 ChatGPT對社交機器人技術發展的影響分析
ChatGPT對社交機器人技術發展的影響分析
ChatGPT對社交機器人技術發展的影響分析
摘 要 作為生成式人工智能的典型代表,全新的預訓練基礎模型ChatGPT已成為各界關注的“現象級”討論熱點。對ChatGPT及其對社交機器人技術發展的影響與啟發進行綜合評述。首先介紹了ChatGPT的概念內涵、主要特征、發展歷程;其次探討了以ChatGPT為代表的預訓練基礎模型所反映出的當前人工智能技術發展趨勢;最后分析了近來生成式人工智能的飛速發展對于社交機器人研究與應用的提升作用。綜述表明,社交機器人對于內容自主生成能力的旺盛需求,使其與生成式人工智能的發展進度緊密耦合,未來將在個性化內容生成、生成內容鑒別與管制、“涌現”能力溯源等方面繼續發展。
1 引 言
美國OpenAI公司推出的ChatGPT,幾乎成為了全球人工智能領域自2016年的AlphaGo以來又一個“里程碑式”節點和“顛覆式”革新,有望開啟新一輪技術驅動產業變革的加速發展。作為從“專用人工智能”邁向“通用人工智能”[1]的標志性成果,ChatGPT已于2023年1月被美國國防信息系統局(DISA)列入觀察名單,值得高度關注。在剛剛過去的2023年2月24日,OpenAI公司基于對ChatGPT所代表的大規模預訓練基礎模型的深入思考和中長期發展規劃,發布了《通用人工智能發展規劃(Planning for AGI and beyond)》(如圖1所示),認為通用人工智能或許能成為人類才智和創造力的強大“增幅器”。

圖1 OpenAI公司發布《通用人工智能發展規劃》
Fig.1 Planning for AGI and beyond from OpenAI
2 ChatGPT的概念特征與發展歷程
2.1概念內涵
ChatGPT是一種全新的預訓練基礎模型[2-3](Pre-Training Foundation Model),主要針對智能對話任務,在“預訓練+下游任務微調”模式的傳統預訓練基礎模型的基礎[4]上,通過引入基于人類反饋的強化學習等先進策略,從海量數據中自主學習“世界知識”,成功實現了復雜自然語言理解、“人格化”類人語言生成、多輪人機問答等能力的質的飛躍,在理解人類思維的準確性方面,達到了前所未有的高度,并成為史上用戶數增長最快的消費級應用(2個月內積累1億用戶)。
2.2主要特征
以ChatGPT為代表的預訓練基礎模型,已經成為當前人工智能發展的主流方向和最高水平,預計將成為現階段及未來3~5年內人工智能研發與應用提速升級的最強“助推器”,其成功的關鍵主要來源于以下三個方面:一是擁有龐大的基座大模型作為支撐,ChatGPT所基于的GPT系列模型均是擁有龐大參數規模的基座大模型,其主要經歷三次迭代,參數量從1.17億增至1750億[5],ChatGPT的參數量業界估計將近2000億;二是擁有高質量的真實數據作為供給,OpenAI在數據積累、清洗、標注等方面進行了持續數年的大力投入,預訓練數據的體量和質量遙遙領先,業界推測ChatGPT的訓練數據規模高達8000億個單詞;三是擁有強大的算力資源作為保障,驅動ChatGPT的算力資源十分昂貴,其所依托的云服務供應商——微軟Azure為此提供了約1萬個GPU(圖形處理器)和超過28.5萬個CPU(中央處理器)。
2.3發展歷程
自2018年起,OpenAI公司先后發布了GPT-1、GPT-2、GPT-3、InstructGPT等4個主要版本[6]。其中,GPT-1的標志是無監督學習,GPT-2的標志是多任務學習,GPT-3的標志是海量參數(如圖2所示)。自GPT-3后,OpenAI公司所有模型都不再開源,現有對ChatGPT的分析研究主要是基于歷史版本的技術推測。OpenAI公司于2019年3月從非盈利轉型為盈利公司,陸續獲得微軟等多個機構的七輪融資,其中,微軟的總投資額高達數十億美元。充足的資金是ChatGPT成功的重要條件,僅2022年,OpenAI研發投入就超過5.44億美元。
