 浮點運算的尾數部分是如何轉變成二進制的?
浮點運算的尾數部分是如何轉變成二進制的?
正文

然后看到這篇關于浮點數的文章,希望大家看了之后有所啟發。
想一下,為什么第一個打印的和預設值不同,但是第二個是相同的?
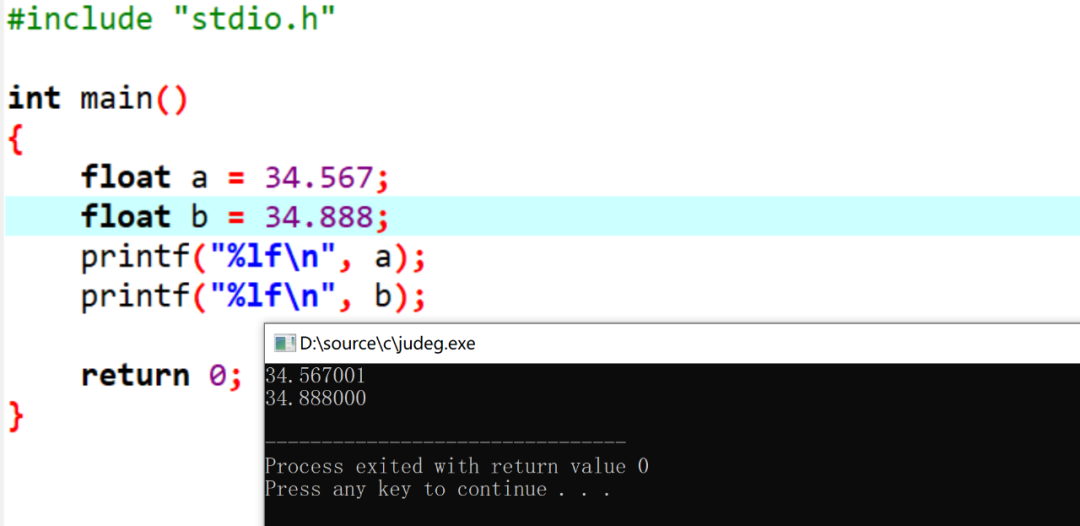
如圖:
尾數部分是如何轉變成二進制的?

前言
很多人在初學寫程式時都會遇到所謂的浮點誤差,如果你到目前都還沒被浮點誤差雷過,那只能說你真的很幸運XD。
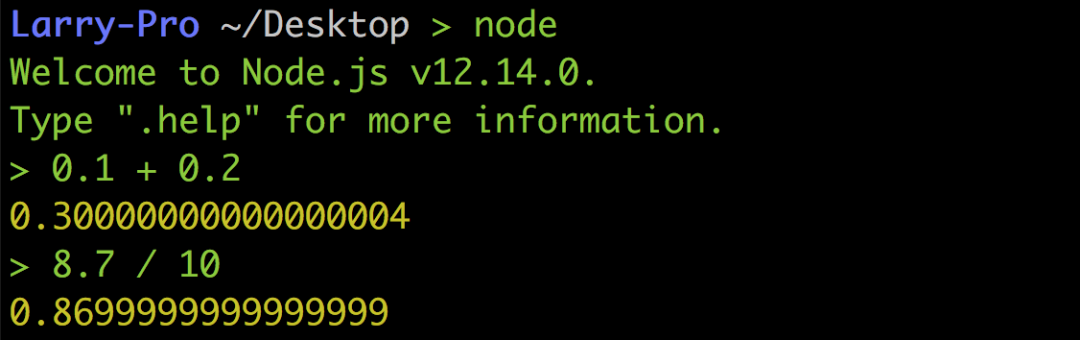
以下圖Python 的例子來說0.1 + 0.2并不等于0.3,8.7 / 10也不等于0.87,而是0.869999…,真的超怪der

但這絕對不是什么神bug,也不是Python 設計得不好,而是浮點數在做運算時必然的結果,所以即便是到了Node.js 或其他語言也都是一樣。
電腦如何儲存一個整數(Integer)
在講為什么會有浮點誤差之前,先來談談電腦是怎么用0 跟1 來表示一個整數,大家應該都知道二進制這個東西:像101代表22 + 2? 也就是5、1010代表23 + 21 也就是10。
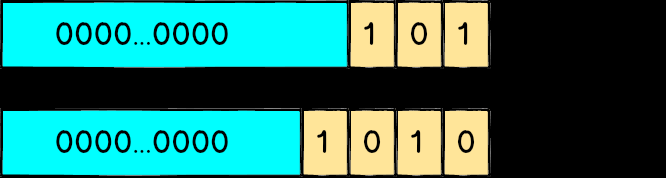
