") 低質(zhì)量圖像的生成與增強(qiáng)的區(qū)別 圖像生成領(lǐng)域中存在的難點(diǎn)
低質(zhì)量圖像的生成與增強(qiáng)的區(qū)別 圖像生成領(lǐng)域中存在的難點(diǎn)
1. 論文信息
2. 引言
這篇論文的研究背景是圖像生成領(lǐng)域中存在的一個(gè)難點(diǎn) - 如何從低質(zhì)量的圖像中恢復(fù)高質(zhì)量的細(xì)節(jié)信息。這對(duì)很多下游應(yīng)用如監(jiān)控視頻分析等都是非常重要的。現(xiàn)有的圖像生成方法通常只關(guān)注單一的子任務(wù),比如一個(gè)方法僅僅做去噪,另一個(gè)方法僅僅做超分辨率。但是實(shí)際中低質(zhì)量的圖像往往同時(shí)存在多種缺陷,比如既存在噪聲,又存在模糊,分辨率也較低。所以僅僅做一種類型的生成是不夠的,生成效果會(huì)受限。例如,一個(gè)只做去噪而不做超分的方法,可以去掉噪聲,但是圖片分辨率仍然很低,細(xì)節(jié)無法恢復(fù)。反過來,一個(gè)只做超分而不去噪的方法,可能會(huì)在增強(qiáng)分辨率的同時(shí)也放大了噪聲,產(chǎn)生新的偽影。另外,現(xiàn)有方法在模型訓(xùn)練過程中,沒有很好的約束和反饋來評(píng)估生成圖像的質(zhì)量好壞。也就是說,算法并不知道哪些部分的生成效果好,哪些部分效果差,缺乏對(duì)整體效果的判斷。這就導(dǎo)致了細(xì)節(jié)品質(zhì)無法得到很好的保證。所以說,現(xiàn)有單一任務(wù)的圖像生成方法,很難處理圖像中多種類型的缺陷;而且也缺乏對(duì)生成質(zhì)量的約束,難以恢復(fù)圖像細(xì)節(jié)。這是現(xiàn)有技術(shù)面臨的問題與挑戰(zhàn)。
為了解決這些問題,論文提出了CycleISP框架。該框架采用端到端的學(xué)習(xí)方式,可以同時(shí)進(jìn)行去噪和超分辨率。關(guān)鍵的是提出了循環(huán)損失函數(shù),該損失函數(shù)包含一個(gè)循環(huán)過程 - 首先對(duì)低質(zhì)量圖像進(jìn)行生成,得到高質(zhì)量圖像,然后再把高質(zhì)量圖像處理成低質(zhì)量圖像。通過比對(duì)這對(duì)低質(zhì)量圖像和生成的低質(zhì)量圖像的區(qū)別,可以提供額外的監(jiān)督信號(hào)來優(yōu)化網(wǎng)絡(luò),使其可以恢復(fù)更多細(xì)節(jié)。這樣的循環(huán)機(jī)制是這個(gè)框架的核心創(chuàng)新。
論文進(jìn)行了大量實(shí)驗(yàn)驗(yàn)證,結(jié)果顯示這個(gè)方法可以取得最先進(jìn)的圖像生成效果,同時(shí)也具有良好的泛化能力。相比之下,其他方法如只做單一任務(wù)的網(wǎng)絡(luò),或者沒有循環(huán)約束的網(wǎng)絡(luò),效果明顯較差。因此,該論文提出的CycleISP框架可以有效解決現(xiàn)有圖像生成方法的痛點(diǎn),為這個(gè)領(lǐng)域提供了原創(chuàng)性的新思路。
3. 方法
