

編者按
為了發展低成本全場景自動駕駛環境感知技術,針對毫米波雷達與視覺的融合感知技術的研究成為當前熱點,然而毫米波雷達和視覺兩種模態各有優缺點,如何充分利用兩種模態的信息提高3D目標檢測的性能,成為業界的一個重要關注點。本文提出了一種利用Transformer實現相機-毫米波雷達融合3D目標檢測,并在nuScenes 3D檢測基準上實現了最先進的性能,從而啟發我們研究基于Transformer的傳感器融合感知技術。
摘要
盡管雷達在汽車行業很受歡迎,但對于基于融合的3D目標檢測,現有的工作大多集中在激光雷達和相機融合上。在本文中,我們提出了TransCAR,一種基于Tansformer的相機和雷達融合解決方案,用于3D目標檢測。我們的TransCAR由兩個模塊組成。第一個模塊從環繞視圖相機圖像中學習2D特征,然后使用一組稀疏的3D對象查詢來索引到這些2D特征。然后,視覺更新的查詢通過transformer自我注意層相互交互。第二個模塊從多次雷達掃描中學習雷達特征,然后應用transformer解碼器學習雷達特征與視覺更新查詢之間的交互;transformer解碼器內部的交叉注意層可以自適應學習雷達特征與視覺更新查詢之間的軟關聯,而不是只基于傳感器標定的硬關聯。最后,我們的模型使用集對集的匈牙利損失估計每個查詢的邊界框,使該方法能夠避免非最大抑制。TransCAR利用無時間信息的雷達掃描提高了速度估計。我們的TransCAR再具有挑戰性的nuScenes數據集上的卓越實驗結果表明,我們的TransCAR由于最先進的基于相機-雷達融合的3D目標檢測方法。
1 簡介
雷達以用于高級駕駛輔助系統(ADAS)多年。然而,盡管雷達在汽車行業中很流行,考慮到3D目標檢測時,大多數工作集中在激光雷達[14,23,25,26,40 - 42,45]、相機[2,7,24,35],和激光雷達-相機融合[6,11,12,15,16,21 - 23,37,38,43]。其中一個原因是,沒有那么多帶有3D邊界框注釋的開放數據集,其中包括雷達數據[3,5,9,29]。另一個原因是,與激光雷達點云相比,汽車雷達信號更加稀疏并缺乏高度信息。這些屬性使得區分感興趣的對象和背景的回波變得很困難。然而,雷達與激光雷達相比有其優勢:(1)雷達在惡劣天氣和光照條件下具有魯棒性;(2)雷達可以通過多普勒效應精確測量目標的徑向速度,而不需要多幀時間信息;(3)雷達的成本比激光雷達低得多。因此,我們認為,通過雷達相機融合研究,有很大的潛力提高表現。 3D目標檢測是自動駕駛和ADAS系統的關鍵。3D物體檢測的目標是預測一組感興趣物體的3D邊界框和類別標簽。由于汽車雷達數據的稀疏性和高度信息的缺乏,僅從汽車雷達數據中直接估計和分類3D邊界框具有一定的挑戰性。基于單目相機的3D探測器[2,7,19,24,35]可以對目標進行分類,準確預測目標的航向角和方位角。然而,深度估計中的誤差是顯著的,因為從單個圖像回歸深度本質上是一個不適定的逆問題。雷達可以提供精確的深度測量,而基于單目相機的解決方案不能。相機可以產生基于雷達的解決方案不能產生的分類和3D邊界框估計。因此,將雷達和相機相融合,以獲得更好的3D目標檢測表現是一個自然的想法。
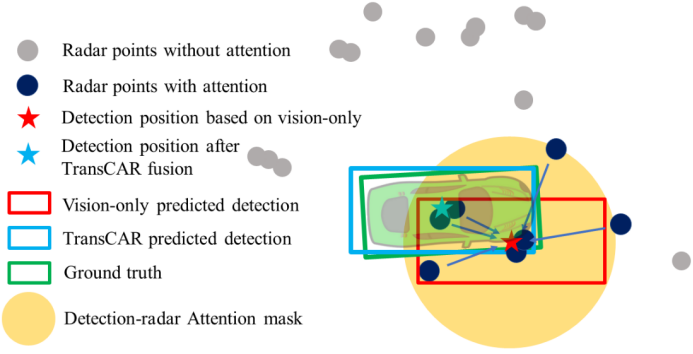
圖1:一個來自nuScenes[3]的例子,展示了TransCAR融合的工作原理。僅視覺檢測有顯著的距離誤差。我們的TransCAR融合可以學習基于視覺的查詢與相關雷達信號之間的交互,并預測改進的檢測。通過查詢雷達注意屏蔽,不相關的雷達點不會被注意。 不同傳感器模態之間的數據關聯是傳感器融合技術面臨的主要挑戰。現有的工作主要依靠多傳感器標定來做像素級[31]、特征級[6,12,15,16,39]或檢測級[21,22]關聯。然而,這對雷達和相機關聯來說是一個挑戰。首先,雷達缺乏高度測量,使得雷達-相機投影在高度方向上包含了很大的不確定性。其次,雷達波束比典型的圖像像素寬得多,并且可以四處反射。這可能導致雷達可以看到一些命中,但攝像頭無法感知。第三,雷達測量數據稀疏且分辨率低。許多相機可見的物體并沒有被雷達擊中。由于這些原因,基于傳感器標定的硬編碼數據關聯算法在雷達和相機融合中的表現較差。 