 Nature:人工智能芯片!
Nature:人工智能芯片!
具有數十億參數的人工智能(AI)模型可以在一系列任務中實現高精度,但它們加劇了傳統通用處理器(例如圖形處理單元或中央處理單元)的低能效。模擬內存計算(模擬 AI)可以通過在“內存塊”上并行執行矩陣向量乘法來提供更好的能源效率。然而,模擬人工智能尚未在需要許多此類圖塊以及圖塊之間神經網絡激活的有效通信的模型上證明軟件等效(SWeq)準確性。
有鑒于此,美國IBM 研究中心S. Ambrogio(一作兼通訊)等人展示了一款14 nm的模擬 AI 芯片,該芯片結合了跨 34 個區塊的 3500 萬個相變存儲器件、大規模并行區塊間通信和模擬低功耗外圍電路,可實現12.4 萬億次 / 秒 / 瓦運算性能,能效是傳統數字計算機芯片的14倍。作者展示了小型關鍵字識別網絡的完全端到端 SWeq 精度,以及更大的 MLPerf 循環神經網絡傳感器 (RNNT) 上接近 SWeq 的精度,其中超過4500萬個權重映射到跨越5個芯片的1.4億個相變存儲器件上。
芯片架構
作者展示了芯片的顯微照片,突出顯示了34個模擬塊的 2D 網格,每個塊都有512×2048PCM 交叉陣列。當持續時間向量從模擬快發送到OLP時,芯片有效地實現了基于斜坡的模數轉換器 (ADC)。所有權重配置、MAC操作和路由方案均由每個圖塊上可用的用戶可配置本地控制器(LC) 定義。本地SRAM存儲定義數百個控制信號的時間序列的所有指令,從而實現高度靈活的測試并簡化設計驗證,與預定義狀態機相比,面積損失較小。作者驗證了持續時間可以在整個芯片上可靠地傳輸,最大誤差等于5ns(較短持續時間為 3ns)。
