 分析 丨 AI數據中心堪比超算,NVIDIA與AMD同場競技
分析 丨 AI數據中心堪比超算,NVIDIA與AMD同場競技
超級計算機對于科學研究、能源、工程設計領域具有重要意義,在商業用途中也發揮重要作用。2022年高性能計算專業大會發布的全球超級計算機Top500排行榜顯示,美國橡樹嶺國家實驗室(ORNL)的Frontier系統位列榜首,自2022年6月以來,Frontier一直是全球超級計算機Top500名單上的強大設備。
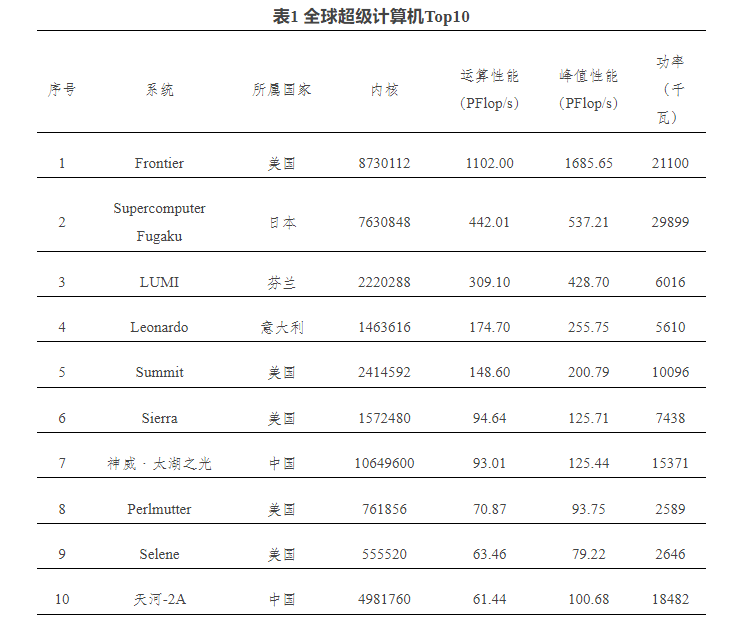
圖注:全球超級計算機Top10,發布時間為2022年11月(來源:中科院網信工作網)
進入2023年,超級計算機的排行將發生改變。
芯查查APP顯示,在美國勞倫斯利弗莫爾國家實驗室(LLNL)安裝的“El Capitan”超級計算機最快于2023年底啟動,從而可能刷新全球超級計算機榜單。El Capitan估計FP64峰值性能約為2.3 exaflops,比Frontier超級計算機的1.68 exaflops性能高出約37%。
同時,人工智能(AI)應用掀起,超大規模云服務企和AI初創企業都開始構建大型數據中心,比如,NVIDIA和CoreWeave正在為Inflection AI開發數據中心;Microsoft Azure正在為OpenAI構建的數據中心。從下圖可以看出,目前在建的這兩個AI數據中心在TFLOPS算力性能上雖然不如現有的超級計算機,但是在成本上已經超出很多。
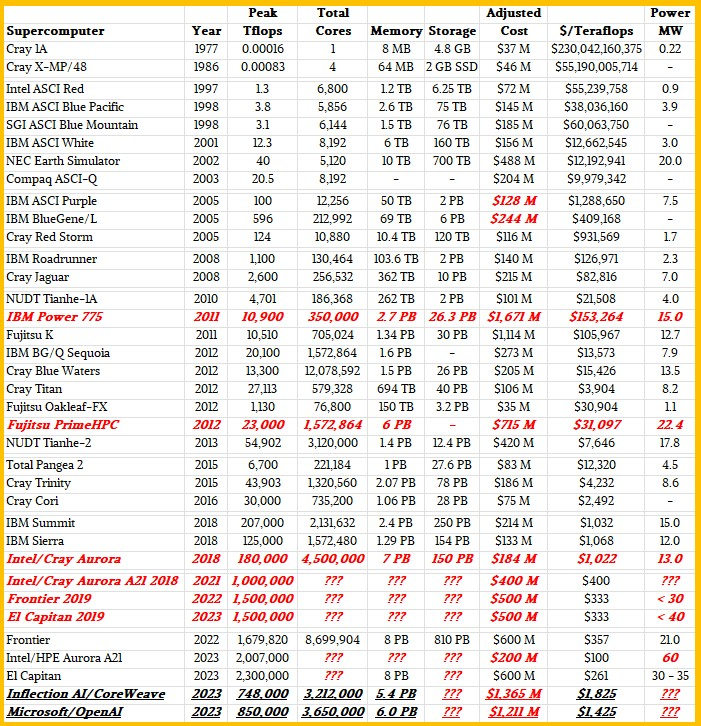
圖注:超級計算機與AI數據中心對比(來源:nextplatform網站)
AI數據中心面向AI訓練和推理進行配置,在建的AI數據中心進程如何?使用了哪些處理器?
Inflection AI使用處理器:NVIDIA H100Inflection AI是一家由Deep Mind前負責人創建,并由Microsoft和Nvidia支持的新創業公司。目前估值約為40億美元,產品為AI聊天機器人,支持計劃、調度和信息收集。
在籌集了13億美元的資金之后,Inflection AI將建立一個由多達22000個NVIDIA H100 GPU驅動的超級計算機集群,其峰值理論計算能力將與Frontier相當。理論上能夠提供1.474 exaflops的FP64性能。在CUDA內核上運行通用FP64代碼時,峰值吞吐量僅為其一半:0.737 FP64 exaflops(與前文圖表數值略有出入,但相差不大)。雖然FP64性能對于許多科學工作負載很重要,但對于面向AI的任務,該系統可能會更快。FP16/BF16的峰值吞吐量為43.5 exaflops,FP8吞吐量的峰值吞吐量是87.1 exaflops。
圖片來源:NVIDIA
Inflection AI的服務器集群成本尚不清楚,但NVIDIA H100 GPU零售價超過30000美元,預計該集群的GPU成本將達到數億美元。加上所有機架服務器和其他硬件,將占13億美元資金的大部分。
在市場需求遠遠超過供應的情況下,NVIDIA或AMD不會為其GPU計算引擎給予大幅折扣就,其服務器OEM和ODM合作伙伴同樣如此。因此,與美國的百億億次高性能計算系統相比,這些設備非常昂貴。Inflection AI的FP16半精度性能為21.8 exaflops,足以驅動一些非常大的LLM和DLRM(大型語言模型和深度學習推薦模型)。
El Capitan使用處理器:AMD Instinct MI300A為超級計算機“El Capitan”提供算力的處理器是“Antares”AMD Instinct MI300A CPU-GPU混合體,其FP16矩陣數學性能仍然未知。

