") 大模型現(xiàn)存的10個問題和挑戰(zhàn)
大模型現(xiàn)存的10個問題和挑戰(zhàn)
大模型現(xiàn)存的問題和挑戰(zhàn)這篇文章介紹了關(guān)于大型語言模型(LLMs)研究中的十個主要方向和問題:
1. 減少和度量幻覺:幻覺指的是AI模型虛構(gòu)信息的情況,可能是創(chuàng)意應(yīng)用的一個特點,但在其他應(yīng)用中可能是一個問題。這個方向涉及減少幻覺和開發(fā)衡量幻覺的度量標(biāo)準(zhǔn)。
2. 優(yōu)化上下文長度和構(gòu)造:針對大多數(shù)問題,上下文信息是必需的,文章介紹了在RAG(Retrieval Augmented Generation)架構(gòu)中優(yōu)化上下文長度和構(gòu)造的重要性。
3. 整合其他數(shù)據(jù)形式:多模態(tài)是強大且被低估的領(lǐng)域,文章探討了多模態(tài)數(shù)據(jù)的重要性和潛在應(yīng)用,如醫(yī)療預(yù)測、產(chǎn)品元數(shù)據(jù)分析等。
4. 使LLMs更快、更便宜:討論了如何使LLMs更高效、更節(jié)約資源,例如通過模型量化、模型壓縮等方法。
5. 設(shè)計新的模型架構(gòu):介紹了開發(fā)新的模型架構(gòu)以取代Transformer的嘗試,以及挑戰(zhàn)和優(yōu)勢。
6. 開發(fā)GPU替代方案:討論了針對深度學(xué)習(xí)的新硬件技術(shù),如TPUs、IPUs、量子計算、光子芯片等。
7. 使代理人更易用:探討了訓(xùn)練能夠執(zhí)行動作的LLMs,即代理人,以及其在社會研究和其他領(lǐng)域的應(yīng)用。
8. 提高從人類偏好中學(xué)習(xí)的效率:討論了從人類偏好中訓(xùn)練LLMs的方法和挑戰(zhàn)。
9. 改進(jìn)聊天界面的效率:討論了聊天界面在任務(wù)處理中的適用性和改進(jìn)方法,包括多消息、多模態(tài)輸入、引入生成AI等。
10. 為非英語語言構(gòu)建LLMs:介紹了將LLMs擴展到非英語語言的挑戰(zhàn)和必要性。
1. 減少和衡量幻覺
幻覺是一個廣受關(guān)注的話題,指的是當(dāng)AI模型編造信息時發(fā)生的情況。在許多創(chuàng)造性的應(yīng)用場景中,幻覺是一種特性。然而,在大多數(shù)其他用例中,幻覺是一個缺陷。一些大型企業(yè)近期在關(guān)于大型語言模型的面板上表示,影響企業(yè)采用LLMs的主要障礙是幻覺問題。
減輕幻覺問題并開發(fā)用于衡量幻覺的度量標(biāo)準(zhǔn)是一個蓬勃發(fā)展的研究課題。有許多初創(chuàng)公司專注于解決這個問題。還有一些降低幻覺的方法,例如在提示中添加更多的上下文、思維鏈、自我一致性,或要求模型在回答中保持簡潔。
要了解更多關(guān)于幻覺的信息,可以參考以下文獻(xiàn):
- Survey of Hallucination in Natural Language Generation (Ji et al., 2022)
- How Language Model Hallucinations Can Snowball (Zhang et al., 2023)
- A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity (Bang et al., 2023)
- Contrastive Learning Reduces Hallucination in Conversations (Sun et al., 2022)
- Self-Consistency Improves Chain of Thought Reasoning in Language Models (Wang et al., 2022)
- SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models (Manakul et al., 2023)
- NVIDIA’s NeMo-Guardrails中關(guān)于事實核查和幻覺的簡單示例
2. 優(yōu)化上下文長度限制
大部分問題需要上下文信息。例如,如果我們詢問ChatGPT:“哪家越南餐廳最好?”,所需的上下文將是“在哪里”,因為越南在越南和美國的最佳越南餐廳不同。