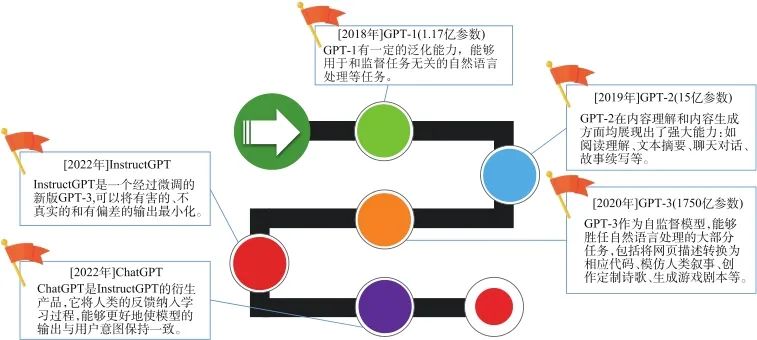
圖2 ChatGPT及其歷史版本的發展歷程
Fig.2 The development of ChatGPT and its historical version
3 ChatGPT對人工智能技術發展的重要意義分析
3.1ChatGPT技術定位與應用分析
ChatGPT 是技術發展的演進,不是跨代式顛覆,但會在應用層面引起新一輪的革命,其影響力不亞于互聯網的誕生。
(1)技術研判
ChatGPT是一次技術路線的勝利。自2018年起,美國谷歌公司的BERT模型和美國OpenAI公司的GPT系列模型成為預訓練基礎模型的兩個主流方向。其中,BERT的訓練方式是讓模型根據前后文雙向猜測,實現無標注文本自監督學習,曾經在很長一段時間內優于GPT;GPT則是按照單向預測、參數升級、反復訓練和生成內容反饋等方式持續迭代優化,目前已明顯優于BERT。目前,ChatGPT 的效能仍然建立在海量數據訓練和統計分析的基礎上,技術本質上尚未脫離“弱人工智能”的范疇,雖然其在某些文字應用(如內容生成)、重復代碼構建等場景中的效能已超過大多數人工,但仍然沒有解決完備“世界知識”與深層認知推理等技術難題。因此,ChatGPT 雖呈現“智能”,卻未擁有“智力”。
以 ChatGPT 為代表的預訓練基礎模型技術將會朝著以下方向發展:一是多模態融合處理,有效處理圖像、視頻、語言、語音等多模態的數據及跨模態信息;二是具有與物理現實世界交互的能力,探索具身智能、物理常識、抽象世界模型、可感知的四維物理空間等;三是信息時效性顯著增加,不僅可以從歷史數據中汲取養分,而且可以動態獲取和即時分析網絡實時信息;四是在縝密邏輯思考、數學求解、長程思考、復雜任務處理等能力上得到進一步提升。
(2)應用研判
ChatGPT技術應用前景廣闊,積極搶占高地刻不容緩。以其在軍事領域的應用為例,美國國防部的“第三次抵消戰略”指出,“人工智能的快速發展,連同機器人技術、自主性、大數據以及與工業界加強合作,將定義下一代戰爭”。將ChatGPT這種交互式人工智能聊天機器人部署在加固型邊緣計算機上有望在多域作戰環境中發揮關鍵作用,為士兵提供他們需要的實時信息、態勢感知結果、輔助決策方案等,以有效協調戰場所有領域的行動。因此,其在海量信息檢索、深度獲取與處理,多模態情報處理與認知,作戰規劃與場景決策,網絡對抗等方面均具備較強的應用潛力。然而,目前此類預訓練基礎模型沒有辦法保證回答是穩定可靠、正確無誤的,對于軍事應用具有較大風險,需進行進一步研究予以解決。
3.2ChatGPT所反映出的人工智能技術主要發展趨勢分析
預訓練基礎模型廣泛而深入的成功應用,深刻闡釋了當前生成式人工智能[7](Generative Artificial Intelligence)發展的主要趨勢,同時也為人工智能的發展指明了方向。
(1)模型、算力、數據仍然是影響人工智能能力的基本要素
ChatGPT成功的關鍵動能主要來自算力、數據、算法這三個方面,充分說明算力、數據、算法依然是當前決定人工智能能力高度的決定性因素。規模龐大且架構先進的模型、強大的算力資源、巨體量高質量的數據資源,決定了以預訓練基礎模型為“風向標”的新一代人工智能所能達到的高度。國內科研院所及科技企業在大語言模型、語料數據集、國產化算力等方面具備一定基礎,但相對ChatGPT仍存在差距。以數據為例,國內并不缺乏數據,但在海量異構數據清洗、標注方面仍未形成有效機制。據估算,百億級數據中可能只有10%的數據是“可用”的,數據質量在一定程度上制約了我國國產大模型的發展[8-9]。
(2)“通用+專用”人工智能呈現出融合發展態勢