如果是一個unsigned 的32 bit 整數,代表他有32 個位置可以放0 或1,所以最小值就是0000...0000也就是0,而最大值1111...1111代表231 + 23? + … + 21 + 2? 也就是4294967295。
從排列組合的角度來想,因為每一個bit 都可以是0 或1,整個變數值有232 種可能性,所以可以精確的表達出0 到232-1 中任一個值,不會有任何誤差。
浮點數(Floating Point)
雖然從0 到232-1 之間有很多很多個整數,但數量終究是有限的,就是232 個那么多而已;但浮點數就大大的不同了,大家可以這樣想:在1 到10 這個區間中只有十個整數,但卻有無限多個浮點數,譬如說5.1、5.11、5.111 等等,再怎么數都數不完。
但因為在32 bit 的空間中就只有232 種可能性,為了把所有浮點數都塞在這個32 bit 的空間里面,許多CPU 廠商發明了各種浮點數的表示方式,但若各家CPU 的格式都不一樣也很麻煩,所以最后是以IEEE發布的IEEE 754作為通用的浮點數運算標準,后來的CPU 也都遵循這個標準進行設計。
IEEE 754
IEEE 754 里面定義了很多東西,其中包括單精度(32 bit)、雙精度(64 bit)跟特殊值(無窮大、NaN)的表示方式等。