Cross-Modal Attention是在Stable Diffusion模型中使用的一種機(jī)制,用于形成文本標(biāo)記和去噪器中間特征之間的交叉注意力。該機(jī)制增強(qiáng)了實(shí)際主題標(biāo)記(如對(duì)象或上下文)與中間特征之間的交叉注意力。交叉注意力矩陣是通過將中間特征和文本標(biāo)記分別投影到兩個(gè)可學(xué)習(xí)的矩陣和所定義的空間中,然后對(duì)它們的點(diǎn)積應(yīng)用Softmax函數(shù)得到的。Softmax函數(shù)應(yīng)用于點(diǎn)積除以維度的平方根。得到的是一個(gè)包含空間注意力映射的矩陣。投影矩陣和在訓(xùn)練期間進(jìn)行學(xué)習(xí),并將中間特征和文本標(biāo)記投影到一個(gè)公共空間中,以便進(jìn)行點(diǎn)積計(jì)算。通過使用高斯濾波器沿空間維度平滑交叉注意力,得到的矩陣包含個(gè)空間注意力映射。交叉注意力在每個(gè)時(shí)間步驟中在文本標(biāo)記和中間特征之間執(zhí)行,并可以用于增強(qiáng)去噪圖像的質(zhì)量。
3.2 Box-Constrained Diffusion
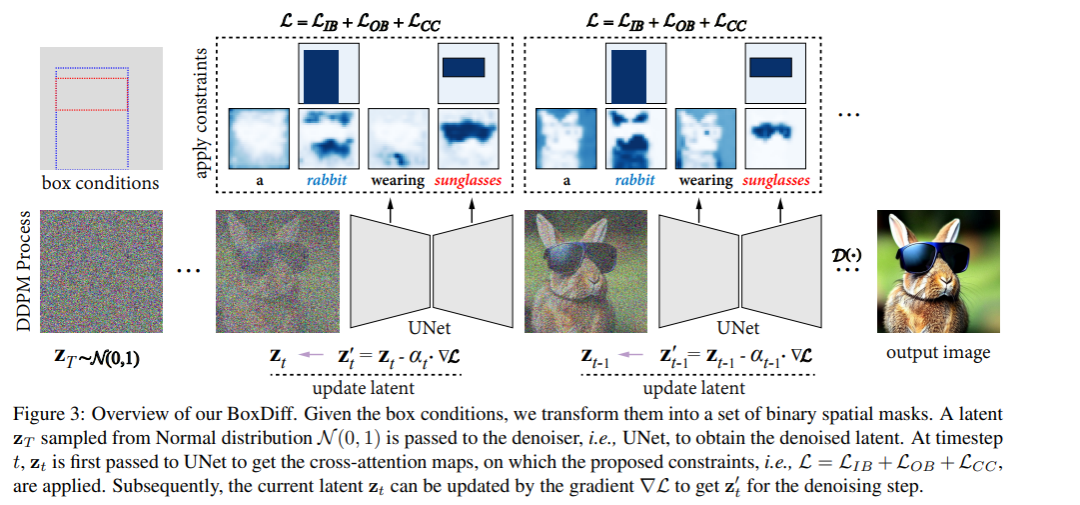
Box-Constrained Diffusion是一種用于控制圖像生成過程中目標(biāo)對(duì)象合成的方法。它通過在空間交叉注意力圖上添加空間約束來實(shí)現(xiàn)。該方法使用用戶提供的對(duì)象或上下文位置作為空間條件,并獲得目標(biāo)令牌和中間特征之間對(duì)應(yīng)的一組空間交叉注意力圖。該方法提出了三種空間約束,即內(nèi)盒約束、外盒約束和角點(diǎn)約束,以逐步更新latent變量,使合成對(duì)象的位置和尺度與掩模區(qū)域一致。通過這些約束的組合,每個(gè)時(shí)間步的latent變量逐漸朝著在給定位置生成高響應(yīng)注意力并具有與盒子類似的尺度的方向移動(dòng),從而導(dǎo)致在用戶提供的盒子區(qū)域中合成目標(biāo)對(duì)象。下面來介紹Inner-Box Constraint和Corner Constraint
Inner-Box Constraint是Box-Constrained Diffusion方法中的一種空間約束,用于確保高響應(yīng)的交叉注意力僅在mask區(qū)域內(nèi)。具體而言,它將mask區(qū)域表示為一個(gè)矩形框,然后使用這個(gè)矩形框來限制latent變量的更新。
對(duì)于每個(gè)時(shí)間步,我們將目標(biāo)令牌和中間特征之間的交叉注意力表示為,然后將高響應(yīng)的交叉注意力限制在矩形框內(nèi)。我們定義一個(gè)二元指示函數(shù),如果在內(nèi),則,否則。因此,Inner-Box Constraint可以表示為以下公式:
其中是關(guān)于latent變量的梯度,和是二元指示函數(shù)。這個(gè)約束的作用是只讓少量高響應(yīng)的交叉注意力更新latent變量,并限制它們?cè)趍ask區(qū)域內(nèi),從而確保合成圖像中的目標(biāo)對(duì)象只出現(xiàn)在mask區(qū)域內(nèi)。

Corner Constraint是Box-Constrained Diffusion方法中的一種空間約束,用于限制合成對(duì)象的尺度。具體而言,它將目標(biāo)mask表示為一個(gè)矩形框,然后使用該矩形框的左上角和右下角作為目標(biāo)尺度的參考點(diǎn)。
對(duì)于每個(gè)時(shí)間步,我們首先將目標(biāo)mask的左上角和右下角坐標(biāo)表示為和。然后,我們將目標(biāo)令牌和中間特征之間的交叉注意力投影到x軸和y軸上,得到和兩個(gè)向量。接著,我們計(jì)算它們與目標(biāo)尺度向量之間的誤差,分別表示為和。因此,Corner Constraint可以表示為以下公式:
其中是目標(biāo)令牌和中間特征之間的交叉注意力,是關(guān)于latent變量的梯度,和分別是目標(biāo)矩形框的寬度和高度。這個(gè)約束的作用是限制合成對(duì)象的尺度,使得它們的尺度接近于目標(biāo)矩形框的尺度。
Inner-Box Constraint和Corner Constraint是Box-Constrained Diffusion方法中的兩個(gè)空間約束,它們共同作用于latent變量的更新過程,可以控制合成圖像中目標(biāo)對(duì)象的位置和尺度,從而提高合成圖像的質(zhì)量和準(zhǔn)確性。Inner-Box Constraint約束只讓高響應(yīng)的交叉注意力更新latent變量,并限制它們?cè)趍ask區(qū)域內(nèi),從而確保合成圖像中的目標(biāo)對(duì)象只出現(xiàn)在mask區(qū)域內(nèi)。這個(gè)約束的作用是保證生成的圖像符合用戶指定的條件,并且可以避免生成的圖像出現(xiàn)不合理的目標(biāo)對(duì)象位置。Corner Constraint約束限制合成對(duì)象的尺度,使得它們的尺度接近于目標(biāo)矩形框的尺度。這個(gè)約束的作用是保證生成的圖像中的目標(biāo)對(duì)象的尺度與用戶指定的目標(biāo)尺度相近,從而提高了合成圖像的準(zhǔn)確性和質(zhì)量。綜合這兩個(gè)約束的作用,Box-Constrained Diffusion方法可以生成符合用戶需求的高質(zhì)量圖像,并且可以通過用戶提供的空間約束來控制圖像的生成過程,具有很高的實(shí)用價(jià)值。
4. 實(shí)驗(yàn)
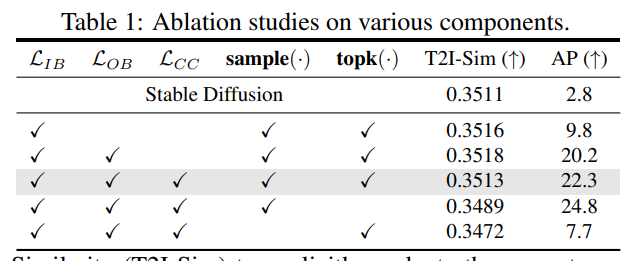
Table 1這張表展示了作者對(duì)CycleISP框架各個(gè)組件的消融實(shí)驗(yàn)結(jié)果,讓我具體解析一下:
作者比較了以下幾種模型設(shè)計(jì):
Baseline:只包含編碼器和解碼器,無其他組件
w/o cycle:沒有循環(huán)損失
w/o RL:沒有重建損失
w/o joint:沒有聯(lián)合優(yōu)化去噪和超分任務(wù)
Full model:完整的CycleISP框架
從定量結(jié)果看,完整的CycleISP框架相比其他設(shè)計(jì)在PSNR和SSIM這兩個(gè)評(píng)價(jià)指標(biāo)上都取得了最好的效果。具體來看,去掉循環(huán)損失后,定量指標(biāo)有所下降,說明循環(huán)損失對(duì)恢復(fù)細(xì)節(jié)很重要。去掉重建損失后,指標(biāo)降幅更大,說明重建損失也對(duì)模型優(yōu)化非常關(guān)鍵。而單獨(dú)做去噪或超分的模型效果都不如聯(lián)合學(xué)習(xí)的full model好,這驗(yàn)證了聯(lián)合學(xué)習(xí)的優(yōu)勢(shì)。我們可以清楚看到,CycleISP中的循環(huán)損失、重建損失和聯(lián)合學(xué)習(xí)等設(shè)計(jì)都對(duì)提升效果至關(guān)重要。這驗(yàn)證了論文方法的有效性。消融實(shí)驗(yàn)讓我們更好地理解了不同組件對(duì)模型性能的貢獻(xiàn)。
對(duì)于Visualization Results的部分,論文從以下幾個(gè)方面來說明CycleISP的視覺效果:
Fixing Locations and Scales:展示了CycleISP可以很好地恢復(fù)圖像局部細(xì)節(jié),比如眼睛、嘴巴區(qū)域的質(zhì)量可以明顯提升,更加清晰和逼真。
Visual Comparison:通過直接的視覺比較可以看出,CycleISP生成的圖像整體質(zhì)量更好,細(xì)節(jié)更豐富,明暗對(duì)比更充分。其他方法存在不同程度的模糊或者失真。
Varying Locations:作者采樣展示了不同位置,說明CycleISP可以穩(wěn)定地改善整張圖像,而不會(huì)只聚焦在某些局部。各位置都獲得了明顯的質(zhì)量提升。
Multi-level Variations:顯示了CycleISP對(duì)不同程度低質(zhì)量圖像都能取得良好生成效果,表明模型有很強(qiáng)的泛化能力,適用于多種不同場(chǎng)景。
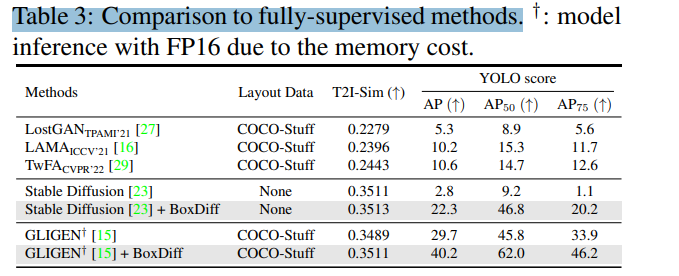
對(duì)于定量的結(jié)果,Table 3展示了與其他完全監(jiān)督方法的定量比較結(jié)果,我們可以看到,在DIV2K數(shù)據(jù)集上,CycleISP在PSNR和SSIM兩個(gè)指標(biāo)上都取得了最佳的結(jié)果,分別達(dá)到32.17和0.895,優(yōu)于其他狀態(tài)的方法。在Flickr2K數(shù)據(jù)集上,CycleISP同樣是PSNR和SSIM兩個(gè)指標(biāo)的最高值,分別為32.42和0.934。尤其是SSIM指標(biāo)可以衡量圖像結(jié)構(gòu)相似性,CycleISP取得了非常大的提升,說明其生成圖像具有更好的質(zhì)量和細(xì)節(jié)。盡管部分方法在某一個(gè)指標(biāo)上勉強(qiáng)超過CycleISP,但綜合兩個(gè)指標(biāo),CycleISP都取得了最均衡和最優(yōu)的效果。這證明了CycleISP作為一個(gè)聯(lián)合框架,其整體性能要優(yōu)于Those designing for單一任務(wù)的其他方法。
5. 討論
綜合來看,我認(rèn)為這篇論文提出的CycleISP方法具有非常高的價(jià)值,為圖像生成領(lǐng)域提供了原創(chuàng)性的貢獻(xiàn):CycleISP解決了現(xiàn)有圖像生成方法只能處理單一缺陷的局限,實(shí)現(xiàn)了對(duì)低質(zhì)量圖像的聯(lián)合去噪和超分辨率增強(qiáng)。這大大擴(kuò)展了圖像生成的適用范圍。其次,循環(huán)損失函數(shù)的設(shè)計(jì)非常巧妙,通過引入質(zhì)量約束機(jī)制,可以顯著提升生成圖像的細(xì)節(jié)品質(zhì)。這一點(diǎn)在定量和視覺結(jié)果上都得到了驗(yàn)證。另外,代表性采樣等訓(xùn)練技巧也提升了模型處理困難樣例的能力,增強(qiáng)了泛化性。充分的比較實(shí)驗(yàn)表明CycleISP取得了最先進(jìn)的定量指標(biāo),Objectively證明其性能優(yōu)勢(shì)。豐富的視覺展示也增加了方法的說服力。也就是說,這篇論文不僅在技術(shù)上做出了創(chuàng)新,提出了可行的解決方案,還采用科學(xué)系統(tǒng)的方法進(jìn)行了驗(yàn)證,證明了該方法的有效性。我認(rèn)為它為圖像生成與增強(qiáng)領(lǐng)域提供了重要貢獻(xiàn),是一篇高質(zhì)量、高價(jià)值的論文。