具有深遠影響的Transformer框架最初是作為自然語言處理(NLP)的革命性技術提出的[30],隨后在計算機視覺應用中顯示了其通用性,包括對象分類[8]和檢測[4,47]。Transformer內部的自注意和交叉注意機制可以學習多個信息集之間的交互[1,4,30]。我們相信,這使得Transformer框架是一個可行的適合解決相機-雷達融合中的數據關聯。在本文中,我們提出了一種新的基于Transformer的雷達和相機融合網絡,稱為TransCAR,以解決上述問題。 我們的TransCAR首先使用DETR3D[35]生成基于圖像的對象查詢。然后,TransCAR從多次累積的雷達掃描中學習雷達特征,并應用transformer解碼器學習雷達特征與視覺更新查詢之間的交互。Transformer解碼器內部的交叉注意可以自適應地學習雷達特征與視覺更新查詢之間的軟關聯,而不是只基于傳感器標定的硬關聯。最后,我們的模型使用集對集匈牙利損失來預測每個查詢的邊界框。圖1說明了TransCAR的主要想法。我們還加入速度差異作為匈牙利二部匹配的指標,因為雷達可以提供精確的徑向速度測量。雖然我們的重點是融合多臺單目相機和雷達,但提出的TransCAR框架也適用于立體相機系統。我們使用具有挑戰性的nuScenes數據集[3]來演示我們的TransCAR。TransCAR的表現大大超過了所有其他先進的(SOTA)基于相機雷達融合的方法。擬議的體系結構提供了以下貢獻: ?我們研究了雷達數據的特點,提出了一種新型的相機-雷達融合網絡,該網絡能夠自適應地學習軟關聯,并在基于雷達-相機標定的基礎上顯示出比硬關聯更好的3D檢測表現。 ?提出了查詢-雷達注意屏蔽,以協助交叉注意層,避免遠處視覺查詢與雷達特征之間的不必要交互,并更好地學習關聯。 ?在不需要時間信息的情況下,TransCAR改進了雷達的速度估計。 ?提交時,在nuScenes 3D檢測基準上,TransCAR在已發表的基于相機-雷達融合的方法中排名第一。
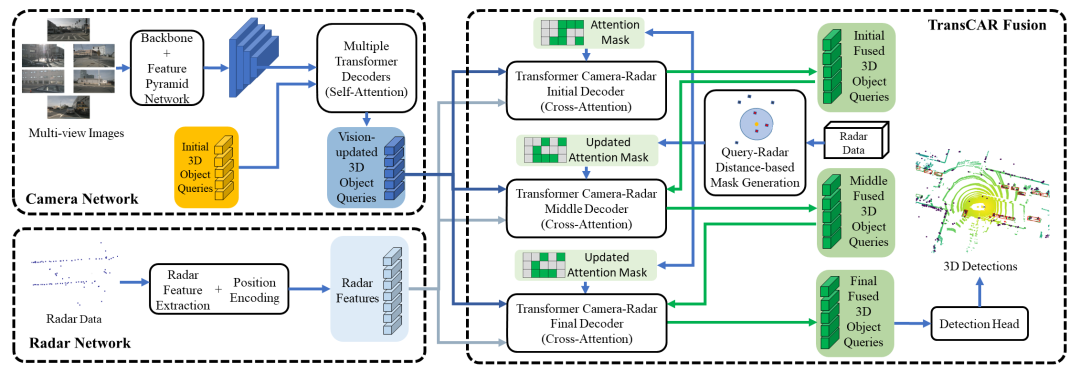
圖2:TransCAR系統架構。該系統主要由三個部分組成:(1)基于transformer解碼器的相機網絡(DETR3D[35])生成基于圖像的3D對象查詢。初始對象查詢是隨機生成的;(2)對雷達點位進行編碼,提取雷達特征的雷達網絡;(3)基于三個transformer交叉注意解碼器的TransCAR融合模塊。我們提出使用transformer來學習雷達特征與視覺更新對象查詢之間的交互,以實現自適應相機-雷達關聯。
2TransCAR
所提的TransCAR體系架構圖如圖2所示。相機網絡首先利用環繞視圖圖像來生成視覺更新的對象查詢。雷達網絡對雷達點位進行編碼并提取雷達特征。然后,TransCAR融合模塊將視覺更新的目標查詢與有用的雷達特征融合。下面,我們將詳細介紹TransCAR中的各個模塊。
2.1
相機網絡
我們的攝像頭網絡將6個攝像頭采集的環繞主車360度的全景圖像和初始3D對象查詢作為輸入,并輸出一組在3D空間的視覺更新的3D對象查詢。我們將DETR3D[35]應用于相機網絡,并遵循自上而下的迭代設計。它利用初始的3D查詢為2D特征建立索引,以細化3D查詢。輸出的3D視覺更新查詢是TransCAR融合模塊的輸入。2.1.1為什么從相機開始我們使用環繞視圖圖像生成用于融合的3D物體查詢。雷達不適合這項任務,因為許多感興趣的物體沒有雷達回波。這背后有兩個主要原因。首先,與相機和激光雷達相比,典型的汽車雷達的垂直視場非常有限,而且它通常安裝在較低的位置。因此,任何位于雷達小垂直視場之外的物體都將被忽略。其次,與激光雷達不同,雷達波束更寬,方位角分辨率有限,因此很難探測到小型物體。根據我們在補充資料中的統計,在nuScenes訓練集中,雷達有很高的漏檢率,特別是對于小目標。對于道路上最常見的兩個類別——汽車和行人,雷達漏掉了36.05%的汽車和78.16%的行人。相機有更好的物體可視性。因此,我們首先利用圖像預測用于融合的3D物體的查詢。2.1.2 研究方法相機網絡使用ResNet-101[10]和特征金字塔網絡(FPN)[17]學習多尺度特征金字塔。這些多尺度特征圖為探測不同大小的目標提供了豐富的信息。