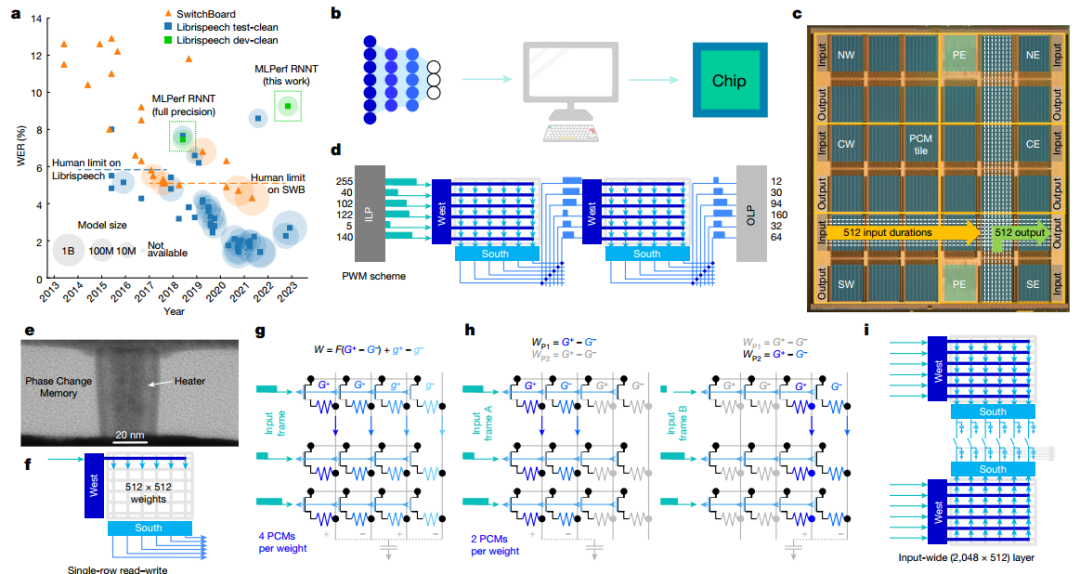
圖 芯片架構
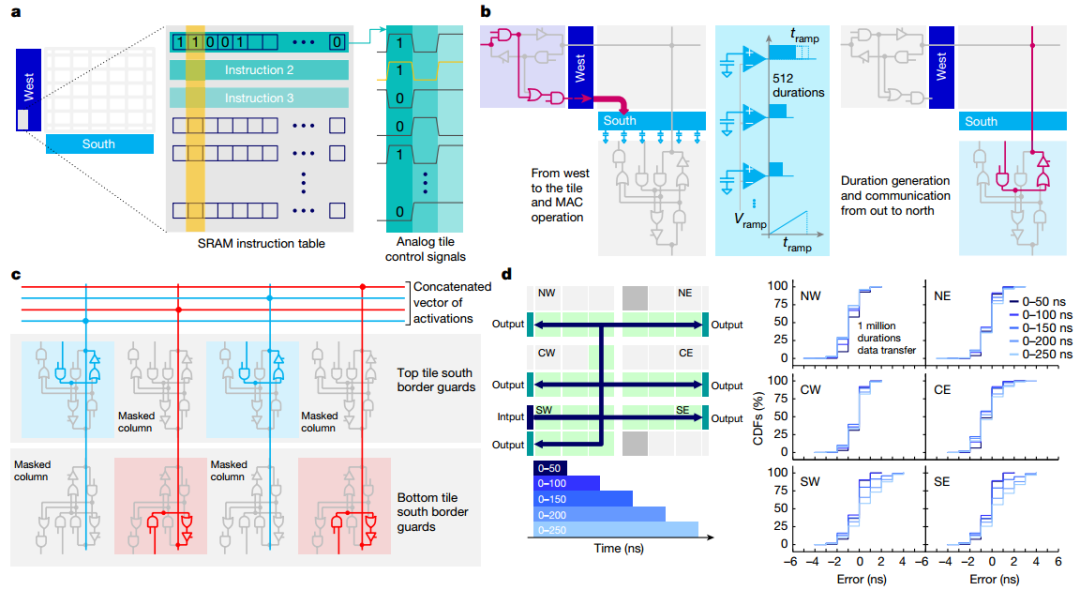
圖 可重構架構和路由
KWS任務
為了演示芯片在端到端網絡中的性能,實現了多類KWS任務。作者采用了 FC網絡,實現了 86.75% 的分類準確度。為了在芯片上實現完全端到端的傳輸,作者進行了一系列修改,最終端到端實現總共使用四個圖塊。為了提高MAC精度并補償外圍電路的不對稱性,引入了MAC不對稱平衡(AB)方法,測得的KWS精度為86.14%,完全在 MLPerf SWeq“等精度”極限 85.88%之內。
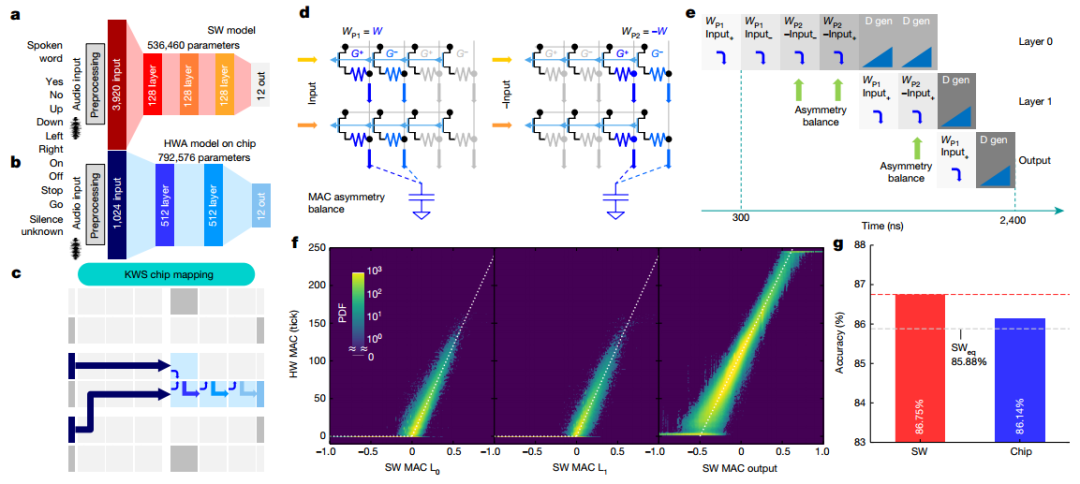
圖 端到端 KWS 任務
芯片上的 RNNT 映射
作者實施了MLPerf數據中心網絡RNNT作為行業相關的工作負載演示。當 RNNT等大型DNN以降低的數字精度實現時,整個網絡的最佳精度選擇可能會有所不同。研究表明即使使用激進的量化,不易受影響的層或整個網絡塊仍將提供較低的 WER,而高度敏感的塊即使對于少量的權重量化也將表現出較高的 WER。對每個單獨的層重復此過程以識別最敏感的層,接著將 MLPerf 權重映射到分布在5個芯片上的142個圖塊上。在總共 45,321,309 個網絡權重和偏差參數中,45,261,568 個被映射到模擬存儲器(權重的 99.9%)。
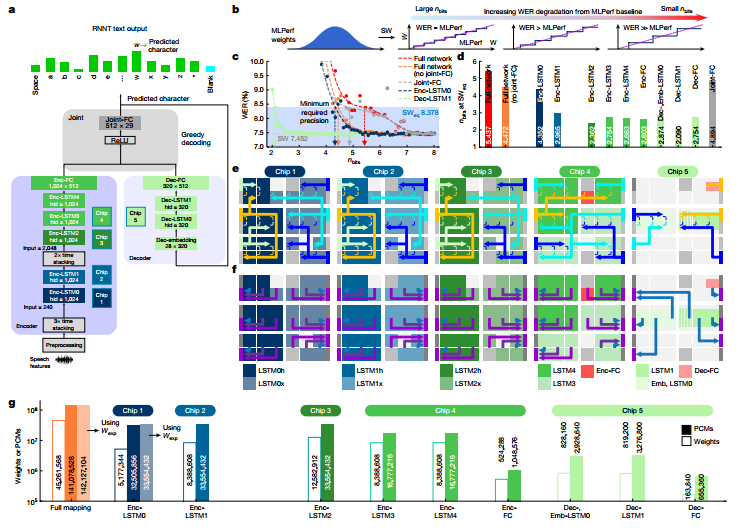
圖 用于語音轉錄的 MLPerf RNNT 網絡
準確度結果