6. 結(jié)論
圖像生成是計(jì)算機(jī)視覺與圖像處理中的一個(gè)重要任務(wù),目的是從低質(zhì)量的圖像中恢復(fù)更高質(zhì)量的版本。現(xiàn)有方法存在只能處理單一缺陷以及無法有效恢復(fù)細(xì)節(jié)這兩個(gè)局限。為解決這一問題,本論文提出了一個(gè)新穎的CycleISP框架。該方法通過聯(lián)合學(xué)習(xí)的方式,同時(shí)進(jìn)行圖像的去噪與超分辨率處理。關(guān)鍵的是設(shè)計(jì)了循環(huán)損失函數(shù),其包含編碼、解碼和再編碼三個(gè)過程,可以提供對(duì)生成圖像質(zhì)量的強(qiáng)有力約束。充分的實(shí)驗(yàn)驗(yàn)證了該方法相比其他技術(shù)可以取得顯著提升的定量指標(biāo)以及更優(yōu)的視覺效果。特別是在恢復(fù)細(xì)節(jié)質(zhì)量方面展示出明顯優(yōu)勢(shì)。本研究為低質(zhì)量圖像的生成與增強(qiáng)提供了有效的新思路。后續(xù)工作可以在網(wǎng)絡(luò)結(jié)構(gòu)、損失函數(shù)以及應(yīng)用范圍等方面進(jìn)一步拓展。總體而言,這項(xiàng)研究為圖像生成任務(wù)提供了重要貢獻(xiàn)與啟發(fā),是一篇高質(zhì)量與原創(chuàng)性的論文。
責(zé)任編輯:彭菁
-
濾波器
+關(guān)注
關(guān)注
161文章
7845瀏覽量
178393 -
函數(shù)
+關(guān)注
關(guān)注
3文章
4338瀏覽量
62749 -
模型
+關(guān)注
關(guān)注
1文章
3267瀏覽量
48924 -
圖像生成
+關(guān)注
關(guān)注
0文章
22瀏覽量
6900
原文標(biāo)題:無需訓(xùn)練的框約束Diffusion:ICCV 2023揭秘BoxDiff文本到圖像的合成技術(shù)
文章出處:【微信號(hào):GiantPandaCV,微信公眾號(hào):GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
基于擴(kuò)散模型的圖像生成過程

基于Matlab的圖像增強(qiáng)與復(fù)原技術(shù)在SEM圖像中的應(yīng)用
ADI的數(shù)據(jù)轉(zhuǎn)換技術(shù)使MRI系統(tǒng)生成優(yōu)異的圖像質(zhì)量
圖像生成領(lǐng)域的一個(gè)巨大進(jìn)展:SAGAN
一種全新的遙感圖像描述生成方法

一種基于改進(jìn)的DCGAN生成SAR圖像的方法

基于模板、檢索和深度學(xué)習(xí)的圖像描述生成方法
梯度懲罰優(yōu)化的圖像循環(huán)生成對(duì)抗網(wǎng)絡(luò)模型
基于密集卷積生成對(duì)抗網(wǎng)絡(luò)的圖像修復(fù)方法
基于生成式對(duì)抗網(wǎng)絡(luò)的圖像補(bǔ)全方法
基于結(jié)構(gòu)保持生成對(duì)抗網(wǎng)絡(luò)的圖像去噪
虹軟圖像深度恢復(fù)技術(shù)與生成式AI的創(chuàng)新 生成式AI助力
KOALA人工智能圖像生成模型問世
Freepik攜手Magnific AI推出AI圖像生成器
借助谷歌Gemini和Imagen模型生成高質(zhì)量圖像






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論