效仿[36,47],我們的相機網絡(DETR3D[35])是迭代的。它有6個Transformer解碼器層來產生視覺更新的3D對象查詢;每一層都將前一層的輸出查詢作為輸入。下面解釋了每個層中的步驟。 對于第一解碼器層,一組N (對于nuScenes N = 900)個可學習3D對象查詢Q0= {Q01,Q02,…,q0N}∈RC在3D監視區域內隨機初始化。上標0表示到第一層的輸入查詢,下標是查詢的索引。網絡從訓練數據中學習這些3D查詢位置的分布。網絡從訓練數據中學習這些3D查詢位置的分布。對于下面的層,輸入查詢是來自上一層的輸出查詢。每個3D對象查詢編碼一個潛在對象的3D中心位置pi∈R3。通過雙線性插值,將這些3D中心點投影到基于相機內外參數的圖像特征金字塔中以提取圖像特征。假設圖像特征金字塔中有k層,對于一個3D點pi,采樣后的圖像特征fi∈RC是所有k層采樣特征的總和,C為特征通道數。一個給定的3D中心點pi可能在任何相機圖像中都不可見。我們用零填充這些視點對應的采樣圖像特征。 Transformer自注意層用于學習N個3D對象查詢之間的交互,并生成注意分數。然后將對象查詢與通過注意力分數加權的采樣的圖像特征相結合,形成更新后的對象查詢Ql= {ql1,ql2,…,qlN}∈RC,其中l為當前層。Ql是第(l + 1)層查詢的輸入集。 對于每個更新的對象查詢qli,使用兩個神經網絡預測一個3D邊界框和一個類標簽。邊界框編碼和丟失函數的細節在2.4節中描述。訓練過程中,每一層后計算一次損失。在推理模式中,僅使用來自最后一層的視覺更新查詢輸出進行融合。
2.2
雷達網絡
該雷達網絡的設計目的是學習有用的雷達特征,并對其3D位置進行編碼以進行融合。我們首先根據x和y距離對雷達點進行過濾,因為只有在BEV中+/?50米范圍內的物體才會在nuScenes[3]中進行評估。由于雷達是稀疏的,我們將前5幀的雷達積累起來,并將其轉換為當前幀。nuScenes數據集為每個雷達點提供了18個通道,包括主車幀中的3D位置x, y, z,徑向速度vx和vy,主車運動補償速度vxc和vyc,虛警概率pdh0,動態屬性通道dynProp指示群集是移動還是靜止,和其他狀態通道1。為了使狀態通道對網絡具有學習的可行性,我們將狀態通道轉化為獨熱向量。由于我們使用了5個累積的幀,每個幀相對于當前時間戳的時間偏移對于指示位置偏移是有用的,所以我們還為每個點添加了一個時間偏移通道。通過這些預處理操作,每個輸入雷達點有36個通道。 使用多層感知器(MLP)網絡學習雷達特征Fr∈RM×C和雷達點位置編碼Pr∈RM×C,其中M和C分別為雷達點數和特征通道數。在本文中,我們對nuScenes數據集設置M = 1500, C = 256。注意,即使在nuScenes數據集中累積,每個時間步長的雷達點也少于1500個。因此,為了尺寸兼容性,我們用超出范圍的位置和零特征填充空點。圖3顯示了雷達網絡的詳細信息。我們將學習到的特征和位置編碼結合起來,作為最終的雷達特征Fradar= (Fr+ Pr)∈RM×C。這些最終的雷達特征和相機網絡的視覺更新查詢將用于下一步的TransCAR融合。
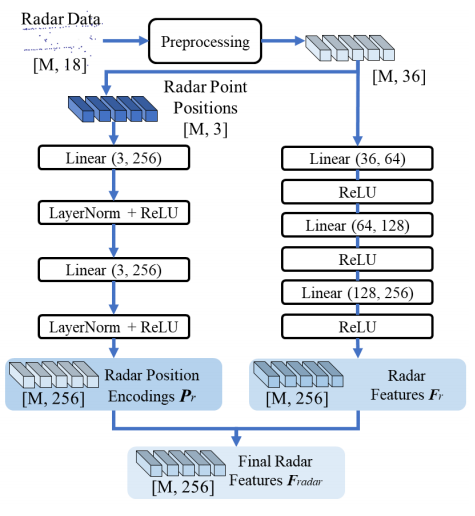
圖3:雷達網絡細節。位置編碼網絡(左)以雷達點位置(xyz)作為輸入。預處理后的雷達數據(章節2.2)發送到雷達特征提取網絡(右側),學習有用的雷達特征。由于雷達信號非常稀疏,所以每個雷達點都是獨立處理的。方括號內的數字表示數據的形狀。
2.3
TransCAR融合
TransCAR融合模塊將前一步的視覺更新查詢和雷達特征作為輸入,輸出融合查詢進行3D邊界框預測。在TransCAR融合模塊中,三個Transformer解碼器以迭代方式工作。提出了查詢-雷達注意屏蔽,以幫助交叉注意層更好地學習視覺更新查詢與雷達特征之間的交互和關聯。2.3.1查詢-雷達注意屏蔽如果輸入查詢、鍵和值的數量都很大,那么訓練一個transformer是很有挑戰性和耗時的[4,8]。對于我們的transformer解碼器,有N個3D對象查詢Q∈RN×C和M個雷達特性Frad∈RM×C作為鍵和值,其中對于nuScenes N = 900和M = 1500。