圖注:基于AMD MI300的刀片設施(來源:http://tomshardware.com)
Instinct MI300是一款數據中心APU,它混合了總共13個chiplet,其中許多是3D堆疊的,形成一個單芯片封裝,其中包含24個Zen 4 CPU內核,融合CDNA 3圖形引擎和八個總容量為128GB的HBM3內存堆棧。這個芯片擁有1460億個晶體管,使其成為AMD投入生產的最大芯片。其中,由9個計算die構成的5nm CPU和GPU混合體,在4個6nm die上進行3D堆疊,這4個die主要處理內存和I/O流量。
預計每個MI300A在2.32 GHz時鐘頻率下可提供784 teraflops性能,常規MI300的時鐘頻率約為1.7GHz。惠普公司(HPE)或許在El Capitan系統中為每個滑軌配置8個MI300A,El Capitan的計算部分應該有大約2931個節點、46個機柜和8行設備。基于上述猜測,El Capitan應該有大約23500個MI300 GPU,具備大約18.4 exaflops的FP16矩陣數學峰值性能。相比Inflection AI,用更少的錢,發揮出更大性能。
Microsoft/OpenAI使用處理器:NVIDIA H100傳聞Microsoft正在為OpenAI構建25000 GPU集群,用于訓練GPT-5。
從歷史上看,Microsoft Azure使用PCI-Express版本的NVIDIA加速器構建其HPC和AI集群,并使用InfiniBand網絡將它們連接在一起。
為OpenAI構建的集群使用NVIDIA H100 PCI-Express板卡,假設為每個20000美元,即5億美元。另外,使用英特爾“Sapphire Rapids”至強SP主機處理器、2TB的主內存和合理數量的本地存儲,每個節點再增加150000美元,這將為容納這25000個GPU的3125個節點再增加4.69億美元。InfiniBand網絡將增加2.42億美元。合計12.1億美元,這些費用要比國家實驗室的超級計算機貴很多。
全球超級計算機追求新穎的架構,為最終商業化而進行研發。超大規模云服務商可以做同樣的數學運算,構建自己的計算引擎,包括亞馬遜網絡服務、谷歌、百度和Facebook都是如此。即使有50%的折扣,諸如Inflection AI和OpenAI的設備單位價格仍然比國家實驗室為超級計算機昂貴。
“神威·太湖之光”使用處理器:申威26010以2022年的全球超級計算機榜單來看,進入Top10的我國超級計算機是“神威·太湖之光”。資料顯示,該計算機安裝了40960個中國自主研發的申威26010眾核處理器,采用64位自主神威指令系統,峰值性能為12.5億億次每秒,持續性能為9.3億億次每秒,核心工作頻率1.5GHz。
申威和龍芯目前是我國自研處理器的代表,兩者均采用自研處理器的指令集架構。CPU國產化目前有3種方式,一個是獲得x86內核授權,一個是獲得Arm指令集架構授權,另一種是自研指令集架構,這種方式的安全可控程度較高,也是自主化較為徹底的一種方式。