在這篇論文中提到,許多信息尋求性的問題都有依賴于上下文的答案,例如Natural Questions NQ-Open數(shù)據(jù)集中約占16.5%。對于企業(yè)用例,這個比例可能會更高。例如,如果一家公司為客戶支持構(gòu)建了一個聊天機器人,為了回答客戶關(guān)于任何產(chǎn)品的問題,所需的上下文可能是該客戶的歷史或該產(chǎn)品的信息。由于模型“學(xué)習(xí)”來自提供給它的上下文,這個過程也被稱為上下文學(xué)習(xí)。
3. 合并其他數(shù)據(jù)模態(tài)
多模態(tài)是非常強大但常常被低估的概念。它具有許多優(yōu)點:
首先,許多用例需要多模態(tài)數(shù)據(jù),特別是在涉及多種數(shù)據(jù)模態(tài)的行業(yè),如醫(yī)療保健、機器人、電子商務(wù)、零售、游戲、娛樂等。例如,醫(yī)學(xué)預(yù)測常常需要文本(如醫(yī)生的筆記、患者的問卷)和圖像(如CT、X射線、MRI掃描)。
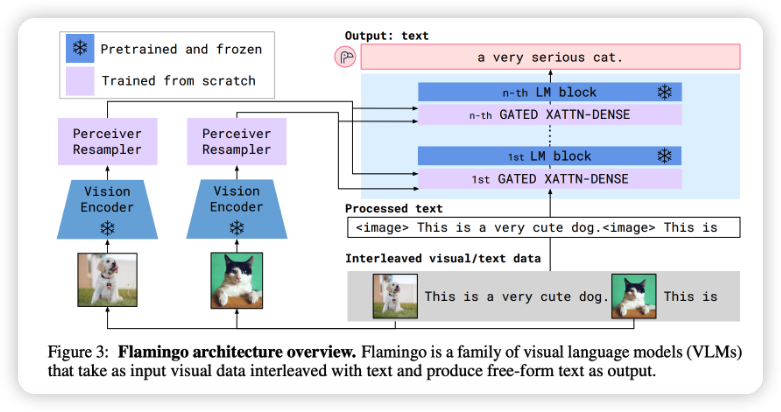
其次,多模態(tài)承諾可以顯著提高模型的性能。一個能夠理解文本和圖像的模型應(yīng)該比只能理解文本的模型表現(xiàn)更好。基于文本的模型需要大量的文本數(shù)據(jù),因此有現(xiàn)實擔(dān)憂稱我們可能會很快用完訓(xùn)練基于文本的模型的互聯(lián)網(wǎng)數(shù)據(jù)。一旦我們用完了文本數(shù)據(jù),我們需要利用其他數(shù)據(jù)模態(tài)。
其中一個特別令人興奮的用例是,多模態(tài)可以幫助視障人士瀏覽互聯(lián)網(wǎng)和導(dǎo)航現(xiàn)實世界。
4. 使LLMs更快且更便宜
當(dāng)GPT-3.5于2022年底首次發(fā)布時,很多人對在生產(chǎn)中使用它的延遲和成本表示擔(dān)憂。這是一個復(fù)雜的問題,牽涉到多個層面,例如:
訓(xùn)練成本:訓(xùn)練LLMs的成本隨著模型規(guī)模的增大而增加。目前,訓(xùn)練一個大型的LLM可能需要數(shù)百萬美元。
推理成本:在生產(chǎn)中使用LLMs的推理(生成)可能會帶來相當(dāng)高的成本,這主要是因為這些模型的巨大規(guī)模。
解決這個問題的一種方法是研究如何減少LLMs的大小,而不會明顯降低性能。這是一個雙重的優(yōu)勢:首先,更小的模型需要更少的成本來進(jìn)行推理;其次,更小的模型也需要更少的計算資源來進(jìn)行訓(xùn)練。這可以通過模型壓縮(例如蒸餾)或者采用更輕量級的架構(gòu)來實現(xiàn)。
5. 設(shè)計新的模型架構(gòu)
盡管Transformer架構(gòu)在自然語言處理領(lǐng)域取得了巨大成功,但它并不是唯一的選擇。近年來,研究人員一直在探索新的模型架構(gòu),試圖超越Transformer的限制。
這包括設(shè)計更適用于特定任務(wù)或問題的模型,以及從根本上重新考慮自然語言處理的基本原理。一些方向包括使用圖神經(jīng)網(wǎng)絡(luò)、因果推理架構(gòu)、迭代計算模型等等。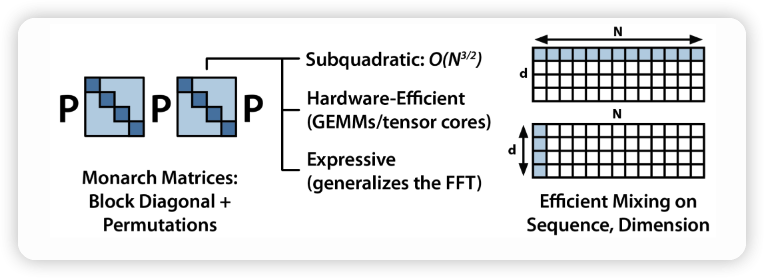
新的架構(gòu)可能會在性能、訓(xùn)練效率、推理速度等方面帶來改進(jìn),但也需要更多的研究和實驗來驗證其實際效果。
6. 開發(fā)GPU替代方案
當(dāng)前,大多數(shù)深度學(xué)習(xí)任務(wù)使用GPU來進(jìn)行訓(xùn)練和推理。然而,隨著模型規(guī)模的不斷增大,GPU可能會遇到性能瓶頸,也可能無法滿足能效方面的要求。
因此,研究人員正在探索各種GPU替代方案,例如:
TPUs(張量處理器):由Google開發(fā)的專用深度學(xué)習(xí)硬件,專為加速TensorFlow等深度學(xué)習(xí)框架而設(shè)計。
IPUs(智能處理器):由Graphcore開發(fā)的硬件,旨在提供高度并行的計算能力以加速深度學(xué)習(xí)模型。
量子計算:盡管仍處于實驗階段,但量子計算可能在未來成為處理復(fù)雜計算任務(wù)的一種有效方法。