不需要學習它們之間的每一個成對的交互(900 × 1500)。對于查詢qi∈Q,只有附近的雷達特征是有用的。沒有必要將qi與其他雷達特征進行交互。因此,我們定義一個二進制N×M 查詢-雷達注意屏蔽M∈{0,1}N×M,以防止對某些位置的注意,其中0表示不注意,1表示允許注意。只有當第i個查詢qi與第j個雷達特征fj之間的xy歐氏距離小于閾值時,才允許注意M中的位置(i,j)。在TransCAR融合中,三個transformer解碼器對應3個查詢-雷達注意屏蔽。這三種屏蔽的半徑分別為2m、2m和1m。2.3.2 transformer相機與雷達交叉注意在我們的TransCAR融合中,通過級聯3個transformer交叉注意解碼器來學習視覺更新查詢和雷達特征之間的關聯。圖4顯示了一個transformer交叉注意解碼器的詳細信息。對于初始解碼器,相機網絡輸出的視覺更新查詢Qimg∈RN×C為輸入查詢。Frad∈RM×C的雷達特性是輸入鍵和值。查詢-雷達注意屏蔽M1用于防止注意某些不必要的配對。解碼器內的交叉注意層將輸出注意分數矩陣A1∈[0,1]N×M。對于A1第i行中的M個元素,表示第i個視覺更新查詢與所有M個雷達特征之間的注意力得分,總和為1。注意,對于每個查詢,只允許注意與之接近的雷達特性,因此對于A1中的每一行,它們中的大多數都是0。這些注意力分數是視覺更新查詢和雷達特性之間的關聯指示器。然后,用于視覺更新查詢的注意力加權雷達特征計算為F?rad1= (A1·Frad)∈RN×C。這些加權雷達特征與原始的視覺更新查詢相結合,然后通過前饋網絡(FFN) ΦFFN1進行增強。這形成了初始階段的融合查詢:Qf1= ΦFFN1(Qimg+F?rad1)∈RN×C。
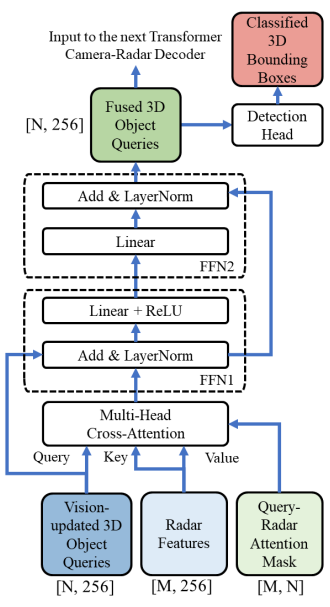
圖4:transformer相機-雷達解碼器層的細節。視覺更新的3D目標Q是對多頭交叉注意模塊的Q。雷達的特性是K和V。詳見第2.3.2節。括號內的數字表示數據的形狀。 中間和最后的transformer解碼器的工作原理與最初的解碼器相似。但是它們使用之前的融合查詢Qf1而不是視覺更新查詢作為輸入。以中間查詢為例,新的查詢-雷達注意屏蔽M2是根據Qf1和雷達點位置之間的距離計算的。當查詢位置在初始解碼器中更新時,我們還使用Qf1中的編碼過的查詢位置重新采樣圖像特征ff2。與初始解碼器類似,Qf1的注意力加權雷達特征被定義為F?rad2= (A2·Frad)∈RN×C,其中A2包括初始階段融合查詢Qf1和雷達特征Frad的注意力分數。輸出融合查詢是通過Qf2= ΦFFN2(Qf1+ F?rad2+ ff2)∈RN×C學習的。在兩個解碼器之后,我們使用兩組FFN進行邊界框預測。我們在訓練過程中計算兩個解碼器的損耗,在推理過程中只使用最后一個解碼器的邊界框輸出。由于能見度的限制,一些查詢可能沒有附近的雷達信號。我們在訓練過程中計算兩個解碼器的損耗,在推理過程中只使用最后一個解碼器的邊界框輸出。 由于能見度的限制,一些查詢可能沒有附近的雷達信號。這些查詢不會與任何雷達信號交互,它們的注意力分數都是0。來自這些查詢的檢測將只基于視覺。
2.4
框編碼和損失函數
框編碼:我們將一個3D邊界框b3D編碼為一個11位向量:
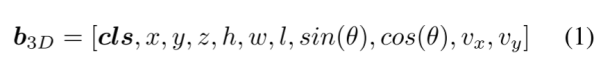
其中cls = {c1,…,cn}為類標號,x、y、z為3D中心位置,h、w、l為3D維度,θ為航向角,vx、vy為沿x、y軸的速度。對于每個輸出對象查詢q,網絡預測它的類分數c∈[0,1]n(n為類數,對于nuScenes n = 10)和3D邊界框參數b∈R10:
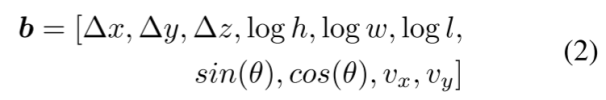