圖注:國內服務器處理器廠商
小 結隨著人工智能應用發酵,超級計算機與AI數據中心的界限可能變得模糊,兩者的硬件和架構已經發展到可以更快地處理更多數據,因此其配置將會逐步超越,芯查查認為,整體呈現為幾點趨勢:面向AI應用,高性能處理器采用更多核心、異質架構將更加普遍,以支持更多的并行計算和更快的數據處理速度,處理器的內存管理和緩存設計也得到了優化,以減少對主存儲器的訪問延遲。專門的加速器,比如圖形處理單元(GPU)和神經網絡處理單元(NPU),將被引入處理器,高效地執行矩陣計算和神經網絡。能效是AI數據中心和超級計算機共同難點,處理器能效成為要點,設計趨向于降低功耗和散熱需求,采用更先進的制程技術、優化的電源管理以及動態頻率調節等方法。AI數據中心和超級計算機建設的需求推動了處理器的發展,也推動了存儲、結構和GPU的進步,這些組件都將服務于系統的數據吞吐量和效率。
審核編輯 黃宇
-
數據中心
+關注
關注
16文章
4855瀏覽量
72369 -
AI
+關注
關注
87文章
31494瀏覽量
270237
發布評論請先 登錄
相關推薦
NVIDIA發布個人超算利器project digital,標志著ai元年的開啟

智算中心會取代通用算力中心嗎?

全球視野 算領未來,施耐德電氣助力數據中心把握智算機遇

AMD數據中心業務收入超越Intel
AMD數據中心業務首超英特爾,Nvidia異軍突起
AI數據中心的能源危機,需要更高效的PSU
AMD全新處理器擴大數據中心CPU的領先地位
NVIDIA 在 Hot Chips 大會展示提升數據中心性能和能效的創新技術

AI時代,我們需要怎樣的數據中心?AI重新定義數據中心

AMD推出全新AMD銳龍和EPYC處理器,擴大數據中心和PC領域領先地位







 工商網監
工商網監
評論