光子芯片:使用光學(xué)技術(shù)進(jìn)行計算,可能在某些情況下提供更高的計算速度。
這些替代方案都有其獨特的優(yōu)勢和挑戰(zhàn),需要進(jìn)一步的研究和發(fā)展才能實現(xiàn)廣泛應(yīng)用。
7. 使代理人更易于使用
研究人員正在努力開發(fā)能夠執(zhí)行動作的LLMs,也被稱為代理人。代理人可以通過自然語言指令進(jìn)行操作,這在社會研究、可交互應(yīng)用等領(lǐng)域具有巨大潛力。
然而,使代理人更易于使用涉及到許多挑戰(zhàn)。這包括:
指令理解和執(zhí)行:確保代理人能夠準(zhǔn)確理解和執(zhí)行用戶的指令,避免誤解和錯誤。
多模態(tài)交互:使代理人能夠在不同的輸入模態(tài)(文本、語音、圖像等)下進(jìn)行交互。
個性化和用戶適應(yīng):使代理人能夠根據(jù)用戶的個性、偏好和歷史進(jìn)行適應(yīng)和個性化的交互。
這個方向的研究不僅涉及到自然語言處理,還涉及到機器人學(xué)、人機交互等多個領(lǐng)域。
8. 提高從人類偏好中學(xué)習(xí)的效率
從人類偏好中學(xué)習(xí)是一種訓(xùn)練LLMs的方法,其中模型會根據(jù)人類專家或用戶提供的偏好進(jìn)行學(xué)習(xí)。然而,這個過程可能會面臨一些挑戰(zhàn),例如:
數(shù)據(jù)采集成本:從人類偏好中學(xué)習(xí)需要大量的人類專家或用戶提供的標(biāo)注數(shù)據(jù),這可能會非常昂貴和耗時。
標(biāo)注噪聲:由于人類標(biāo)注的主觀性和誤差,數(shù)據(jù)中可能存在噪聲,這可能會影響模型的性能。
領(lǐng)域特異性:從人類偏好中學(xué)習(xí)的模型可能會在不同領(lǐng)域之間表現(xiàn)不佳,因為偏好可能因領(lǐng)域而異。
研究人員正在探索如何在從人類偏好中學(xué)習(xí)時提高效率和性能,例如使用主動學(xué)習(xí)、遷移學(xué)習(xí)、半監(jiān)督學(xué)習(xí)等方法。
9. 改進(jìn)聊天界面的效率
聊天界面是LLMs與用戶交互的方式之一,但目前仍然存在一些效率和可用性方面的問題。例如:
多消息對話:在多輪對話中,模型可能會遺忘之前的上下文,導(dǎo)致交流不連貫。
多模態(tài)輸入:用戶可能會在消息中混合文本、圖像、聲音等不同模態(tài)的信息,模型需要適應(yīng)處理這些多樣的輸入。
對話歷史和上下文管理:在長時間對話中,模型需要有效地管理對話歷史和上下文,以便準(zhǔn)確回應(yīng)用戶的問題和指令。
改進(jìn)聊天界面的效率和用戶體驗是一個重要的研究方向,涉及到自然語言處理、人機交互和設(shè)計等多個領(lǐng)域的知識。
-
AI
+關(guān)注
關(guān)注
87文章
31028瀏覽量
269384 -
人工智能
+關(guān)注
關(guān)注
1792文章
47373瀏覽量
238877 -
模型
+關(guān)注
關(guān)注
1文章
3255瀏覽量
48902
發(fā)布評論請先 登錄
相關(guān)推薦
【「大模型啟示錄」閱讀體驗】對大模型更深入的認(rèn)知
使用vLLM+OpenVINO加速大語言模型推理

高效大模型的推理綜述

國產(chǎn)大模型發(fā)展的經(jīng)驗與教訓(xùn)

當(dāng)前主流的大模型對于底層推理芯片提出了哪些挑戰(zhàn)
大模型發(fā)展下,國產(chǎn)GPU的機會和挑戰(zhàn)

在PyTorch中搭建一個最簡單的模型
AI大模型的發(fā)展歷程和應(yīng)用前景

大模型發(fā)展下,國產(chǎn)GPU的機會和挑戰(zhàn)(上)
助聽器降噪神經(jīng)網(wǎng)絡(luò)模型
【大語言模型:原理與工程實踐】大語言模型的應(yīng)用
【大語言模型:原理與工程實踐】大語言模型的評測
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》
工業(yè)大模型的五個基本問題

大模型時代,國產(chǎn)GPU面臨哪些挑戰(zhàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論