其中?x,?y和?z是預測和上一層查詢位置之間的偏移量。與DETR3D估算Sigmoid空間[35]中的位置偏移不同,我們直接回歸3D笛卡爾坐標中的位置偏移。DETR3D使用Sigmoid空間,因為他們希望將位置輸出保持在[0,1]之間,所以所有的查詢位置都在距離邊界內。而對于TransCAR,我們從優化的視覺更新查詢開始,其位置相對更準確。因此,我們可以避免可能會影響學習的冗余的非線性激活。損失:我們使用集對集匈牙利損失來指導訓練,并測量網絡預測與以下事實之間的差異[4,28,35]。損失函數中有兩個部分,一個用于分類,另一個用于邊界框回歸。我們將焦點損失[18]用于分類以解決類的不平衡,并將L1損失用于邊界框回歸。假設N和K表示同一幀中預測和基本事實的個數,由于N明顯大于K,我們將φ(無對象)填充基本事實集合。效仿[4,28,35],我們使用匈牙利算法[13]來解決預測和基本事實之間的二部匹配問題:
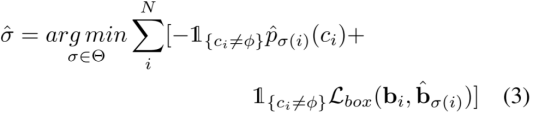
式中,Θ為排列集合,p?σ(i)(ci)為排列指數為σ(i)的ci類概率,Lbox為邊界框的L1差值,bi和b?σ(i)分別為基本事實框和預測框。這里,請注意,我們還將速度估計vx和vy合并到Lbox中,以便更好地匹配和估計速度。采用最優排列σ?,最終匈牙利損失可表示為:
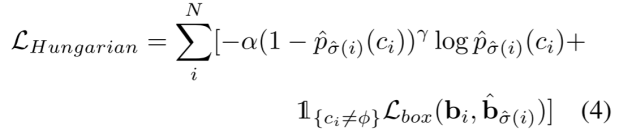
其中α和γ是焦點損失的參數。
3 實驗結果
我們在具有挑戰性的nuScenes 3D檢測基準[3]上評估了我們的TransCAR,因為它是唯一包含雷達的開放大規模標注數據集。
3.1
數據集
在nuScenes數據收集車輛上安裝有6臺相機、5臺雷達和1臺激光雷達。nuScenes 3D檢測數據集包含1000個20秒的駕駛片段(場景),其中訓練片段700個,驗證片段150個,測試片段150個。標注率為2Hz,因此分別有28k、6k和6k標注幀用于訓練、驗證和測試。有10類對象。真陽指標是基于BEV中心距離的。
3.2
評價結果
我們在表1中展示了nuScenes測試集的3D檢測結果。我們的TransCAR在提交時優于所有其他的相機雷達融合方法。與基線僅相機方法相比,DETR3D[35]、TransCAR具有更高的mAP和NDS (nuScenes Detection Score[3])。注意,DETR3D是用CBGS[46]訓練的,而TransCAR不是。從表1中可以看出,在10個等級中,汽車等級提升幅度最大(+2.4%)。汽車和行人是駕駛場景的主要興趣對象。在nuScenes數據集中,轎車類在訓練集中所占比例最高,占總實例的43.74%,其中63.95%的汽車實例被雷達命中。因此,這些汽車實例為我們的TransCAR學習融合提供了足夠的訓練實例。行人類在訓練集中所占比例第二高,占總實例數的19.67%,但雷達返回僅占21.84%。TransCAR仍可將行人mAP提高1.2%。這說明,對于有雷達命中的目標,TransCAR可以利用雷達命中來提高檢測表現,對于無雷達命中的目標,TransCAR可以保持基線表現。 表1:nuScenes測試集與SOTA方法的定量比較。在‘Sensor’欄中,‘C’、‘L’和‘CR’分別代表相機、激光雷達和相機-雷達融合。‘C.V.’, ‘Ped’, ‘Motor’和‘T.C’分別是工程車輛、行人、摩托車和交通錐的縮寫。TransCAR是目前最好的基于相機雷達融合的方法,擁有最高的NDS和mAP,甚至優于早期發布的基于激光雷達的方法。表現最好的用粗體突出顯示,排除了僅使用激光雷達的解決方案。
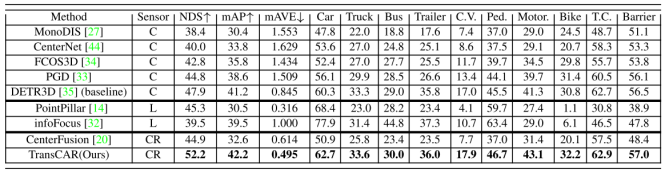
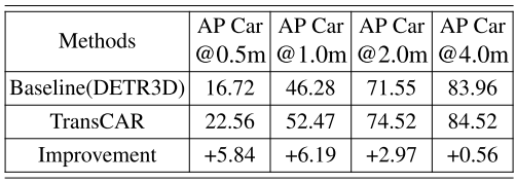
表2為轎車類的基線DETR3D[35] 與不同中心距離評價指標的定量比較。在nuScenes數據集中,真陽指標基于中心距離,即真陽指標與基本真實值之間的中心距離應小于閾值。nuScenes定義了從0.5米到4.0米的四個距離閾值。如表2所示,TransCAR針對所有4個指標改進了AP。特別是對于更加嚴格和重要的指標0.5和1.0米閾值,改進分別為5.84%和6.19%。 表2:在nuScenes驗證集上,不同中心距離評價指標的轎車類與基線DETR3D的平均精度(AP)比較。我們的TransCAR在所有評估指標上都大大提高了AP。
3.3
定性結果
