信模型該怎樣去設計?
發表于 04-26 06:25
移動Agent位置透明通信模型的設計
提出一種高效可靠的移動Agent通信模型――D-C通信模型,結合域名字解析器和移動Agent系統中的Communicator實現移動Agent之間的通信。通過引入一種基于全局的、與位置
發表于 04-16 08:53
?26次下載
過程控制工業以太網通信模型探討
提出了建立在交換式以太網和IEEE 802.1Q/P 技術基礎上用于過程控制的以太網通信模型REPC,并進行了分析。關鍵詞:通信模型工業以太網 過程控制Abstract: REPC, a communication model of in
發表于 06-19 08:34
?27次下載
數據網格中基于優化機制的通信模型
針對基于多計算機機群構成的網格的大規模并行計算的需要,對多級分組通信模型的單一機群分組通信進行了研究。探討了在單一機群內的主動節點、被動節點個數和各個計算節點
發表于 06-25 13:52
?12次下載
基于VxWorks的通信模型設計
本文提出了一種任務間的通信模型,將用于網絡通信的UDP方式引進到任務間的通信中,使通信更加靈活和便于管理,改善了整個系統的性能。
發表于 06-01 10:07
?1039次閱讀
企業資產管理系統中通信模型的研究與實現
為了改善企業資產管理(EAM)系統在用戶體驗、模塊間數據傳輸效率及耦合度等方面的不足,構建了基于Silverlight與WCF技術研究與實現EAM系統中的通信模型。利用Silverlight構建客戶端提升
發表于 07-06 16:57
?34次下載
RabbitMQ中的路由模型(direct)
路由模型 RabbitMQ 提供了五種不同的通信模型,上一篇文章中,簡單的介紹了一下RabbitMQ的發布訂閱
什么是通信模型DDS
完成的,它相當于是ROS機器人系統中的神經網絡。 通信模型 DDS的核心是通信,能夠實現通信的模型和軟件框架非常多,這里我們列出常用的四種





 工商網監
工商網監
評論