正規化
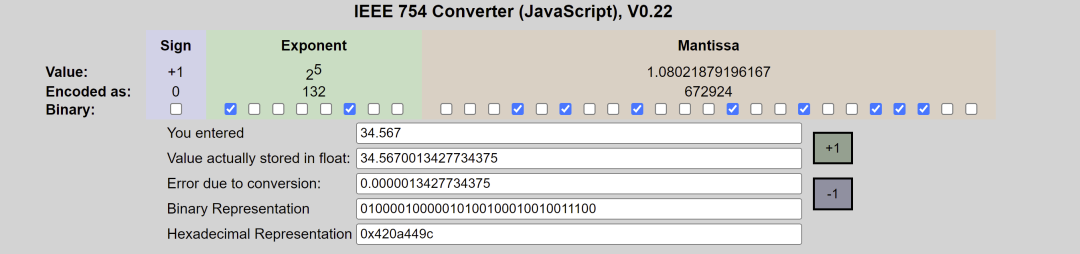
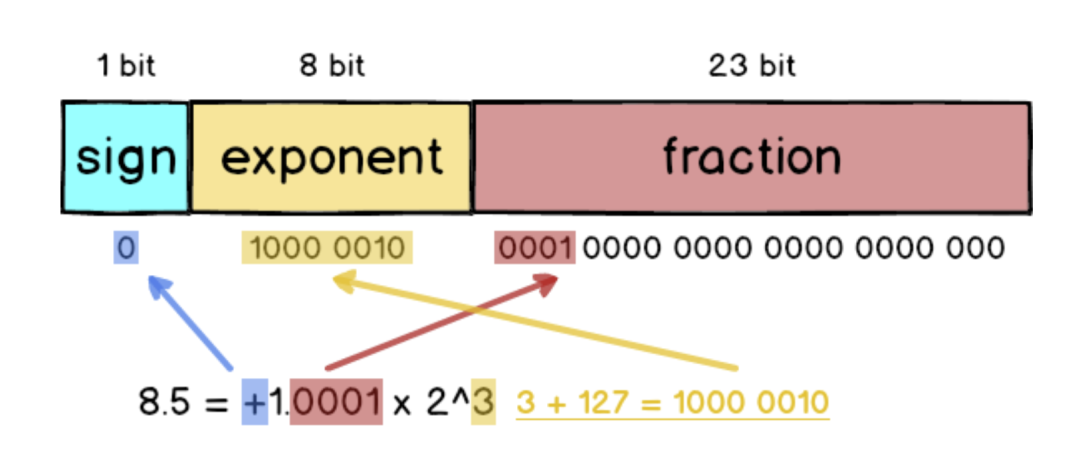
以8.5 這個符點數來說,如果要變成IEEE 754 格式的話必須先做正規化:把8.5 拆成8 + 0.5 也就是23 + 1/21,接著寫成二進位變成1000.1,最后再寫成1.0001 x 23,跟十進位的科學記號滿像的。
單精度浮點數
在IEEE 754 中32 bit 浮點數被拆成三個部分,分別是sign、exponent 跟fraction,加起來總共是32 個bit。
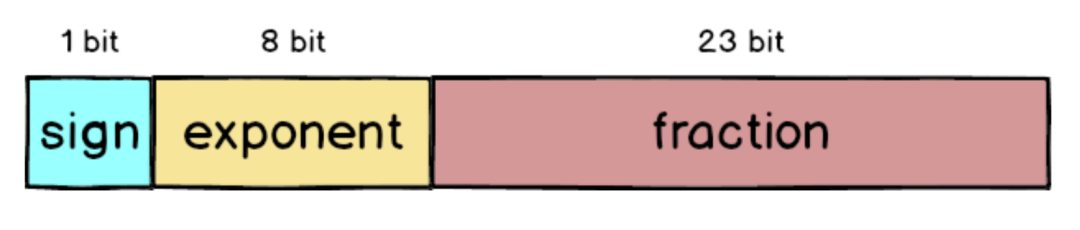
sign:最左側的1 bit 代表正負號,正數的話sign 就為0,反之則是 1。
exponent:中間的8 bit 代表正規化后的次方數,采用的是超127格式,也就是3 還要加上127 = 130。
fraction:最右側的23 bit 放的是小數部分,以1.0001 來說就是去掉1. 之后的000。
所以如果把8.5 表示成32 bit 格式的話就會是這樣:
這圖我畫超久的,請大家仔細看XD。
什么情況下會不準呢?