圖5顯示了在nuScenes數據集[3]上,TransCAR與基線DETR3D[35]之間的定性比較。藍色和紅色的框分別是來自TransCAR和DETR3D的預測,綠色填充的矩形是基本事實。較大的暗點為雷達點,較小的色點為激光雷達參考點(黃色至綠色表示距離的增加)。左列的橢圓區域突出了TransCAR所做的改進,圖像上的橙色框突出了自上向下視圖中相應的橢圓區域。TransCAR融合了基線DETR3D的檢測結果,顯著改善了3D邊界框估計。
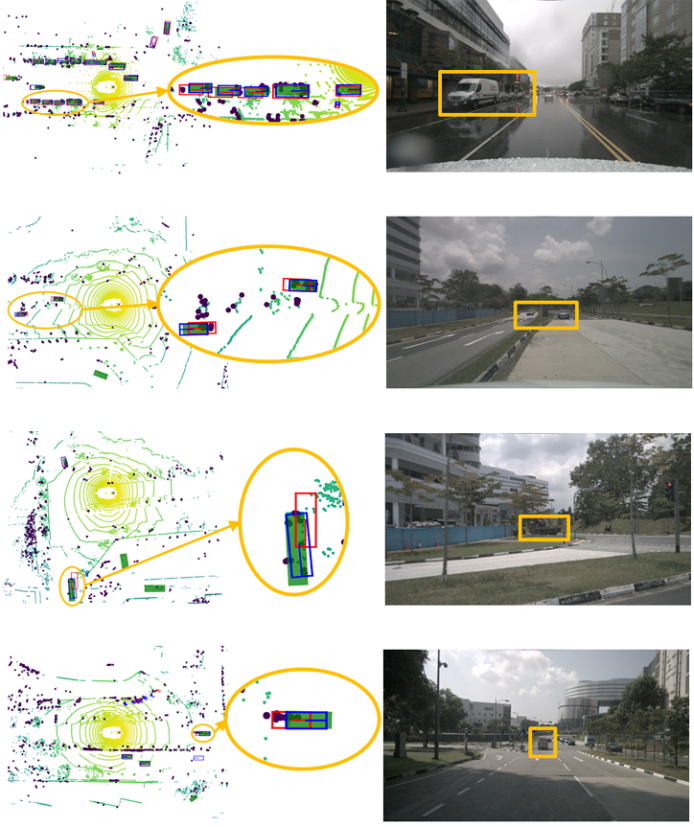
圖5:在nuScenes數據集[3]上,TransCAR與基線DETR3D的定性比較。藍色和紅色的框分別是來自TransCAR和DETR3D的預測,綠色填充的矩形是基本事實。較大的暗點為雷達點,較小的色點為激光雷達參考點(黃色至綠色表示距離的增加)。左列的橢圓區域突出了TransCAR所做的改進,圖像上的橙色框突出了自上向下視圖中相應的橢圓區域。包含放大和彩色的最佳視角。
3.4
消融與分析
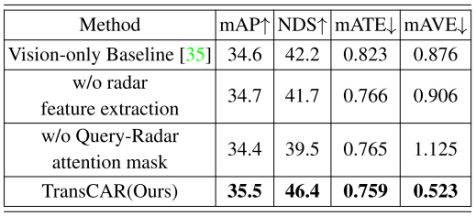
由于篇幅限制,我們在本節展示了部分消融研究,更多的消融研究在補充材料中顯示。各組件的貢獻:我們評估每個組件在我們的TransCAR網絡中的貢獻。nuScenes驗證集的消融研究結果如表3所示。僅限視覺的基線是DETR3D[35]。徑向速度是雷達可以提供的唯一測量結果之一;雖然它不是真實的速度,但它仍然可以引導網絡在沒有時間信息的情況下預測物體的速度。如表3第二行所示,在沒有雷達徑向速度時,網絡只能利用雷達點的位置進行融合,且mAVE (m/s)顯著較高(0.906 vs. 0.523)。查詢雷達注意屏蔽可以根據查詢和雷達特征之間的距離來防止對它們的注意。如果沒有它,每個查詢都必須與場景中的所有雷達特征(在我們的工作中是1500)交互。 表3:TransCAR組件在nuScenes 驗證集上的消融。
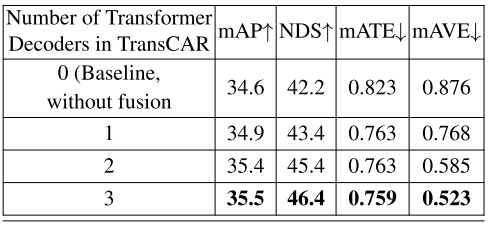
迭代改進:在TransCAR中有三個迭代工作的transformer交叉注意解碼器。我們研究了迭代設計在TransCAR融合中的有效性,結果如表4所示。從表4的定量結果可以看出,TransCAR融合中的迭代細化可以提高檢測表現,有利于充分利用我們提出的融合架構。 表4:對不同數量transformer解碼器在TransCAR中檢測結果的評價。
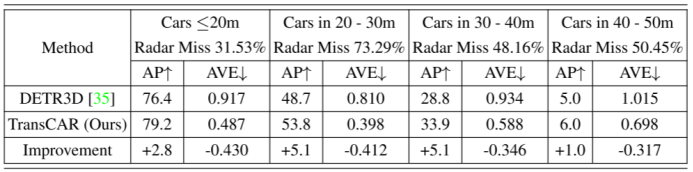
不同距離范圍的表現:表5和表6顯示了不同距離范圍下nuScenes數據集的檢測表現,表5顯示了10個類的平均結果,表6僅為轎車類。這兩個表的結果表明,僅視覺基線法(DETR3D)和我們的TransCAR在較短的距離中表現更好。在20~40米范圍內,TransCAR的改進更為顯著。這主要是因為對于20米以內的目標,位置誤差較小,利用雷達進行改進的空間有限。對于超過40米的物體,該基線的表現很差,因此TransCAR只能提供有限的改進。請注意,表5中所有10個類的平均精度(mAP)和相應的改進比表6中轎車類的要小。這主要有兩個原因。首先,mAP是所有類ap的均值,在nuScenes數據集中,雷達傳感器對于小型目標類(行人、自行車、交通錐等)有較高的失誤率。例如,78.16%的行人和63.74%的騎自行車的人沒有雷達信號。因此,與大型對象(汽車、公共汽車等)相比,這些類的表現更差。因此,對于這類目標,TransCAR所帶來的改進是有限的,對于有雷達回波的目標類,TransCAR可以利用雷達信號來提高檢測表現,對于無雷達回波的目標類,TransCAR只能保持基線表現。其次,nuScenes數據集存在明顯的類失衡現象,轎車類占訓練實例的43.74%,而其他類如自行車和摩托車僅占1.00%和1.07%。這些稀少的類的訓練例子是不夠的。對于主要的轎車類,也是駕駛場景中最常見的對象,TransCAR可以大幅度提高檢測表現和速度估計(表6)。 表5:nuScenes驗證集上所有不同距離范圍的平均精度(mAP, %)、nuScenes檢測分數(NDS)和平均速度誤差(AVE, m/s)。我們的TransCAR在所有距離范圍內都優于基線(DETR3D)。