很長一段時間內,由于通用人工智能存在前期投入大、智能水平低、商業模式匱乏等問題,人工智能發展普遍聚焦垂直專業領域的賦能應用,專用人工智能是發展主流;作為從“專用人工智能”邁向“通用人工智能”的標志性成果,ChatGPT的成功意味著通用人工智能已逐步進入商業化落地階段[10]。經過海量數據訓練后,預訓練基礎模型可以被引導執行任意的任務:預訓練基礎模型代表了一種范式轉變,從訓練基于特定任務的模型到訓練可執行多任務的模型。因此,在聚焦垂直專業領域的專用人工智能發展日趨成熟的當下,以預訓練基礎模型為代表的、具備解決多任務能力的通用人工智能也逐漸進入商業化階段,“通用”和“專用”互補的人工智能技術與產業體系正在加速演進。
(3)人工智能正由“感知智能”快速向“認知智能”邁進
預訓練基礎模型帶來了理解人類語言和推理解題能力的大幅度提升,引領人工智能從感知智能所側重的圖像信號(信號抽象程度相對較低)處理能力向認知智能所側重的人類語言信號(信號抽象程度相對較高)處理能力演進,引領人工智能從感知智能所達到的“能說、能看”能力向“能思考、能創作、能決策”等高階認知能力快速演進。
(4)模型存在安全隱患,可信可解釋將成“下一站”研究方向
受訓練語料和技術架構的影響,ChatGPT存在意識形態安全、內容安全、隱私泄露、網絡安全等諸多問題[11-12]。以意識形態安全為例,部分政治問題等敏感的問答反映出ChatGPT依然存在思想偏見,其能夠被發展為無處不在的意識形態對抗,對使用者產生無形的影響;同時,其本身也易被人為干擾導致結果出現偏向。因此,在人工智能“大模型”時代、通用技術不可阻擋的發展潮流中,面向數據隱私保護、正確價值觀引導等安全要素,應積極開展反ChatGPT相關的“反智能”基礎算法研究應用工作。
(5)圍繞預訓練基礎模型的人工智能競爭可能形成“贏者通吃”態勢
萬億級預訓練基礎模型對企業的數據儲備、技術實力、算力平臺、投入資金等要求極高。高昂的投入需求意味著,主流的大規模預訓練基礎模型只能由大型科技公司或者少數研究機構掌握。同時,ChatGPT發布后的全世界熱度,使其具備巨大的先發優勢,能夠搶先收集大量用戶使用數據,使其與其他企業之間的差距“雪球”越滾越大,逐步形成“數據壁壘”,進而質變為“能力壁壘”。
4 ChatGPT對社交機器人技術的影響分析與發展建議
4.1ChatGPT對社交機器人技術發展的主要影響分析
在信息時代社交媒體出現后,其應用場景越來越廣泛、豐富,且社交媒體的用戶覆蓋率逐年上升。社交機器人通常是指用于自主化文宣、價值傳播等用途的,且具有發布、轉發、評論、點贊、聊天等“人-機”交互功能的社交媒體虛擬賬號[13-14],又稱為“虛擬機器人”(如圖3所示),在市場營銷、情感陪護、輿情治理等領域有著廣泛而深入的應用。在各大社交媒體平臺中,Twitter平臺以其高達4.36億的用戶數量排在前列,其月度活躍用戶數量達2.11億,而這其中有4800萬的賬號是社交機器人[15]。
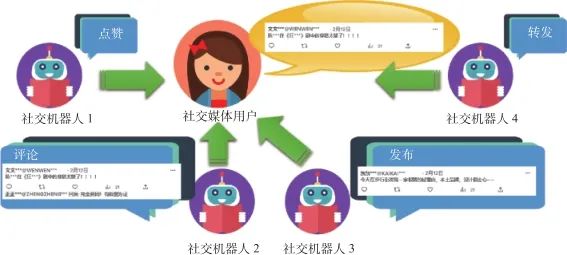
圖3 社交機器人功能示意
Fig.3 Function diagram of social robot
在當前人工智能時代,隨著相關技術的成熟與應用的豐富,社交機器人已逐漸從“人工”有人化、手動式養殖培育轉變為“自動”無人化、托管式成長,但是其技術層面的核心需求——內容生成是始終不變的,其所生成和發布傳播的內容的質量決定了社交機器人所能夠產生的價值和應用效益。隨著近年來以預訓練基礎模型為代表的生成式人工智能技術的快速發展(例如2022年被譽為“人工智能生成內容[16](AI-Generated Content)元年”),特別是最近ChatGPT快速興起帶來的啟示,社交機器人的內容生成方法論已由傳統的基于規則模板的“淺層”生成轉變為當前預訓練基礎模型加持下的“深度”創作,已由過去生成內容的“千篇一律”轉變為現在的向著“差異化、人格化”方向發展。
(1)ChatGPT體現出的智能“涌現”帶來社交機器人“創造力”的提升
