 應用筆記 | STM32L4R9 的QuadSPI Flash 通訊速率不理想
應用筆記 | STM32L4R9 的QuadSPI Flash 通訊速率不理想
關鍵字:Octo-SPI, Quad Serial Flash
目錄預覽
1 引言2 問題分析3 問題解決
4 小結
1. 引言
客戶反應STM32L4R9 同QSPI Flash 通訊,測出來的讀取速率為10MB/s, 和理論值相差較大。
2.問題分析
按照客戶的時鐘配置和STM32L4R9 的數據手冊中的數據,OSPI 讀數速率為10MB/s肯定存在問題。同時我們也可以在AN4760 應用手冊中看到如下說明:

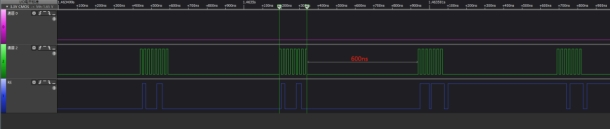
在客戶系統中,IO0~IO3的4線通訊模式下信號波形如下圖,可以看出每經過8 個CLK周期就有很長一段時間的延時。如果提高CPU的主頻,這個延時會縮短,但客戶測到最短的延時也有200ns,并且一直存在:
3.問題解決
從客戶測試波形上看,由于是4條數據線,因此8個clock正好是4bytes,也就是32bits數據。懷疑STM32L4R9 QSPI在DMA通訊中,讀到一個word(32bits)數據后需要在內部做一定的數據處理,造成時間延遲。
分析代碼發現,DMA設置的是byte傳輸模式,如下面代碼:
#define BUFFERSIZE (COUNTOF(aTxBuffer) - 1)
hdma.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;
hdma.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;
STM32L4R9是Cortex-M4 內核,系統總線是32bits的,懷疑是在32bit總線上傳輸byte數據會降低效率,造成延遲,于是修改代碼如下:
示例代碼在下面路徑,需要使用附件中的main.c文件替換掉下面文件中的main.c:
…STM32Cube_FW_L4_VxxProjects32L4R9IDISCOVERYExamplesOSPIOSPI_NOR_ReadWrite_DMAEWARM
另外程序中做如下改動:
#define BUFFERSIZE 1024 // (COUNTOF(aTxBuffer) - 1)
hdma.Init.PeriphDataAlignment = DMA_PDATAALIGN_WORD;
hdma.Init.MemDataAlignment = DMA_PDATAALIGN_WORD;
配置時請留意OSPIHandle.Init.FifoThreshold = 4; //也需要4的倍數。
修改代碼后進行測試,代碼讀 4096bytes的圖像(1026 words),發現每個word數據中間的延遲已經沒有了。之前速度提不上去的問題是DMA byte設置引起,因為STM32L4R9是32bits系統,使用8bits傳輸會降低效率,需要改為DMA 32bits配置就OK了。圖形數據傳輸的總字節數也要設置為4的倍數,不足的需要補齊。
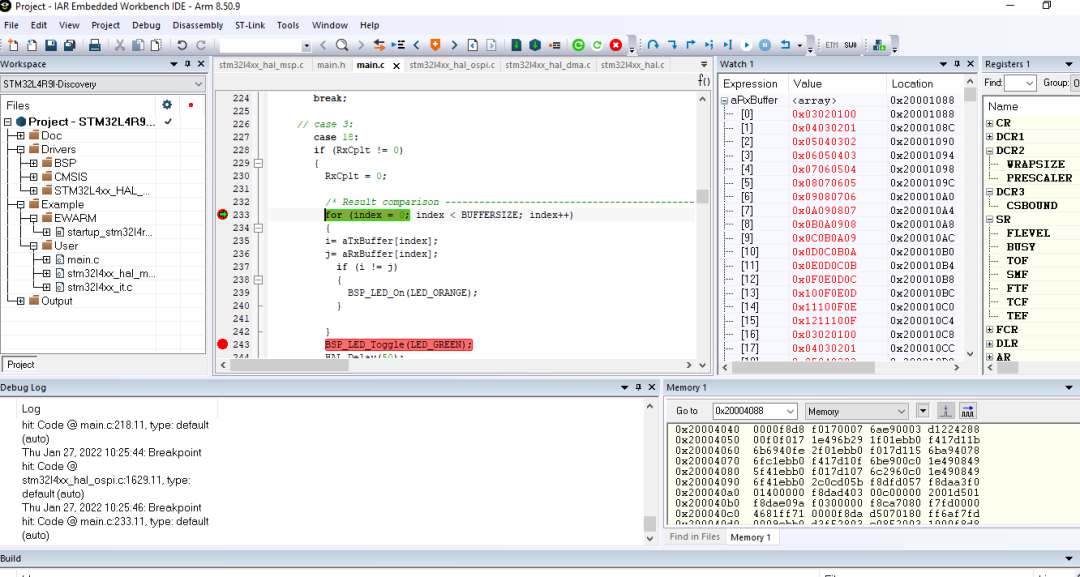
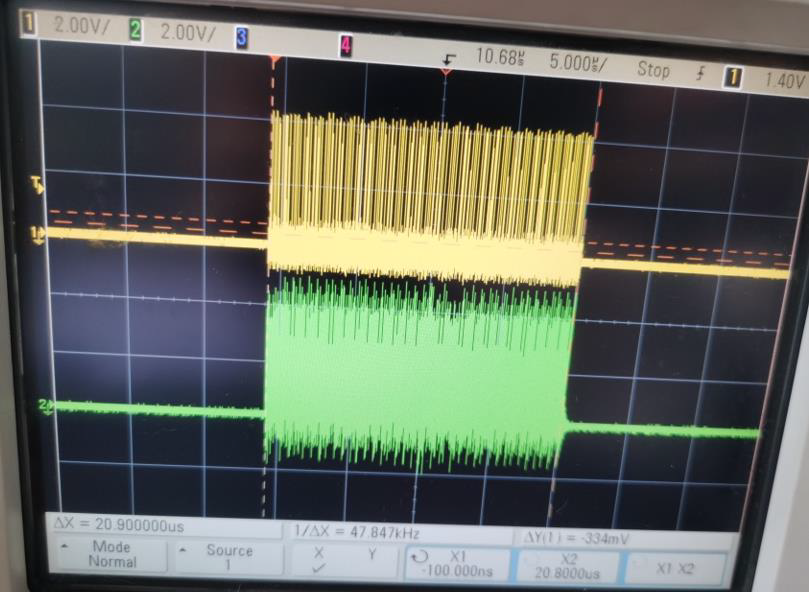
DMA改為word設置后數據傳輸時沒有延遲
4. 小結
對32位系統來說,使用byte的數據傳輸在一些情況下會降低效率,建議對32bits系統使用32bits的數據傳輸方式。
完整內容請點擊“閱讀原文”下載原文檔。

長按掃碼關注公眾號
更多資訊,盡在STM32
▽點擊“閱讀原文”,可下載原文檔
-
單片機
+關注
關注
6039文章
44583瀏覽量
636519 -
STM32
+關注
關注
2270文章
10910瀏覽量
356611
原文標題:應用筆記 | STM32L4R9 的QuadSPI Flash 通訊速率不理想
文章出處:【微信號:STM32_STM8_MCU,微信公眾號:STM32單片機】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于Pytorch訓練并部署ONNX模型在TDA4應用筆記






 工商網監
工商網監
評論