表6:nuScenes驗證集上不同距離范圍的轎車類的平均精度(AP, %)和平均速度誤差(AVE, m/s)。給出了雷達傳感器在不同距離下的漏檢率。被雷達錯過的轎車被定義為沒有雷達回波的轎車。我們的TransCAR改進了AP,并在所有距離范圍內大大降低了速度估計誤差。
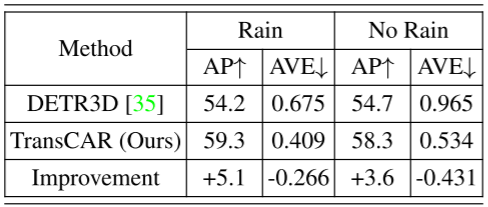
不同的天氣和光照條件:與相機相比,雷達在不同的天氣和光照條件下魯棒性更強。我們對雨天和夜間的檢測表現進行了評估,結果如表7和表8所示。注意nuScenes不為每個帶注釋的幀提供天氣標簽,天氣信息在場景描述部分提供(場景是一個20秒的數據段[3])。在人工檢查了一些帶注解的幀后,我們發現“雨”下的幀并不是在下雨的時候捕獲的,有些是在下雨之前或之后采集的。然而,與在晴天采集的圖像相比,這些圖像的質量較低。因此,它們適合于我們的評價實驗。 表7顯示了轎車類在下雨和無雨場景下的AP和AVE。與無雨場景相比,在下雨場景中,TransCAR有更高的AP改善(+5.1% vs. +3.6%)。下雨場景的AVE小于無雨場景;這是因為雨幀存在偏差,這些雨場景中的車輛更接近主車,更容易被檢測到。 表8為夜間和白天場景的檢測表現比較。夜間光照條件差,基線法的表現不如白天(AP為52.2% vs.54.8%,AVE為1.691m/s vs.0.866m/s), TransCAR可以利用雷達數據提高AP 6.9%, 降低AVE 1.012m/s。雖然夜間場景有限(15個場景,602幀),但該結果仍然可以證明TransCAR在夜間場景中的有效性。 表7:在nuScenes驗證集上,轎車類在下雨和無雨場景下的平均精度(AP)和平均速度誤差(AVE, m/s)的比較。nuScenes驗證集中6019幀(150個場景)中有1088幀(27個場景)被標注為下雨。在下雨條件下,TransCAR能夠顯著提高探測表現,降低速度估計誤差。
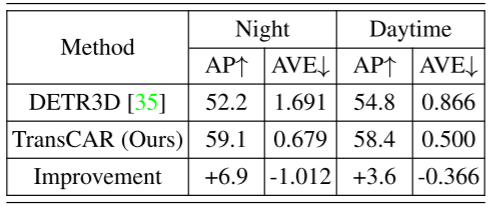
表8:轎車類在nuScenes驗證集的夜間和白天場景的平均精度(AP)和平均速度誤差(AVE, m/s)的比較。夜間采集nuScenes驗證集6019幀中的602幀。TransCAR可以利用雷達數據顯著提高表現,降低夜間相機受到影響時的速度估計誤差。
4補充材料
4.1
雷達和激光雷達漏檢率的比較
與激光雷達相比,雷達具有更高的漏檢率。主要有兩個原因:第一,與激光雷達相比,汽車雷達的視野非常有限。并且雷達通常安裝在較低的位置。因此,任何位于雷達小垂直視場之外的物體都將被忽略。其次,雷達波束較寬,方位角分辨率有限,難以探測到小型目標。nuScenes訓練集的LiDAR和radar失誤率統計如表9所示。我們計算了不同類別的物體數量,雷達或激光雷達漏檢的物體數量以及相應的漏檢率。雷達有很高的漏檢率,特別是對小目標。對于道路上最常見的兩個類別——汽車和行人,雷達漏掉了36.05%的汽車和78.16%的行人。 請注意,我們不是在批評雷達。表9顯示了在目標探測任務中使用雷達所面臨的挑戰。了解雷達測量的性質有助于我們設計合理的融合系統。正如在主論文中討論的,基于這些統計數據,我們得出結論,雷達,配置在nuScenes車輛上,不適合用于生成3D查詢。 表9:nuScenes訓練集中,主車50米范圍內不同類別對象的統計。* ‘C.V.’, ‘Ped’,‘Motor’ 和‘T.C’分別代表工程車輛、行人、摩托車及交通錐。被雷達或激光雷達錯過的目標被定義為該目標沒有命中/回波。雷達漏掉了更多的目標。對于自動駕駛應用中最常見的兩個類別,汽車和行人,雷達忽略了36.05%的汽車和78.16%的行人。雖然nuScenes沒有提供圖像中物體的詳細可見性,但我們相信它比雷達高得多。因此,我們使用相機而不是雷達來生成3D目標查詢進行融合。
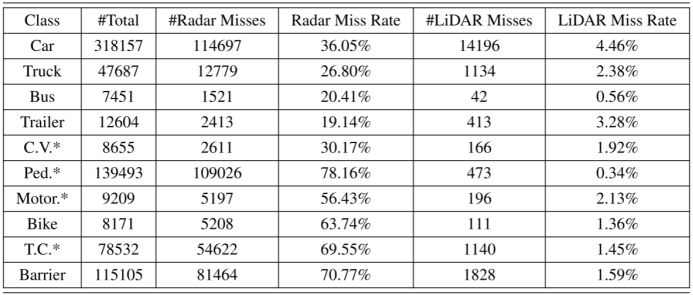
*在“傳感器”一欄中,C表示僅攝相機。L代表只使用激光雷達, CR代表基于相機和雷達融合的方法。 我們注意到,盡管雷達傳感器有這些物理限制,但我們的結果表明,與雷達融合可以顯著改善僅對圖像的檢測。這開啟了以不同方式配置雷達的可能性,例如在車頂上,以減少漏檢率,并可能進一步提高融合表現。
4.2
二級評價指標的更多結果