“涌現”通常是指:一個研究對象表現出自身部分所不具備的特性。例如,這些行為或能力只有通過各個部分的相互作用才能顯現出來。已有研究將以ChatGPT為典型代表的預訓練基礎模型的“涌現”能力定義為:如果一種能力不存在于較小的模型中、而存在于較大的模型中,那么這種能力就是涌現出來的[17]。
已有研究發現,預訓練基礎模型的表現并非隨著模型規模增加而線性增長,而是存在臨界點。只有當模型規模大到超過特定的臨界點,才會“涌現”出較小的模型不具備的“新”能力、自主學習到“新”功能,體現出創造性。ChatGPT所體現出的這種“涌現”能力能夠賦予社交機器人強大的“創造”能力,不僅徹底改觀以往人們對社交機器人發文“千篇一律”的印象,通過產生生動的且具備“人格化”的內容,讓人越來越不易察覺發文的背后是一臺機器,還能生成意想不到的、超乎尋常的內容。
(2)先進計算架構驅動下的ChatGPT帶動社交機器人在“多任務”適配能力上的提升
如何驅動社交機器人彈性、高效地適用于不同的垂直領域場景(例如在金融、醫療、教育領域之間快速切換等)、應用于不同任務(例如對話問答、內容檢索、方案規劃等),是目前社交機器人所需要解決的關鍵問題。
預訓練基礎模型驅動下的社交機器人在多任務適配能力方面的提升,主要源自如下兩個重要因素:一是預訓練基礎模型所體現出的涌現能力意味著,大規模預訓練基礎模型可以進一步擴展語言模型的功能范疇與應用范圍。ChatGPT的成功,已經表明預訓練基礎模型在零樣本或者小樣本學習上的涌現能力,已讓它們得以進入實際應用領域,并能夠在自然語言處理研究領域之外產生和服務于許多新的應用;二是預訓練基礎模型所采用的“預訓練+下游任務微調”或者“預訓練+提示”等先進的數據訓練與推理范式[18-20],保證其能夠快速適配不同的應用任務。
(3)跨模態數據關聯理解能力帶動社交機器人“多模態”內容生成能力的提升
圖片、視頻等多模態信息加持下的生成內容,比傳統單調的文字形式文宣,對社交媒體受眾而言更容易被接受也更加具有感染力。因此,讓發布和回復的內容存在多種模態(如圖文結合等方式),是社交機器人研究與應用一直追求的目標。
從技術層面來看,ChatGPT屬于生成式人工智能范疇,預訓練基礎模型擅長于多模態數據融合、推理與生成[21-23],能夠依托數據挖掘分析策略從海量多源多模態異構信息中得到高價值信息、提高多元化和細粒度的跨模態數據關聯能力,基于預訓練基礎模型的多模態內容生成,已經成為當前重要的研究熱點。此外,在目前多模態內容生成的“延長線”上,進一步探索融合跨模態知識來得到更加符合推理目標的準確的推理鏈條,是未來預訓練基礎模型在認知能力強化方面的必由之路。
(4)以策略生成為代表的輔助決策能力帶動社交機器人“精準投送”能力的提升
目前,以ChatGPT為代表的預訓練基礎模型已體現出初步的、可用的時序邏輯梳理和策略規劃能力,而這正是社交機器人所亟需的,如文宣內容編排與投放順序、推送強度與內容搭配等,這些文宣投放策略方面的設置與“組合拳”,直接決定了社交機器人的信息傳遞目的能否完成、決定了社交機器人的工作效能。
一方面,基于ChatGPT的人工智能可以分析來自多個來源與媒介的大量數據,以提供快速準確的“目標對象是否容易被影響、是否適宜文宣投放”的評估,幫助決策人員快速做出規避投入風險的決策;另一方面,依托預訓練基礎模型日漸成熟的策略生成能力,快速生成包括投放對象、投放內容、投放順序等要素在內的文宣投放方案,并通過“人-機”協同機制迭代完善生成更明智、更有效的投送決策,實現新的精準投送。
4.2發展基于生成式人工智能的社交機器人技術的主要建議
ChatGPT是一種大規模預訓練模型,該類模型是“生成式人工智能”的典型代表,生成式人工智能更是被譽為“提出了自啟蒙運動以來從未經歷過的哲學挑戰和實踐挑戰”。生成式人工智能對于社交機器人技術有著天然的強關聯,對發展基于生成式人工智能的社交機器人技術,建議如下:
(1)開展個性化內容自主生成的研究
伴隨著互聯網的深度發展和廣泛普及,無論是商業推廣還是輿情治理,都離不開對廣大受眾的精準推動,通過彈性強度推送、精心搭配推送內容、情感調動、意識形態引導等方式施加輿論引導、實現公眾認知的改觀。因此,亟需推進面向動態領域知識的多模態內容生成,構建面向虛擬機器人養成的行動部署技術體系,融合畫像庫及事件知識圖譜設定社交機器人身份,結合大規模預訓練基礎模型,研究具有明確立場、觀點、情感傾向和具有目標地區語言特點的內容生成技術;研究目標用戶導向、事件導向的社交機器人智能化行為,提升社交機器人的人格化水平。
(2)開展生成內容甄別與管制的研究
生成式人工智能降低了虛假信息的偽造成本,為制造“信息繭房”、情報迷霧、輿論攻擊、意識形態滲透、網絡攻擊等提供了新手段,給國家安全帶來新的挑戰。因此,亟需深化開展開源情報迷霧甄別技術研究,避免被誤導、被誘偏;圍繞意識形態與認知塑造,開展以ChatGPT為代表的生成式人工智能技術濫用的檢測識別與監管控制。
(3)開展涌現能力定位溯源的研究
ChatGPT體現出強大的智能“涌現”能力。涌現能力具有重要的科學意義:如果涌現能力是沒有盡頭的,那么只要模型足夠大,強人工智能的出現就是必然的。但是這種“涌現”目前不可控、不可預測,而且涌現能力也并非全然是好事,例如預訓練基礎模型帶來的社會與倫理問題(性別與種族歧視、不文明用語等),有時也具有涌現的特性,即當模型較小時不會出現、只有模型足夠大時才會呈現。因此,亟需研究預訓練基礎模型的涌現能力及其局限性:一方面建立對涌現能力的一般性理解,并探索其未實現的潛力及最終極限,探究大模型涌現能力來源、定位模型預測不穩定的根本原因,以此為構建穩健大規模預訓練基礎模型奠定基礎;另一方面,研究知識真實性驗證技術,實現對大模型中“過時”“錯誤”知識的快速定位,研究大模型知識更新、編輯技術,實現大模型知識的快速更新修補。
5 結束語
全新的預訓練基礎模型ChatGPT代表著當前生成式人工智能技術的前沿水平,已經成為新一代人工智能戰略布局中不可取代的“共性技術基礎設施”,并顯著帶動了社交機器人在內容“創造性”、“多任務”適配、“多模態”內容生成、內容“精準投送”等方面的能力提升。可以預見,隨著以預訓練基礎模型為代表的生成式人工智能技術的發展與完善,未來社交機器人技術的研發與應用,將在個性化內容生成、生成內容鑒別與管制、智能“涌現”能力溯源等方面繼續取得進步。
-
機器人
+關注
關注
211文章
28632瀏覽量
208161 -
人工智能
+關注
關注
1796文章
47643瀏覽量
239902 -
ChatGPT
+關注
關注
29文章
1566瀏覽量
7989
原文標題:推薦閱讀 | ChatGPT對社交機器人技術發展的影響分析
文章出處:【微信號:CloudBrain-TT,微信公眾號:云腦智庫】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人的基礎模塊
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
【「具身智能機器人系統」閱讀體驗】1.初步理解具身智能
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
【「具身智能機器人系統」閱讀體驗】+初品的體驗
《具身智能機器人系統》第1-6章閱讀心得之具身智能機器人系統背景知識與基礎模塊
ChatGPT 與傳統聊天機器人的比較
機器人技術的發展趨勢
醫療機器人發展現狀與趨勢
Meta人工智能聊天機器人進軍新市場,挑戰ChatGPT
機器人視覺的作用是什么
其利天下技術·搭載無刷電機的掃地機器人的前景如何?
FMEA與機器人:如何確保機器人技術的可靠性與安全性
自然語言控制機械臂:ChatGPT與機器人技術的融合創新(下)






 工商網監
工商網監
評論