剛剛8.5 的例子可以完全表示為23+ 1/21,是因為8 跟0.5 剛好都是2 的次方數,所以完全不需要犧牲任何精準度。
但如果是8.9 的話因為沒辦法換成2 的次方數相加,所以最后會被迫表示成1.0001110011… x 23,而且還會產生大概0.0000003 的誤差,好奇結果的話可以到IEEE-754 Floating Point Converter網站上玩玩看。
雙精度浮點數
上面講的單精度浮點數只用了32 bit 來表示,為了讓誤差更小,IEEE 754 也定義了如何用64 bit 來表示浮點數,跟32 bit 比起來fraction 部分大了超過兩倍,從23 bit 變成52 bit,所以精準度自然提高許多。
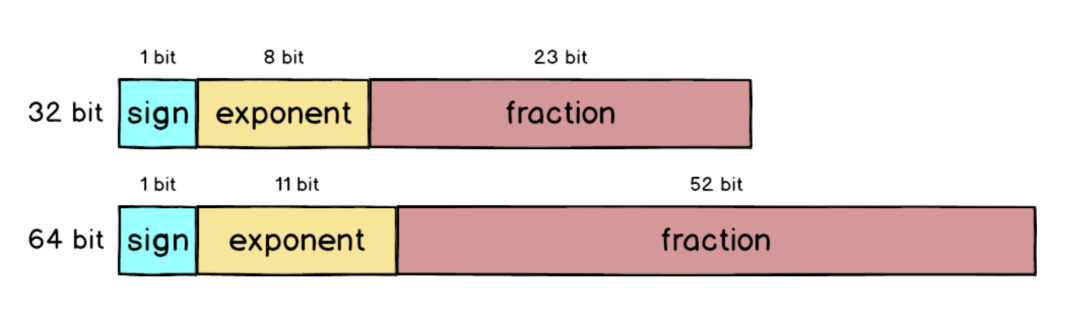
以剛剛不太準的8.9 為例,用64 bit 表示的話雖然可以變得更準,但因為8.9 無法完全寫成2 的次方數相加,到了小數下16 位還是出現誤差,不過跟原本的誤差0.0000003 比起來已經小了很多。

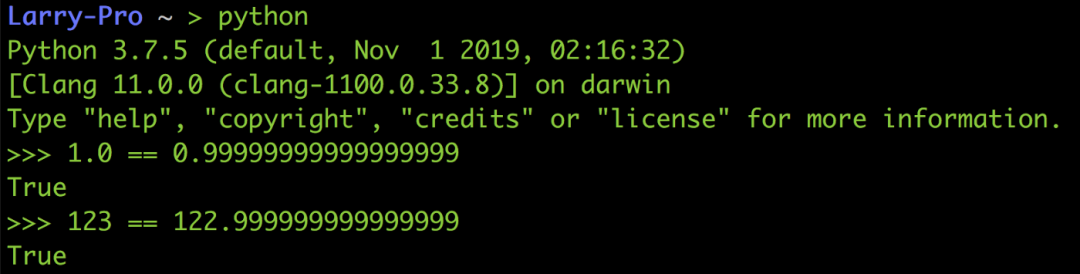
類似的情況還有像Python 中的1.0跟0.999...999是相等的、123跟122.999...999也是相等的,因為他們之間的差距已經小到無法放在fraction 里面,所以就二進制的格式看來他們每一個bit 都一樣。
解決方法
既然無法避免浮點誤差,那就只好跟他共處了(打不過就加入?),這邊提供兩個比較常見的處理方法。
設定最大允許誤差ε (epsilon)
在某些語言里面會提供所謂的epsilon,用來讓你判斷是不是在浮點誤差的允許范圍內,以Python 來說epsilon 的值大概是2.2e-16。
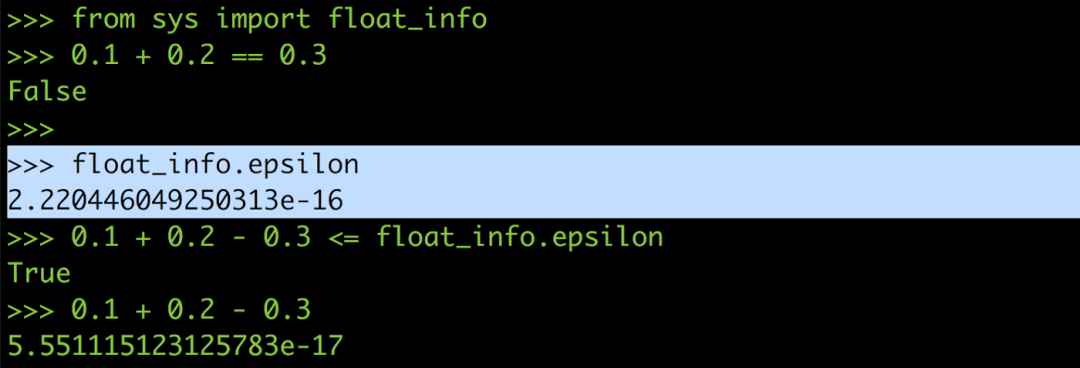
所以你可以把0.1 + 0.2 == 0.3改寫成0.1 + 0.2 — 0.3 <= epsilon,這樣就能避免浮點誤差在運算過程中作怪,也就可以正確比較出0.1 加0.2 是不是等于0.3。
當然如果系統沒提供的話你也可以自己定義一個epsilon,設定在2 的-15 次方左右。
完全使用十進位進行計算
之所以會有浮點誤差,是因為十進制轉二進制的過程中沒辦法把所有的小數部分都塞進fraction,既然轉換可能會有誤差,那干脆就不要轉了,直接用十進制來做計算!!