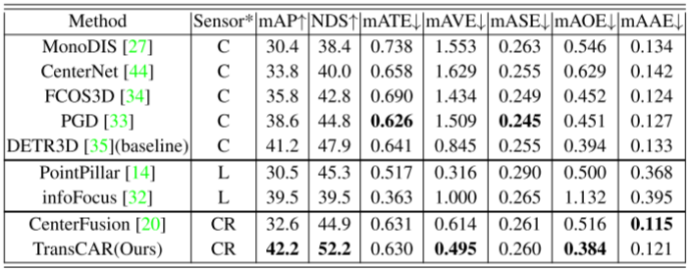
為了完整起見,我們展示了表10,以顯示nuScenes測試集上的其他二級評價指標與其他SOTA方法的比較。在與雷達融合后,與其他方法相比,我們的TransCAR在所有二級評價指標上都具有更好或相同水平的表現。特別是在雷達信號融合的情況下,TransCAR在速度估計方面有很大的優勢。與基線(DETR3D)相比,TransCAR提高了所有評估指標的表現。 表10:nuScenes測試集上nuScenes數據集定義的其他二級評價指標與其他SOTA方法的比較。排除激光雷達唯一的解決方案,最好的表現突出在粗體。
4.3
更多消融研究
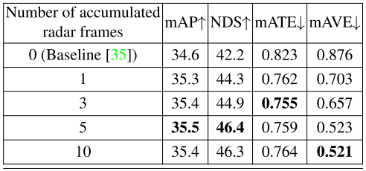
用于融合的雷達幀數:由于雷達點云稀疏,我們累積了多個具有自車運動補償的雷達幀進行融合。我們評估了累積不同雷達幀數的影響,結果如表11和表12所示。表11顯示了nuScenes驗證集中所有10個類的評估結果,表12是僅針對轎車類的結果。累積5幀雷達整體效果最好,累積10幀時速度誤差mAVE略低。積累更多的雷達幀可以提供更密集的雷達點云進行融合,但同時也會包含更多的噪聲點。此外,對于快速移動的物體,積累更多的雷達幀會產生更長的“軌跡”,因為在這個階段物體的運動無法得到補償。這可能會潛在地損害邊界框位置估計。 表11:累積不同雷達幀數進行融合的各類檢測結果評價。
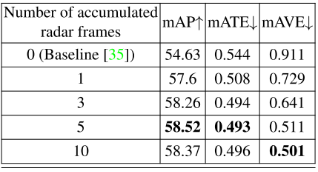
表12:累積不同雷達幀數進行融合的車輛檢測結果評價。
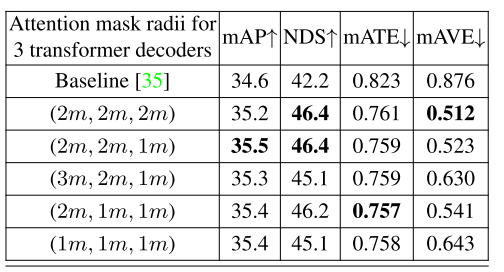
注意屏蔽半徑:在我們的TransCAR融合系統中,我們將圓形注意屏蔽應用于transformer解碼器。對于每個transformer解碼器,圓形注意屏蔽的半徑可以不同。我們在nuScenes驗證集上測試了不同的圓注意屏蔽半徑組合,結果如表13所示。如表13所示,所有半徑配置都能顯著提高3D檢測表現。大的和小的注意屏蔽之間存在一種權衡。大的注意屏蔽可以增加合并正確的雷達特征的概率,特別是對于大的物體,但包含噪聲和附近其他物體的雷達特征的可能性也更高。對于小的注意屏蔽,我們更確定所包含的雷達特征是好的,但我們更有可能錯過正確的雷達特征。由表13可知,(2m, 2m, 1m)的綜合表現最好。開始時較大的半徑提供了較高的探測機會,以捕獲正確的雷達特征。最后半徑越小,估計結果越精確。 表13:在我們的TransCAR中,每個transformer解碼器的不同注意屏蔽半徑的比較。
5結論
在本文中,我們提出了一種基于transformer的高效、魯棒的相機與雷達3D檢測框架TransCAR,它可以學習雷達特征與視覺查詢之間的軟關聯,而不是基于傳感器標定的硬關聯。相關的雷達特性提高了距離和速度估計。相關的雷達特性改善了距離和速度估計。我們的TransCAR在具有挑戰性的nuScenes探測基準上成為了最先進的相機-雷達探測方法。我們希望我們的工作可以啟發雷達相機融合的進一步研究,并激勵使用transformer進行傳感器融合。
-
3D
+關注
關注
9文章
2939瀏覽量
109117 -
雷達
+關注
關注
50文章
3039瀏覽量
119023 -
目標檢測
+關注
關注
0文章
220瀏覽量
15840 -
毫米波雷達
+關注
關注
107文章
1071瀏覽量
65037
原文標題:TransCAR:基于Transformer的相機-毫米波雷達融合3D目標檢測方法
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
毫米波雷達方案對比
毫米波雷達(一)
毫米雷達波概述
求大佬分享一種基于毫米波雷達和機器視覺的前方車輛檢測方法
毫米波雷達工作原理,雷達感應模塊技術,有什么優勢呢?
雷達傳感器模塊,智能存在感應方案,毫米波雷達工作原理
漫談車載毫米波雷達歷史
加特蘭基于AiP毫米波雷達芯片率先實現3D目標跟蹤等功能

毫米波雷達(RADAR)

毫米波雷達(RADAR)
毫米波雷達模塊的目標檢測與跟蹤
基于毫米波雷達和多視角相機鳥瞰圖融合的3D感知方法





 工商網監
工商網監

評論