作者展示了2513個音頻查詢的完整 Librispeech 驗證數據集的權重映射和編程后的實驗WER。總WER為9.475%,與SW 基線相比總體下降了 2.02%。在本實驗中,通過芯片推斷完整的Librispeech驗證數據集并保存輸出結果。然后將這些輸入到芯片 2 中,依此類推,輸入到所有 5 個芯片中。即使在PCM漂移超過1周后重復進行,且沒有任何重新校準或重量重新編程,RNNT WER 也僅下降了 0.4%。
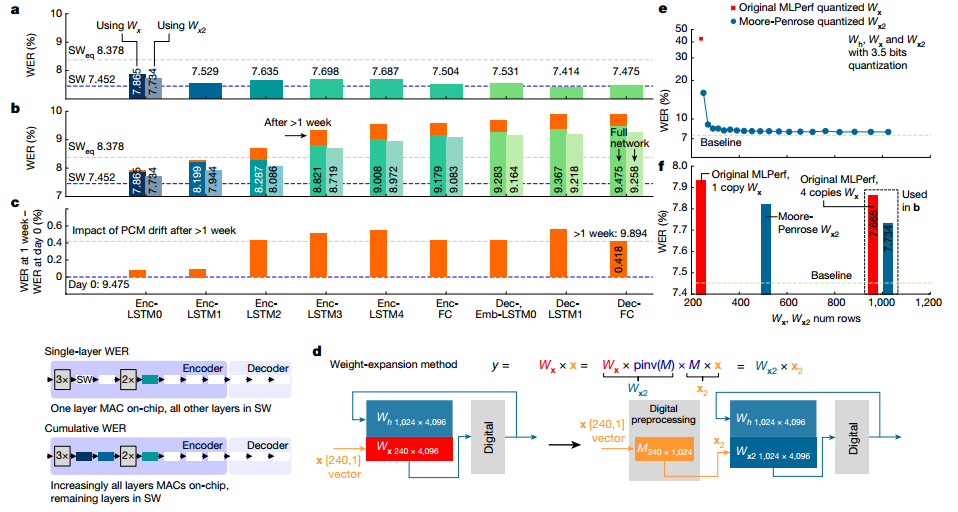
圖 在 MLPerf RNNT上使用Librispeech進行WER實驗
電源和系統性能
作者還測量了推理操作期間每個芯片的全部功耗。所有控制和通信電路均以 0.8V 驅動。芯片最佳功率性能 為12.40 TOPS/W。通過將積分時間減半,芯片的 TOPS/W 可以再提高 25%,但 WER 會額外降低1%。隨著重量的增加,使用本文報道的芯片的模擬人工智能系統可以在3.57W的功率下實現6.704TOPS/W,比MLPerf的最佳能效提高了14 倍,WER 為 9.258%。

圖 MLPerf RNNT功率和系統性能
-
芯片
+關注
關注
456文章
51157瀏覽量
427092 -
人工智能
+關注
關注
1796文章
47643瀏覽量
240223 -
存儲器件
+關注
關注
1文章
32瀏覽量
9707
原文標題:Nature:人工智能芯片!
文章出處:【微信號:wc_ysj,微信公眾號:旺材芯片】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論