在Python 里面有一個module 叫做decimal,它可以幫你用十進位來進行計算,就像你自己用紙筆計算0.1 + 0.2 絕對不會出錯、也不會有任何誤差(其他語言也有類似的模組)。
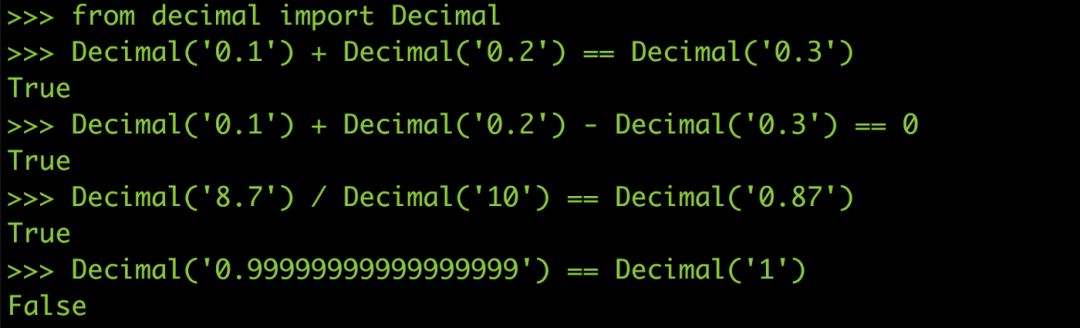
自從我用了Decimal 之后不只bug 不見了,連考試也都考一百分了呢!
雖然用十進位進行計算可以完全躲掉浮點誤差,但因為Decimal 的十進位計算是模擬出來的,在最底層的CPU 電路中還是用二進位在進行計算,所以跑起來會比原生的浮點運算慢非常多,所以也不建議全部的浮點運算都用Decimal 來做。
總結
回歸到這篇文章的主題:「為什么浮點誤差是無法避免的?」,相信大家都已經知道了。
至于你說知道IEEE 754 的浮點數格式有什么用嗎?好像也沒什么特別的用處XD,只是覺得能從浮點數的格式來探究誤差的成因很有趣而已,感覺離真相又近了一點點。
而且說不定哪天會有人問我「為什么浮點運算會產生誤差而整數不會」,那時我就可以有自信的講解給他聽,而不是跟他說「反正浮點運算就是會有誤差,背起來就對了」
來源:https://medium.com/starbugs/see-why-floating-point-error-can-not-be-avoided-from-ieee-754-809720b32175 版權歸原作者或平臺所有,僅供學習參考與學術研究,如有侵權,麻煩聯系刪除~感謝
審核編輯:劉清
-
二進制
+關注
關注
2文章
795瀏覽量
41690 -
python
+關注
關注
56文章
4799瀏覽量
84820
原文標題:為什么浮點運算會產生誤差而整數不會?
文章出處:【微信號:最后一個bug,微信公眾號:最后一個bug】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
二進制格雷碼與自然二進制碼的互換分析
二進制數邏輯運算是怎么運算的
浮點數轉換為二進制存儲的方法

二進制電平,什么是二進制電平
浮點數轉換為二進制存儲






 工商網監
工商網監
評論